Text-to-Speech (TTS) 是智能語音技術的核心組成部分。隨著大模型時代的到來,TTS 模型的參數量和計算量持續增長,如何高效利用 GPU 部署 TTS 模型,構建低延遲、高吞吐的生產級應用,已成為開發者日益關注的焦點。
本文將圍繞兩款 Github 社區流行的 TTS 模型——F5-TTS 和 Spark-TTS——詳細介紹運用 NVIDIA Triton 推理服務器和 TensorRT-LLM 框架實現高效部署的實踐經驗,包括部署方案的實現細節、具體使用方法及最終的推理效果等。開發者可根據不同的應用場景選擇合適的方案,并可利用性能分析工具調整配置,以最大化利用 GPU 資源。
方案介紹
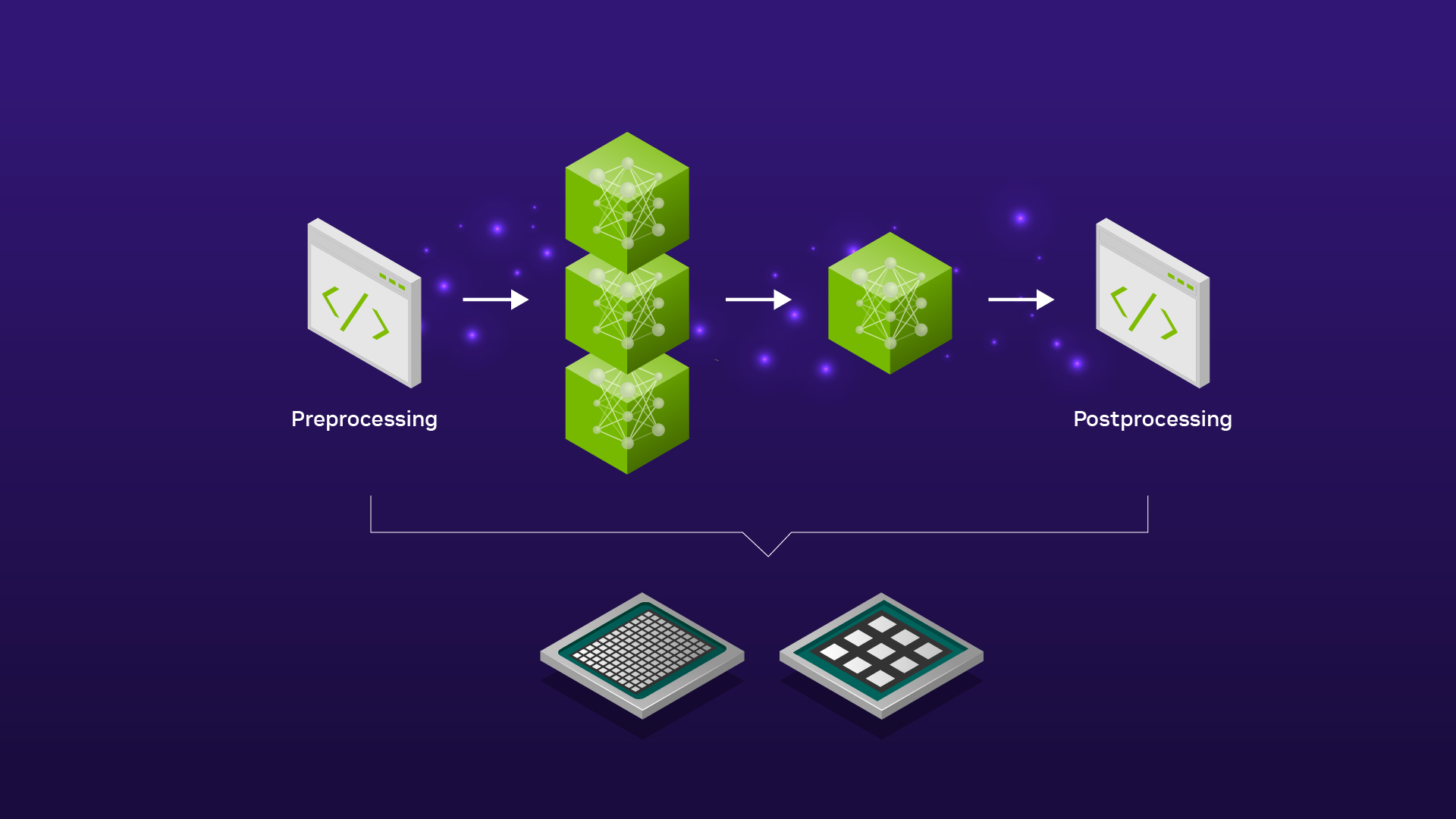
當前主流的 TTS 大模型大致可分為兩類:非自回歸擴散模型和自回歸 LLM 模型。非自回歸擴散模型因其解碼速度快,易于實現高吞吐性能;而自回歸 LLM 模型則以更佳的擬人效果和對流式合成的天然支持為特點。實踐中,常有方案將兩者結合,先使用自回歸 LLM 生成語義 Token,再利用非自回歸擴散模型生成音頻細節。

圖1:TTS 部署方案結構
F5-TTS
F5-TTS 是一款非自回歸擴散 TTS 模型,它基于 DiT (Diffusion Transformer) 和 Flow-matching 算法,移除了傳統非自回歸 TTS 模型中的 Duration 模塊,使模型能直接學習文本到語音特征的對齊。
其推理加速方案利用 NVIDIA TensorRT-LLM 加速計算密集的 DiT 模塊,并采用 NVIDIA TensorRT 優化 Vocos 聲碼器,最后通過 NVIDIA Triton 進行服務部署。
方案地址:https://github.com/SWivid/F5-TTS/tree/main/src/f5_tts/runtime/triton_trtllm
Spark-TTS
Spark-TTS 是一款自回歸 LLM TTS 模型,它采用經過擴詞表預訓練的 Qwen2.5-0.5B LLM 來預測 Speech Token,并基于 VAE Decoder 重構最終音頻。
其部署方案通過 NVIDIA TensorRT-LLM 加速基于 LLM 的語義 Token 預測模塊,并借助 NVIDIA Triton 串聯其余組件,支持離線合成與流式推理兩種模式。
方案地址:https://github.com/SparkAudio/Spark-TTS/tree/main/runtime/triton_trtllm
方案性能
我們從 WenetSpeech4TTS 測試集中選取了 26 組 Prompt Audio 和 Target Text 音頻文本對,在 Zero-shot 音色克隆任務上測試了模型的推理性能。測試細節如下:
| GPU | Dataset | Precision | Warm up |
| 單張 NVIDIA Ada Lovelace GPU | 26 prompt speech/text pairs | FP16 (F5-TTS) / BF16 (Spark-TTS) | Yes |
F5-TTS
針對 F5-TTS,我們在 Offline 模式下(即直接在本地進行推理,不涉及服務部署和請求調度)測試了 TensorRT-LLM 推理方案的性能:
測試結果如下(Batch Size 固定為 1,因當前 F5-TTS 版本暫不支持 Batch 推理;Flow-matching 推理步數固定為 16):
| Model | Concurrency | RTF | Mode |
| F5-TTS Base (Vocos) | 1 (Batch_size) | 0.04 | Offline TensorRT-LLM |
| F5-TTS Base (Vocos) | 1 (Batch_size) | 0.15 | Offline Pytorch |
如上表所示,與原生 PyTorch 實現(默認啟用 SDPA 加速)相比,NVIDIA TensorRT-LLM 方案在 Ada Lovelace GPU 上實現了約 3.6 倍的加速,每秒可生成的音頻時長從 7 秒提升至 25 秒。
