在過去的幾年里,使用容器來大規模部署數據中心應用程序的數量急劇增加。原因很簡單:容器封裝了應用程序的依賴項,以提供可重復和可靠的應用程序和服務執行,而無需整個虛擬機的開銷。如果您曾經花了一天的時間為一個科學或 深度學習 應用程序提供一個包含大量軟件包的服務器,或者已經花費數周的時間來確保您的應用程序可以在多個 linux 環境中構建和部署,那么 Docker 容器非常值得您花費時間。
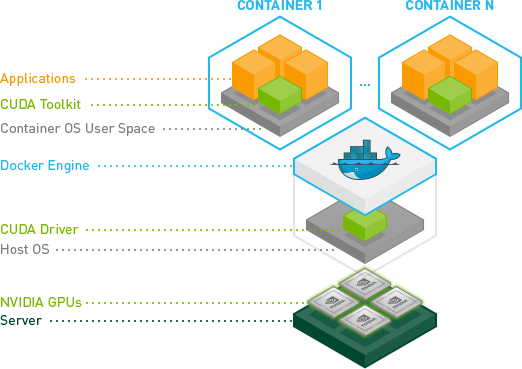
在 NVIDIA ,我們以各種方式使用容器,包括開發、測試、基準測試,當然還有生產中的容器,作為通過 NVIDIA DGX-1 的云管理軟件部署深度學習框架的機制。 Docker 改變了我們管理工作流程的方式。使用 Docker ,我們可以在工作站上開發和原型化 GPU 應用程序,然后在任何支持 GPU 容器的地方發布和運行這些應用程序。
在本文中,我們將介紹 Docker 容器;解釋 NVIDIA Docker 插件的好處;通過構建和部署一個簡單的 CUDA 應用程序的示例;最后演示如何使用 NVIDIA Docker 運行當今最流行的深度學習應用程序和框架,包括 DIGITS 、 Caffe 和 TensorFlow 。
上周在 DockerCon 2016 年 上, Felix 和 Jonathan 做了一個演講“使用 Docker 實現 GPU – 加速應用”。這是幻燈片。
[slideshare id=63346193&doc=146387dockercon16-160622172714]
Docker 簡介
Docker 容器是一種將 Linux 應用程序與其所有庫、數據文件和環境變量捆綁在一起的機制,以便在運行的任何 Linux 系統上以及在同一主機上的實例之間,執行環境始終是相同的。 Docker 容器僅為用戶模式,因此來自容器的所有內核調用都由主機系統內核處理。 在它的網站上 , Docker 這樣描述容器:
Docker 容器將一個軟件包在一個完整的文件系統中,該文件系統包含運行所需的一切:代碼、運行時、系統工具、系統庫——任何可以安裝在服務器上的東西。這保證了軟件無論其環境如何,都將始終運行相同的程序。
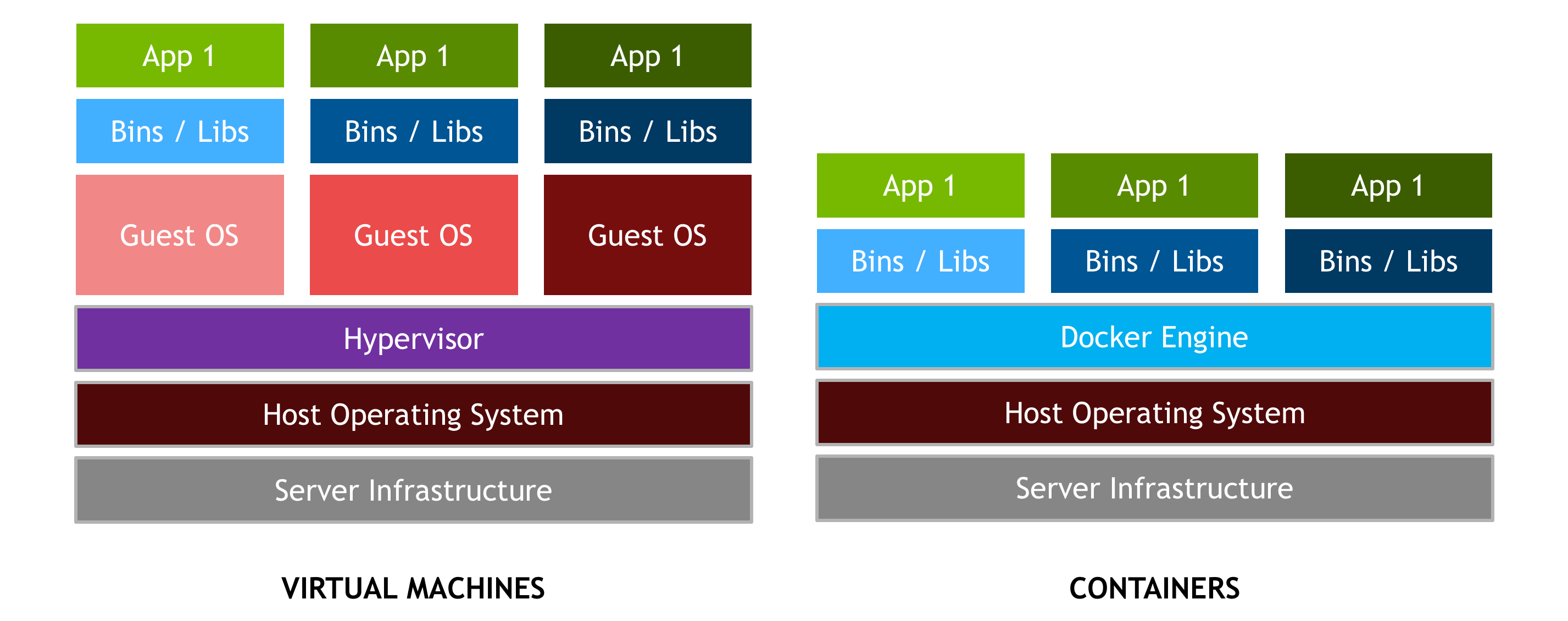
區分容器和基于 hypervisor 的虛擬機( vm )很重要。 vm 允許操作系統的多個副本,甚至多個不同的操作系統共享一臺機器。每個虛擬機可以承載和運行多個應用程序。相比之下,容器被設計成虛擬化單個應用程序,并且部署在主機上的所有容器共享一個操作系統內核,如圖 2 所示。通常,容器運行速度更快,以裸機性能運行應用程序,并且更易于管理,因為進行操作系統內核調用沒有額外的開銷。
Docker 提供了硬件和軟件封裝,允許多個容器同時在同一個系統上運行,每個容器都有自己的資源集( CPU 、內存等)和它們自己的專用依賴集(庫版本、環境變量等)。 Docker 還提供了可移植的 Linux 部署: Docker 容器可以在任何內核為 3 . 10 或更高版本的 Linux 系統上運行。自 2014 年以來,所有主要的 Linux 發行版都支持 Docker 。封裝和可移植部署對于創建和測試應用程序的開發人員以及在數據中心運行應用程序的操作人員都很有價值。
Docker 提供了許多更重要的功能。
- Docker 強大的命令行工具“ Docker build ”,使用“ Dockerfile ”中提供的描述,從源代碼和二進制文件創建 Docker 映像。
- Docker 的組件架構允許一個容器映像用作其他容器的基礎。
- Docker 提供容器的自動版本控制和標簽,優化了組裝和部署。 Docker 映像由版本化的層組合而成,因此只需要下載服務器上缺少的層。
- Docker Hub 是一項服務,它可以方便地公開或私下共享 Docker 圖像。
- 容器可以限制在一個系統上有限的一組資源(例如一個 CPU 內核和 1GB 內存)。
Docker 提供了一個 分層文件系統 ,它可以節省磁盤空間,并構成可擴展容器的基礎。
為什么是 Docker ?
