
為了高效應對 AI 工作負載,數據中心正在被重構。這是一項非常復雜的工作,因此,NVIDIA 目前正在交付以 NVIDIA 機架級架構為單位的 AI 工廠。為了讓 AI 工廠發揮最佳性能,許多加速器需要以更大的帶寬和更低的延遲在機架規模上協同工作,并以最節能的方式支持盡可能多的用戶。
設計滿足這些需求的機架會面臨許多技術挑戰。這需要高密度的加速器、網卡(NICs)、交換機以及縱向擴展和橫向擴展網絡,所有這些都緊密相關。這種高密配置對于提供當今 AI 所需的高級計算能力和背板帶寬至關重要。
傳統的風冷方法通常不足以滿足此類高密部署的需求,因此需要高密度液冷機架,例如 NVIDIA NVLink 高速縱向擴展互連技術。圖 1 說明了 NVLink 和更大的縱向擴展域如何提供最佳性能。NVIDIA 機架式擴展解決方案提供了一條經過驗證的可擴展路徑,通向更快速、更高效的基礎設施。
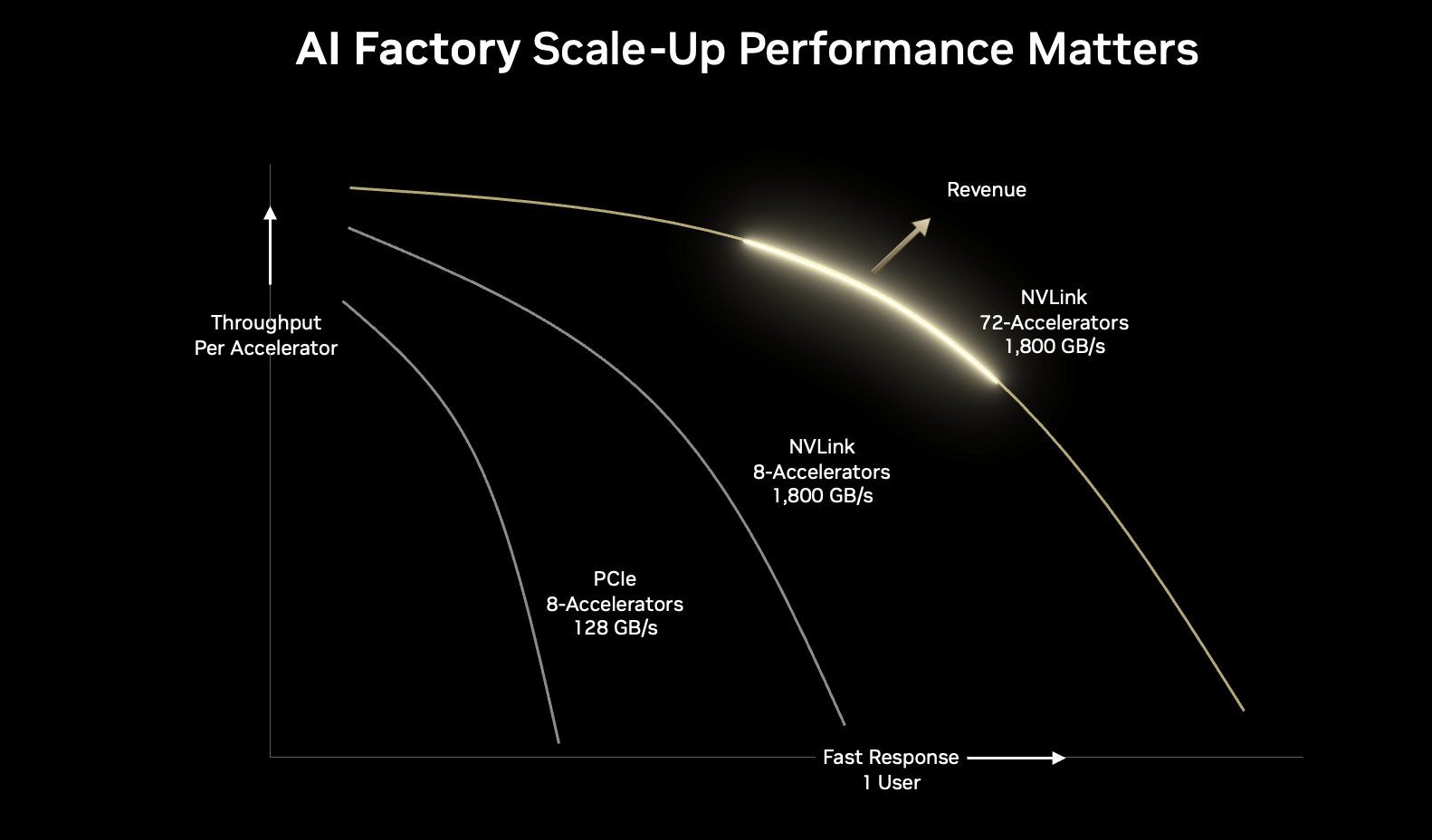
圖 1. 性能隨著 NVIDIA NVLink 域的擴大而提升
NVIDIA AI 工廠生態系統?