Spark-TTS
對于 Spark-TTS,我們在 Client-Server 模式下(即客戶端向服務器發送請求)測試了端到端推理服務的性能。測試結果如下(Offline 模式不統計首包延遲,Streaming 模式首包音頻長度為 1 秒):
| Mode | Concurrency | First Chunk Latency (P50) | Avg Latency | RTF |
| Offline | 1 | – | 876.24 ms | 0.14 |
| Offline | 2 | – | 920.97 ms | 0.07 |
| Offline | 4 | – | 1611.51 ms | 0.07 |
| Streaming | 1 | 210.42 ms | 913.28 ms | 0.15 |
| Streaming | 2 | 226.08 ms | 1009.23 ms | 0.09 |
| Streaming | 4 | 1017.70 ms | 1793.86 ms | 0.08 |
上表結果中,LLM 模塊默認啟用了 TensorRT-LLM 的 inflight batching 模式。為模擬多路并發場景,我們基于 Python asyncio 庫實現了一個異步并發客戶端。此部署方案在 Ada Lovelace GPU 上,每秒可生成約 15 秒音頻,流式模式下的首包延遲低至 200 余毫秒。
快速上手
本節將指導您如何快速部署和測試 F5-TTS 與 Spark-TTS 模型。在此之前,建議您先克隆對應的代碼倉庫,并進入 runtime/triton_trtllm 目錄操作。
F5-TTS
詳細步驟請參考 F5-TTS/src/f5_tts/runtime/triton_trtllm/README.md 和 run.sh 腳本。
1. 最簡部署?(Docker Compose):這是啟動?F5-TTS?服務最快捷的方式。
#?根據您的模型選擇,例如?F5TTS_Base
MODEL=F5TTS_Base docker compose up(注意: F5TTS_v1_Base 的支持可能仍在開發中,請檢查項目 README)
2. 手動部署與服務啟動:如果您需要更細致地控制部署流程,可以使用?run.sh?腳本分階段執行。
#?腳本參數:<start_stage> <stop_stage> [model_name]
#?例如,執行階段0到4,使用?F5TTS_Base?模型
bash run.sh 0 4 F5TTS_Base這個命令會依次執行以下主要步驟:
- Stage 0:下載?F5-TTS?模型文件。
- Stage 1:轉換模型權重為?TensorRT-LLM?格式并構建引擎。
- Stage 2:導出?Vocos?聲碼器為?TensorRT?引擎。
- Stage 3:構建?Triton?推理服務器所需的模型倉庫。
- Stage 4:啟動?Triton?推理服務器。
3. 測試服務:服務啟動后,您可以使用提供的客戶端腳本進行測試。
- gRPC?客戶端?(數據集?Benchmark):
#?示例命令,對應?run.sh stage 5
#?具體參數(如?num_task, dataset)請根據需求調整
python3 client_grpc.py --num-tasks 1 --huggingface-dataset?yuekai/seed_tts?--split-name wenetspeech4tts --log-dir?./log_f5_grpc_bench- HTTP?客戶端(單句測試):
#?示例命令,對應?run.sh stage 6
# audio,?reference_text,?target_text?請替換為您的測試數據
python3 client_http.py --reference-audio ../../infer/examples/basic/basic_ref_en.wav \