Docker 容器與平臺無關,但也與硬件無關。當使用特殊的硬件,如 NVIDIA GPUs 時,這就產生了一個問題,這些硬件需要內核模塊和用戶級庫來操作。因此, Docker 本機不支持容器中的 NVIDIA GPUs 。
解決這個問題的早期解決方案之一是在容器中完全安裝 NVIDIA 驅動程序,并在啟動時映射到與 NVIDIA GPUs (例如 /dev/nvidia0 )對應的字符設備中。此解決方案很脆弱,因為主機驅動程序的版本必須與容器中安裝的驅動程序版本完全匹配。這一要求大大降低了這些早期容器的可移植性,破壞了 Docker 更重要的特性之一。
為了使 Docker 映像能夠利用 NVIDIA GPUs 實現可移植性,我們開發了 nvidia-docker ,這是一個托管在 Github 上的開源項目,它提供了基于 GPU 的可移植容器所需的兩個關鍵組件:
- 與驅動程序無關的 CUDA 圖像;以及
- Docker 命令行包裝器,在啟動時將驅動程序和 GPUs (字符設備)的用戶模式組件裝入容器。
nvidia-docker 本質上是圍繞 docker 命令的包裝器,它透明地為容器提供了在 GPU 上執行代碼所需的組件。只有在使用 nvidia-docker run 來執行使用 GPUs 的容器時才是絕對必要的。但為了簡單起見,在本文中,我們將其用于所有 Docker 命令。
安裝 Docker 和 NVIDIA Docker
在我們開始構建集裝箱化的 GPU 應用程序之前,讓我們先確保您已經安裝了必備軟件并能正常工作。您需要:
- 您系統的最新 NVIDIA drivers 。
- 碼頭工人。您可以按照 此處為安裝說明 操作。
- ` NVIDIA -docker `您可以按照 此處為安裝說明 操作。
為了幫助安裝,我們創建了一個 執行 docker 和 NVIDIA -docker 安裝的可靠角色 。 Ansible 是一個自動化機器配置管理和應用程序部署的工具。
要測試您是否準備就緒,請運行以下命令。您應該會看到與所示內容類似的輸出。
ryan@titanx:~$ nvidia-docker run --rm hello-world Using default tag: latest latest: Pulling from library/hello-world a9d36faac0fe: Pull complete Digest: sha256:e52be8ffeeb1f374f440893189cd32f44cb166650e7ab185fa7735b7dc48d619 Status: Downloaded newer image for hello-world:latest Hello from Docker. This message shows that your installation appears to be working correctly. [... simplified output ...]
現在一切都正常了,讓我們開始在容器中構建一個簡單的 GPU 應用程序。
構建集裝箱化 GPU 應用程序
為了突出 Docker 和我們的插件的特性,我將在容器中從 CUDA 工具箱示例構建 deviceQuery 應用程序。此三步方法可以應用于任何 CUDA 示例,也可以應用于您最喜歡的應用程序,只需稍作修改。
- 在容器中設置和探索開發環境。
- 在容器中構建應用程序。
- 在多個環境中部署容器。
發展環境
相當于安裝 CUDA 開發庫的 Docker 命令如下:
nvidia-docker pull nvidia/cuda
這個命令從 DockerHub 獲取最新版本的 nvidia/cuda 映像, DockerHub 是一個用于容器映像的云存儲服務。可以使用 docker run 在這個容器中執行命令。下面是在我們剛剛提取的容器中對 nvcc --version 的調用。
ryan@titanx:~$ nvidia-docker run --rm -ti nvidia/cuda nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2015 NVIDIA Corporation Built on Tue_Aug_11_14:27:32_CDT_2015 Cuda compilation tools, release 7.5, V7.5.17
如果需要 CUDA 6 . 5 或 7 . 0 ,可以指定 圖像的標記 。 Ubuntu 和 CentOS 可用的 CUDA 圖像列表可以在 NVIDIA -docker 維基 上找到。下面是一個使用 CUDA 7 . 0 的類似示例。