NVIDIA 為 AI 工廠建立了成熟的生態系統。其中包括先進 GPU 技術和用于縱向擴展計算網的 NVIDIA NVLink。NVIDIA NVLink Switch 芯片可在 72 個 GPU的 NVLink 域中實現 130 TB/s 的 GPU 帶寬。NVIDIA Quantum-X800 InfiniBand、NVIDIA Spectrum-X Ethernet 和 NVIDIA Bluefield-3 DPU 支持擴展到數十萬個 GPU。
此外,與領先的傳統 CPU 相比,NVIDIA Grace 等高性能 CPU 可提供高達 2 倍的能效,并在低功耗的情況下提供驚人的帶寬。這種機架級架構在廣大的 OEM 和 ODM 合作伙伴網絡的支持下,已經部署到各大云提供商,奠定了現代 AI 工廠的基礎。
面向半定制 AI 基礎架構的 NVIDIA NVLink Fusion
新推出的?NVIDIA NVLink Fusion 是一種面向芯片的技術,可讓超大規模企業利用 NVIDIA NVLink 生態系統構建半定制 AI 基礎設施。
NVLink Fusion 使用戶能夠半定制 ASIC 或 CPU,從而 實現出色的性能擴展。那些超大規模企業可以直接用到 NVLink、?NVIDIA NVLink-C2C?、?NVIDIA Grace CPU?、NVIDIA GPU、?NVIDIA CPO?網絡、機架擴展架構和?NVIDIA Mission Control?軟件的創新成果。
由于超大規模企業已經在部署完整的 NVIDIA 機架級解決方案,這使他們能夠在 AI 工廠中提供異構芯片產品,同時在單一可擴展的硬件基礎設施上實現標準化。憑借 NVIDIA 豐富的基礎設施合作伙伴生態系統,NVLink Fusion 使用者可輕松進行大規模部署和管理。
NVIDIA NVLink 縱向擴展互連
NVLink Fusion 的核心是突破性互連技術 NVLink。為了充分發揮大規模 AI 模型的潛力,機架內每個 GPU 之間的無縫通信至關重要。第 5 代 NVLink 可為每個 GPU 提供?1.8 TB/s?的雙向帶寬,是 PCIe Gen5 帶寬的 14 倍,可在非常復雜的大型模型中實現無縫高速通信。它還通過面向集合通信的網絡計算技術提高了吞吐量并降低了延遲。NVLink 帶寬每擴展 2 倍,即可將機架級 AI 性能提升 1.3-1.4 倍。
半定制 AI 基礎架構的行業應用
NVLink Fusion 使超大規模企業能夠將其半定制 ASIC 無縫集成到高度優化和廣泛部署的數據中心架構中。NVLink Fusion 包含 NVLink 芯片,可通過相同的 NVIDIA 機架級擴展架構來縱向擴展 NVIDIA 和半定制 ASIC 的混合基礎設施,并與 NVIDIA CPU、NVIDIA NVLink 交換機、NVIDIA ConnectX Ethernet SuperNIC、NVIDIA BlueField DPU 以及用于橫向擴展解決方案的 NVIDIA Quantum 和 NVIDIA Spectrum-X 交換機搭配使用。領先的超大規模企業已經在部署 NVIDIA NVLink 全機架解決方案,并且通過使用 NVLink Fusion 在同一機架架構上實現異構芯片數據中心的標準化,從而加快產品上市時間。
