MLCommons 開發的 MLPerf 基準是組織衡量其機器學習模型跨工作負載培訓性能的關鍵評估工具。 MLPerf Training v2.1- 這個以 AI 培訓為重點的基準套件的第七次迭代測試了廣泛流行的 AI 用例的性能,包括以下:
- 圖像分類
- 物體檢測
- 醫學影像學
- 語音識別
- 自然語言處理
- 正式建議
- 強化學習
許多人工智能應用程序利用流水線中部署的多個人工智能模型。這意味著,人工智能平臺必須能夠運行當今可用的所有模型,并提供支持新模型創新的性能和靈活性。
NVIDIA AI platform 在此輪中提交了所有工作負載的結果,它仍然是唯一一個提交了所有 MLPerf 培訓工作負載結果的平臺。
![Diagram shows a user asking their phone to identify the type of flower in an image and the many AI models that may be used to perform this identification task across several domains[SBE1] : audio, vision, recommendation, and TTS.](https://developer-blogs.nvidia.com/wp-content/uploads/2022/11/model-use-case.png)
NVIDIA Hopper 可大幅提升性能
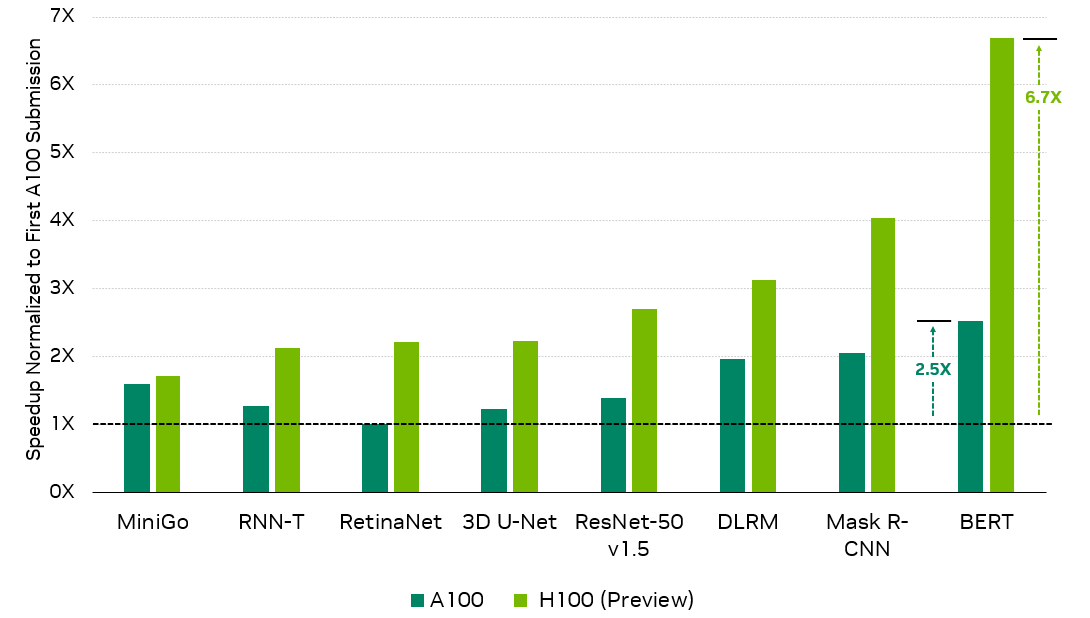
在這一輪中, NVIDIA 使用新的 H100 Tensor Core GPU 提交了其首個 MLPerf 訓練結果,與首次提交的 A100 Tensor Core GPU 相比,性能提高了 6.7 倍,與最新的 A100 結果相比,性能提升了 2.6 倍。
ResNet-50 v1.5 : 8x NVIDIA 0.7-18 , 8x NVIDIA 2.1-2060, 8x NVIDIA 2.1-2091 | BERT : 8x NVIDIA 0.7-19 , 8x NVVIDIA 2.1-2062, 8x NVIDIA 2.1-2091 | DLRM : 8x NVIDIA 0.7-17 , 8x NVID IA 2.1-2059, 8x NVIDIA 2.1-2091 |掩模 R-CNN : 8x NVVIDIA 0.7-19 , 8x NVID IA 2.1-2062, 8x NVIDIA 2.1-2091 | RetinaNet : 8x NVIDIA 2.0-2091 , 8x NVIDIA 2.1-2061, 8x NVIDIA 2.1-2091 | RNN-T : 8x NVVIDIA 1.0-1060 , 8x NVID IA 2.1-2061, 8x NVIDIA 2.1-2091 | Mini-Go : 8x NVVIDIA 0.7-20 , 8x NVID IA 2.1-2063, 8x NVIDIA 2.1-2091 | 3D U-Net : 8x NVIDIA 1.0-1059 , 8x NVID IA 2.1-2060, 8x NVIDIA 2.1-2091
第一個 NVIDIA A100 Tensor Core GPU 結果因 MLPerf Training 2.0 中引入的更高精度要求(如適用)而針對吞吐量標準化。
MLPerf 名稱和徽標是商標。有關詳細信息,請參閱 www.mlperf.org .
