
MLPerf 是一個全行業人工智能聯盟,其任務是開發一套性能基準,涵蓋廣泛使用的一系列主要人工智能工作負載。最新的 mlperfv1 . 0 培訓包括視覺、語言和推薦系統,以及強化學習任務。它不斷發展,以反映最先進的人工智能應用。
NVIDIA 按照我們的傳統,提交了所有八個基準的 MLPerf v1 . 0 培訓結果。事實上,建立在 NVIDIA 人工智能平臺上的系統是唯一可以進行全面提交的商用系統。
與之前提交的 MLPerf v0 . 7 相比,我們在芯片到芯片的基礎上提高了 2 . 1 倍,在規模上提高了 3 . 5 倍。我們創造了 16 項業績記錄,其中 8 項是基于每個芯片的, 8 項是針對商用解決方案類別的大規模培訓。
| Benchmark | Max Scale Records (min) DGX SuperPod |
Per Accelerator Records (min) A100 |
| Recommendation (DLRM) | 0.99 | 15.3 |
| NLP (BERT) | 0.32 | 169.2 |
| Image classification (ResNet-50 v1.5) | 0.4 | 219.0 |
| Speech recognition – Recurrent (RNN-T) | 2.75 | 309.6 |
| Image Segmentation (3D U-Net) | 3.00 | 229.1 |
| Object detection lightweight (SSD) | 0.48 | 66.5 |
| Object detection heavyweight (Mask R-CNN) | 3.95 | 400.2 |
| Reinforcement Learning | 15.53 | 2156.3 |
(*)使用 NVIDIA 8xA100 服務器訓練時間計算 A100 的每個加速器性能,并將其乘以 8 |每個芯片的性能比較,通過比較最接近的類似規模下的性能得出其他性能。 ?
根據加速器記錄: BERT : 1 . 0-1033 | 數據鏈路管理: 1 . 0-1037 | 面罩 R-CNN : 1 . 0-1057 | ResNet50 v1 . 5 : 1 . 0-1038 | 固態硬盤: 1 . 0-1038 | RNN-T : 1 . 0-1060 | 3D U 網: 1 . 0-1053 | 迷你們: 1 . 0-1061 ?
最大刻度記錄: BERT : 1 . 0-1077 | 數據鏈路管理: 1 . 0-1067 | 面罩 R-CNN : 1 . 0-1070 | ResNet50 v1 . 5 : 1 . 0-1076 | 固態硬盤: 1 . 0-1072 | RNN-T : 1 . 0-1074 | 3D U 網: 1 . 0-1071 | 迷你們: 1 . 0-1075 ?
MLPerf 名稱和徽標是商標。有關詳細信息,請參閱 www.mlperf.org .
這是以 NVIDIA A100 GPU s 為特色的第二輪 MLPerf 訓練。我們對相同硬件的持續改進是 NVIDIA 平臺實力和持續軟件改進承諾的生動證明。與前幾輪 MLPerf 一樣, NVIDIA 工程師開發了一系列創新,以實現這些新的性能水平:
- 在所有基準上擴展 CUDA 圖形 。傳統上,神經網絡是從 CPU 以單個內核的形式啟動,在 GPU 上執行。在 MLPerf v1 . 0 中,我們在 GPU 上啟動了整個內核序列,將與 CPU 的通信最小化。
- 使用 SHARP 將節點之間的有效互連帶寬增加一倍。夏普將集合操作從 CPU 和 GPU 卸載到網絡,并消除了在端點之間多次發送數據的需要。
CUDA 圖形和銳利的增強使我們能夠將我們的規模增加到 4096 GPU 的創紀錄數字,用于解決單個人工智能網絡。
- 空間并行性使我們能夠在 8 個 GPU 上分割單個圖像,用于像 3D U-Net 這樣的大規模圖像分割網絡,并使用更多的 GPU 來獲得更高的吞吐量。
- 在硬件改進中, NVIDIA A100 GPU 上的新 HBM2e GPU 內存將內存帶寬提高了近 30% ,達到 2 TBps 。
這篇文章提供了許多用于提供出色規模和性能的優化的見解。其中許多改進在 NGC 上可用,它是 NVIDIA GPU 優化軟件的中心。您可以在實際應用程序中認識到這些優化的好處,而不只是在一旁觀察更好的基準測試分數。
