
人工智能正在改變計算方式,推動AI在全球范圍內的應用部署。智能聊天機器人、圖像和視頻合成的簡單文本提示、個性化內容推薦以及醫學成像只是人工智能應用的幾個例子。
推理工作負載對計算要求很高,而且多種多樣,要求平臺能夠快速處理從未見過的數據上的許多預測,并在各種人工智能模型上運行推理。希望部署人工智能的組織需要一種方法,在各種工作負載、環境和部署場景中客觀評估基礎設施的性能。人工智能訓練和推理都是如此。
MLPerf 推理 v3.1 是由 MLCommons 聯盟開發的最新版本,它是行業標準的人工智能推理基準套件。這個版本補充了 MLPerf 培訓和 MLPerf HPC。MLPerf 推理 v3.1 能夠衡量各種重要工作負載的推理性能,包括圖像分類、對象檢測、自然語言處理、語音識別和推薦系統,以及常見的數據中心和邊緣部署場景。
MLPerf 推理 v3.1 包括兩個重要的更新,以更好地反映現代人工智能用例:
- 添加大語言模型(LLM)測試,基于 GPT-J——一種開源的 6B 參數 LLM——來表示文本摘要的生成式人工智能。
- 更新的 DLRM 測試具有新的模型架構和更大的數據集,這些都反映了在 MLPerf Training v3.0 中引入的 DLRM 更新,更好地反映了現代推薦系統的規模和復雜性。
由完整的NVIDIA AI Inference software stack,包括最新的 TensorRT 9.0,NVIDIA 在 MLPerf 推理 v3.1 中使用了廣泛的產品進行提交。其中包括首次提交的NVIDIA GH200 Grace Hopper Superchip,擴展了NVIDIA H100 Tensor Core GPU。NVIDIA 還提交了NVIDIA L4 Tensor Core GPU對于主流服務器,以及NVIDIA Jetson AGX Orin 和 Jetson Orin NX邊緣人工智能和機器人平臺。
這篇文章的其余部分提供了 NVIDIA 提交的精彩內容,以及這些非凡成果是如何實現的。
Grace Hopper 超級芯片擴展 NVIDIA Hopper 推理性能