ryan@titanx:~$ nvidia-docker run --rm -ti nvidia/cuda:7.0 nvcc --version Unable to find image 'nvidia/cuda:7.0' locally 7.0: Pulling from nvidia/cuda 6c953ac5d795: Already exists [ … simplified layers -- ubuntu base image … ] 68bad08eb200: Pull complete [ … simplified layers -- cuda 7.0 toolkit … ] Status: Downloaded newer image for nvidia/cuda:7.0 nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2015 NVIDIA Corporation Built on Mon_Feb_16_22:59:02_CST_2015 Cuda compilation tools, release 7.0, V7.0.27
由于系統上本地只有 nvidia/cuda:7.5 映像,所以上面的 docker run 命令將 pull 和 run 操作合并在一起。您會注意到, nvidia/cuda:7.0 圖像的拉動比 7 . 5 圖像的拉動要快。這是因為兩個容器映像共享相同的基礎 ubuntu14 . 04 映像,該映像已經存在于主機上。 Docker 緩存并重用圖像層,因此只下載 CUDA 7 . 0 工具包所需的新層。這一點很重要: Docker 鏡像是逐層構建的,可以與多個鏡像共享,節省主機上的磁盤空間(以及部署時間)。 Docker 映像的這種可擴展性是一個強大的特性,我們將在本文后面討論。(了解更多 Docker 的分層文件系統 ).
最后,您可以通過運行一個執行 bash shell 的容器來探索開發映像。
nvidia-docker run --rm -ti nvidia/cuda:7.5 bash
在這個沙盒環境中盡情玩耍吧。您可以通過 apt 安裝軟件包或檢查 /usr/local/cuda 中的 CUDA 庫,但請注意,退出( ctrl + d 或 exit 命令)時,對正在運行的容器所做的任何更改都將丟失。
這種非持久性實際上是 Docker 的一個特性。 Docker 容器的每個實例都從映像定義的相同初始狀態開始。在下一節中,我們將研究一種擴展和向圖像添加新內容的機制。
構建應用程序
讓我們在容器中構建 deviceQuery 應用程序,方法是用應用程序的層擴展 CUDA 映像。一種用于定義層的機制是 Dockerfile 。 Dockerfile 就像一個藍圖,文件中的每一條指令都會給圖像添加一個新的層。讓我們看看 deviceQuery 應用程序的 Dockerfile 。
# FROM defines the base image
FROM nvidia/cuda:7.5
# RUN executes a shell command
# You can chain multiple commands together with &&
# A \ is used to split long lines to help with readability
# This particular instruction installs the source files
# for deviceQuery by installing the CUDA samples via apt
RUN apt-get update && apt-get install -y --no-install-recommends \
cuda-samples-$CUDA_PKG_VERSION && \
rm -rf /var/lib/apt/lists/*
# set the working directory
WORKDIR /usr/local/cuda/samples/1_Utilities/deviceQuery
RUN make
# CMD defines the default command to be run in the container
# CMD is overridden by supplying a command + arguments to
# `docker run`, e.g. `nvcc --version` or `bash`
CMD ./deviceQuery
有關可用 Dockerfile 指令的完整列表,請參閱 碼頭工人 。
在只有 Dockerfile 的文件夾中運行以下 docker build 命令,從 Dockerfile 藍圖構建應用程序的容器映像。
nvidia-docker build -t device-query .