大規模訓練
大規模培訓需要對系統硬件和軟件進行精確調整,以協同工作,并支持大規模出現的獨特性能要求。 NVIDIA 在這兩個方面都取得了重大進展,現在可以用于生產。
在系統方面,我們大規模培訓的關鍵組成部分是 NVIDIA DGX SuperPOD 。 DGX SuperPOD 是 HPC 和 AI 數據中心多年專業經驗的結晶。它基于 NVIDIA DGX A100 ,具有最新的 NVIDIA A100 張量核心 GPU 、第三代 NVIDIA NVLink 、 NVSwitch 和 NVIDIA ConnectX-6 VPI 200 Gbps HDR InfiniBand 。這些結合起來,使賽琳娜成為 超級計算機 500 強排行榜 中排名前五的超級計算機,其組件如下:
- 4480 NVIDIA A100 張量核 GPU s
- 560 NVIDIA DGX A100 系統
- 850 Mellanox 200G HDR InfiniBand 交換機
在軟件方面, NGC 容器版本 v 。 21 . 05 增強并支持多種功能:
- 分布式優化器支持增強。
- 使用 Mellanox HDR Infiniband 和 NCCL 2 . 9 . 9 提高了通信效率。
- 增加了銳利的支撐。 SHARP 改進了 MPI 和機器學習集體操作的性能。向 NCCL 添加了 SHARP 支持,以將所有 reduce 集體操作卸載到網絡結構中,從而減少節點之間的數據傳輸量。
工作量
在本節中,我們將深入研究針對選定的單個 MLPerf 工作負載的優化。
建議( DLRM )
推薦可以說是當今數據中心中最普遍的人工智能工作負載。 NVIDIA MLPerf DLRM 提交基于 HugeCTR ,一個 GPU 加速推薦框架,它是 NVIDIA Merlin 開放測試版框架的一部分。 HugeCTR v3 . 1 測試版增加了以下優化:
混合嵌入
將 DLRM 擴展到多個節點的主要挑戰之一是 NVLink 和 Infiniband 之間的 per- GPU all-to-all 帶寬相差約 10 倍。這使得節點間的嵌入交換成為訓練過程中的一個重要瓶頸。
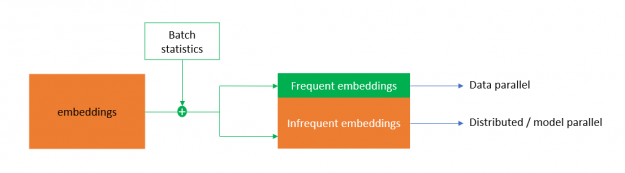
為了解決這個問題, HugeCTR 實現了混合嵌入,這是一種新的嵌入設計,在進行前向傳遞的嵌入權值交換之前,對一批類別進行重復數據消除。在后向通道中進行梯度交換之前,還可以局部減小梯度。
為實現高效的重復數據消除,混合嵌入根據類別的統計訪問頻率將類別映射為頻繁和不頻繁的嵌入。頻繁嵌入是以數據并行的方式實現的,它在一個批處理中帶走了大部分復制的類別,減少了嵌入交換的流量。不頻繁嵌入遵循分布式模型并行嵌入范式。這使 DLRM 能夠以前所未有的效率擴展到多個節點。
優化集體
所有到所有和所有減少集體延遲在擴展效率方面起著重要作用。小消息大小的多節點全對全吞吐量受到 Infiniband 消息速率的限制。為了緩解這種情況, HugeCTR 使用分層的 all-To-all 實現了融合的 NVLink 聚合,以嵌入 exchange 。
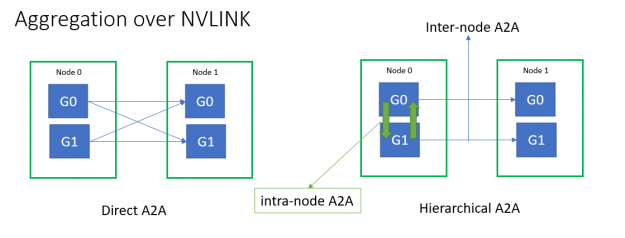
您可以從所有節點到所有節點進行優化,并進一步減少延遲:
- 直接使用本機 IB verbs API 和 SHARP 來減少庫開銷。
- 圖形可捕獲, GPU – 啟動通信以減少啟動開銷。
- 用單側躍遷協議代替雙側會合協議來減少網絡跳數。
- 使用持久通信緩沖區消除冗余的消息緩沖區副本。
- 直接在 GPU 內存上使用 NIC 原子,而不是通過 CPU 間接定向,減少了 NIC- GPU 同步延遲。
與環網相比,還使用單次減少算法優化了節點內的所有減少。
頻繁嵌入 all-reduce 和 MLP-all-reduce 融合到一個 all-reduce 操作中,以節省暴露的 all-reduce 延遲。
優化的數據讀取器
輸入管道在培訓績效中起著重要的作用。為了達到峰值 I / O 吞吐量, HugeCTR 使用 Linux 異步 I / O 庫( AIO )實現了一個完全異步的數據讀取器。由于混合嵌入要求整個批處理出現在所有 GPU 上,因此每個 GPU 的直接主機到設備( H2D )將使 PCIe 成為瓶頸。因此,使用分層方法將數據復制到 GPU 上,首先通過 PCIe 執行 H2D ,然后通過 NVLink 進行廣播。
