假設您已經使用 PyTorch 、 TensorFlow 或您選擇的框架訓練了您的模型,并對其準確性感到滿意,并且正在考慮將其部署為服務。有兩個重要的目標需要考慮:最大化模型性能和構建將其部署為服務所需的基礎設施。這篇文章討論了這兩個目標。
通過在三個堆棧級別上加速模型,可以從模型中擠出更好的性能:
- 硬件加速
- 軟件加速
- 算法或網絡加速。
NVIDIA GPU 是深度學習從業者在硬件加速方面的首選,其優點在業界得到廣泛討論。
關于 GPU 軟件加速的討論通常圍繞庫,如 cuDNN 、 NCCL 、 TensorRT 和其他 CUDA-X 庫。
算法或網絡加速 圍繞量化和知識提取等技術的使用,這些技術本質上是對網絡本身進行修改,其應用高度依賴于您的模型。
這種加速需求主要是由業務問題驅動的,如降低成本或通過減少延遲來改善最終用戶體驗,以及戰術考慮因素,如在計算資源較少的邊緣設備上部署模型。
服務深度學習模型
在模型加速后,下一步是構建一個服務服務來部署您的模型,這會帶來一系列獨特的挑戰。這是一個非詳盡列表:
- 該服務能否在不同的硬件平臺上工作?
- 它會處理我必須同時部署的其他模型嗎?
- 服務是否可靠?
- 如何減少延遲?
- 使用不同的框架和技術堆棧訓練模型;我該如何應對?
- 如何縮放?
這些都是有效的問題,解決每一個問題都是一個挑戰。
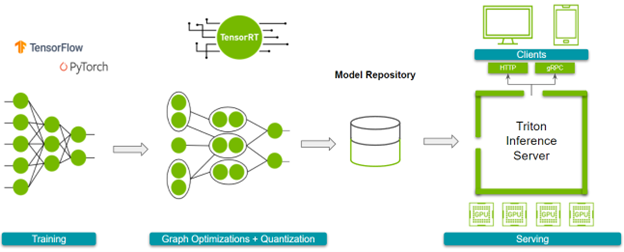
解決方案概述
本文討論了使用 NVIDIA TensorRT 及其 PyTorch 和 TensorFlow 的框架集成、 NVIDIA Triton 推理服務器和 NVIDIA GPU 來加速和部署模型。
NVIDIA TensorRT 公司
NVIDIA TensorRT 是一個用于高性能深度學習推理的 SDK 。它包括深度學習推理優化器和運行時,為深度學習推理應用程序提供低延遲和高吞吐量。
通過其與 PyTorch 和 TensorFlow 的框架集成,只需一行代碼就可以將推理速度提高 6 倍。
NVIDIA Triton 推理服務器
NVIDIA Triton 推理服務器是一種開源的推理服務軟件,提供單一的標準化推理平臺。它可以支持在數據中心、云、嵌入式設備或虛擬化環境中的任何 GPU 或基于 CPU 的基礎設施上對來自多個框架的模型進行推理。
有關更多信息,請參閱以下視頻:
工作流概述
在深入細節之前,下面是總體工作流程。接下來,請參閱以下參考資料:
圖 1 顯示了您必須完成的步驟。
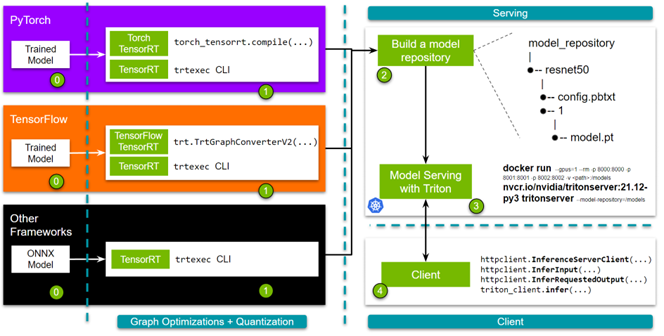
在你開始跟隨之前,準備好你訓練過的模型。
- 第 1 步: 優化模型。您可以使用 TensorRT 或其框架集成來實現這一點。如果選擇 TensorRT ,則可以使用 trtexec 命令行界面。對于與 TensorFlow 或 Pytorch 的框架集成,可以使用單行 API 。
- 第 2 步: 構建模型存儲庫。啟動 NVIDIA Triton 推理服務器需要一個模型存儲庫。該存儲庫包含要提供服務的模型、指定詳細信息的配置文件以及任何必需的元數據。
- 第 3 步: 啟動服務器。
- 第 4 步: 最后,我們提供了簡單而健壯的 HTTP 和 gRPC API ,您可以使用它們來查詢服務器!