NVIDIA GH200 Grace〔Hopper〕超級芯片通過相干 NVLink-C2C 結合了 NVIDIA Hopper GPU 和 NVIDIA Grace CPU,以 900 GB/s 的速率創建單個超級芯片。這比 PCIe Gen5 高 7 倍,功耗降低 5 倍。此外,它還通過 96 GB HBM3 GPU 內存和 480 GB 低功耗、高帶寬 LPDDR5X 內存的組合,集成了高達 576 GB 的快速訪問內存。
GH200 Grace Hopper 超級芯片具有集成電源管理功能,使 GH200 能夠利用 能源效率 的 Grace CPU,以平衡效率和性能。有關詳細信息,請參閱 NVIDIA Grace Hopper 超級芯片架構深度解析 以及 NVIDIA Grace Hopper 超級芯片架構 白皮書。
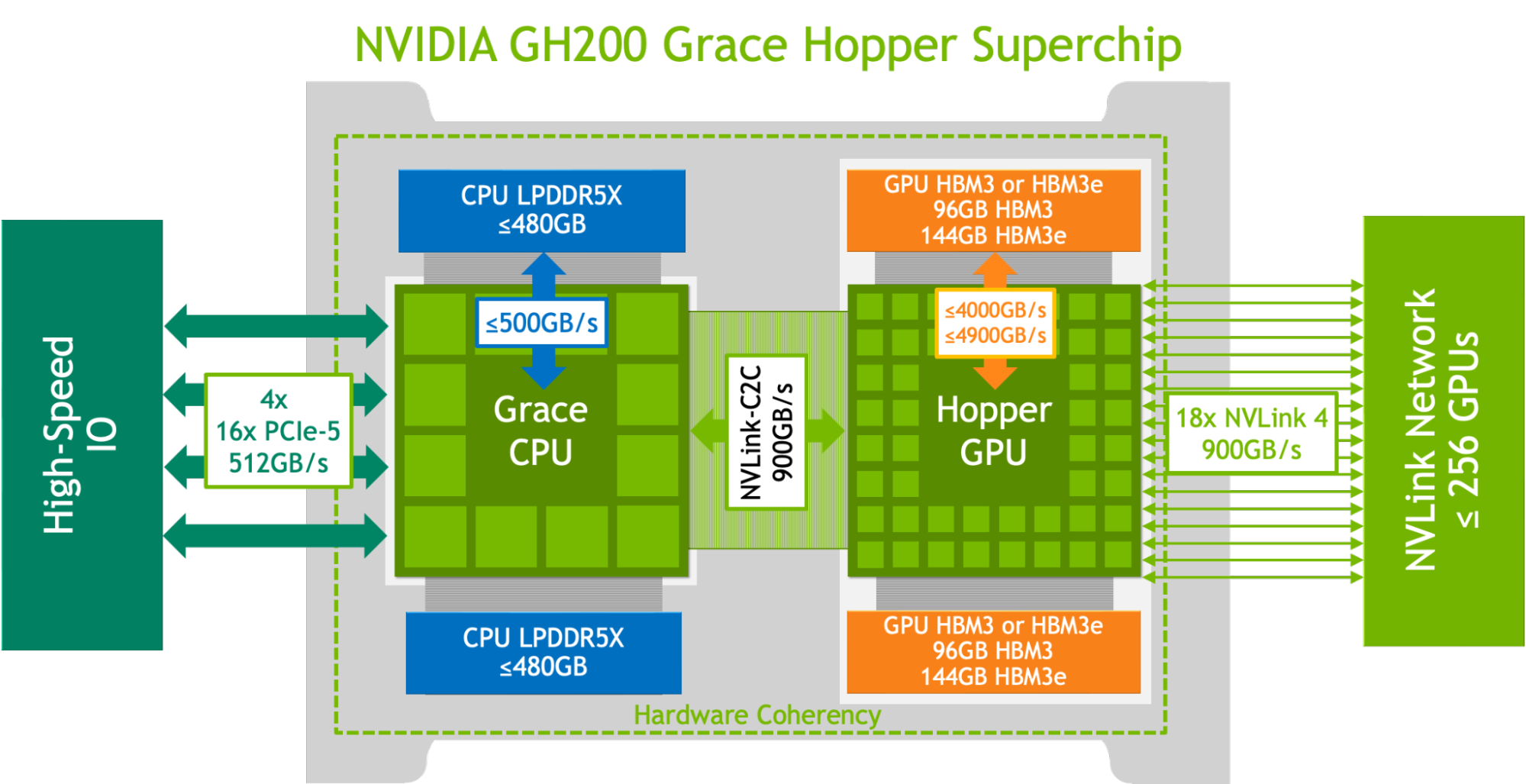
這個 NVIDIA GH200 Grace Hopper Superchip 是專為在計算和內存密集型工作負載中提供領先性能所需的多功能性而設計的。它還在最苛刻的前沿工作負載上提供了更高的性能,例如基于 transformer 的大型模型(具有數千億或數萬億參數)、具有數萬億字節嵌入表的推薦系統和矢量數據庫。
GH200 Grace Hopper 超級芯片除了針對最密集的人工智能工作負載而構建外,還針對 MLPerf 推理測試的流行主流工作負載而大放異彩。它運行了每一次測試,展示了它對完整 NVIDIA 軟件堆棧的無縫支持。它擴展了 NVIDIA 在每個工作負載上提交的單個 H100 SXM 所實現的卓越性能。
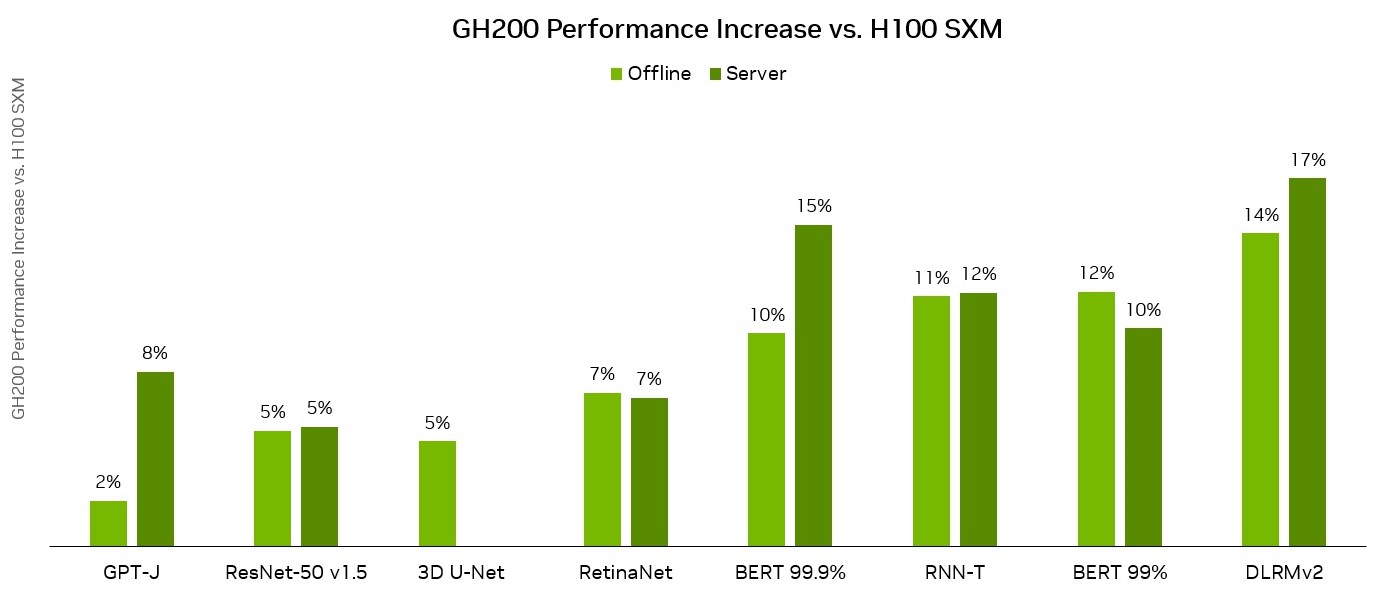
MLPerf 推斷:Datacenter v3.1,已關閉。提交 ID: NVIDIA 3.1-0107(1xH100 SXM),3.1-0110(1xGH200 Grace Hopper 超級芯片)
MLPerf 的名稱和標志是 MLCommons 協會在美國和其他國家的商標。保留所有權利。未經授權,嚴禁使用。更多詳細信息,請訪問www.mlcommons.org。
