
隨著大語言模型在數學和科學等領域越來越多地承擔推理密集型任務,其輸出長度也變得越來越長,有時會跨越數萬個 token。這種轉變使得高效吞吐量成為一個關鍵瓶頸,尤其是在現實世界、延遲敏感型環境中部署模型時。
為了應對這些挑戰,并使研究社區能夠推進推理模型背后的科學發展,NVIDIA 開發了 Nemotron-H-47B-Reasoning-128K 和 Nemotron-H-8B-Reasoning-128k。這兩種模型還提供 FP8 量化變體。所有模型均基于 Nemotron-H-47B-Base-8K 和 Nemotron-H-8B-Base-8K 基礎模型開發而成。
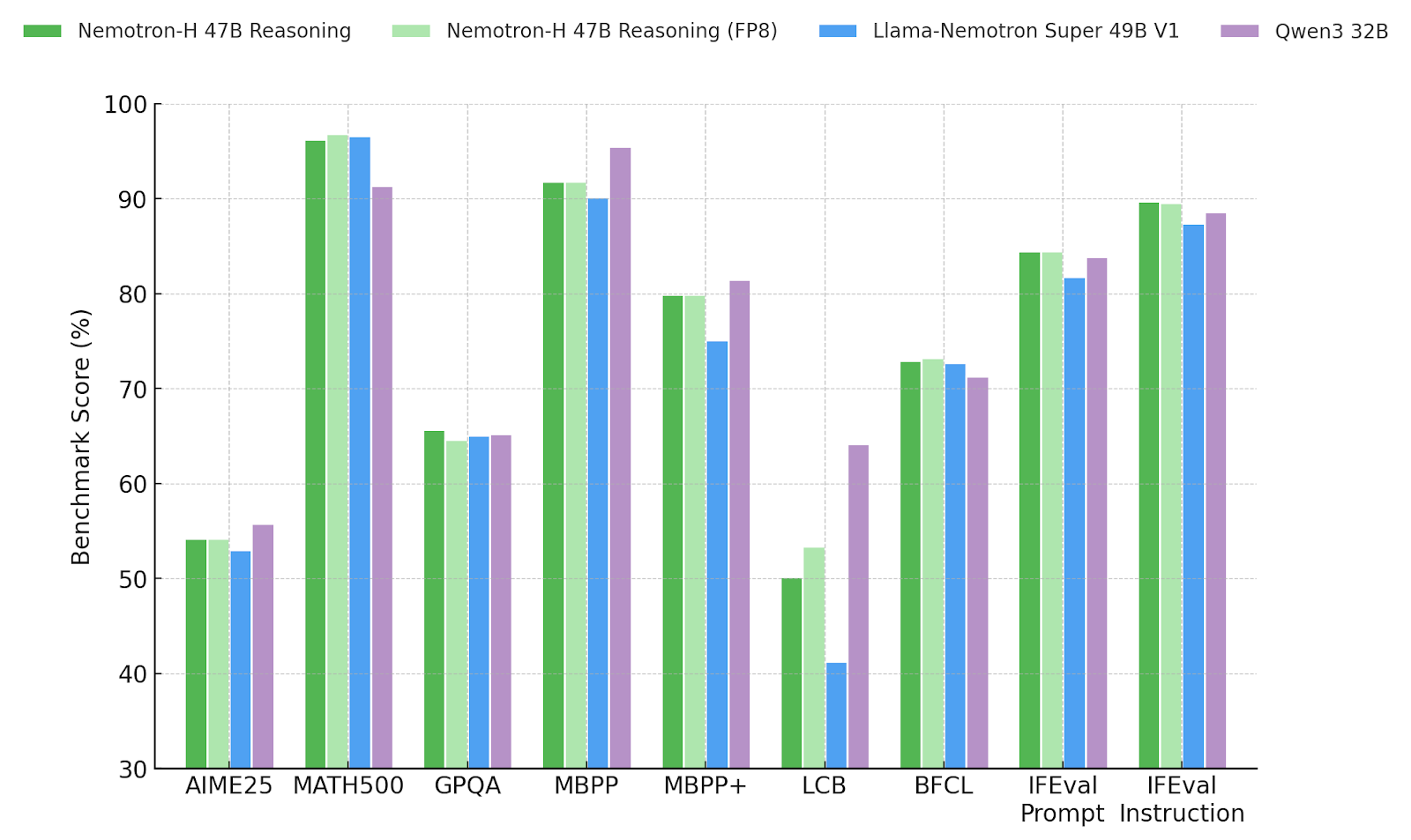
與類似大小的 Transformer 模型相比,該系列中功能最強大的模型 Nemotron-H-47B-Reasoning 可顯著加快推理時間。值得注意的是,它提供的吞吐量比 Llama-Nemotron Super 49B V1.0 高出近 4 倍,支持 128K 令牌上下文,并且達到或超過了推理密集型任務的準確性。與 Llama-Nemotron Nano 8B V1.0 模型相比,Nemotron-H-8B-Reasoning-128k 模型也顯示了類似的趨勢。
這些結果表明,像 Nemotron-H 這樣的混合架構可以像純 Transformer 模型一樣有效地進行后訓練,同時在吞吐量和上下文長度方面也具有顯著優勢。
新的 Nemotron-H 推理模型系列的一個關鍵特征是能夠在推理和非推理模式下運行。用戶可以選擇接收包含詳細中間步驟的輸出,也可以指示模型根據任務做出簡潔的響應。如果未指定偏好,模型會智能地自行選擇最佳策略。這種靈活的控制使模型能夠輕松適應各種用例。
NVIDIA 將以開放的研究許可證發布四個 Nemotron-H Reasoning 模型,我們邀請社區使用它們進行構建、測試和創新。此處提供了模型卡和模型權重:
- Nemotron-H -47B-Reasoning-128k
- Nemotron-H-47B-Reasoning-128k-FP8
- Nemotron-H -8B-Reasoning-128k
- Nemotron-H-8B-Reasoning-128k-FP8
訓練階段
訓練流程從監督式微調 (Supervised Fine-Tuning, SFT) 開始,使用包含顯式推理跟蹤 (包含在 標簽中) 的精選示例來指導模型在得出最終答案之前逐步解決問題。這些軌跡通常表示多種可能的解路徑,并鼓勵模型探索替代方案和進行迭代,從而提高準確性。但是,增加的詳細程度也會增加推理成本,尤其是對于更長的追蹤。
為了平衡這一點,我們引入了配對示例,并刪除了推理,使模型能夠學習何時以及如何直接做出響應。這種雙格式訓練有助于模型流暢地適應不同的推理要求。
第 1 階段:掌握數學、代碼 和科學理解
微調的第一階段專注于數學、科學和編碼,這些領域的顯式推理特別有價值。此處的訓練數據使用的推理與非推理樣本的比例為 5:1,其中一些示例可在 Llama-Nemotron-Post-Training-Dataset 中公開獲取。超過 30,000 個步驟 (批量大小為 256) ,該模型在內部 STEM 基準測試中表現出了一致的改進。