此外,在其第五次 MLPerf 培訓中, A100 繼續在全套工作負載中提供優異的性能,與首次提交相比,由于廣泛的軟件優化,性能提高了 2.5 倍。
這篇文章詳細介紹了 NVIDIA 為實現這些結果所做的工作。
BERT
對于這一輪 MLPerf ,我們對 BERT 提交的文件進行了若干優化,包括使用 FP8 格式,對 FP8 操作進行優化,減少 CPU 開銷,以及對小規模應用序列打包。
與 NVIDIA transformer 引擎集成
MLPerf Training v2.1 中 BERT 提交的 關鍵優化之一是使用 NVIDIA Transformer Engine library. 。該庫在 NVIDIA GPU 上加速 transformer models ,并利用 NVIDIA Hopper 第四代 Tensor Core 支持的 FP8 數據格式。
BERT FP8 輸入用于完全連接的層,以及在單個內核中實現多頭注意力的融合多頭注意力內核。與 FP16 格式相比,使用 FP8 格式可以減少存儲器和流式多處理器( SM )之間傳輸的數據量,從而縮短存儲器訪問時間。
與 NVIDIA Hopper 架構上的 FP16 格式相比,將 FP8 格式用于矩陣乘法的輸入還利用了 FP8 格式更高的計算速率 GPU 。通過利用 FP8 格式,與在相同硬件上不使用 transformer 引擎相比, transformer Engine 將端到端訓練時間縮短了 37% 。
transformer 引擎從用戶那里提取出 FP8 張量類型。因此,編碼器層的輸入和輸出處的張量格式保持為 FP16 。 FP8 使用的詳細信息由編碼器層內的 transformer 引擎庫處理。
FP8 采用 E4M3 和 E5M2 格式,在 transformer 引擎中稱為混合配方。有關 FP8 格式和配方的更多信息,請參見 Using FP8 with Transformer Engine 。
FP8 通用矩陣乘法層
transformer 引擎庫具有自定義的融合內核實現,以加速常用的 NLP 和數據轉換操作。
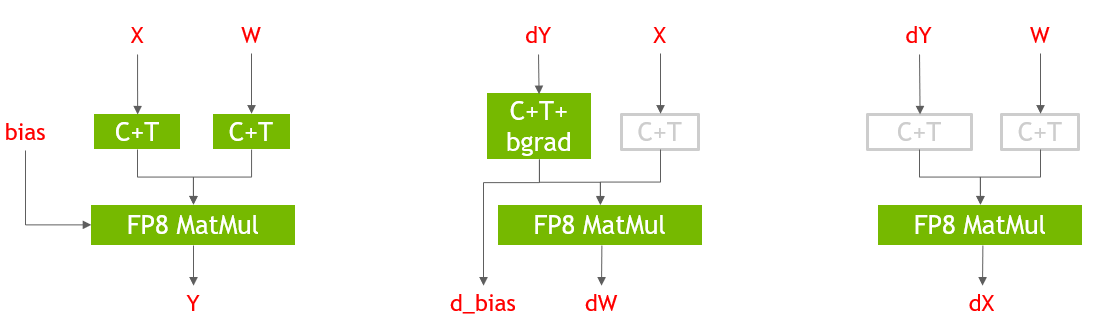
圖 3 顯示了 PyTorch 中 Linear 層的前向和后向傳遞的 FP8 實現。使用 transformer 引擎庫提供的 Cast + Transpose ( C + T )融合內核將 GEM 層的輸入轉換為 FP8 , GEM 輸出以 FP16 精度保存。 FP8 GEMM 層可使端到端培訓時間提高 29% 。在圖 3 中,灰色的 C ++操作是冗余的,僅用于說明目的。 FP8 GEMM 層使用 transformer Engine 庫后端的 cuBLAS 庫。
FP8 的效率更高,融合多頭注意力
在這一輪中,我們根據 FlashAttention 算法實現了一種不同版本的融合多頭注意力,它對 BERT 用例更有效。
此實現不寫入前向通道中的 softmax 輸出或丟棄掩碼,以用于后向通道。相反,它重新計算后向通道中 softmax 輸出,并使用直接來自前向通道的隨機數生成器狀態來重新生成后向通道的丟棄掩碼。
