
介紹
高效的管道設計對數據科學家至關重要。在編寫復雜的端到端工作流時,您可以從各種構建塊中進行選擇,每種構建塊都專門用于特定任務。不幸的是,在數據格式之間重復轉換容易出錯,而且會降低性能。讓我們改變這一點!
在本系列博客中,我們將討論高效框架互操作性的不同方面:
- 在第一個職位中,我們討論了不同內存布局以及異步內存分配的內存池的優缺點,以實現零拷貝功能。
- 在第二職位中,我們強調了數據加載/傳輸過程中出現的瓶頸,以及如何使用遠程直接內存訪問( RDMA )技術緩解這些瓶頸。
- 在本文中,我們將深入討論端到端管道的實現,展示所討論的跨數據科學框架的最佳數據傳輸技術。
要了解有關框架互操作性的更多信息,請查看我們在 NVIDIA 的 GTC 2021 年會議上的演示。
讓我們深入了解以下方面的全功能管道的實現細節:
- 從普通 CSV 文件解析 20 小時連續測量的電子 CTR 心電圖( ECG )。
- 使用傳統信號處理技術將定制 ECG 流無監督分割為單個心跳。
- 用于異常檢測的變分自動編碼器( VAE )的后續培訓。
- 結果的最終可視化。
對于前面的每個步驟,都使用了不同的數據科學庫,因此高效的數據轉換是一項至關重要的任務。最重要的是,在將數據從一個基于 GPU 的框架復制到另一個框架時,應該避免昂貴的 CPU 往返。
零拷貝操作:端到端管道
說夠了!讓我們看看框架的互操作性。在下面,我們將逐步討論端到端管道。如果你是一個不耐煩的人,你可以直接在這里下載完整的 Jupyter 筆記本。源代碼可以在最近的RAPIDS docker 容器中執行。
 by
by 步驟 1 :數據加載
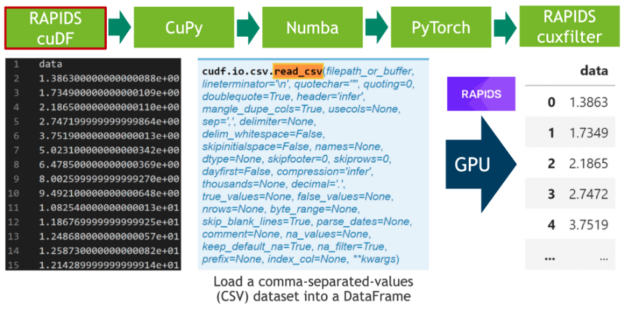
在第一步中,我們下載 20 小時的 ele CTR 心電圖作為 CSV 文件,并將其寫入磁盤(見單元格 1 )。之后,我們解析 CSV 文件中的 500 MB 標量值,并使用 RAPIDS “ blazing fast CSV reader ”(參見單元格 2 )將其直接傳輸到 GPU 。現在,數據駐留在 GPU 上,并將一直保留到最后。接下來,我們使用cuxfilter( ku 交叉濾波器)框架繪制由 2000 萬個標量數據點組成的整個時間序列(見單元格 3 )。
步驟 2 :數據分割
在下一步中,我們使用傳統的信號處理技術將 20 小時的 ECG 分割成單個心跳。我們通過將 ECG 流與高斯分布的二階導數(也稱為里克爾小波)進行卷積來實現這一點,以便分離原型心跳中初始峰值的相應頻帶。使用 CuPy (一種 CUDA 加速的密集線性代數和陣列運算庫)可以方便地進行小波采樣和基于 FFT 的卷積運算。直接結果是,存儲 ECG 數據的 RAPIDS cuDF 數據幀必須使用 DLPack 作為零拷貝機制轉換為 CuPy 陣列。
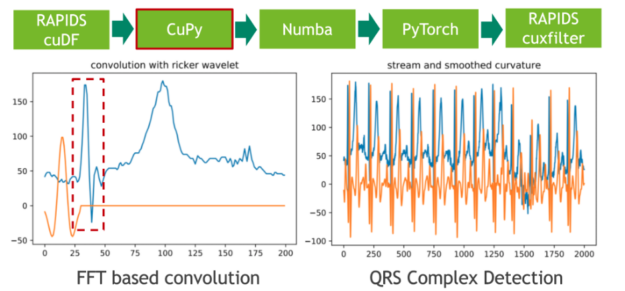