第 2 階段:擴大教學范圍、對話范圍和安全性
第二階段轉向指令遵循、安全對齊和多輪對話,同時繼續從階段 1 中采樣,以保持強大的 STEM 性能。該數據集更緊湊 (約小 10 倍) ,并均衡混合了推理和非推理樣本。這有助于模型在更廣泛的任務范圍內進行泛化,同時改進對推理模式切換的控制。
長語境訓練
為了支持 128K 個 token 的上下文,我們使用多達 256K 個 token 的合成序列訓練模型。這些模型通過將較短的對話 (來自第 2 階段訓練數據) 拼接在一起,并通過旨在強調遠程記憶的任務來增強這些對話來構建。例如,我們包括:
- 參考先前輪次的后續問題
- 基于長文檔的QA,需要深入理解
- 交叉參考的Multi-turn chat
- 使用干擾器執行Keyword aggregation tasks
這些示例鼓勵模型開發出可靠的長上下文注意力模式。我們在非推理模式下使用 RULER 基準測試來評估此功能。在相同的 128K-token 條件下,該模型的 RULER 分數為 84%,而 Llama-Nemotron 的 RULER 分數僅為 46%,這表明長上下文處理的顯著提升。
使用 GRPO 進行強化學習
在 SFT 之后,我們在多個階段應用了 Group Relative Policy Optimization (GRPO) 。每個階段都針對特定技能 (如 instruction following 或 tool use) ,方法是使用自動驗證器創建特定于任務的數據集,然后使用通用獎勵模型進行更廣泛的微調。
指令遵循調優
為了增強指令依從性,我們從 LMSYS Chat 數據集中對 16,000 個提示詞進行了采樣,并將其與 IFEval 式指令配對。基于規則的驗證器根據它們對每個指令的滿足程度對輸出進行評分,從而創建一個獎勵信號,使其能夠精確地優先遵循方向。
棄權的函數調用
接下來,我們使用來自 Glaive V2 和 Xlam 的大約 40,000 個有效工具使用示例進行訓練。為了建立魯棒性,我們在無法正確調用函數的情況下添加了 10,000 個負樣本,從而獎勵模型識別何時棄權。這種均衡的 50K 樣本數據集使模型能夠在使用工具時變得更加敏銳。
通過獎勵模型提供一般幫助
在最后的 RL 階段,我們使用基于 Qwen-32B 的獎勵模型 (在 RewardBench 上得分 92.8) 來提高整體響應可用性。根據 HelpSteer2 中的提示,我們運行了大約 200 個 GRPO 步驟。雖然時間很短,但這一最后階段顯著提高了輸出質量,尤其是在工具使用和指令依從性方面。
推理時的受控推理
可以使用系統提示符中的簡單控制標簽自定義 Inference-time 行為:
{'reasoning': True}觸發推理模式{'reasoning': False}觸發直接應答模式- 省略標簽可讓模型選擇
我們的 Jinja 聊天模板會檢測這些控制字符串,并相應地修改助手的響應。當存在 {'reasoning': True} 時,響應以 Assistant:<think>\n 為前綴,表示推理追蹤的開始。找到 {'reasoning': False} 時,響應以 Assistant:<think></think> 為前綴,發出非推理響應的信號。這種機制幾乎 100% 控制了推理或非推理模式。