GH200 Grace Hopper 超級芯片包含 96 GB 的 HBM3,并提供高達 4 TB/s 的 HBM3 內存帶寬,而 H100 SXM 分別為 80 GB 和 3.35 TB/s。與 NVIDIA H100 SXM 相比, NVIDIA GH200 Grace Hopper 超級芯片的更大內存容量和更大的內存帶寬使其能夠為工作負載使用更大的批量。例如,在服務器場景中,RetinaNet 和 DLRMv2 的批處理大小都增加了一倍,在離線場景中,批處理大小增加了 50%。
GH200 Grace Hopper 超級芯片 NVIDIA Hopper GPU 和 Grace CPU 之間的高帶寬通過 NVLink-C2C 鏈路實現了 CPU GPU 之間的快速通信,這有助于提高性能。
例如,在 MLPerf DLRMv2 工作負載中,通過 PCIe 傳輸一批張量占用 H100 SXM 上大約 22%的批推斷時間。然而,由于 NVLink-C2C,GH200 Grace Hopper 超級芯片僅使用 3%的推理時間進行了相同的傳輸。
由于具有更高的內存帶寬和更大的內存容量,與 MLPerf 推理 v3.1 工作負載上的 H100 GPU 相比,Grace Hopper 超級芯片的每芯片性能優勢高出 17%。這些結果展示了 GH200 Grace Hopper 超級芯片和 NVIDIA 軟件堆棧的性能和多功能性。
優化 GPT-J 6B 用于 LLM 推理
為了表示 LLM 的推理工作負載,MLPerf 推理 v3.1 引入了一種基于 GPT-J 6B 模型的新測試:具有 6B 參數的 LLM。新基準測試的任務是使用CNN / DailyMail 數據集。
NVIDIA 平臺在 GPT-J 工作負載方面取得了優異的成績,GH200 Grace Hopper Superchip 在離線和服務器場景中的每加速器性能都達到了最高水平。 NVIDIA L4 GPU 還提供了強大的性能,超過了最好的 CPU ——在熱設計功率(TDP)僅為 72 瓦的 1 插槽 PCIe 卡中,僅獲得 6 倍的性能。
