
NVIDIA Blackwell 平臺的推出開啟了生成式 AI 技術進步的新時代。其最前沿是新推出的 GeForce RTX 50 系列 GPU,適用于 PC 和工作站,配備具有 4 位浮點計算 (FP4) 的第五代 Tensor Cores,是加速 Black Forest Labs 的 FLUX 等高級生成式 AI 模型的必備。
隨著新的圖像生成模型力求達到速度、準確性、更高分辨率和復雜的提示依從性,它們變得越來越大、越來越復雜。要在 PC 和工作站的本地推理中部署這些大型復雜模型,超越 16 位和 8 位計算的優勢在于。
Blackwell 與 NVIDIA TensorRT 推理工具軟件生態系統相結合,可提供易于使用的庫,這些庫支持用于推理的 FP4 量化和部署,具有出色的性能和質量。
實現這一目標并非易事。為了利用 Blackwell 中的 4 位硬件創新,本文將深入探討我們如何使用 NVIDIA TensorRT Model Optimizer 中復雜的 PTQ 和 QAT 技術,將 FLUX 模型成功量化為 FP4 權重。我們還將介紹如何將量化模型導出到 ONNX,以及 TensorRT 推理庫如何處理量化運算符,以便將端到端推理旅程示例化為 TensorRT DemoDiffusion。最后,我們將討論如何使用熱門的 GenAI 發行版 ComfyUI 在 RTX 50 系列 GPU 上本地試用此功能。
量化模型
在 FLUX-1.Dev 中,Transformer 主干是我們的主要優化目標,因為在運行 28 個推理步驟時,它在 NVIDIA GeForce RTX 5090 上占總推理延遲的 98%。因此,降低 Transformer 的計算成本有望大幅提升性能。
我們使用 TensorRT-ModelOPT 量化了所有 Transformer 層,但最終輸出層和嵌入層除外。雖然 FP4 訓練后量化最初會導致圖像質量輕微下降 (尤其是在小文本和數字中) 和指標輕微下降 (例如 Image Reward 和 CLIP-IQA) ,但我們通過使用基于蒸餾的 QAT 方法和來自 FLUX-1.Dev 的合成數據微調 FP4 量化模型來解決這些問題。此微調步驟成功恢復了圖像清晰度,并改進了評估指標。
我們的蒸餾流程使用 BF16-precision 模型作為教師,使用 FP4-quantized 模型作為學生。此設置使低精度學生模型能夠有效地從高精度教師那里學習,從而提高準確性和視覺質量。
此外,我們在 FP4 量化基礎上應用了先進的 PTQ 方法 SVDQuant,從而實現了與 QAT 相媲美的質量提升,進一步縮小了量化模型和全精度模型之間的差距。
QAT 和 SVDQuant 均可提供與 BF16 基本匹配的準確度的量化模型,并且 ModelOPT v0.27 支持這兩種方法。兩者之間的選擇取決于用戶要求:
- QAT:提供簡單的部署路徑,沒有額外的運行時開銷,但在訓練期間需要額外的計算資源。
- SVDQuant:消除了額外微調 (training-free) 的需求,但它增加了部署復雜性并引入了一些運行時開銷,對推理性能略有影響。
用戶可以選擇 QAT (以犧牲額外的前期訓練工作為代價) ,以最大限度提高運行時效率;也可以選擇 SVDQuant (以犧牲額外的運行時處理為代價) ,以實現更快、無訓練的部署。它們之間的質量比較如圖 2 所示。

| Model | Image Reward | CLIP-IQA | CLIP |
|---|---|---|---|
| BF16 | 1.118 | 0.926 | 30.150 |
| FP4 PTQ | 1.096 | 0.923 | 29.860 |
| FP4 QAT | 1.119 | 0.928 | 29.920 |
| FP4 SVDQ | 1.108 | 0.927 | 30.068 |
導出成 ONNX
導出 FP4 模型需要 ONNX 1.18.0 (opset 23) 。這樣可以精確定義量化節點的輸入/輸出張量和離線量化權重張量,確保順利部署。ModelOpt 的導出過程依賴于標準 ONNX DQ 節點和 TensorRT 自定義運算符的組合,以實現 FP4 量化,同時通過雙量化保持數值穩定性。