這個命令生成一個名為 device-query 的 docker 容器映像,它繼承了 CUDA 7 . 5 開發映像的所有層。
運行集裝箱化 CUDA 應用程序
我們現在準備在 GPU 上執行 device-query 容器。默認情況下, nvidia-docker 將主機上的所有 GPUs 映射到容器中。
ryan@titanx:~$ nvidia-docker run --rm -ti device-query ./deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 2 CUDA Capable device(s) Device 0: "GeForce GTX TITAN X" CUDA Driver Version / Runtime Version 8.0 / 7.5 CUDA Capability Major/Minor version number: 5.2 Total amount of global memory: 12287 MBytes (12883345408 bytes) (24) Multiprocessors, (128) CUDA Cores/MP: 3072 CUDA Cores [... simplified output …] Device 1: "GeForce GTX TITAN X" CUDA Driver Version / Runtime Version 8.0 / 7.5 CUDA Capability Major/Minor version number: 5.2 Total amount of global memory: 12288 MBytes (12884705280 bytes) (24) Multiprocessors, (128) CUDA Cores/MP: 3072 CUDA Cores [... simplified output …] > Peer access from GeForce GTX TITAN X (GPU0) -> GeForce GTX TITAN X (GPU1) : Yes > Peer access from GeForce GTX TITAN X (GPU1) -> GeForce GTX TITAN X (GPU0) : Yes deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 7.5, NumDevs = 2, Device0 = GeForce GTX TITAN X, Device1 = GeForce GTX TITAN X Result = PASS
nvidia-docker 還通過 NV_GPU 環境變量提供資源隔離功能。下面的示例在 GPU 1 上運行 device-query 容器。
ryan@titanx:~$ NV_GPU=1 nvidia-docker run --rm -ti device-query ./deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 1 CUDA Capable device(s) Device 0: "GeForce GTX TITAN X" CUDA Driver Version / Runtime Version 8.0 / 7.5 CUDA Capability Major/Minor version number: 5.2 Total amount of global memory: 12288 MBytes (12884705280 bytes) (24) Multiprocessors, (128) CUDA Cores/MP: 3072 CUDA Cores [... simplified output …] deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 7.5, NumDevs = 1, Device0 = GeForce GTX TITAN X Result = PASS
因為我們只將 GPU 1 映射到容器中, deviceQuery 應用程序只能看到并報告一個 GPU 。資源隔離允許您指定允許您的容器化應用程序使用哪個 GPUs 。為獲得最佳性能,請確保在選擇 GPUs 的子集時考慮到 PCI 樹的拓撲結構。(要更好地了解 PCIe 拓撲對多 GPU 性能的重要性,請參閱此 關于與 NCCL 圖書館進行有效集體交流的博客文章 。)
集裝箱 GPU