???????????????????????--reference-text?"Some call me nature, others call me mother nature."?\
???????????????????????--target-text?"I don\'t really care what you call me. I\'ve been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring."4. Offline TensorRT-LLM 基準測試: 如果您希望直接測試 TensorRT-LLM 在 Offline 模式下的性能(不通過 Triton 服務),可以執行 run.sh 中的 Stage 7。
#?此命令對應?run.sh stage 7
#?環境變量如?F5_TTS_HF_DOWNLOAD_PATH, model,?vocoder_trt_engine_path, F5_TTS_TRT_LLM_ENGINE_PATH
#?通常在?run.sh?腳本頂部定義,請確保它們已正確設置或替換為實際路徑。
batch_size=1
model=F5TTS_Base?#?示例模型名稱
split_name=wenetspeech4tts
backend_type=trt
log_dir=./log_benchmark_batch_size_${batch_size}_${split_name}_${backend_type}
#?確保以下路徑變量已設置,或直接替換
# F5_TTS_HF_DOWNLOAD_PATH=./F5-TTS (示例)
# F5_TTS_TRT_LLM_ENGINE_PATH=./f5_trt_llm_engine (示例)
#?vocoder_trt_engine_path=vocos_vocoder.plan?(示例)
rm?-r?$log_dir?2>/dev/null
# ln -s ... #?符號鏈接通常在?run.sh?中處理,按需創建
torchrun?--nproc_per_node=1 \
benchmark.py --output-dir?$log_dir?\
--batch-size?$batch_size?\
--enable-warmup \
--split-name?$split_name?\
--model-path?$F5_TTS_HF_DOWNLOAD_PATH/$model/model_1200000.pt \
--vocab-file?$F5_TTS_HF_DOWNLOAD_PATH/$model/vocab.txt \
--vocoder-trt-engine-path?$vocoder_trt_engine_path?\
--backend-type?$backend_type?\
--tllm-model-dir?$F5_TTS_TRT_LLM_ENGINE_PATH?||?exit?1Spark-TTS
詳細步驟請參考?Spark-TTS/runtime/triton_trtllm/README.md?和?run.sh?腳本。
1. 最簡部署 (Docker Compose):
docker compose up2. 手動部署與服務啟動: 使用 run.sh 腳本進行分階段部署。
#?腳本參數:<start_stage> <stop_stage> [service_type]
#?service_type?可為?'streaming'?或?'offline',影響模型倉庫配置
#?例如,執行階段0到3,部署為?offline?服務
bash run.sh 0 3 offline此命令會執行:
- Stage 0:下載?Spark-TTS?模型。
- Stage 1:轉換模型權重并構建?TensorRT?引擎。
- Stage 2:根據指定的?service_type?(streaming/offline)?創建?Triton?模型倉庫。
- Stage 3:啟動?Triton?推理服務器。
3. 測試服務 (Client-Server 模式):服務啟動后,可使用客戶端腳本進行測試。