這種方法更有效,特別是當由于寄存器壓力降低而使用 FP8 輸入和輸出時。其結果是端到端培訓時間提高了 8% 。
使用數據集打包最小化開銷
以前,對于小規模,我們使用了一種非填充策略,以最小化因序列長度和額外填充而產生的開銷。
另一種方法是 pack 以幾乎完全填充批處理矩陣的方式對序列進行處理,使得額外的填充可以忽略,同時在迭代期間保持緩沖區大小不變。
在我們的最新提交中,我們使用了序列打包算法來預處理中小規模( 64 GPU 或更少) NVIDIA Hopper 提交的訓練數據。這與前幾輪中采用的 1024 GPU 及更大規模的技術類似。
將 CPU 預處理與 GPU 操作重疊,以提高訓練時間
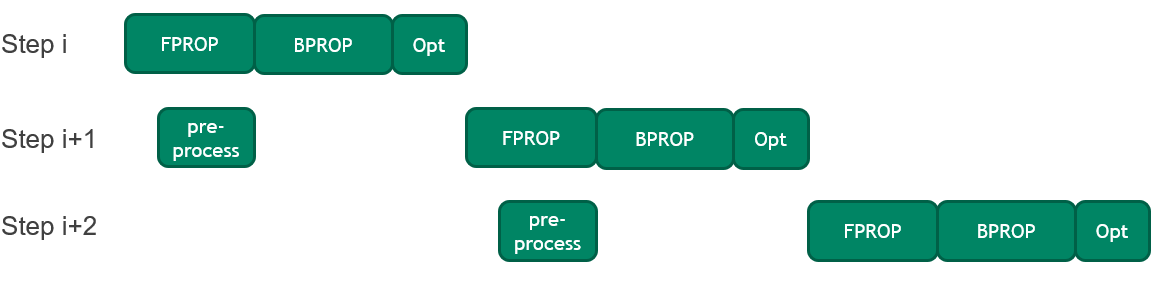
BERT 中的每個訓練步驟都涉及在將 CPU 上的輸入序列(也稱為小批量)復制到 GPU 之前對其進行預處理。
在這一輪中,引入了一種優化方法,將當前小批量的前向傳遞執行與下一個小批量的預處理相結合。這種優化減少了閑置 GPU 時間,這在 GPU 執行速度加快時尤為重要。它使端到端培訓時間提高了 2% 。
針對 H100 優化的新超參數和批量大小
憑借基于 NVIDIA Hopper 架構的新型 H100 Tensor Core GPU ,吞吐量隨著本地批量大小的增長而增長。因此,我們增加了每批加速器的大小,并相應地優化了訓練超參數。
ResNet-50 型
在這一輪 MLPerf 中,我們將卷積和內存綁定操作的融合擴展到外延融合之外,并提高了池化操作的性能。
Conv BN fprop 融合
ResNet-50 模型由 Conv- > BN- > Relu- > Conv- > BN- > Relu 模式組成,當執行內存綁定規范化層時,導致 Tensor 核心閑置。
在 MLPerf 培訓 2.1 中,BatchNorm分為BatchNorm Stats計算和BatchNorm Apply。
NVIDIA GPU 的可編程性使我們能夠在上一次卷積的尾波中融合統計數據計算,并在下一次卷積主循環中融合fuse Apply。
然而,對于權重梯度計算,這意味著必須通過融合wgrad中的BatchNorm Apply和ReLu來重新計算輸入。使用 cuDNN 中的新的高性能內核,這一特性為小規模帶來了 4.2% 的端到端加速。
更快的池操作
ResNet-50 模型在主干和分類器塊中采用maxPool和AvgPool操作。通過使用 cuDNN 中的新圖形 API ,并利用 NVIDIA H100 Tensor Core GPU 中更高的 DRAM 帶寬,我們將池化操作速度提高了 3 倍以上。這導致 MLPerf Training v2.1 的速度提高了 3% 以上。
視網膜網
本輪 MLPerf 中 RetinaNet 的主要優化是改進 NVCOCO 庫中的分數計算,以消除最大規模提交的 CPU 瓶頸。其他優化包括新的融合、擴展 CUDA 圖的范圍以減少 CPU 開銷,以及使用 DALI 庫來改進評估階段的數據預處理。
NVCOCO :加速得分
隨著 GPU 執行速度的加快,在 CPU 上執行的代碼部分可能會限制性能。在每 GPU 執行的工作量較小的大范圍內尤其如此。