在我們目前的例子中,我們在一個有兩個 GPUs NVIDIA X Titan 的工作站上構建并運行 device-query 。現在,讓我們在 DGX-1 服務器上部署該容器。部署容器是將容器映像從構建位置移動到運行位置的過程。部署容器的多種方法之一是 碼頭樞紐 ,這是一種云服務,用于承載容器映像,類似于 Github 托管 git 存儲庫的方式。我們用來構建 device-query 的 nvidia/cuda 映像由 Docker Hub 托管。
在將 device-query 推送到 DockerHub 之前,我們需要用 DockerHub 用戶名/帳戶對其進行標記。
ryan@titanx:~$ nvidia-docker tag device-query ryanolson/device-query
現在將標記的圖像推送到 Docker Hub 很簡單。
ryan@titanx:~/docker/blog-post$ nvidia-docker push ryanolson/device-query The push refers to a repository [docker.io/ryanolson/device-query] 35f4e4c58e9f: Pushed 170db279f3a6: Pushed 3f6d94182a7e: Mounted from nvidia/cuda [ … simplifed multiple ‘from nvidia/cuda’ layers … ]
對于使用 Docker Hub 或其他容器托管存儲庫的替代方法,請查看 docker save 和 docker load 命令。
我們推送到 Docker Hub 的 device-query 映像現在可供世界上任何支持 Docker 的服務器使用。為了在我實驗室的 DGX-1 上部署 device-query ,我只需拉取并運行映像。這個例子使用了 CUDA 8 . 0 候選版本,現在您可以通過加入 NVIDIA 加速計算開發人員計劃 來訪問它。
lab@dgx-1-07:~$ nvidia-docker run --rm -ti ryanolson/device-query Using default tag: latest latest: Pulling from ryanolson/device-query 6c953ac5d795: Already exists [ … simplified multiple ‘already exists’ layers … ] 1cc994928295: Pull complete a9e6b6393938: Pull complete Digest: sha256:0b42703a0785cf5243151b8cba7cc181a6c20a3c945a718ce712476541fe4d70 Status: Downloaded newer image for ryanolson/device-query:latest ./deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 8 CUDA Capable device(s) Device 0: "Tesla P100-SXM2-16GB" CUDA Driver Version / Runtime Version 8.0 / 7.5 CUDA Capability Major/Minor version number: 6.0 Total amount of global memory: 16281 MBytes (17071669248 bytes) (56) Multiprocessors, (64) CUDA Cores/MP: 3584 CUDA Cores [... simplified output … ] Device 7: "Tesla P100-SXM2-16GB" CUDA Driver Version / Runtime Version 8.0 / 7.5 CUDA Capability Major/Minor version number: 6.0 Total amount of global memory: 16281 MBytes (17071669248 bytes) (56) Multiprocessors, (64) CUDA Cores/MP: 3584 CUDA Cores [ … simplified output … ] deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 7.5, NumDevs = 8, Device0 = Tesla P100-SXM2-16GB, Device1 = Tesla P100-SXM2-16GB, Device2 = Tesla P100-SXM2-16GB, Device3 = Tesla P100-SXM2-16GB, Device4 = Tesla P100-SXM2-16GB, Device5 = Tesla P100-SXM2-16GB, Device6 = Tesla P100-SXM2-16GB, Device7 = Tesla P100-SXM2-16GB Result = PASS