為了實現這些結果,用于 LLM 推理的 NVIDIA 軟件智能地應用 FP8 和 FP16 精度,以提高性能,同時滿足目標精度要求。
執行 GPT-J 推斷的關鍵挑戰是 transformer 塊中的鍵值(KV)高速緩存的高內存消耗。通過以 FP8 數據格式存儲 KV 緩存, NVIDIA 提交顯著增加了所使用的批處理大小。這提高了 GPU 內存利用率,并能夠更好地利用 NVIDIA GPU 巨大的計算性能。
啟用 DLRM-DCNv2 提交
MLPerf 推理 v3.1 引入了對基準測試先前版本中使用的 DLRMv1 模型的更新。這個 DLRMv2 模型采用了三層DCNv2 cross network。DLRMv2 還使用多個 hot 分類輸入,而不是一個 hot,這些輸入來自Criteo Terabyte Click Logs Dataset。
推薦推理的挑戰之一來自于在系統上擬合嵌入表。通過將模型轉換為 FP16 精度,包括嵌入表,我們既可以提高性能,又可以將嵌入表的內存占用減半,將其減少到 49GB。這使得整個嵌入表能夠適應單個 H100 GPU 。
為了使我們能夠在具有 24GB 內存的 L4 GPU 上提交, NVIDIA 軟件使用通過分析訓練數據集獲得的行頻率數據,智能地在 GPU 和主機內存之間分割嵌入表。使用這些數據, NVIDIA 軟件可以通過在 GPU 上存儲最常用的嵌入表行,最大限度地減少主機 CPU 和 GPU 之間的內存傳輸。
NVIDIA 平臺在 DLRMv2 上展示了非凡的性能,GH200 與 H100 SXM 相比,性能提升了 17%。
使用可編程視覺加速器最大限度地提高 NVIDIA Jetson Orin 的并行性
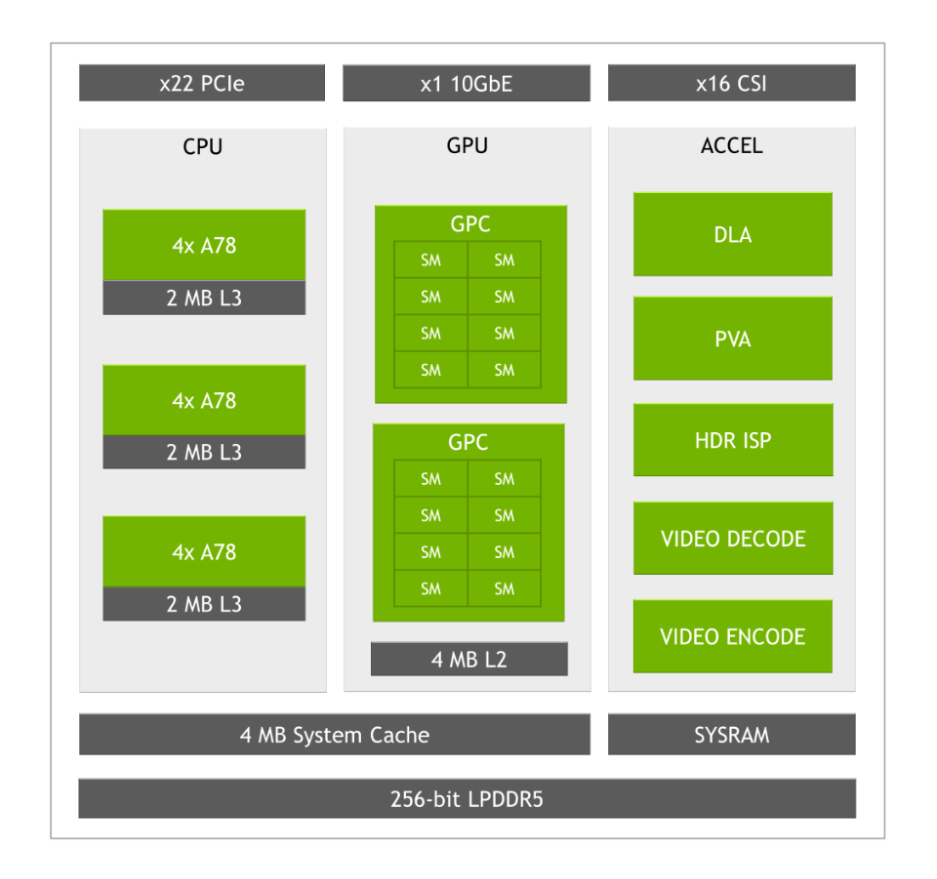
Jetson AGX Orin series and Jetson Orin NX series 是基于 NVIDIA Orin 片上系統(SoC)的邊緣人工智能和機器人的嵌入式模塊。為了在一系列用例中提供卓越的人工智能性能和效率,Jetson Orin 集成了許多計算引擎:
- A GPU 基于 NVIDIA Ampere Architecture,具有第三代張量核心。