在本文中,使用 NGC 中的 Docker 容器。您可能需要創建一個帳戶并獲得 API key 來訪問這些容器。現在,這里是細節!
使用 TensorRT 加速模型
TensorRT 通過圖優化和量化加速模型。您可以通過以下任何方式獲得這些好處:
- trtexec CLI 工具
- Python / C ++ API
- Torch- TensorRT (與 PyTorch 集成)
- TensorFlow- TensorRT (與 TensorFlow 集成)
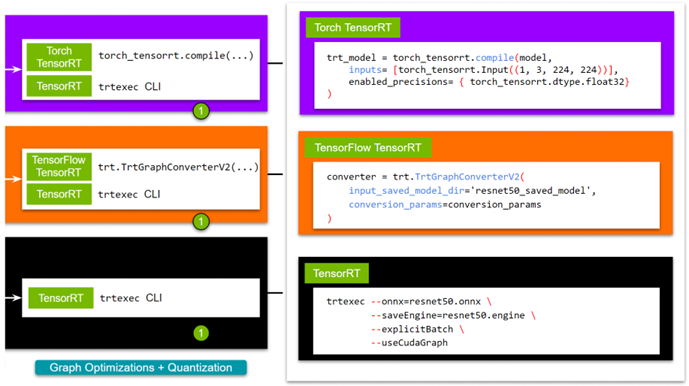
雖然 TensorRT 在本機上支持圖形優化的更大定制,但框架集成為生態系統的新開發人員提供了易用性。由于選擇用戶可能采用的路由取決于其網絡的特定需求,我們希望列出所有選項。有關更多信息,請參閱 使用 NVIDIA TensorRT 加速深度學習推理(更新) .
對于 TensorRT ,有幾種方法可以構建 TensorRT 引擎。對于本文,請使用 trtexec CLI 工具。如果您想要一個腳本來導出一個預訓練的模型,請使用 export_resnet_to_onnx.py 示例。有關更多信息,請參閱 TensorRT 文件 .
docker run -it --gpus all -v /path/to/this/folder:/trt_optimize nvcr.io/nvidia/tensorrt:<xx:yy>-py3 trtexec --onnx=resnet50.onnx \ --saveEngine=resnet50.engine \ --explicitBatch \ --useCudaGraph
要使用 FP16 ,請在命令中添加--fp16。在繼續下一步之前,您必須知道網絡輸入層和輸出層的名稱,這是定義 NVIDIA Triton 模型存儲庫配置時所必需的。一種簡單的方法是使用polygraphy,它與 TensorRT 容器一起打包。
polygraphy inspect model resnet50.engine --mode=basic
ForTorch TensorRT ,拉動 NVIDIA PyTorch 容器 ,安裝了 TensorRT 和火炬 TensorRT 。要繼續,請使用 sample 。有關更多示例,請訪問 Torch-TensorRT GitHub repo 。
# <xx.xx> is the yy:mm for the publishing tag for NVIDIA's Pytorch # container; eg. 21.12 docker run -it --gpus all -v /path/to/this/folder:/resnet50_eg nvcr.io/nvidia/pytorch:<xx.xx>-py3 python torch_trt_resnet50.py
為了擴展細節,您基本上使用 Torch- TensorRT 用 TensorRT 編譯 PyTorch 模型。在幕后,您的模型被轉換為 TorchScript 模塊,然后對 TensorRT 支持的操作進行優化。有關更多信息,請參閱 PyTorch – TensorRT 文件 .