卷積的特征響應(結果)測量流中每個位置的固定頻率內容的存在。請注意,我們選擇小波的方式使局部最大值對應于心跳的初始峰值。
步驟 3 :局部極大值檢測
在下一步中,我們使用非最大抑制( NMS )的 1D 變體將這些極值點映射到二進制門。 NMS 確定流中每個位置的對應值是否為預定義窗口(鄰域)中的最大值。這個令人尷尬的并行問題的 CUDA 實現非常簡單。在我們的示例中,我們使用即時編譯器 Numba 實現無縫的 Python 集成。 Numba 和 Cupy 都將 CUDA 陣列接口實現為零拷貝機制,因此可以完全避免從 Cupy 陣列到 Numba 設備陣列的顯式轉換。
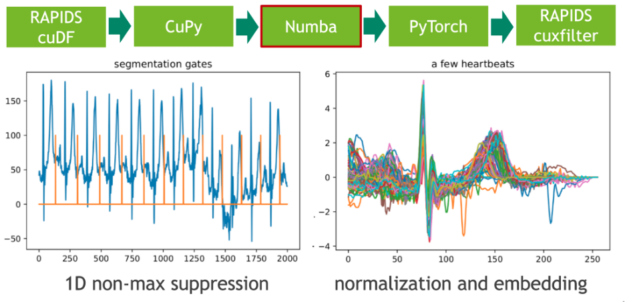
每個心跳的長度是通過計算門位置的相鄰差分(有限階導數)來確定的。我們通過使用謂詞門== 1 過濾索引域,然后調用 cupy . diff ()來實現這一點。得到的直方圖描述了長度分布。
步驟 4 :候選修剪和嵌入
我們打算使用固定長度的輸入矩陣在心跳集上訓練(卷積)變分自動編碼器( VAE )。用 CUDA 內核可以實現心跳信號在零向量中的嵌入。在這里,我們再次使用 Numba 進行候選修剪和嵌入。
步驟 5 :異常值檢測
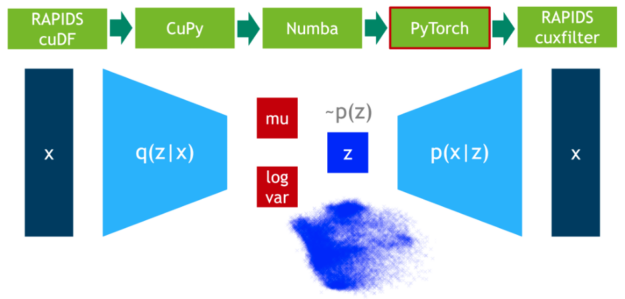
在這一步中,我們在 75% 的數據上訓練 VAE 模型。 DLPack 再次用作零拷貝機制,將 CuPy 數據矩陣映射到 PyTorch 張量。
步驟 6 :結果可視化
在最后一步中,我們可視化剩余 25% 數據的潛在空間。
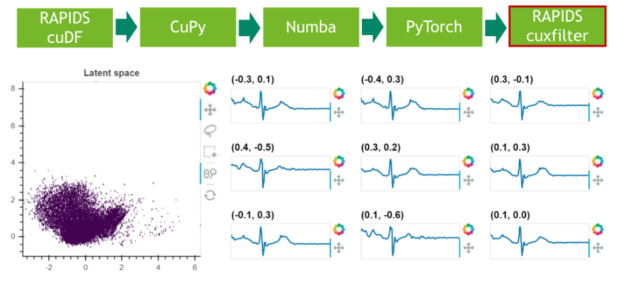
從這篇和前面的博文中可以看出,互操作性對于設計高效的數據管道至關重要。在不同的框架之間復制和轉換數據是一項昂貴且極其耗時的任務,它為數據科學管道增加了零價值。數據科學工作負載變得越來越復雜,多個軟件庫之間的交互是常見的做法。 DLPack 和 CUDA 陣列接口是事實上的數據格式標準,保證了基于 GPU 的框架之間的零拷貝數據交換。
對外部內存管理器的支持是一個很好的特點,在評估您的管道將使用哪些軟件庫時要考慮。例如,如果您的任務同時需要數據幀和數組數據操作,那么最好選擇 RAPIDS cuDF + CuPy 庫。它們都受益于 GPU 加速,支持 DLPack 以零拷貝方式交換數據,并共享同一個內存管理器 RMM 。或者, RAPIDS cuDF + JAX 也是一個很好的選擇。然而,后一種組合 或許需要額外的開發工作來利用內存使用,因為 JAX 缺乏對外部內存分配器的支持。
在處理大型數據集時,數據加載和數據傳輸瓶頸經常出現。 NVIDIA GPU 直接技術起到了解救作用,它支持將數據移入或移出 GPU 內存,而不會加重 CPU 的負擔,并將不同節點上 GPU 之間傳輸數據時所需的數據副本數量減少到一個。
?