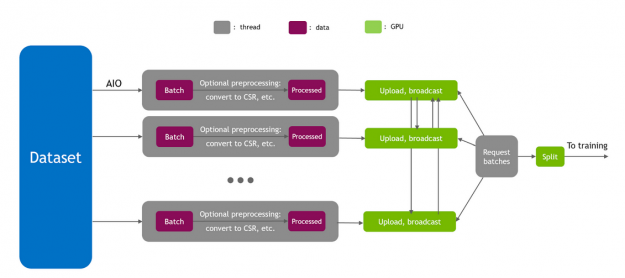
此外,來自數據讀取器的 H2D 通信可能會干擾節點間的 all-to-all 并減少通過 PCIe 的通信量。因此, HugeCTR 實現了智能數據讀取器調度以避免這種干擾。
帶嵌入的重疊 MLP
由于底層 MLP 與嵌入沒有數據依賴關系,因此底層 MLP 的幾個組件可以與嵌入重疊,以有效地利用 GPU 資源。
- 底部 MLP 正向與嵌入正向過程重疊
- 頻繁嵌入局部權值更新與所有約簡重疊
- MLP 重量更新與節間全對全重疊
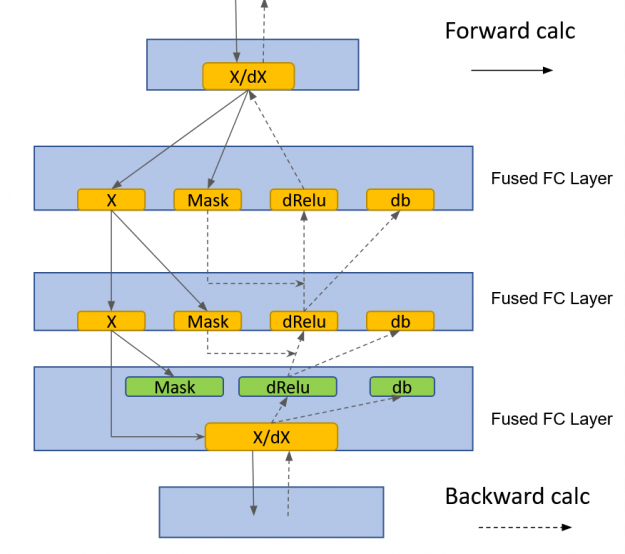
cuBLAS Lt GEMM 融合
HugeCTR 實現了一個融合的、完全連接的層,該層利用了 cublasLt GEMM 融合:
- 用于 MLP-fprop 的 GEMM + Relu +偏置融合
- GEMM + dRelu + dBias 融合治療 MLP-bprop
全迭代 CUDA 圖
為了減少啟動延遲并防止內核啟動、數據讀取器和通信流量之間的 PCIe 干擾,所有 DLRM 計算和通信內核都設計為流可捕獲。整個訓練迭代被捕獲到一個 CUDA 圖中。
通過前面的優化,我們擴展到多個節點,并在不到一分鐘的時間內在 14 個 DGX-A100 節點上完成了 DLRM 訓練任務。與之前提交的 v0 . 7 相比,這是 3 . 3 倍的加速。
NLP ( BERT )
BERT 可以說是當今 NLP 領域最重要的工作負載之一。在 MLPerf v1 . 0 版本中,我們通過以下優化改進了 v0 . 7 版本:
融合多頭注意
多頭注意塊中激活張量的大小隨序列長度的平方而增大。這會導致內存占用增加,以及由于伴隨的內存訪問操作而導致運行時間延長。我們將 softmax 、掩蔽和退出操作融合到一個內核中,包括前向傳遞和后向傳遞。通過這樣做,我們避免了對多頭注意塊中的大激活張量進行多次內存訪問操作,從而顯著提高了性能。
有關詳細信息,請參閱 NVIDIA Apex 庫中的 SelfMultiheadAttn 。
分布式 LAMB
在這一輪 MLPerf 中,我們實現了分布式 LAMB 。在分布式 LAMB 中,梯度首先在每個 DGX-A100 節點內的八個 GPU 上分裂。接下來是八個獨立組中的節點之間的 all reduce 。在這個操作之后,每個 GPU 都有 8 個塊中的一個,這些塊構成了全約化梯度張量, LAMB 優化器在 1 / 8 上運行th全梯度張量。
必要時,通過計算局部范數并執行 all-reduce 操作來計算梯度范數。在優化器之后,在每個節點上執行一個 intranode all gather 操作,這樣每個 GPU 都有完整的更新參數張量。繼續執行下一次迭代的前向傳遞。
分布式 LAMB 極大地提高了單節點和多節點配置的性能。有關更多信息,請參閱 Apex 庫中的 DistributedFusedLAMB 。
無同步訓練
在某些情況下, GPU 的執行取決于在 CPU 上存儲或計算的某個值。一個例子是當一個特定的張量有一個不同的大小,這取決于每次迭代的計算。因為張量大小信息保存在 CPU 上, GPU 和 CPU 之間必須有一個同步,才能傳遞張量大小信息以進行適當的緩沖區分配。
我們的解決方案是使用具有固定大小的張量,但使用單獨的布爾掩碼指示哪些元素是有效的。這種方法不需要 CPU – GPU 同步,因為張量大小是已知的。當后續計算必須知道張量的實際大小時,對于平均運算,布爾掩碼的元素可以在 GPU 上求和。
盡管這種方法導致對 GPU 內存的訪問稍微多一些,但它比在關鍵路徑中進行 CPU 同步要快得多。這種優化為小的本地批處理大小帶來了顯著的性能提升,對于我們的 max-scale 配置就是這樣。這是因為 CPU 同步無法跟上小批量的快速 GPU 執行。

CPU – GPU 同步的另一個來源是保存在 CPU 上的數據,例如學習率或其他可能的優化器狀態。我們將所有優化器狀態保留在 GPU 上,以便分布式 LAMB 實現無同步執行。
通過這些優化,我們消除了訓練周期中 CPU 和 GPU 之間的所有同步。唯一的同步是發生在評估點上的同步,以將每個評估點的評估精度實時記錄到一個文件中。
