
這是 LLM 基準測試系列 的第二篇文章,介紹了在使用 NVIDIA NIM 部署 Meta Llama 3 模型 時,如何使用 GenAI-Perf 對其進行基準測試。
在構建基于 LLM 的應用時,了解這些模型在給定硬件上的性能特征至關重要。這有多種用途:
- 識別瓶頸和潛在優化機會
- 確定服務質量和吞吐量 tradeoff
- 基礎架構配置
作為以客戶端 LLM 為中心的基準測試工具, NVIDIA GenAI-Perf 提供了以下關鍵指標:
- 首次令牌生成時間 (TTFT)
- 令牌間延遲 (ITL)
- 每秒令牌數 (TPS)
- 每秒請求數 (RPS)
- … 等等
GenAI-Perf 還支持任何符合 OpenAI API 規范 (業內廣泛接受的默認標準)的 LLM 推理服務。
在本基準測試指南中,我們使用了 NVIDIA NIM ,這是一系列推理微服務,可為基礎 LLM 和微調 LLM 提供高吞吐量和低延遲推理。NIM 具有易用性、企業級安全性和可管理性。
為優化您的 AI 應用,本文將介紹如何為 Llama 3 設置 NIM 推理微服務,使用 GenAI-Perf 來衡量性能并分析輸出。
為何使用 GenAI-Perf 對模型性能進行基準測試?
NVIDIA NIM 微服務是經過優化的預封裝容器,支持在云、數據中心和 NVIDIA RTX AI PC 等各種平臺上輕松部署和運行 AI 模型,從而加速任何領域的 生成式 AI 開發。NIM LLM 由行業領先的后端提供支持,包括 TensorRT-LLM 和 vLLM。NIM 不斷改進,即使在相同的硬件生成上也能提供最佳性能。
借助 GenAI-Perf,您不僅可以重現和驗證這些性能結果,還可以使用自己的硬件進行基準測試。有關此過程的更多信息,請參閱 NVIDIA NIM 性能 。
使用 NIM 進行基準測試的步驟
NIM 性能 頁面上的所有性能數據均通過 NVIDIA GenAI-Perf 工具收集。按照本文其余部分中介紹的分步方法,您可以在自己的硬件上重現這些性能數字以及基準測試模型。
使用 NIM 設置兼容 OpenAI 的 Llama-3 推理服務
NIM 為將 LLM 和其他 AI 基礎模型投入生產提供了最簡單、最快速的方法。有關更多信息,請參閱 使用 NVIDIA NIM 部署生成式 AI 的簡單指南 或 適用于大語言模型的最新 NVIDIA NIM 文檔 ,該文檔為您介紹了硬件要求和前提條件,包括 NVIDIA NGC API 密鑰。
使用以下命令部署 NIM 并執行 inference:
export NGC_API_KEY=<YOUR_NGC_API_KEY> ?
# Choose a container name for bookkeepingexport CONTAINER_NAME=llama-3.1-8b-instruct?
# Choose a LLM NIM Image from NGCexport IMG_NAME="nvcr.io/nim/meta/${CONTAINER_NAME}:latest"?
# Choose a path on your system to cache the downloaded modelsexport LOCAL_NIM_CACHE=./cache/nimmkdir -p "$LOCAL_NIM_CACHE"?
# Start the LLM NIMdocker run -it --rm --name=$CONTAINER_NAME \??--gpus all \??--shm-size=16GB \??-e NGC_API_KEY \??-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \??-u $(id -u) \??-p 8000:8000 \??$IMG_NAME |
在此代碼示例中,我們指定了 Meta Llama-3.1-8b-Instruct 模型,該模型也是容器的名稱。我們還提供了一個本地目錄并將其掛載為緩存目錄,用于保存已下載的模型資產。
在啟動期間,NIM 容器會下載所需資源,并開始為 API 端點背后的模型提供服務。以下消息表明成功啟動:
INFO: Application startup complete. ?
