隨著數據生成的不斷增加,線性性能擴展已成為擴展存儲的絕對要求。存儲網絡就像汽車道路系統:如果道路不是為速度而建的,那么汽車的潛在速度也無關緊要。即使是法拉利在充滿障礙的未鋪路面的土路上也很慢。
擴展存儲性能可能會受到連接存儲節點的以太網結構的阻礙。 NVIDIA 加速以太網可以消除性能瓶頸,為一般應用程序,特別是 AI / ML 實現最大的存儲性能。
擴展存儲需要強大的網絡
全球每秒有 54000 張照片被拍攝。當你讀到這篇文章的時候,這個數字會更高。無論您的業務是什么,您都有可能擁有大量必須存儲和分析的數據,而且數據量每天都在增長。
使用越來越大的存儲文件管理器的舊的按比例擴展方法已被一種按比例擴展的方法所取代,這種方法可以提供容量和性能都呈線性擴展的存儲。
使用擴展存儲或分布式存儲,可以將幾個較小的節點配置和連接為一個邏輯單元。單個文件或對象可以分布在多個節點上。
隨著需要更大的規模,可以很容易地添加額外的存儲節點,以提高存儲容量和性能。這既適用于傳統的企業存儲供應商解決方案,也適用于軟件和硬件獨立采購的軟件定義解決方案。
分布式存儲實現了靈活的擴展和成本效益,但需要高性能網絡來連接存儲節點。許多數據中心交換機不適合存儲的獨特流量特性,事實上可能會削弱橫向擴展存儲解決方案的性能。
存儲流量與傳統流量的區別
對于許多用例來說,網絡流量是一致和同質的,傳統的以太網就足夠了。但是,存儲設備生成的流量可能會導致以下詳細問題。
網絡壓力
當前的存儲解決方案受益于更快的 SSD 和存儲接口,如 NVMe 和 PCIe Gen 4 (即將推出的 PCIe Gen 5 ),它們旨在提供更高的性能。
擁塞
當存儲結構飽和時,網絡擁堵就不可避免了,就像高速公路上有太多交通時道路擁堵一樣。網絡擁塞對于擴展存儲來說尤其成問題,因為每個存儲節點都有望提供快速的數據傳輸。但當出現擁塞時,許多數據中心交換機都存在公平問題,其中一些節點的速度會比其他節點慢得多。單個文件或對象通常分布在多個節點上,因此任何降低單個節點速度的操作都會有效地降低整個集群的速度。
突發交通
大多數存儲工作負載都是突發性的,會產生密集的數據傳輸,并在短時間內重復需要大量帶寬。當這種情況發生時,網絡交換機必須使用其緩沖區來吸收突發,直到瞬態突發結束,從而防止數據包丟失。否則,數據包丟失將需要重新傳輸數據,從而顯著降低應用程序性能。
存儲巨型幀
傳統的數據中心網絡流量使用 1 . 5KB 的最大數據包大小( MTU )。當擴展存儲節點可以使用 9 KB 的“巨型幀”時,它們的性能會更好,這樣可以在降低吞吐量的同時提高吞吐量? CPU 處理開銷。許多使用商品交換機 ASIC 構建的數據中心交換機在使用巨型幀時表現不佳或不可預測。
低延遲
提高存儲 IOP 的方法之一是通過減少基于閃存的介質中的讀/寫操作的數量級延遲。?然而,當網絡引入高延遲時,尤其是由于過度緩沖,這些昂貴的性能改進可能會丟失。
訓練和推理都需要足夠的數據量和高速訪問,以確保 GPU 處理器足夠快地被饋送,使其保持完全參與。在訓練期間, WRITE 操作由所有節點執行,以提高模型的準確性。這導致了突發,使得交換機必須有效地處理擁塞。最后,較低的存儲延遲使 GPU 能夠更有效地處理計算任務。
為什么 ASIC 不適合存儲流量
大多數數據中心交換機都是使用商品交換機 ASIC 構建的,這些 ASIC 針對傳統的數據流量模式和數據包大小進行了成本優化。為了在實現帶寬目標的同時保持低成本,以太網交換機芯片供應商通過使用分離緩沖區架構來損害公平性。
每個交換機都有一個緩沖區,用于吸收流量突發,并在發生擁塞時防止數據包丟失。常見的方法是擁有一個跨多個端口共享的緩沖區。然而,并非所有共享緩沖區都是相同的——存在不同的緩沖區架構。
商品開關沒有 完全共享緩沖區他們使用入口共享緩沖區或出口共享緩沖區。