CUDA graphs in PyTorch
傳統上, CPU 單獨啟動每個 GPU 內核。一般來說,即使 GPU 內核對大批量處理做更多的工作, CPU 內核啟動工作和相關的 CPU 開銷保持不變,除非 CPU 調度發生變化。因此,對于較小的本地批處理大小, CPU 開銷可能成為一個重要的性能瓶頸。這就是我們在 MLPerf 中的 max-scale BERT 配置中發生的情況。
除此之外,當 CPU 執行成為瓶頸時, CPU 執行的變化會導致每個迭代的所有 GPU 的運行時不同。當工作負載擴展到多個 GPU 時(在本例中是 4096 個 GPU ),這會帶來很大的同步開銷。每個 GPU 同步每個梯度縮減的迭代,迭代時間由最慢的工人決定。
BERT 圖形是一種功能,它允許一次啟動整個內核序列,消除了內核執行之間的 CPU 開銷。 CUDA 圖形最近在 PyTorch 中可用。通過圖捕獲模型,我們消除了 CPU 開銷和伴隨的同步開銷。對于我們的 max-scale CUDA 配置, CUDA Graphs 實現本身就帶來了 1 . 7 倍的性能提升。
一炮皆減銳利
夏普顯著提高了 BERT 的集體性能,特別是我們的最大規模配置。對于這種 BERT 配置,夏普的端到端性能提升了 17% 。
圖像分類( ResNet-50 v1 . 5 )
ResNet-50 是 MLPerf 工作負載中的老手。在這個版本的 MLPerf 中,我們繼續通過改進 cuDNN 中的 Conv + BN + ReLu 融合內核來優化 ResNet ,并進行以下優化:
DALI 優化
在 ResNet-50 的大范圍(> 128 個節點)中,我們將每 GPU 的本地批大小減少到非常小的值。這通常會導致低于 20 毫秒的迭代時間。為了減少數據管道的開銷,我們引入了輸入批處理乘數( IBM )。大批量的 DALI 吞吐量高于小批量。為了利用這個事實,我們創建了比本地批大小大得多的超級批。對于每個迭代,我們從這些超級批中導出所需的樣本,從而增加 DALI 處理吞吐量并減少數據管道開銷。
在這些小的迭代時間中,無間隙和連續執行是實現完美縮放的關鍵。 通過提示預分配 DALI 緩沖區 是我們引入的另一個功能,用于在探索數據集時減少動態 GPU 內存分配的開銷。
MXNet 融合了 BN + ReLu 和 BN + Add + ReLu 性能優化
對于 ResNet-50 ,批處理范數( BN )是網絡迭代時間的重要部分。通過矢量化、緩存友好的內存遍歷和減少量化,優化了 MXNet 中融合的 BN + ReLu 和 BN + Add + ReLu 核。
改進的 MXNet 依賴引擎改進
新的 MXNet 依賴引擎提供了一種異步方法來調度 GPU 上的工作,減少了主機( CPU )開銷和抖動,例如 MXNet 和 Horovord 握手產生的開銷。
在新的依賴關系引擎中,只要在 GPU 上安排了工作,操作就會更新依賴關系,而不是在工作完成時。后續操作必須執行同步以確保正確性。通過消除對同步的需要并使用 cudaStreamWait 事件來管理依賴關系,這一點得到了進一步的增強。
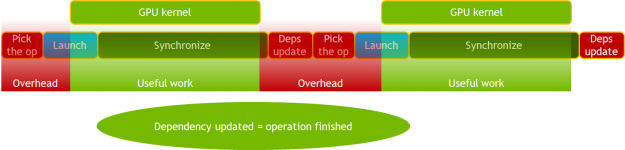
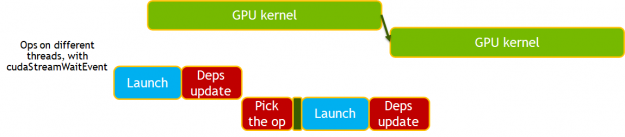
圖像分割( 3D U 網)
U-Net3D 是這一輪 MLPerf 訓練的兩個新工作量之一。我們使用了以下優化:
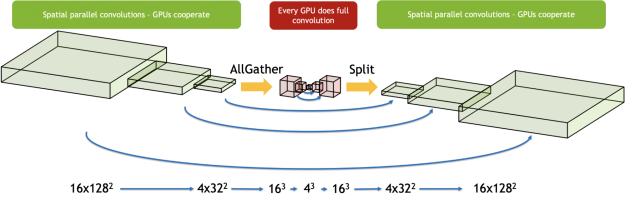
空間平行性
在 3du-Net 中,由于訓練數據集中的樣本數相對較小,因此在原始數據并行性的情況下,其可伸縮性有一個基本的限制。為了打破這一限制,我們使用空間平行性將單個圖像分割成八個 GPU s 。在反向傳播結束時,可以像往常一樣減少每個分區的梯度,以得到合成的梯度,然后可以用來計算權重梯度。
實現空間并行卷積的簡單方法是在運行卷積之前從相鄰的 GPU 傳輸光環信息。然而,為了提高效率,我們實現了一個不同的方案,在這個方案中,我們從相鄰的 GPU 轉移光環,同時運行主要的內部卷積。這個主卷積的誤差項是用光暈獨立計算出來的,再加上它就得到了結果。通過隱藏傳輸成本,我們看到了比單純方法更好的擴展效率。