- 兩個第二代,固定功能的 NVIDIA Deep Learning Accelerators(NVDLA v2.0)
- 一個第二代可編程視覺加速器(PVA v2.0)。
這些加速器可用于卸載 GPU ,并在 Jetson Orin 模塊上實現額外的 AI 推理性能。
NVDLA 是一款針對深度學習操作進行優化的固定函數加速器,旨在實現卷積神經網絡推理的全硬件加速。
在 MLPerf 推理 v3.1 中,我們首次證明了 PVA 與 GPU 和 DLA 同時用于推理。第二代 PVA 為各種計算機視覺內核提供了專用硬件,如濾波、扭曲和快速傅立葉變換(FFT)。它還支持高級編程內核,可以作為 TensorRT 自定義插件的后端運行時。
在 23.08 Jetson CUDA -X AI 開發者預覽版中,我們包含了一個示例 PVA SDK。此包為非最大值抑制(NMS)層提供運行時支持。這表明 PVA 可以作為一種高效的加速器,補充強大的 Jetson Orin GPU 。
NVIDIA 開發了一個 TensorRT 自定義 NMS-PVA 插件,作為 Jetson Orin 用戶的參考,并將其作為 NVIDIA MLPerf 推理 v3.1 提交的一部分。
在 NVIDIA Orin 平臺上提交的 NVIDIA MLPerf 推理 v3.0 RetinaNet 中, GPU 處理了來自 GPU ResNext+FPN 骨干網以及兩個 DLA 的所有輸出。
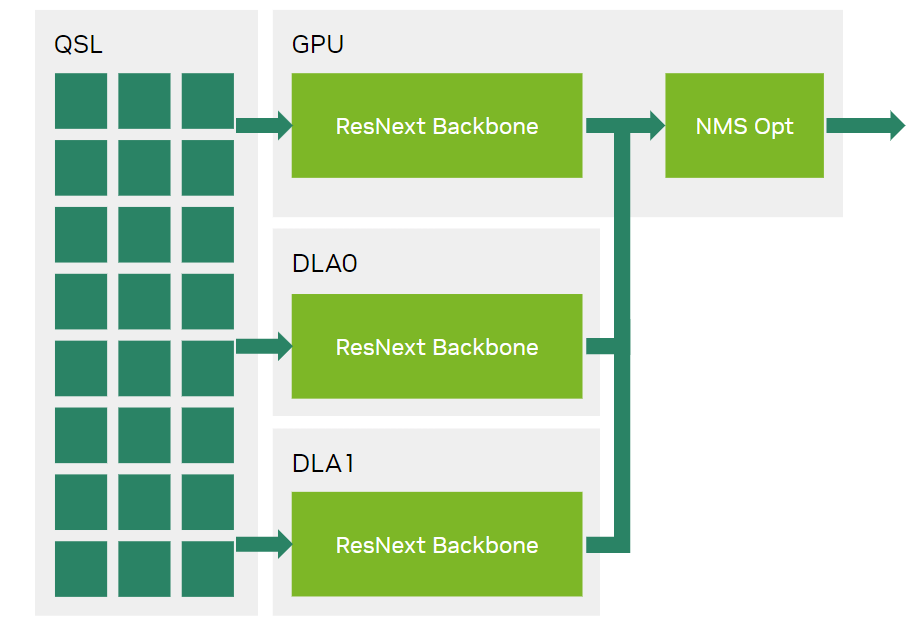
圖 5 顯示了在 MLPerf 推理 v3.0 提交中, GPU 是如何負責 GPU 和 DLA 的 ResNext+FPN 主干的輸出的。
通過使用 NMS-PVA 插件,NMS 操作員現在可以從 GPU 卸載到 PVA,從而在 Jetson Orin AGX 和 Jetson Orin NX 上實現三個完全并行的推理流。在兩個 DLA 上運行的 ResNext 和 FPN 骨干網的輸出現在由在端到端 RetinaNet TensorRT 引擎內運行 NMS-PVA 插件的兩個 PVA 消耗。