對于靜態權重量化,BF16 模型最初使用自定義 ONNX 運算符 (TRT_FP4QDQ) 導出,該運算符封裝了 BF16 權重和塊大小屬性。后處理步驟將這些自定義節點替換為結構化的兩步去量化 (DQ) 模式。
第一個 DQ 節點通過去量化預先計算的 FP8 塊級擴展張量來提取 BF16 塊級擴展因子。第二個 DQ 節點從壓縮的 FP4 量化權重和來自第一個 DQ 節點的 BF16 塊級擴展因子中重建 BF16 去量化權重。即使在 FP8 (E4M3) 的有限動態范圍內,這種雙量化方案也能確保數值穩定性。
對于動態輸入量化,TensorRT 自定義運算符 (TRT_FP4DynamicQuantize) 在運行時捕獲 BF16 輸入,并計算 FP4 量化輸入及其 FP8 塊級擴展系數。這些張量與 FP8 塊級縮放的 FP32 縮放系數一起,通過類似的兩步 DQ 模式。第一個 DQ 節點重建 BF16 塊級擴展因子,第二個 DQ 節點將輸入去量化回 BF16。此方法可在量化 ONNX 模型的 TensorRT 部署中實現高效融合,同時保持精度,特別是對于塊級量化模型而言。
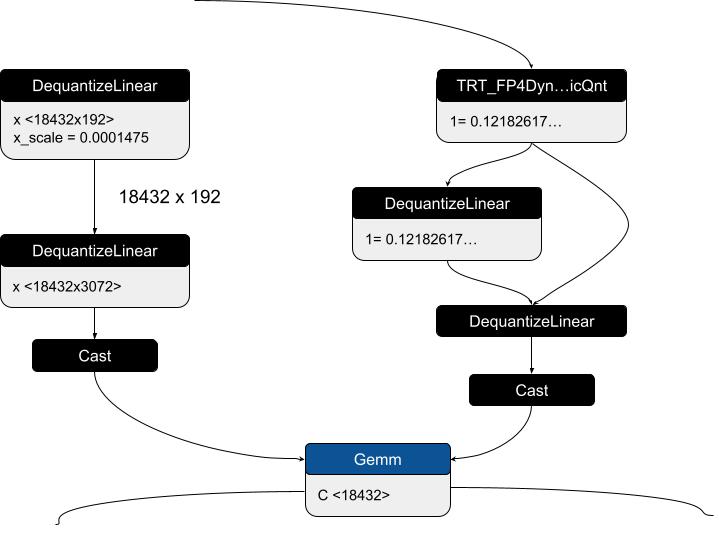
為了驗證 ONNX 導出并確保數值準確性,我們實現了 ONNX 本地函數,該函數可模擬 TRT_FP4DynamicQuantize 的行為,從而啟用 ONNXRuntime 驗證。為簡單起見,初始測試使用了 BF16 全局規模系數 (GSF),但后來擴展了本地功能,以支持 FP32 GSF,從而提高穩定性和準確性。
此外,由于量化的 ONNX 模型包含真實的量化權重而非 BF16 權重,因此有助于更輕松地在不同平臺上進行分配和部署。量化的 Torch Checkpoint 也可以重新加載,以便重新導出到 ONNX。然后,將最終的 ONNX 模型轉換為 TensorRT 引擎,以便在目標 GPU 類型上進行推理。
這種方法可確保高效的 FP4 量化,同時保持準確性、優化內存使用量并簡化大規模部署的模型分發。查看 Black Forest Labs 的 FP4 ONNX Transformer 模型示例。
使用來自 TRT 10.8 的 FP4 加速性能
NVIDIA Blackwell GPU 引入了對新數據類型 FP4 的硬件支持。借助 FP4,Blackwell 可以更大限度地提高性能,同時保持可用的任務精度。FP4 還提供優于 INT4 的推理準確性。
FP4 的一些優勢包括:
- 計算吞吐量是 FP32 的 16 倍;在 RTX5090 的理論 TOPS 下,是 FP8 的 4 倍。
- 降低 DRAM 和 L2 占用空間。
- 降低 DRAM 到 L2 到 SM 的帶寬消耗。
- 降低存儲和運輸要求。
以 GEMM 運算為例,FP4 量化由一組基元運算表示,如下所示。X/Y/W 是 GEMM 的輸入張量/輸出張量/權重張量,S 是量化運算使用的縮放系數。

在 FLUX 工作流中,Transformer 通過 FP4 推理加速。除 Transformer 開頭和結尾的層外,所有全連接 (FC) 層都在 FP4 中運行。與 FP8 相比,FC 層的性能最高可達到 FP8 的 3.1 倍。Transformer 中的多頭注意力 (MHA) 部分在 FP8 中運行。
在 FLUX Transformer 中,還有一些層 (例如 normalization 層) 未被量化為較低精度以實現更好的圖像質量。借助 Transformer 主干中的細粒度混合精度解決方案,Geforce GPU 上的最終交付性能如下所示:
| Model | 5090 fp16* | 5090 fp8 | 5090 fp4 | 4090 fp8* |
| FLUX.1-dev(包含 30 個 diffusion 步驟) | 10930.96ms | 6680.93ms | 3852.75ms | 10620.37ms |