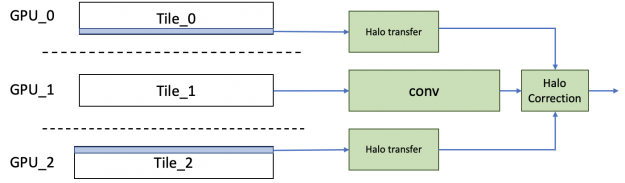
對于反向傳播,類似地, dgrad 操作所需的光暈與權值梯度和數據梯度的計算并行傳輸。然后,為數據梯度傳輸的光暈被重新用于計算權重和數據梯度的校正項。
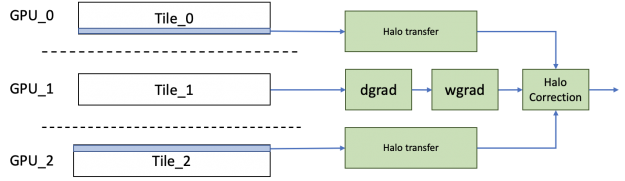
3D U-NET 在網絡中間具有瓶頸區域,其激活大小小得多,不適合于空間并行性。我們使用了一種混合方法,只對從中受益的層使用空間并行性。我們從瓶頸區域之前的所有 GPU 中收集樣本的激活,并在每個 GPU 上連續執行這些層。當合作變得有益時,我們又把工作分給了 GPU 。這確保了我們為網絡的每個區域分別做出最佳選擇。
異步求值
在參考代碼中,求值貢獻了大量的時間。因為評估可以與訓練同時運行,所以我們為運行評估分配了專用節點。
為了將評估完全隱藏在訓練周期之后,我們使用了空間并行來加速驗證步驟。此外,由于 evaluation 使用同一組圖像,因此這些圖像只加載一次,然后緩存在 GPU 內存中。
因為評估要到培訓的三分之一時間才會開始,所以評估節點有足夠的時間加載、處理和緩存數據集,以及初始化所有必需的庫。
在訓練周期結束時,訓練節點使用 InfiniBand 將模型快速傳輸到評估節點,并繼續運行后續的訓練迭代。傳遞模型參數后,求值節點運行求值。在評估結束時,如果達到目標精度,評估節點將與訓練節點通信。
添加的評估節點數量剛好足以將整個評估周期隱藏在訓練周期之后。
![Asynchronous evaluation runs concurrently with training on dedicated nodes.]](https://developer-blogs.nvidia.com/wp-content/uploads/2021/06/Asynchronous-evaluation-schedule-625x217.png)
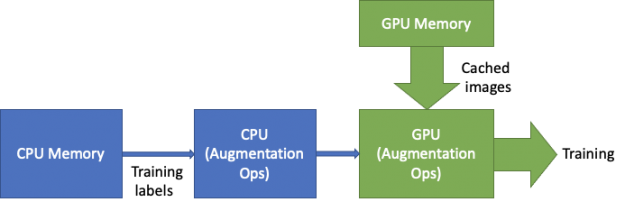
數據加載器
我們通過兩種方式優化了數據加載器:優化擴充和緩存數據集。
Augmentations :由于數據集的小尺寸, 3D U-Net 需要大量的擴充。最昂貴的操作之一是我們稱之為“有偏見的作物”。與隨機裁剪相反,有偏裁剪以給定的概率選擇具有正標簽的區域。這要求每次選擇昂貴的路徑時,都要對標簽上的三維連接組件進行大量計算。為了避免每次加載示例時都計算連接的組件,結果將緩存在主機中并重用,以便只計算一次。
數據加載 :隨著使用新特性的培訓變得更快, I / O 開始成為瓶頸。為了緩解這種情況,我們將整個圖像數據集緩存在 GPU 內存中。這將從關鍵數據加載程序路徑中移除 PCIe 和 I / O 。當圖像從大而高帶寬 GPU 內存加載時,標簽從 CPU 加載以執行增強。
通道上次布局支持
因為 Channels Last 布局對于卷積內核更有效,所以在 MXNet 中添加了對 Channels Last 格式的本機支持。這避免了模型中需要的任何額外轉置,以利用高效的 GPU 內核。
優化的 cuDNN 內核
3du-Net 有多個編碼器和解碼器層,信道數很小。使用 256 的典型平鋪大小× 64 對于這些操作中使用的內核,會產生顯著的分片大小量化效果。為了優化這一點, cuDNN 添加了一些內核,這些內核針對較小的磁貼大小進行了優化,具有更好的緩存重用性。這有助于 3D-U-Net 實現更好的計算利用率。
除了這些優化之外, 3du-Net 還受益于優化的 BatchNorm + ReLu 激活內核。使用 BatchSize 值 1 重復運行 BatchNorm 內核以獲得實例 Norm 功能。在 MXNet 、 CUDA 圖形和 SHARP 中實現的異步依賴引擎也顯著提高了性能。
通過對 3D U-Net 進行一系列優化,我們將 DGX 擴展到 100 個 A100 節點( 800 GPU s ),在 80 個節點( 640 GPU s )上運行訓練,在 20 個節點( 160 GPU s )上運行評估。與單節點配置相比, 100 節點的最大規模配置獲得了 9 . 7 倍以上的加速比。
目標檢測(輕量級)( SSD )
這是輕量 SSD 第四次出現在 MLPerf 中。在這一輪中,評估時間表被改為每五個時代進行一次,從第一個時代開始。在前幾輪中,評估計劃從第 40 個時代開始。即使有額外的計算要求,我們也將提交時間加快了 x1 . 6 以上。