對于入口共享緩沖區,在一組傳入端口和特定內存片之間存在靜態映射。這些端口只能使用分配的片中的內存,而不能使用整個緩沖區,即使緩沖區的其余部分可用并且沒有人在使用它。
對于出口共享緩沖區,映射是在一組輸出端口和特定緩沖區內存片之間進行的。同樣,每組出口只能使用其分配的緩沖區切片,而不能使用整個緩沖區。
對于這兩種體系結構,停留在同一內存片中的流的行為與在內存片之間傳輸的流不同。如果許多流使用具有相同緩沖區的端口,那么這些端口將經歷更高的延遲和更低的吞吐量,而使用緩沖區的其他部分的流量將享受更高的性能。
存儲性能取決于存儲流量(和其他流量)使用的端口以及這些端口的緩沖區片的繁忙程度。這就是為什么使用拆分緩沖區的交換機經常遇到與公平性、可預測性和微突發吸收相關的問題。
為什么深度緩沖區交換機不適合存儲
深度緩沖交換機通常指的是提供更多緩沖( GB 而不是 MB )的交換機。深度緩沖交換機通常被推廣用作路由器,因為如果網絡速度不匹配或出現緊急情況,它們可以吸收并保持大量流量突發。
但在大多數數據中心應用程序(包括擴展存儲)中,深度緩沖區交換機會對性能產生負面影響,原因如下:
作業完成時間
對于并行文件系統,響應最慢的存儲節點決定了獲取文件所需的時間。與具有片上緩沖區的商品交換機 ASIC 不同,深度緩沖交換機同時具有片上和片外緩沖區,并且它們都是片上而非完全共享的緩沖區。
想想流動在離開開關之前可以走多少路。它們可以停留在一個片上存儲器片內(最快),在片上存儲器片間移動(較慢),或在片上和片外存儲器片間移動(非常慢)。
所有這些流的行為都會有所不同,因此會導致存儲流量的公平性和可預測性問題。由于這些問題會降低一個或多個節點的速度,因此會對作業完成時間產生不利影響,并降低整個分布式存儲集群的速度。
延遲
交換機緩沖區越大,每個數據包必須經過的隊列就越長,延遲也就越大。深度緩沖區交換機的測試平均端口到端口延遲超過 500 微秒。與來自同一代的完全共享的緩沖交換機相比,NVIDIA Spectrum 1 的延遲僅為 0.3 微秒。而切換/路由數據包需要的時間是納秒而不是微秒。
深度緩沖延遲高出 1000 倍。你可能想知道,這只是發生在擁堵的時候嗎?不會。在擁塞的情況下,深度緩沖區的延遲會高得多;事實上,最長可達 20 毫秒,或高出 50000 倍。對于數據中心之間的路由器來說, 500 微秒的延遲可能還可以,但在數據中心內,這意味著閃存性能的下降。
功率和成本
深緩沖開關即使在空閑時也需要數百瓦的功率才能運行,這使得其持續的運行成本更高。深度緩沖交換機的初始購買成本也高得多。如果性能更好,這可能是合理的,但現實世界的測試證明恰恰相反。
選擇不合適的網絡交換機會嚴重降低存儲工作負載,使昂貴的快速存儲變得更便宜、更慢。
使用 NVIDIA Spectrum,可以減少資本支出和運營支出。瓦特也可以用于機架內的其他用途。
NVIDIA Spectrum 交換機針對存儲進行了優化
有了商品交換 ASIC ,流要么停留在同一個內存片上,要么在內存片之間流動。
使用 NVIDIA Spectrum 開關,由于完全共享的緩沖區,所有流的行為都是相同的。這種架構的價值在于最大的突發吸收能力以及最佳的公平和可預測的性能。通過交換機的所有業務流都得到相同的處理,并且通常享有相同的良好性能,無論它們使用哪個入口和出口。
深度緩沖開關和 NVIDIA Spectrum 的基準測試
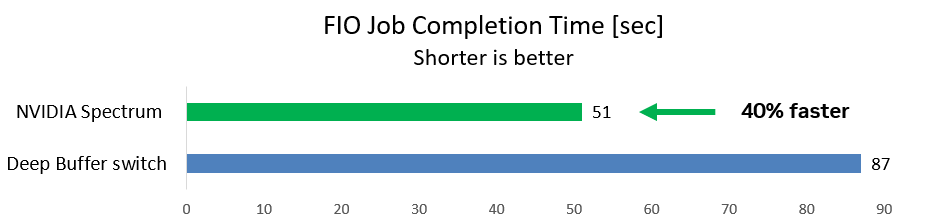
第一種情況使用一個通用的存儲基準 FIO 工具,用于在后臺流量運行時從兩個啟動器到一個目標的 WRITE 操作。這是一種典型的存儲場景。
團隊測量了 FIO 工作完成所需的時間(越短越好)。使用深度緩沖開關, FIO 作業耗時 87 秒。使用 NVIDIA Spectrum 開關,作業運行速度快 40% ,僅需 51 秒即可完成。
深度緩沖區交換機大大增加了延遲,從而降低了存儲速度并降低了應用程序性能。但是延遲能有多高?