model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True).eval().to("cuda") # Compile with Torch TensorRT;
trt_model = torch_tensorrt.compile(model, inputs= [torch_tensorrt.Input((1, 3, 224, 224))], enabled_precisions= { torch_tensorrt.dtype.float32} # Runs with FP32; can use FP16
) # Save the model
torch.jit.save(trt_model, "model.pt")
對于 TensorFlow TensorRT ,過程基本相同。首先,拉動 NVIDIA TensorFlow Container ,它與 TensorRT 和 TensorFlow TensorRT 一起提供。我們以 short script tf_trt_resnet50.py為例。有關更多示例,請參閱 TensorFlow TensorRT github 回購。
# <xx.xx> is the yy:mm for the publishing tag for the NVIDIA Tensorflow # container; eg. 21.12 docker run -it --gpus all -v /path/to/this/folder:/resnet50_eg nvcr.io/nvidia/tensorflow:<xx.xx>-tf2-py3 python tf_trt_resnet50.py
同樣,您基本上是使用 TensorFlow- TensorRT 用 TensorRT 編譯 TensorFlow 模型。在幕后,您的模型被分割成包含 TensorRT 支持的操作的子圖,然后進行優化。有關更多信息,請參閱 張量流 – TensorRT 文檔 .
# Load model
model = ResNet50(weights='imagenet')
model.save('resnet50_saved_model') # Optimize with tftrt converter = trt.TrtGraphConverterV2(input_saved_model_dir='resnet50_saved_model')
converter.convert() # Save the model
converter.save(output_saved_model_dir='resnet50_saved_model_TFTRT_FP32')
現在,您已經使用 TensorRT 優化了模型,可以繼續下一步,設置 NVIDIA Triton ?聲波風廓線儀。
設置 NVIDIA Triton 推理服務器
NVIDIA Triton 推理服務器用于簡化生產環境中大規模部署模型或模型集合。為了實現易用性和靈活性,使用 NVIDIA Triton 圍繞著構建一個模型存儲庫,其中包含模型、用于部署這些模型的配置文件以及其他必要的元數據。
看看最簡單的例子。圖 4 有四個關鍵點。config.pbtxt文件( a )是前面提到的配置文件,其中包含模型的配置信息。
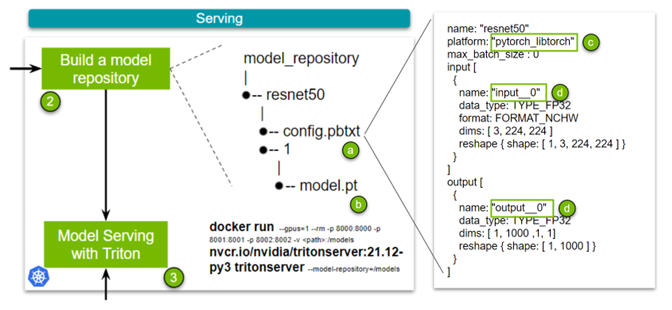
此配置文件中有幾個要點需要注意:
- Name: 此字段定義模型的名稱,并且在模型存儲庫中必須是唯一的。
- Platform: ( c )此字段用于定義模型的類型:是 TensorRT 引擎、 PyTorch 模型還是其他模型。
- 輸入和輸出: ( d )這些字段是必需的,因為 NVIDIA Triton 需要關于模型的元數據。本質上,它需要網絡輸入和輸出層的名稱以及所述輸入和輸出的形狀。對于 TorchScript ,由于沒有輸入和輸出層的名稱,請使用
input__0。數據類型設置為 FP32 ,輸入格式指定為 3 、 224 、 224 的(通道、高度、寬度)。
該集合中的 TensorRT 、 Torch TensorRT 和 TensorFlow- TensorRT 工作流之間存在微小差異,其歸結為指定平臺并更改輸入和輸出層的名稱。我們為所有三個( TensorRT 、 Torch-TensorRT 或 TensorFlow-TensorRT )制作了示例配置文件。最后,添加經過訓練的模型( b )。
現在已經構建了模型存儲庫,您可以啟動服務器了。為此,您只需拉動容器并指定模型存儲庫的位置。有關使用 Kubernetes 擴展此解決方案的更多信息,請參閱 大規模部署 NVIDIA Triton 與 MIG 和 Kubernetes .