| FLUX.1-schnell (w/ 4 diffusion steps) | 4427.43ms | 912.53ms | 590.56ms | 3385.43ms |
演示適用于 FLUX.1-Dev 和 Schnell 的 demoDiffusion 示例
Black Forest Labs FLUX 是一套圖像生成模型。TensorRT 演示 Diffusion 展示了如何加速模型套件。工作流使用為每個模型構建的 TensorRT 引擎按順序運行其組件。
輸入文本提示首先由 CLIP 和 T5 文本編碼器處理。然后,降噪器會將文本編碼器生成的文本嵌入與隱空間中的純噪聲向量一起使用。降噪器是一種擴散轉換器,它根據文本嵌入的信息對噪聲向量進行迭代降噪。然后,VAE 解碼器會將隱空間中的降噪向量處理為像素空間中的圖像。
考慮 FLUX pipeline 使用的四個模型的大小。Clip 文本編碼器、T5 文本編碼器、diffusion transformer 和 VAE 模型的大小分別為 246 MB、9.52 GB、23.8 GB 和 168 MB,總大小為 33.734 GB,適用于 FP16 模型。
由于模型較大,我們無法直接在顯存低于 24 GB 的 RTX GPU 上運行工作流。此問題可通過 low-vram 模式解決,該模式可按需加載模型,并在執行推理后卸載模型。由于模型按順序運行,我們可以顯著降低 GPU 顯存使用量。下表顯示了針對不同精度使用 low-vram 模式節省的 GPU 顯存。
| Precision | Default mode | With low-vram |
|---|---|---|
| FP16 | 39.3 GB | 23.9 GB |
| BF16 | 35.7 GB | 23.9 GB |
| FP8 | 24.6 GB | 14.9 GB |
| FP4 | 21.67 GB | 11.1 GB |
除了使用 FP4 加速標準開發工作流之外,demoDiffusion 還提供了控制圖像生成過程的方法,方法是使用 FLUX ControlNet 工作流以邊緣或深度圖的形式提供結構線索,即 depth 和 canny。用戶可以通過提供邊緣 (canny) 或深度圖以及指導圖像生成過程的文本提示來保留圖像構圖。ControlNet 工作流不同于標準開發工作流,其在 Diffusion Transformer 架構中,以 Control 圖像的形式接收額外的輸入,以使用文本和圖像信息執行降噪。depth 和 canny 控制網絡的 FP8 校正數據集位于 GitHub 上。


試用 TensorRT 10.8 demoDiffusion,以運行具有峰值 FP4 性能的 FLUX.1-Dev 和 FLUX.1-Schnell 模型。
集成 ComfyUI
熱門的圖像生成工具 ComfyUI 現已支持在 Blackwell GPU 上運行。此外,為簡化低精度推理的采用,專用的 NVIDIA NIM 推理微服務提供了易于使用的解決方案,可通過自定義節點與 ComfyUI 集成。
通過使用自定義 NVIDIA NIM 節點,用戶可以使用高質量的 FLUX 流程生成圖像,同時受益于專為在消費者桌面上高效運行而設計的優化 TensorRT 引擎。

專門的藍圖展示了如何使用 FLUX NIM 設置 ComfyUI 工作流,以生成文本到圖像。為簡化流程,我們提供了 NIM 安裝程序,便于設置 WSL2 環境和 NIM 部署。最終產品使用戶能夠在 FP4 中使用 FLUX 引擎生成高質量圖像。此外,用戶可以通過深度和 Canny 地圖引導更好地控制最終輸出,從而提高圖像精度。
開始使用
在本文中,我們了解了先進的模型如何通過量化器、編譯器和運行時的軟件工具鏈經歷多個優化步驟,以利用我們最新的 4 位硬件創新。這將生成式 AI 的強大功能帶到了云端以外的桌面或工作站。如果您擁有全新的 50 系列 RTX GPU,請使用 TensorRT demoDiffusion 嘗試整個制作流程。
?