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit) |
運行時,NIM 提供了一個兼容 OpenAI 的 API,您可以查詢:
from openai import OpenAIprompt = "Once upon a time"response = client.completions.create(????model="meta/llama-3.1-8b-instruct",????prompt=prompt,????max_tokens=16,????stream=False)completion = response.choices[0].textprint(completion) |
設置 GenAI-Perf 并對單個用例進行基準測試
現在您已運行 NIM Llama-3 推理服務,接下來請設置基準測試工具。
最簡單的方法是使用預構建的 Docker 容器。我們建議在與 NIM 相同的服務器上啟動 GenAI-Perf 容器,以避免網絡延遲,除非您特別希望在測量時考慮網絡延遲。
有關入門的更多信息,請參閱 GenAI-Perf 文檔。
運行以下命令以使用預構建 container.
export RELEASE="24.12" # recommend using latest releases in yy.mm format?
docker run -it --net=host --gpus=all -v $PWD:/workdir nvcr.io/nvidia/tritonserver:${RELEASE}-py3-sdk |
您應將主機目錄安裝到容器中,以便持久化 benchmarking 資產。在之前的示例中,我們加載了當前目錄。
在容器內,您可以按如下所示啟動 GenAI-Perf 評估工具,該工具可在 NIM 后端執行變暖負載測試:
export INPUT_SEQUENCE_LENGTH=200export INPUT_SEQUENCE_STD=10export OUTPUT_SEQUENCE_LENGTH=200export CONCURRENCY=10export MODEL=meta/llama-3.1-8b-instruct?
genai-perf profile \????-m $MODEL \????--endpoint-type chat \????--service-kind openai \????--streaming \????-u localhost:8000 \????--synthetic-input-tokens-mean $INPUT_SEQUENCE_LENGTH \????--synthetic-input-tokens-stddev $INPUT_SEQUENCE_STD \????--concurrency $CONCURRENCY \????--output-tokens-mean $OUTPUT_SEQUENCE_LENGTH \????--extra-inputs max_tokens:$OUTPUT_SEQUENCE_LENGTH \????--extra-inputs min_tokens:$OUTPUT_SEQUENCE_LENGTH \????--extra-inputs ignore_eos:true \????--tokenizer meta-llama/Meta-Llama-3.1-8B-Instruct \????-- \????-v \????--max-threads=256 |
在此最小示例中,我們指定了輸入和輸出序列長度以及要測試的并發性。我們還要求后端忽略特殊的 EOS 令牌,以便輸出達到預期長度。
此測試使用 Hugging Face 中的 Llama-3 標記器,這是一個嚴密保護的存儲庫。您必須申請訪問權限,然后使用 Hugging Face 憑據登錄。
pip install huggingface_hub?