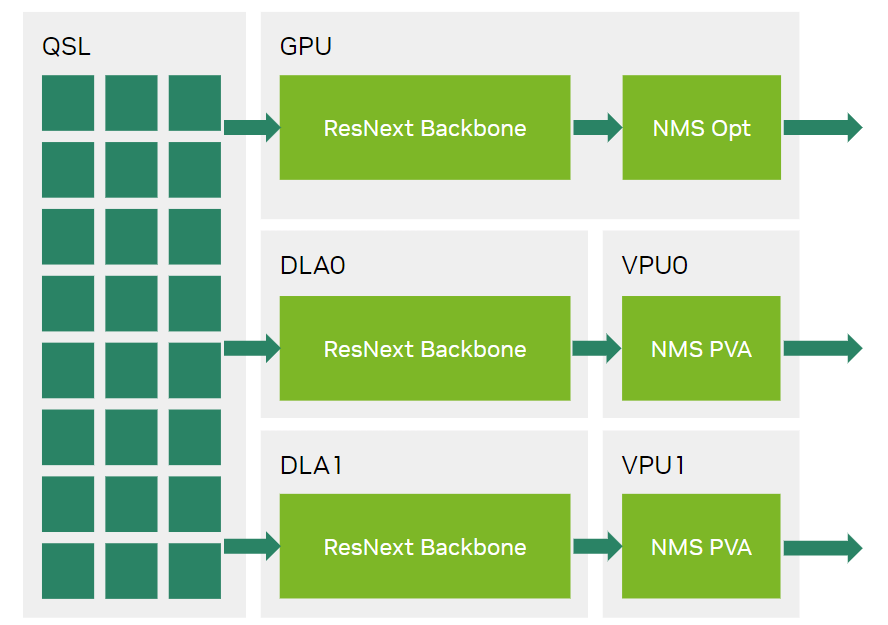
在圖 6 中, NVIDIA MLPerf 推理 v3.1 提交通過優化使用 Jetson Orin PVA,使計算能夠完全并行運行。
PVA 與 GPU 和 DLA 的精心使用將 Jetson AGX Orin 64GB 和 Jetson Orin NX 16GB 模塊的性能提高了 30%。當 PVA 的這種使用與新優化的 NMS-Opt GPU 插件相結合時, Jetson AGX-Orin 在 RetinaNet 工作負載上的性能提高了 61%,功率效率提高了 38%。 Jetson Orin NX 16GB 顯示出更大的增益,在同一測試中性能提升了 84%。
算法優化進一步提高 BERT 性能
在 MLPerf 推理 v3.1 中, NVIDIA 使用 OmniML 團隊開發的技術,在開放部門中使用 L4 GPU 提交了關于 BERT 大型工作負載的報告。OmniML 是 NVIDIA 于 2023 年初收購的一家初創公司,為從云平臺到邊緣設備的用例帶來了機器學習算法模型優化方面的專業知識。
BERT 上的開放劃分提交應用了結構化修剪和蒸餾技術,在保持 99%準確率的同時,將性能提高了 4.7 倍。本次提交展示了算法優化的潛力,可以顯著增強 NVIDIA 平臺本已卓越的性能。
NVIDIA 部署了一種專有的自動結構化修剪工具,該工具使用基于梯度的靈敏度分析將模型修剪為給定的目標 FLOP,并通過蒸餾對其進行微調,以恢復大部分精度。在保持嵌入維度不變的情況下,在模型中的所有 transformer 層中修剪 transformer 層的數量、注意力頭和線性層維度。
與原始的 MLPerf 推理 BERT INT8 模型相比,我們的修剪模型將參數數量減少了 4 倍,FLOP 數量減少了 5.6 倍。該模型在每層中具有不同數量的頭部和線性層尺寸。根據修剪后的模型構建的 TensorRT 發動機比 607 MB 小 3.4 倍,177 MB。
使用 NVIDIA 閉除法提交中使用的相同技術,將微調模型量化為 INT8 精度。提交的文件還采用了量化感知訓練(QAT)期間的蒸餾,以實現 99%或更高的準確性。