最終結果
在數學、編碼、科學、工具使用和對話等基準測試中,Nemotron-H-47B-Reasoning-128K 的準確性與 Llama-Nemotron Super 49B V1.0 相當或更出色,并且在所有非編碼基準測試中都優于 Qwen3 32B。該模型還支持應用于所有線性層的后訓練量化,以最小的精度損失實現高效部署。最后,我們提供此量化版本的檢查點和結果,以證明其在實踐中的有效性。
無論您的應用需要透明度、精度還是速度,Nemotron-H-47B-Reasoning 都能為您提供多功能和高性能的基礎。
吞吐量比較
與類似大小的 Transformer 模型相比,Nemotron-H-47B-Reasoning 采用混合式 Mamba-Transformer 架構,可顯著加快推理時間。下圖顯示了推理式工作負載與推理吞吐量的平均基準準確性。我們使用 Megatron-LM 對 BF16 中兩個 NVIDIA H100 GPU 上可實現的最大吞吐量進行基準測試,其中每個模型都會處理簡短的輸入序列 (128 個令牌) ,并生成擴展的推理追蹤 (32K 個輸出令牌) 。為了更大限度地提高每個 GPU 的吞吐量,我們為每個模型選擇適合的最大批量大小。

我們的內部評估流程(用于確保一致的蘋果到蘋果比較)顯示,Qwen3 達到了最高的平均基準得分,緊隨其后的是 Nemotron-H-47B-Reasoning。值得注意的是,Nemotron-H 提供的吞吐量約比基于 Transformer 的基準高出 4 倍。
貢獻者
Yian Zhang、David Mosallanezhad、Bilal Kartal、Dima Rekesh、Luis Vega、Haifeng Qian、Felipe Soares、Julien Veron Vialard、Gerald Shen、Fei Jia、Ameya Mahabaleshwarkar、Samuel Kriman、Sahil Jain、Parth Chadha、Zhiyu Li、Terry Kong、Hoo Chang Shin、Anna Shors、Roger Waleffe、Duncan Riach、Cyril、Meurillon Matvei、Novikov、Daria Gitman、Evelina Bakhturina、Igor Gitman、Shubham Toshniwal、Ivan Moshkov、Wei Du、Prasoon Varshney、Makesh Narsimhan Sreedhar、Somshubra Majumdar、 Wasi Uddin Ahmad、Sean Narenthiran、Mehrzad Samadi、Jocelyn Huang、Siddhartha Jain、Vahid Noroozi、Krysztof Pawelec、Twinkle Vashishth、Oleksii Kuchaiev、Boris Ginsburg、Mostofa Patwary、and Adithya Renduchintala
?