huggingface-cli login |
有關全套選項和參數的更多信息,請參閱 GenAI-Perf 文檔。
成功執行后,您應在終端中看到類似于以下內容的結果:
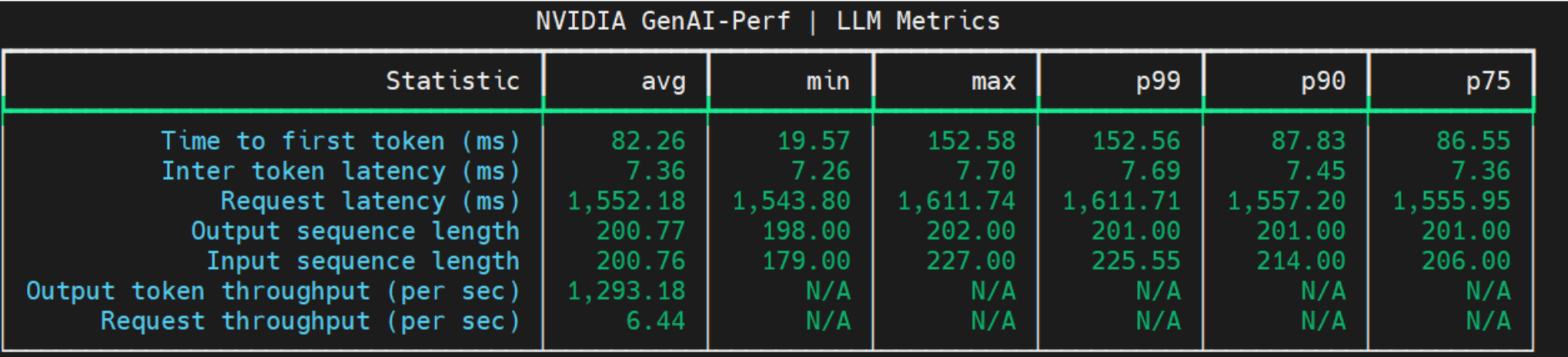
瀏覽幾個使用案例
使用基準測試時,通常會設置測試來掃描或執行多個用例 (輸入和輸出長度組合) 和負載場景 (不同的并發值) 。使用以下 BASH 腳本定義參數,以便 GenAI-Perf 執行所有組合。
在進行基準測試掃描之前,我們建議運行熱身測試。在本例中,我們在設置 GenAI-Perf 和單個用例時做到了這一點。
在 GenAI-Perf 容器中,運行以下命令:
bash benchmark.sh |
這是 benchmark.sh 腳本:
declare -A useCases?
# Populate the array with use case descriptions and their specified input/output lengthsuseCases["Translation"]="200/200"useCases["Text classification"]="200/5"useCases["Text summary"]="1000/200"useCases["Code generation"]="200/1000"?
# Function to execute genAI-perf with the input/output lengths as argumentsrunBenchmark() {????local description="$1"????local lengths="${useCases[$description]}"????IFS='/' read -r inputLength outputLength <<< "$lengths"?
????echo "Running genAI-perf for $description with input length $inputLength and output length $outputLength"????#Runs????for concurrency in 1 2 5 10 50 100 250; do?
????????local INPUT_SEQUENCE_LENGTH=$inputLength????????local INPUT_SEQUENCE_STD=0????????local OUTPUT_SEQUENCE_LENGTH=$outputLength????????local CONCURRENCY=$concurrency????????local MODEL=meta/llama-3.1-8b-instruct?????????????????genai-perf profile \????????????-m $MODEL \????????????--endpoint-type chat \????????????--service-kind openai \????????????--streaming \????????????-u localhost:8000 \????????????--synthetic-input-tokens-mean $INPUT_SEQUENCE_LENGTH \????????????--synthetic-input-tokens-stddev $INPUT_SEQUENCE_STD \????????????--concurrency $CONCURRENCY \????????????--output-tokens-mean $OUTPUT_SEQUENCE_LENGTH \????????????--extra-inputs max_tokens:$OUTPUT_SEQUENCE_LENGTH \????????????--extra-inputs min_tokens:$OUTPUT_SEQUENCE_LENGTH \????????????--extra-inputs ignore_eos:true \????????????--tokenizer meta-llama/Meta-Llama-3-8B-Instruct \????????????--measurement-interval 30000 \????????????--profile-export-file ${INPUT_SEQUENCE_LENGTH}_${OUTPUT_SEQUENCE_LENGTH}.json \????????????-- \????????????-v \????????????--max-threads=256?????????done}?