SSD 由許多較小的卷積層組成。如前所述, MXNet 依賴引擎 CUDA 圖的改進以及 SHARP 的啟用對基準測試尤其有影響。
更高效的配置
深度學習模型的訓練時間是一個多變量函數。在其最基本的形式中,方程式如下:
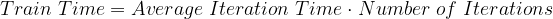
目標是最小化
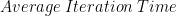

另一方面,
| Batch size | Iterations per epoch (1) | Epochs to convergence (2) | Total iterations |
| 1024 | 115 | 50 | 5750 |
| 2048 | 58 | 65 | 3770 |
| 3072 | 39 | 75 | 2925 |
| 4096 | 29 | 90 | 2610 |
( 1 ) MS-COCO 歷元大小為 117266 張圖像 (2 ) 經驗值
與我們使用 2048 批量大小的 v0 . 7 提交相比, v1 . 0 批量大小為 3072 ,需要的迭代次數減少了 22% 。因為較大的迭代只慢了 20% ,結果是收斂速度快了 8% 。
在本例中,將批處理大小改為 4096 而不是 3072 將導致更長的訓練時間。迭代次數減少 11% 并不能彌補每次迭代額外 20% 的運行時間。
優化評價
評估可分為三個階段:
- Inference :使用經過訓練的模型對驗證數據集進行預測。在 GPU 上運行。
- Prep : [NEED DESCRIPTION]
- Scoring :根據基本事實評估推理結果。在 CPU 上異步運行。
v1 . 0 中的新評估為基本提交添加了八個驗證周期。更糟糕的是,對 epoch 訓練時間的改進意味著得分需要不到 2 秒或 5 個 epoch 的訓練時間。否則,它不會被完全隱藏,任何訓練時間的改進都是毫無意義的。
為了提高推理時間,我們保證了推理圖是靜態的。我們改進了非最大值抑制實現,并將用于過濾負檢測的布爾掩碼移到圖的外部。靜態圖節省了內存重新分配時間,使訓練和推理上下文之間的切換更快。
對于得分,我們使用 nv-cocoapi ,這是一個 C ++實現的 cocoapi 和 60X 倍的速度更快。對于 v1 . 0 ,我們通過多線程結果累積、更快的索引排序和緩存基本真相數據結構,將 nv-cocoapi 的性能提高了 2 倍。
目標檢測(重量級)( Mask R-CNN )
我們通過以下技術優化了目標檢測:
CUDA graphs in PyTorch
深度學習框架使用 GPU 加速計算,但大量代碼仍在 CPU 內核上運行。 CPU 代碼處理類似張量形狀的元數據,以準備啟動 GPU 內核所需的參數。處理元數據的成本是固定的,而 GPU 所做的計算工作的成本與批處理大小正相關。對于大批量, CPU 開銷占總運行時成本的百分比可以忽略不計。在小批量時, CPU 開銷可能會大于 GPU 運行時。當這種情況發生時, GPU 在內核調用之間處于空閑狀態。
此問題可以在 Nsight Systems 時間軸圖上確定。下圖顯示了在繪圖前每 – GPU 批大小為 1 的掩碼 R-CNN 的“主干”部分。綠色部分顯示 CPU 負載,藍色部分顯示 GPU 負載。在這個配置文件中,您可以看到 CPU 在 100% 負載時達到最大值,而 GPU 大部分時間處于空閑狀態。 GPU 內核之間有很多空白。

CUDA graph 是一個工具,當張量形狀是靜態的時,它可以自動消除 CPU 開銷。在第一步中捕獲所有內核調用的完整圖。在隨后的步驟中,整個圖形通過一個操作啟動,消除了所有的 CPU 開銷。 PyTorch 現在支持 CUDA 圖形,我們使用它來加速 MLPerf 1 . 0 的 Mask R-CNN 。
![With CUDA graph, the entire graph is launched with a single op, eliminating all the CPU overhead.]](https://developer-blogs.nvidia.com/wp-content/uploads/2021/06/CUDA-graph-optimization.png)