| 腳本 | 封閉式分部 | 開放式部門 | 加速 |
| 脫機采樣/秒 | 1029 | 4609 | 4.5 倍 |
| 服務器采樣數/秒 | 899 | 4265 | 4.7 倍 |
| 單流 p90 延遲(ms) | 2.58 | 0.82 | 3.1 倍 |
為了更好地了解每個模型優化如何影響性能, NVIDIA 進行了堆疊分析,并分別應用了不同的模型優化方法(圖 8)。
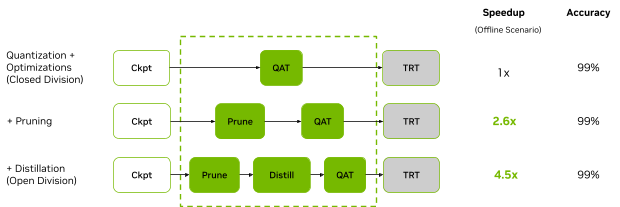
圖 7 顯示,通過模型修剪和蒸餾,與在離線場景中運行相同的 GPU 相比,使用 L4 的 NVIDIA 對 BERT 工作負載的開放劃分提交提供了 4.5 倍的加速。
應用的每種模型優化方法都可以很容易地相互集成。與基線模型相比,它們共同帶來了顯著的性能改進。
NVIDIA 加速計算提升推理和 AI 訓練工作負載的性能
在其 MLPerf 首秀中,GH200 Grace Hopper 超級芯片在數據中心類別的封閉部門的所有工作負載和場景中都表現出色,在 NVIDIA 單芯片 H100 SXM 提交的產品中,性能提高了 17%。 NVIDIA 軟件堆棧目前完全支持 GH200 Grace Hopper 超級芯片。
對于主流服務器,L4 GPU 在緊湊、低功耗的 PCIe 附加卡中實現了對 CPU 的巨大性能飛躍。
對于邊緣 AI 和機器人應用, Jetson AGX-Orin 和 Jetson Orin-NX 模塊實現了出色的性能。軟件優化有助于進一步釋放為這些模塊提供動力的強大 NVIDIA Orin SoC 的潛力。它將廣受歡迎的物體檢測人工智能網絡 RetinaNet 的性能提高了 84%。
在這一輪中, NVIDIA 還提交了開放部門的結果,首次展示了模型優化的潛力,以顯著提高推理性能,同時仍能實現卓越的準確性。
最新的 MLPerf 推理 v3.1 基準測試表明, NVIDIA 加速計算平臺繼續提供領先的性能和多功能性。技術堆棧的每一層都有創新,從云到邊緣,以光速。
?