目前,評估階段的 mAP 度量計算在 CPU 上運行,這是我們之前提交的最大規模中的性能瓶頸。
在這一輪 MLPerf 中,我們優化了此評估計算,以消除 CPU 瓶頸,并使 GPU 優化發揮作用。這尤其有助于最大規模的提交。
C ++擴展也在 NVIDIA cocoapi 中進一步優化。對于其 mAP 度量計算,我們將 COCO 的性能比 original cocoapi implementation 提高了 3 倍,總體性能提高了 20 倍。這些優化主要集中于文件 I / O 、內存訪問和負載平衡。
我們將 pybind11 替換為本機 C NumPy PyModules ,作為 Python 和 C ++之間的接口。通過在 C ++端直接讀取 JSON 文件并與 Python 對象的 C Python 指針交互,我們消除了以前可能存在的深度副本。
此外,循環轉換(如循環融合和循環重新排序)顯著提高了多線程的緩存位置和內存訪問效率。
我們在 OpenMP 中添加了更多的并行區域,以利用額外的并行性,并調整了任務調度,以更好地實現線程間的負載平衡。
度量計算中的這些優化總體上在 160 節點規模上實現了約 60% 的端到端性能改進。從關鍵路徑中消除 CPU 瓶頸也使我們能夠將最大規模從 160 個節點增加到 256 個節點。盡管實現目標精度所需的時間增加了,但這將使總訓練時間減少約 30% 。
COCO 優化的總端到端加速是 2.3 倍。
擴展 CUDA 圖:無同步 Adam 優化器
CUDA Graphs 提供了一種在沒有 CPU 干預的情況下啟動多個 GPU 內核的機制,從而減輕了 CPU 開銷。
在 MLPerf Training v2.0 中, CUDA 圖形在我們的 RetinaNet 提交中被廣泛使用。然而,由于優化器實現中的 CPU- GPU 同步,梯度縮放和 Adam 優化器步驟被排除在圖形捕獲的區域之外。
在提交的 MLPerf Training v2.1 中, Adam 優化器進行了修改,以實現無同步操作。這使我們能夠進一步擴展 CUDA 圖的范圍并減少 CPU 開銷。
附加 cuDNN 運行時融合
除了先前提交的 MLPerf 中使用的 conv-bias-relu 融合外,通過使用 cuDNN 運行時融合,在 RetinaNet 主干中使用了 conv-scale-bias-relu-fusion 。這使我們能夠避免內核啟動延遲和數據移動,從而實現 1.5% 的端到端加速。
評估期間使用 NVIDIA DALI
在訓練通行證中取得了顯著的提速,從而增加了評估階段所花費的時間比例。
NVIDIA DALI 以前在培訓期間使用,但在評估期間未使用。為了解決相對較慢的評估迭代時間,我們使用 DALI 來有效地加載和預處理數據。
面罩 R-CNN
在這一輪 MLPerf 中,除了改進 Mask R-CNN 不同塊的并行化之外,我們啟用了新的內核融合,并減少了訓練迭代中的 CPU 開銷。
更快的 JSON 解釋器
從 ujson 切換到 orjson 將 COCO 2017 注釋文件的加載時間縮短了約 1.5 秒。
更快的評估和 NVCOCO 優化
我們使用為 RetinaNet 解釋的 NVCOCO 改進,將所有 Mask R-CNN 配置的端到端時間縮短了約 2 秒。平均而言,這些優化將每個歷元的評估時間減少約 2 秒,但只有最后一次評估在端到端時間內公開。