NVLink Fusion 技術還為 AI 創新者開辟了另一種集成途徑,即通過 NVIDIA NVLink-C2C 技術將半定制 CPU 連接到 NVIDIA GPU。合作伙伴可以將其先進的 CPU 技術與 NVIDIA GPU 相結合,實現內存一致性,從而提供 NVIDIA 全棧 AI 基礎架構產品。NVIDIA NVLink-C2C 最初應用于 NVIDIA Grace Hopper 和 NVIDIA Grace CPU 超級芯片,可提供?900 GB/s?的一致性互連帶寬。
圖 2 顯示了不同的 NVLink Fusion 組合選項。

圖 2. NVLink Fusion 機架部署示例
專為 AI 工廠打造的軟件
通過 NVLink Fusion 連接的 AI 工廠可以由 Mission Control 提供支持,這是一個統一的運營和編排軟件平臺,可自動執行 AI 數據中心和工作負載的復雜管理。
從配置部署到驗證基礎設施,再到編排任務關鍵型工作負載,Mission Control 可增強 AI 工廠運營,幫助企業更快地啟動和運行前沿模型
NVLink Fusion 合作伙伴生態系統
NVIDIA 生態系統涵蓋定制芯片設計師、CPU、IP 和 OEM/ODM 合作伙伴,提供通過 NVIDIA 來大規模部署定制芯片的完整解決方案。借助 NVLink Fusion,他們可以與 NVIDIA 合作伙伴生態系統合作,將 NVIDIA 機架級解決方案部署集成到數據中心基礎設施中。高性能 AI 工廠可以快速縱向擴展,以滿足模型訓練和代理式 AI 推理等嚴苛工作負載的需求。
面向 AI 的 加速網絡 平臺
NVIDIA Quantum-X800 InfiniBand 平臺、NVIDIA Spectrum-X Ethernet 網絡平臺、NVIDIA Bluefield-3 DPU 和 NVIDIA Connect-X SuperNIC 可以為大規模 AI 數據中心提供可擴展的性能、效率和安全性。
NVLink Fusion 可為系統中的每個 GPU 提供 800 Gb/s 的總數據吞吐量,并與 Quantum-X800 和 Spectrum-X 平臺無縫集成,使 AI 工廠和云數據中心能夠在沒有瓶頸的情況下處理萬億參數模型。
NVIDIA 光電一體化(CPO) 交換機是 NVIDIA Quantum-X 和 Spectrum-X 平臺的一部分,通過集成硅光技術取代了可插拔光模塊,與傳統網絡相比,其能效提高了?3.5 倍?,網絡可靠性提高了 10 倍,信號完整性提高了 63 倍,部署時間縮短了 1.3 倍。
NVIDIA 的 CPO 網絡簡化了管理和設計,為計算基礎設施提供更強大的功能。這些優勢對于邁向未來百萬級 GPU 的 AI 工廠至關重要。
BlueField-3 DPU 擴展到整個數據中心,可加速 GPU 對數據的訪問、保障云上多租戶的安全和高效的數據中心運營。NVIDIA GB300 NVL72 架構率先在 GPU 和 ConnectX-8 SuperNIC 之間引入 PCIe Gen6 連接,無需獨立的 PCIe 交換機接口。新的 I/O 模塊將在同一設備上配備兩個 ConnectX-8 芯片,為系統中的每個 GPU 提供全速的 800 Gb/s 網絡連接。
總結?
AI 變革所需的基礎設施不但強大,還要敏捷、可擴展且高效。僅靠添加更多的獨立服務器或組件已不再可行。未來依賴于深度集成的機架級解決方案,使海量計算資源能夠作為一個統一的整體運行。NVIDIA 的 NVLink 技術一直在其 GPU 平臺上處于縱向擴展架構的前沿。現在,借助 NVLink Fusion,NVIDIA 將這種經過驗證的出色性能擴展能力應用到半定制芯片領域。
?