- gRPC?客戶端?(數據集?Benchmark):此命令對應?
run.sh?中的?stage 4。
#?示例:測試?offline?模式,并發數為2
# bash run.sh 4 4 offline
#?其核心命令如下:
num_task=2
mode=offline?#?或?streaming
python3 client_grpc.py \
????--server-addr?localhost \
????--model-name?spark_tts?\
????--num-tasks?$num_task?\
????--mode?$mode?\
????--huggingface-dataset?yuekai/seed_tts?\
????--split-name wenetspeech4tts \
????--log-dir?./log_concurrent_tasks_${num_task}_${mode}- 單句測試客戶端:此命令對應?run.sh?中的?stage 5。
- Streaming?模式?(gRPC):# bash run.sh 5 5 streaming
#?其核心命令如下:
python client_grpc.py \
????--server-addr?localhost \
????--reference-audio ../../example/prompt_audio.wav \
????--reference-text $prompt_audio_transcript?\
????--target-text $target_audio_text?\
????--model-name?spark_tts?\
????--chunk-overlap-duration 0.1 \
????--mode streaming4. Offline?模式?(HTTP):?# bash run.sh 5 5 offline
#?其核心命令如下:
python client_http.py \
????--reference-audio ../../example/prompt_audio.wav \
????--reference-text $prompt_audio_transcript?\
????--target-text $target_audio_text?\
????--model-name?spark_tts兼容 OpenAI 格式的 API
許多開源對話項目 (如 OpenWebUI)已支持 OpenAI 格式的 TTS API。為方便開發者集成,我們提供了兼容 OpenAI API 的服務,用法如下:
git?clone?https://github.com/yuekaizhang/Triton-OpenAI-Speech.git
cd?Triton-OpenAI-Speech
docker compose up
curl?$OPENAI_API_BASE/audio/speech \
????-H?"Content-Type: application/json"?\
????-d?'{
????"model": "spark_tts",
????"input":?$target_audio_text,
????"voice": "leijun",
????"response_format": "pcm"
????}'?| \
sox -t raw -r 16000 -e signed-integer -b 16 -c 1 - output3_from_pcm.wav
總結
無論是 F5-TTS 或是 Spark-TTS,都可以看到 NVIDIA Triton 推理服務器和 TensorRT-LLM 框架可以大幅提升 TTS 模型的推理速度,也方便開發者進行模型部署。我們將持續增加對更多語音多模態模型的部署支持。
除了 TTS,NVIDIA 技術團隊也為多種社區流行的多模態模型開發了最佳實踐,詳細方案介紹以及教程,請參閱 mair-hub項目。
近期我們還將舉辦一場和該主題相關的在線研討會,歡迎大家報名參加,共同交流和探討。
活動信息