優化后的 NVCOCO 庫是一個即時替代品,使最終用戶可以直接使用優化。
矢量化批量 ROI 對齊
感興趣區域( ROI )對齊執行雙線性插值,這需要大量的數學工作。由于這項工作對于所有通道都是相同的,因此在通道維度上進行矢量化可將所需的工作量減少約 4 倍。
計算啟動配置的方式也進行了更改,以避免啟動超出需要的 CUDA 線程。
綜合這些努力, ROI Align 正向傳播的性能提高了約 5 倍。
在模型代碼中展示更多的并行性
與大多數模型一樣, Mask R-CNN 包含了許多可以并行執行的代碼段。例如,遮罩水頭損失計算涉及計算多個提案的損失,其中每個提案的損失可以獨立計算。
我們通過識別這些可以并行化的部分并將它們放在單獨的 CUDA 流上,實現了 3-5% 的加速。
刪除更多 CPU- GPU 同步
在沒有使用 CUDA 圖的代碼部分, GPU 內核從 CPU 代碼啟動。 CPU 代碼主要執行簿記任務,如管理內存、跟蹤指針和索引等。
如果 CPU 代碼不夠快, GPU 內核將在下一個內核啟動之前完成并處于空閑狀態。將 CPU 性能提高到代碼的 CPU 部分比 GPU 部分運行得更快的程度對于最大化訓練性能至關重要。這需要一定量的 CPU 提前運行。
CPU- GPU 同步防止了這一點,因為它們會使 CPU 保持空閑狀態,直到當前 GPU 工作完成,因此刪除 CPU- GPU 同步對訓練性能也至關重要。
我們在過去的幾輪提交中使用 NVIDIA A100 Tensor Core GPU 完成了這項工作。然而, NVIDIA H100 Tensor Core GPU 提供的顯著性能提高需要刪除更多這些 CPU- GPU synchronization 。
這對 NVIDIA A100 Tensor Core GPU 的結果影響很小,因為 CPU 開銷不像 Mask R-CNN 上的 GPU 。然而,對于 32- GPU 配置,它將 H100 Tensor Core GPU 的性能提高了 25-30% 。
RPN 和 FPN 中的運行時融合
在前幾輪中,我們使用cudnn v8 API 為 Mask R-CNN 的 ResNet-50 主干執行運行時融合,從而加快了代碼的速度。
在這一輪中, RetinaNet 利用先前的工作將運行時融合擴展到 RPN 和 FPN 模塊,進一步將端到端性能提高約 2% 。
AI 性能提高 6.7 倍
基于 NVIDIA Hopper 架構的 NVIDIA H100 GPU 為 NVIDIA AI 平臺帶來了下一個巨大的性能飛躍。與首次提交的 A100 GPU 相比,它的性能提高了 6.7 倍。
僅通過軟件改進, A100 GPU 在最新一輪中的性能就比首次提交的高出 2.5 倍,展示了 NVIDIA AI 平臺持續的全棧創新。
用于 NVIDIA MLPerf 提交的所有軟件都可以從 MLPerf 存儲庫中獲得,您可以復制我們的基準測試結果。我們不斷將這些前沿的 MLPerf 改進融入到我們的深度學習框架容器中。這些容器是 available on NGC ,我們用于 GPU 優化應用程序的軟件中心。