# Iterate over all defined use cases and run the benchmark script for eachfor description in "${!useCases[@]}"; do????runBenchmark "$description"done |
“--measurement-interval 30000 參數是每次測量所用的時間間隔 (以毫秒為單位) 。GenAI-Perf 用于測量在指定時間間隔內完成的請求。選擇一個足夠大的值,以便完成多個請求。對于更大的網絡 (例如 Llama-3 70B) 和更多并發 (例如 250) ,請選擇更高的值。例如,您可以使用 100000 毫秒,即 100 秒。”
分析輸出
測試完成后,GenAI-Perf 會在名為 \artifacts 的默認目錄中生成結構化輸出,并按模型名稱、并發性和輸入/輸出長度進行組織。
artifacts├── meta_llama-3.1-8b-instruct-openai-chat-concurrency1│?? ├── 1000_200.json│?? ├── 1000_200_genai_perf.csv│?? ├── 1000_200_genai_perf.json│?? ├── 200_1000.json│?? ├── 200_1000_genai_perf.csv│?? ├── 200_1000_genai_perf.json│?? ├── 200_200.json│?? ├── 200_200_genai_perf.csv│?? ├── 200_200_genai_perf.json│?? ├── 200_5.json│?? ├── 200_5_genai_perf.csv│?? ├── 200_5_genai_perf.json│?? └── inputs.json├── meta_llama-3.1-8b-instruct-openai-chat-concurrency10│?? ├── 1000_200.json│?? ├── 1000_200_genai_perf.csv│?? ├── 1000_200_genai_perf.json│?? ├── 200_1000.json│?? ├── 200_1000_genai_perf.csv│?? ├── 200_1000_genai_perf.json│?? ├── 200_200.json│?? ├── 200_200_genai_perf.csv│?? ├── 200_200_genai_perf.json│?? ├── 200_5.json│?? ├── 200_5_genai_perf.csv│?? ├── 200_5_genai_perf.json│?? └── inputs.json├── meta_llama-3.1-8b-instruct-openai-chat-concurrency100│?? ├── 1000_200.json… |
*genai_perf.csv 文件是主要的基準測試結果。您可以使用以下代碼在給定用例(例如 200/5 的 ISL/OSL)的所有并發中讀取所有每秒請求(RPS)和第一個令牌時間(TTFT)指標:
import osimport pandas as pd?
root_dir = "./artifacts"directory_prefix = "meta_llama-3.1-8b-instruct-openai-chat-concurrency"?
concurrencies = [1, 2, 5, 10, 50, 100, 250]RPS = []TTFT = []?
for con in concurrencies:????df = pd.read_csv(os.path.join(root_dir, directory_prefix+str(con), f"200_5_genai_perf.csv"))????RPS.append(float(df.iloc[8]['avg'].replace(',', '')))????TTFT.append(float(df.iloc[0]['avg'].replace(',', ''))) |
最后,您可以使用以下代碼使用收集的數據繪制和分析 latency-throughput 曲線。在這里,每個數據點都對應一個并發值。
import matplotlib.pyplot as plt?
plt.plot(TTFT, RPS, 'x-')plt.xlabel('TTFT(ms)')plt.ylabel('RPS')?
