Merlin HugeCTR(以下簡稱 HugeCTR)是 GPU 加速的推薦程序框架,旨在在多個 GPU 和節點之間分配訓練并估計點擊率(Click-through rate)。
此次v3.4更新涉及的模塊主要為:
相關介紹:
V3.4.1 版本新增內容
- 調整了整個代碼庫中日志消息的日志級別。
- 現已支持對具有多個標簽的數據集進行推理:
“Softmax” 層現在已支持 FP16,并且支持混合精度以進行多標簽推理。有關詳細信息,請參閱此頁面。
- 支持多 GPU 離線推理:
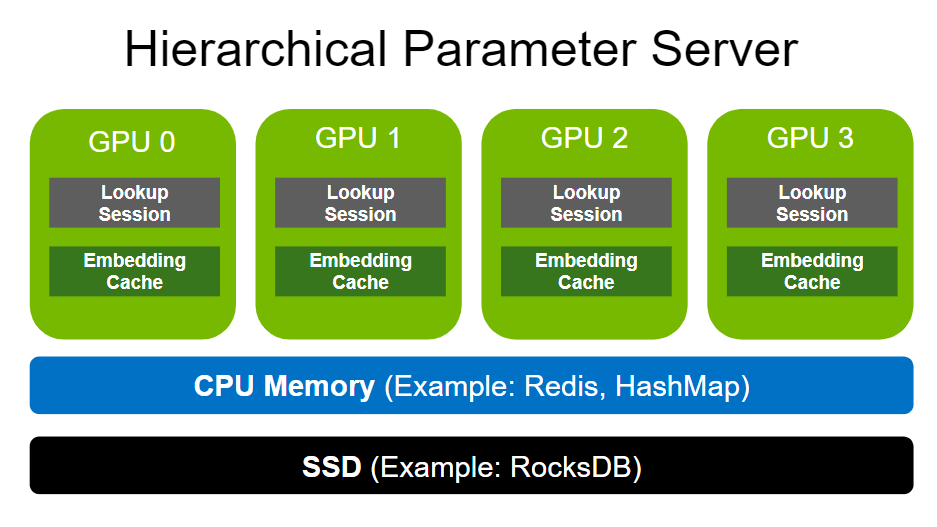
我們通過 Python 接口支持多 GPU 離線推理,它可以利用 Hierarchical Parameter Server 并在多個設備上實現并發執行。更多信息請參考推理 API 和多 GPU 離線推理筆記本。
- HPS 已構建為獨立庫:
我們重構了代碼庫并將分層參數服務器構建為一個獨立的庫,以后會進一步封裝。
- metadata.json 簡介:
添加了有關 Parquet data 中 _metadata.json 的詳細信息,請參閱此頁面。
- 增加了用于估計每個 GPU 的詞匯量大小的文檔和工具:
我們添加了一個工具來計算每個 GPU 的不同嵌入類型的詞匯量大小,在此基礎上, workspace_size_per_gpu_in_mb 可以根據嵌入向量大小和優化器類型評估更多信息請參考腳本與 Q&A。
- 訓練中支持 HDFS:
- 現在支持從 HDFS 加載和存儲模型和優化器狀態。
- 增加了編譯選項使 HDFS 的支持更加靈活。
- 添加了一個筆記本來展示如何將 HugeCTR 與 HDFS 一起使用
- 增加了一個演示如何分析模型文件的 Python 腳本和筆記本
- 錯誤修復:
已知問題
- HugeCTR 使用 NCCL 在 rank 之間共享數據,并且 NCCL 可能需要共享系統內存用于 IPC 和固定(頁面鎖定)系統內存資源。在容器內使用 NCCL 時,建議您通過發出以下命令 (-shm-size=1g -ulimit memlock=-1) 來增加這些資源。
另見 NCCL 的已知問題。還有 GitHub 問題。
- 目前即使目標 Kafka broker 無響應,KafkaProducers 啟動也會成功。為了避免與來自 Kafka 的流模型更新相關的數據丟失,您必須確保有足夠數量的 Kafka brokers 啟動、正常工作并且可以從運行 HugeCTR 的節點訪問。
- 文件列表中的數據文件數量應不小于數據讀取器的數量。否則,不同的 worker 將被映射到同一個文件,從而導致數據加載不會按預期進行。
- 正則化器暫不支持聯合損失訓練。
——————————————————————————————————————-
NVIDIA GTC 大會將于 3 月 21 日至 24 日線上舉辦!掃描下方海報二維碼,即刻免費注冊,切莫錯過推薦系統專家們所帶來的獨家講座,獲取開發秘笈。