通過作圖,我們可以看到 GPU 內核被緊密打包, GPU 利用率仍然很高。圖示部分現在以 6 毫秒而不是 31 毫秒的速度運行,速度提高了 5 倍。我們主要只是繪制 ResNet 主干,而不是整個模型。即使在那時,我們看到整個基準的提升超過了 2 倍。
刪除同步點
有許多 PyTorch 模塊使主進程等待 GPU 完成之前啟動的所有內核。這可能對性能有害,因為當 CPU 可以啟動更多內核時,它會處于空閑狀態。 CPU 可以在低開銷段中領先于 GPU ,并開始從后續段啟動內核。只要總的 CPU 開銷小于總的 GPU 內核時間, CPU 就永遠不會成為瓶頸,但當引入同步點時,瓶頸就會中斷。而且,具有同步點的模型段不能用 CUDA 圖形表示,因此刪除同步非常重要。
我們為 mlperf1 . 0 做了一些工作。例如, Trang . RangPrm 改寫為使用 CUB 而不是推力,因為后者是同步 C ++模板庫。這些改進在最新的 NGC 容器中提供。
刪除所有同步將 CUDA 圖中的提升從 1 . 6x 提高到 2 . 5x 。
異步求值
我們提交的 mlperf0 . 7 進行了異步評估,但速度不夠快,無法跟上優化后的培訓。每個歷元的評估時間為 18 秒,其中 4 秒是完全暴露的時間。如果不更改評估代碼,我們的 at-scale 提交的時間會慢大約 100 秒。
在三個評價階段中,推理和準備占了所有的暴露時間。為了加快推理速度,我們將測試圖像緩存在 GPU 內存中,因為它們永遠不會改變。我們將準備階段移到后臺進程池中,因為測試數據集中的每個樣本都可以獨立處理。我們在兩個背景過程中同時對分割模板和框進行評分。這些優化將每個歷元的計算時間減少到了~ 4 秒。
數據加載器優化
該組件在訓練期間加載和增強圖像。在我們提交的 mlperf0 . 7 中,所有數據加載工作都由 CPU 內核完成。舊的 dataloader 不夠快,無法跟上優化后的培訓。為了解決這個問題,我們開發了一個混合數據加載器。
混合數據加載器對 CUDA 上的圖像進行解碼,然后使用 Torchvision 對 GPU 進行圖像增強。為了完全隱藏數據加載的代價,我們將 loss 后向調用移到主訓練循環中的 load next image 調用。由于 CPU 圖形啟動, CPU 在丟失向后調用后空閑了幾毫秒。這是足夠的時間解碼下一個圖像。在 GPU 完成反向傳播之后,它們處于空閑狀態,而優化器在梯度上進行所有減少。在此空閑時間內, dataloader 執行圖像增強工作。
ResNet 層與 cuDNN v8 的更好融合
ResNet50 的基本構造塊是一個由卷積、批處理范數和激活函數組成的三層堆棧。對于 maskr-CNN ,批處理范數是凍結的,這意味著批處理范數和激活函數都是可以融合的逐點操作。
在前幾輪中,我們使用 PyTorch JIT fuser 來融合兩個逐點操作。多虧了 cuDNN v8 中的新融合引擎,我們通過將逐點運算與卷積融合在一起對其進行了改進。 fusion 引擎靈活的 API 還使我們能夠在一個 autograd 函數下融合所有三個基本層。這讓我們可以繞過定影器的限制,在反向傳播中進行不對稱融合,以獲得更大的性能提升。
語音識別( RNN-T )
RNN-T 語音識別是這一輪 MLPerf 訓練中的又一項新任務。我們使用了以下優化:
頂點傳感器損耗
RNN-T 使用一種特殊的損耗函數,我們稱之為傳感器損耗函數。計算損耗的算法本質上是迭代的。由于不規則的內存訪問模式和暴露的長內存讀取延遲,簡單的實現通常效率低下。
為了克服這個困難,我們開發了 apex.contrib.transducer.TransducerLoss 。它采用了一種類似于對角線波前的計算范式來開發算法中的并行性。共享內存和寄存器廣泛用于緩存迭代之間交換的數據。 loss 函數還使用預取來隱藏內存訪問延遲。
頂點傳感器接頭
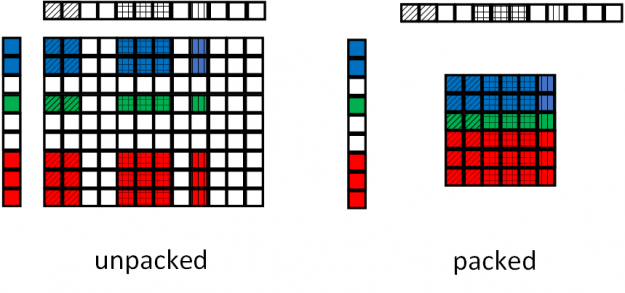
另一個經常出現在傳感器類型網絡中的組件是傳感器聯合操作。為了加速這個操作,我們開發了 apex.contrib.transducer.TransducerJoint 。這個 Apex 擴展不僅比其本機的 PyTorch 擴展快,而且還支持輸出打包,減少了后續層的工作負載。
圖 17 顯示了頂點傳感器接頭的填料操作。在基線聯合操作中,由于聯合操作與輸入填充無關,因此輸入序列中的填充被轉移到輸出。在頂點傳感器聯合操作中,輸出端的填充被移除,減小了饋送給后續操作的張量的大小。