Docker for Deep Learning 和 HPC
既然您已經了解了構建和運行一個簡單的 CUDA 應用程序是多么容易,那么運行更復雜的應用程序(如 DIGITS 或 Caffe )有多困難?如果我告訴你這就像一個命令那么簡單呢?
nvidia-docker run --name digits --rm -ti -p 8000:34448 nvidia/digits
這個命令啟動 nvidia/digits 容器,并將運行 DIGITS web 服務的容器中的 34448 端口映射到主機上的端口 8000 。
如果您在閱讀本文的同一臺機器上運行該命令,那么現在嘗試打開 http://localhost:8000 。如果在遠程計算機上執行 nvidia-docker 命令,則需要訪問該計算機上的端口 8000 。如果可以直接訪問遠程服務器,只需將 localhost 替換為遠程服務器的主機名或 IP 地址。
只需一個命令,就可以啟動并運行 NVIDIA 的數字平臺,并且可以從瀏覽器訪問,如圖 3 所示。
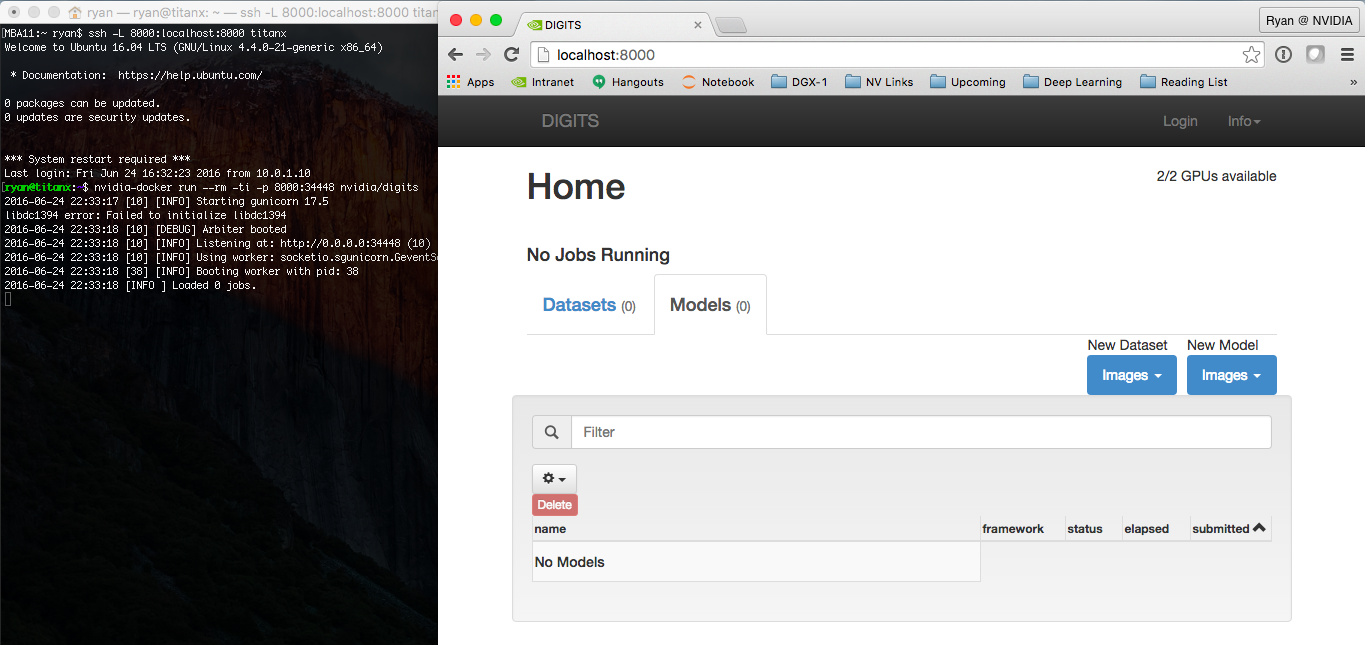
這就是為什么我們喜歡 NVIDIA 的 Docker 。作為 DIGITS 等開源軟件的開發人員,我們希望像您這樣的用戶能夠以最小的努力使用我們最新的軟件。
而且我們并不是唯一的一家:谷歌和微軟分別使用我們的 CUDA 圖片作為 TensorFlow 和 CNTK 的基礎圖片。 Google 提供 TensorFlow 的預構建 Docker 映像 通過他們的公共容器存儲庫,而微軟 為 CNTK 提供 Dockerfile 則可以自己構建。
讓我們看看啟動一個更復雜的應用程序有多容易,比如 TensorFlow ,它需要 NumPy 、 Bazel 和無數其他依賴項。是的,只是一條線!您甚至不需要下載和構建 TensorFlow ,您可以直接使用 Docker Hub 上提供的圖像。
nvidia-docker run --rm -ti tensorflow/tensorflow:r0.9-devel-gpu
運行此命令后,您可以通過運行其包含的 MNIST 訓練腳本來測試 TensorFlow :
nvidia-docker run --rm -ti tensorflow/tensorflow:r0.9-devel-gpu root@ab5f46ba17d2:~# python -m tensorflow.models.image.mnist.convolutional [tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcublas.so locally [tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcudnn.so locally [tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcufft.so locally [tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcuda.so locally [tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcurand.so locally Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes. Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes. Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes. Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes. [...]
今天就開始使用 NVIDIA Docker
在這篇文章中,我們通過擴展 nvidia/cuda 映像并在多個不同的平臺上部署我們的新容器,介紹了在容器中構建 GPU 應用程序的基本知識。當您將您的 GPU 應用程序容器化時,請使用下面的注釋與我們聯系,以便我們可以將您的項目添加到 使用 nvidia-docker 的項目列表 。
要開始并了解更多信息,請查看 nvidia-docker github 頁面 和 我們 2016 年的 Dockercon 演講 。