對于第二種情況,該團隊采用了深度緩沖區交換機,并測試了在不同的擁塞用例下延遲是如何受到影響的。最大緩沖區占用率僅為整個緩沖區大小的 10% 左右。
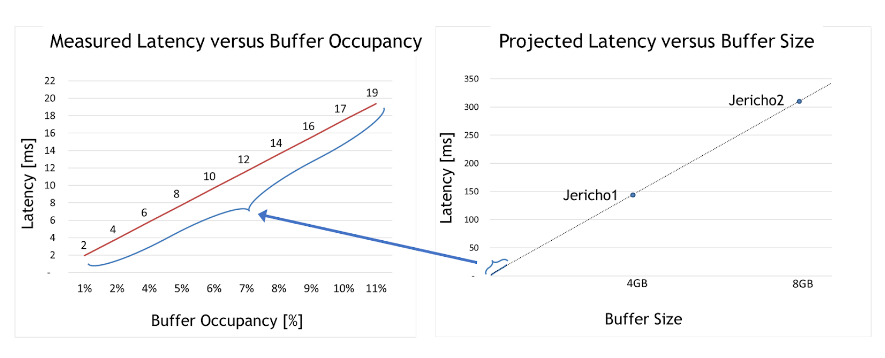
從圖 2 左側的圖表中可以得出兩個有意義的見解。首先,深度緩沖區交換機延遲比 Spectrum 交換機高 50000 倍( 2 – 19 毫秒,而 Spectrum 僅為 300 納秒)。
其次,緩沖區占用率和延遲之間存在明顯的線性相關性。換句話說,測試證明,占用的緩沖區越大,延遲就越大。
有了這一理解,圖 2 右側的圖表顯示了每個深度緩沖 ASIC (如 Jericho 1 、 Jericho 2 或 Ramon )的最大延遲。這些非常高的延遲數通常與數據中心應用程序不兼容,尤其與快速存儲解決方案不兼容。
對于第三種情況,該團隊使用了兩臺 Windows 機器,并同時將每個機器中的一個文件復制到同一目標存儲中。
使用深度緩沖區交換機,一臺 Windows 機器的帶寬是另一臺的三倍( 830MBps ,而 290MBps )。有了 Spectrum 開關,每臺機器都有 584 MBps (如預期的 50% )。
實際測試表明,深度緩沖區交換機對數據中心應用程序(如吸收數據包和防止數據丟失)沒有積極影響。
長途或廣域網連接可能需要深度緩沖交換機;然而,它們對于數據中心應用程序來說是次優的,并且會產生負面影響,特別是當工作負載擴展到僅兩個節點之外時,如本用例中所示。

這三個用例證明了為什么深度緩沖區交換機會對 AI / ML 和存儲工作負載產生不利影響,而 Spectrum 交換機則提供了最大化的性能。
總結
NVIDIA Spectrum Ethernet switches 是專為 AI/ML 和存儲工作負載而構建的,其性能優于具有拆分緩沖區或深度緩沖區的交換機。它們可以更好地處理擁塞,防止數據包丟失,并且在處理巨型幀(首選存儲)方面表現出色。NVIDIA Spectrum 以太網交換機可以提供良好的應用程序性能,網絡延遲也較低。
了解更多信息,請訪問 NVIDIA Spectrum Ethernet switches。深入了解網絡存儲領域,請訪問 NVIDIA Developer Forums。
?