序列分裂
為了減少填充物上浪費的 LSTM 計算,我們將批處理分為兩個階段(圖 18 )。在第一個過程中,對小批量中的所有樣本進行評估,直到特定的時間步(用黑框括起來)。小批量樣品的一半在第一次通過時完成。另一半樣本的剩余時間步長(用紅色框括起來)在第二遍中進行評估。用藍色框括起來的區域表示批量拆分的節省。
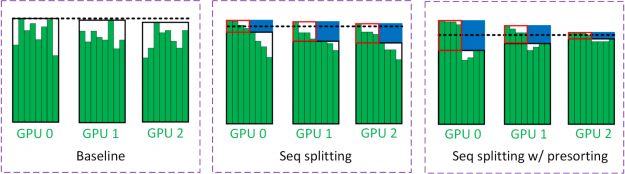
圖 18 中的黑色虛線估計了 GPU 所看到的工作量。因為第二遍的批處理大小減少了一半, GPU 看到的工作負載大約減少了一半。在 multi- GPU 訓練中,通常是最慢的 GPU 限制了訓練吞吐量。虛線是從具有大多數工作負載的 GPU 中獲得的。
為了減輕這種負載不平衡,我們采用了一種稱為預排序的技術,即根據序列長度對小批量中的樣本進行排序。最長和最短的序列放在同一個 GPU 上以平衡工作負載。這背后的直覺是,具有長序列的 GPU 可能是瓶頸。因此,短序列也應該放在這些 GPU 上,以最大限度地發揮序列分裂的優勢。
批量拆分
RNN-T 有一個有趣的網絡結構,其中 LSTM 處理相對較小的張量,而聯合網絡則處理更大的張量。為了使 LSTMs 能夠更有效地以大批量運行,同時不超過 GPU 內存容量,我們采用了一種稱為批處理拆分的技術(圖 17 )。我們使用了一個相當大的批量大小,這樣 LSTMs 就獲得了相當高的 GPU 利用率。相比之下,聯合網絡對批處理的一部分進行操作,并逐個遍歷這些子批。
在圖 19 中,使用了 2 的批次分割因子。在這種情況下,輸入到 LSTMs 和聯合網的批量大小分別是 B 和 B / 2 。因為在反向傳播完成后,除了權值的梯度之外,關節網絡生成的所有張量都不再需要,所以可以釋放它們并為循環中的下一個子批次創建空間。
![Batch splitting enables LSTMs to run more efficiently with a large batch size while not exceeding the GPU memory.]](https://developer-blogs.nvidia.com/wp-content/uploads/2021/06/Batch-splitting-625x286.png)
用 CUDA 圖進行批量評估
除了加速訓練, RNN-T 的評估也被仔細審查。 RNN-T 的評估本質上是迭代的,預測網絡的評估是逐步進行的。批處理 MIG 中的每個示例在同一時間步中選擇不同的代碼路徑,具體取決于執行結果。因此,簡單的實現會導致較低的 GPU 利用率和較長的評估時間,與培訓本身相當。
為了克服這些困難,我們在評估中進行了兩類優化。第一個優化在批處理模式下執行評估,并使用謂詞處理批處理中的不同控制流。第二個優化繪制了主 RNN-T 評估循環,該循環由許多短 GPU 核組成。我們還使用循環展開和重疊 CPU – GPU 通信與 GPU 執行來分攤相關的開銷。優化后的評估速度比單節點配置的參考代碼快 100 倍以上,比最大規模配置快 30 倍以上。
cuDNN v8 中更優化的 LSTMs
LSTM 是 RNN-T 的主要構造塊。端到端網絡時間的很大一部分花在 LSTMs 上。在 cuDNN v8 中, LSTMs 的性能得到了極大的優化。例如,將更好的水平融合算法和啟發式算法應用于 LSTM 單元中的 gemm 和 LSTM 層之間的 drop-out ,提高了性能并減少了 drop-out 帶來的開銷。
概括
MLPerf v1 . 0 展示了人工智能領域的不斷創新。 NVIDIA 人工智能平臺通過硬件、數據中心技術和軟件的緊密集成,提供領先的性能,以充分發揮人工智能的潛力。
自第一個 MLPerf 訓練基準啟動以來的過去兩年半時間里, NVIDIA 性能提高了近 7 倍。 NVIDIA 平臺在性能和可用性方面都非常出色,提供了從數據中心到邊緣再到云的單一領導平臺。
所有用于 NVIDIA 提交的軟件都可以從 MLPerf 存儲庫獲得,以使您能夠重現我們的基準測試結果。我們不斷地將這些最前沿的 MLPerf 改進添加到我們的深度學習框架容器中,這些容器可以在 NGC 上找到,它是我們的 GPU 優化應用程序的軟件中心。
?