labels = [1, 2, 5, 10, 50, 100, 250]# Add labels to each data pointfor i, label in enumerate(labels):????plt.annotate(label, (TTFT[i], RPS[i]), textcoords="offset points", xytext=(0,10), ha='center') |
圖 2 顯示了使用 GenAI-Perf 測量數據生成的圖形。
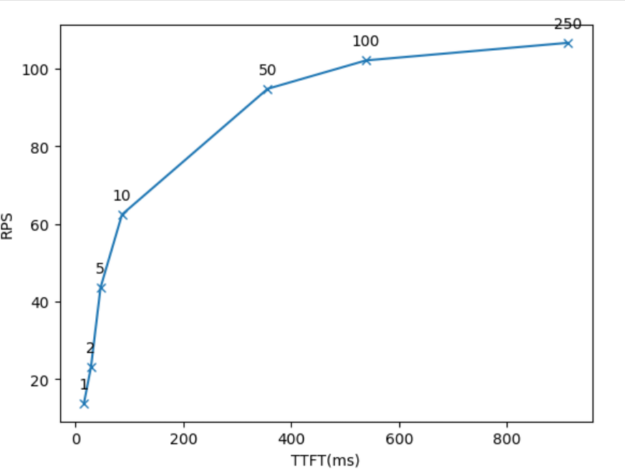
解釋結果
圖 2 顯示了 x 軸上的 TTFT、y 軸上的系統總吞吐量以及每個點上的并發情況。圖形的使用方法有以下幾種:
- 擁有延遲預算 (例如可接受的最大 TTFT) 的 LLM 應用所有者可以將該值用于 x,并尋找匹配的 y 值和并發值。這表明使用該延遲預算和相應的并發值可以實現的最高吞吐量。
- LLM 應用所有者可以使用并發值來定位圖形上的相應點。點的 x 和 y 值顯示該并發級別的延遲和吞吐量。
圖 2 還顯示了延遲快速增長且吞吐量很少或根本沒有提升的并發情況。例如,concurrency=50 就是其中一個值。
類似的圖形可以使用 ITL、e2e_latency 或 TPS_per_user 作為 x 軸,顯示系統總吞吐量與單個用戶延遲之間的權衡。
對定制 LLM 進行基準測試
如今,LLMs 可以很好地滿足許多常見任務的需求,例如開放式 QA 或會議總結。
但是,定制 LLM 對某些任務大有益,例如在內部企業知識庫上對 LLM 進行訓練,使其適應內部工作文化、專業知識和協議、特定產品組合和縮略語,甚至使用內部生產力工具。
NIM 支持提供定制模型。NIM 支持低秩自適應 (LoRA) ,這是一種針對特定領域和用例定制 LLM 的簡單高效的方法。要使用 LoRA 自定義 LLM,您可以使用 NVIDIA NeMo ,這是一個用于訓練生成式 AI 模型的開源平臺。 完成后,您可以使用 NIM 加載和部署多個 LoRA 適配器。
首先,將經過 NVIDIA NeMo 訓練的 LoRA 適配器放入特定目錄結構中,然后按照 Parameter-Efficient Fine-Tuning 中的說明,將適配器文件夾名稱作為環境變量傳遞給 NIM。NIM 還支持使用 HuggingFace PEFT 庫 訓練的 LoRA 適配器。
添加 LoRA 模型后,可以通過將 base model ID 替換為 LoRA 模型名稱來查詢與 base model 類似的 LoRA 模型:
curl -X 'POST' \??-H 'accept: application/json' \??-H 'Content-Type: application/json' \??-d '{"model": "llama3-8b-instruct-lora_vhf-math-v1","prompt": "John buys 10 packs of magic cards. Each pack has 20 cards and 1/4 of those cards are uncommon. How many uncommon cards did he get?","max_tokens": 128}' |
借助 GenAI-Perf,可以通過 -m 參數傳遞 LoRA 模型的 ID 來對 LoRA 模型的部署指標進行基準測試:
genai-perf profile \????????????-m llama-3-8b-lora_1 llama-3-8b-lora_2 llama-3-8b-lora_3 \???????--model-selection-strategy random \????????????--endpoint-type completions \????????????--service-kind openai \????????????--streaming \ |
在本例中,測試了三個 LoRA 模型:
- llama-3 -8b-lora_1
- llama-3 -8b-lora_2
- llama-3 -8b-lora_3
--model-selection-strategy {round_robin,random} 參數用于指定應循環調用還是隨機調用這些適配器。
總結
NVIDIA GenAI-Perf 工具旨在滿足對由大規模 LLM 提供支持的基準測試解決方案的迫切需求。它支持 NVIDIA NIM ,以及其他兼容 OpenAI 的 LLM 服務解決方案。
本文為您提供了最重要、最熱門的指標和參數,有助于標準化整個行業的模型基準測試方式。
有關如何選擇正確的指標和優化 AI 應用性能的更多信息和專家指導,請參閱 LLM Inference Sizing:Benchmarking End-to-End Inference Systems GTC 會議。
?
?