docker run --gpus=1 --rm -p 8000:8000 -p 8001:8001 -p 8002:8002 -v /full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models
隨著服務器的啟動和運行,您最終可以構建一個客戶端來滿足推理請求!
設置 NVIDIA Triton 客戶端
管道中的最后一步是查詢 NVIDIA Triton 推理服務器。您可以通過 HTTP 或 gRPC 請求向服務器發送推斷請求。在深入細節之前,安裝所需的依賴項并下載一個示例圖像。
pip install torchvision pip install attrdict pip install nvidia-pyindex pip install tritonclient[all] wget -O img1.jpg "https://bit.ly/3phN2jy"
在本文中,使用 Torchvision 將原始圖像轉換為適合 ResNet-50 模型的格式。客戶不一定需要它。我們有更全面的 image client 和為 triton-inference-server/client GitHub repo 中可用的標準用例預先制作的大量不同的客戶端。然而,對于這個解釋,我們將使用一個簡單得多的瘦客戶端來演示 API 的核心。
好的,現在您已經準備好查看 HTTP 客戶端(圖 5 )。下載客戶端腳本:
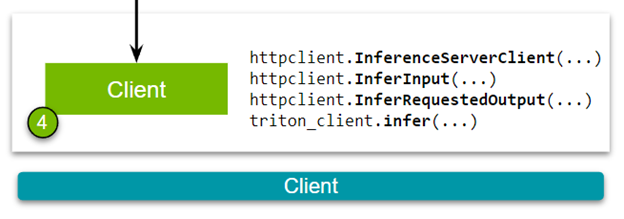
構建客戶端有以下步驟。首先,在 NVIDIA Triton 推理服務器和客戶端之間建立連接。
triton_client = httpclient.InferenceServerClient(url="localhost:8000")
其次,傳遞圖像并指定模型的輸入和輸出層的名稱。這些名稱應該與您在創建模型存儲庫時構建的配置文件中定義的規范一致。
test_input = httpclient.InferInput("input__0", transformed_img.shape, datatype="FP32")
test_input.set_data_from_numpy(transformed_img, binary_data=True) test_output = httpclient.InferRequestedOutput("output__0", binary_data=True, class_count=1000)
最后,向 NVIDIA Triton 推理服務器發送推理請求。
results = triton_client.infer(model_name="resnet50", inputs=[test_input], outputs=[test_output])
這些代碼示例討論了 Torch- TensorRT 模型的細節。不同模型(在構建客戶端時)之間的唯一區別是輸入和輸出層名稱。我們用 Python 、 C ++、 Go 、 Java 和 JavaScript 構建了 NVIDIA Triton 客戶端。有關更多示例,請參閱 triton-inference-server/client GitHub repo 。
結論
這篇文章介紹了一個端到端的推理管道,您首先使用 TensorRT 、 Torch TensorRT 和 TensorFlow TensorRT 優化訓練模型,以最大限度地提高推理性能。然后,通過設置和查詢 NVIDIA Triton 推理服務器,對服務進行建模。所有軟件,包括 TensorRT 、 Torch-TensorRT 、 TensorFlow-TensorRT 和 Triton 在本教程中討論,今天可以從 NGC 下載 Docker 容器。
?