
RAPIDS 機器學習庫 cuML 支持多種類型的輸入數據格式,同時嘗試以最適合用戶工作流的輸出格式返回結果。 RAPIDS 團隊為 cuML 添加了支持不同類型用戶的功能:

最大化兼容性
使用現有 NumPy 、 Scikit-learn 和傳統的基于 PyData 庫的工作流的用戶: cuML 的默認行為,允許盡可能多的格式,以及其基于 Scikit-learn 的 API 設計,允許以最小的工作量和無中斷的方式移植這些工作流的一部分。因此,例如,您可以使用 NumPy 數組作為輸入,然后返回 NumPy 數組作為輸出,正如您所期望的那樣,只是速度要快得多。
最大化性能
希望通過將所有內容都保存在 GPU 內存中來獲得最終性能的用戶: cuML 使用的開源標準和行為的可配置性允許用戶以較低的努力實現最高性能。本文將詳細介紹用戶如何利用這項工作從 cuML 和 GPU s 中獲得最大的好處。
兼容的輸入格式: CUDA 數組接口的奇跡
很大程度上要感謝 cuda_array_interface ,即所謂的 CAI , cuML 接受多種數據格式:
- cuDF 對象(數據幀和序列)
- pandas 對象(數據幀和序列)
- NumPy 陣列
- CuPy 和 Numba 設備陣列
- 任何與 CAI 兼容的對象,如 PyTorch 和 CuPy 數組。這組被稱為 CAI 數組。
這個列表根據用戶需求不斷擴展。例如, cuML 團隊正在為 dlpack 陣列標準開發 直接支持 ,與 TensorFlow 的新支持正好吻合。也可以通過 cuDF 還是丘比 或 dlpack 支持來實現。如果您有當前不支持的特定數據格式,請提交問題或請求 在 GitHub 上 。
默認行為: cuML 如何開箱即用?
cuML 的默認行為被設計成盡可能多地鏡像輸入。因此,例如,如果您在 cuDF 中執行 ETL ,這對于 RAPIDS 用戶非常典型,您將看到如下內容:
| import cuml | |
| import cudf | |
| df = cudf.DataFrame() | |
| df[1] = [1.0, 2.0, 5.0] | |
| df[2] = [4.0, 2.0. 1.0] | |
| df[3] = [4.0, 2.0. 1.0] | |
| kmeans = cuml.KMeans(n_clusters=2) | |
| kmeans.fit(df) | |
| print(type(kmeans.labels_)) | |
| # <class 'cudf.core.series.Series'> |
 by
by 使用 cuDF 數據幀時, cuML 會返回 cuDF 對象(在本例中是一個序列)。但是,如前所述, cuML 還允許您在不更改 cuML 調用的情況下使用 NumPy 數組:
在本例中,現在 cuML 以 NumPy 數組的形式返回結果。鏡像輸入數據類型格式是 cuML 的默認行為,通常情況下,該行為是:
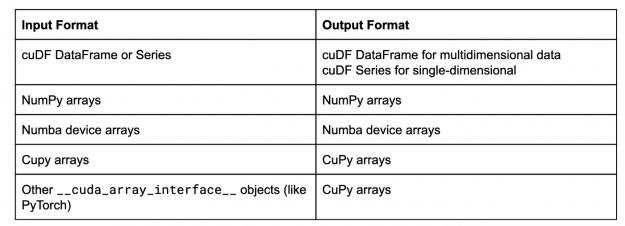
這個列表在不斷增長,所以希望很快能在該表中看到類似 dlpack 兼容庫的內容。
可配置性:如何讓 cuML 按自己的方式工作?
cuML 允許用戶全局配置輸出類型。例如,如果您的 ETL 和機器學習工作流基于 GPU ,但依賴于基于 NumPy 的可視化框架,請嘗試以下操作:
使用 set_global_output_type 指令會影響對 cuML 的所有后續調用。如果用戶需要更細粒度的控制(例如,您的模型由 GPU 庫處理,但只有一個模型需要是 NumPy 數組才能進行專門的可視化),則可以使用以下機制:
- cuML 的上下文管理器
using_output_type:
- 設置單個模型的輸出類型:
這種新功能可以自動將數據轉換為方便的格式,而無需手動從多種類型轉換數據。以下是模型為了解返回內容而遵循的規則:
- 如果在構建模型時指定了輸出類型,例如
cuml.KMeans(n_clusters=2, output_type=’numpy’),那么它將給出該類型的結果。 - 如果模型是使用
cuml.using_output_type在上下文管理器with中構建的,那么模型將使用該上下文的輸出類型。 - 如果
output_type是使用set_global_output_type設置的,那么它將返回該類型的結果。 - 如果沒有指定上述任何一項,則模型將鏡像用于輸入的對象的類型,如“默認行為”部分中所述。
效率:我應該使用什么格式?
既然您知道了如何使用 cuML 的輸入和輸出可配置性,那么問題是,最好使用什么格式?這將取決于你的需要和優先級,因為所有的格式都有權衡。讓我們考慮一個簡單的工作流程:

使用基于 NumPy 的對象
在下面的圖 3 中,傳輸(粉色框)限制了 cuML 可以給您的加速量,因為通信使用較慢的系統內存,您必須通過 PCI-Express 總線。每次使用 NumPy 數組作為模型的輸入或要求模型返回 NumPy 數組時,主系統內存和 GPU 之間至少有一次內存傳輸。
乍一看,有人認為這影響不大。然而,將盡可能多的數據保存在 GPU 中,即使不是最大的原因,也是 RAPIDS 實現閃電般速度的原因之一。

使用 cuDF 對象
使用 GPU 對象而不是 NumPy 數組具有重要意義。例如,使用 cuDF 對象如下圖 4 所示。橙色框表示完全在 fast GPU 內存上發生的轉換。不幸的是,這意味著在 cuML 算法處理過程中會有一個額外的數據副本,這會限制在特定 GPU 中可以處理的數據集的大小。

DataFrames (和 Series )是非常強大的對象,允許用戶以平易近人和熟悉的方式進行 ETL 。但要提供這一點,它們是具有大量復雜性的復雜結構,以實現此功能。
其中有幾個例子:
- 除了數據之外,每一列都可以有一個位掩碼數組(基本上是一個由 0 和 1 組成的附加數組),允許用戶在數據中有丟失的條目。
- 由于數據幀在添加/刪除行和列時需要提供靈活性,因此每一列 MIG 在內存中應該彼此遠離。
- 當然,還有一些附加的結構,比如索引和列名。
但是,這些限制為某些分析工作流帶來了一些困難:
- 首先,許多算法在所有數據都是連續的情況下工作得更好,例如,所有字節都分組在同一個內存區域中,因為高效地訪問內存是快速處理數據的一個重要組成部分(特別是對于 GPU s !)。
- 內存是一種有限的資源(一般來說,但對于 GPU 和加速器來說更是如此),因此額外的開銷會產生非常顯著的影響。
使用設備陣列
下面的圖 5 說明了用于輸入或輸出的 CAI 數組如何在 cuML 中處理數據時具有最低的開銷。通過使用 CAI ,不會發生內存傳輸或轉換。 cuML 直接使用 CAI 的屬性訪問數據,然后返回 CAI 數組。這些格式幾乎沒有開銷。設備陣列,例如來自 CuPy 或 Numba 的設備陣列,比數據幀/系列等效物的結構要簡單得多。與 NumPy 類似,它們被設計成由元數據描述的連續內存塊。這個設計決定就是為什么 NumPy 對于最初的 Python 生態系統是革命性的。考慮到所有這些,設備陣列是使用 cuML 最有效的方法也就不足為奇了!
如前所述,從 cuML 的角度來看,所有 CAI 數組本質上是相同的,因此您的工作流可以組合 Numba 、 CuPy 、 cuML 等功能,而無需執行昂貴的內存復制操作。

選擇數據類型的提示
那么您應該使用什么數據類型呢?如前所述,這取決于場景,但這里有一些建議:
- 如果您有一個現有的 PyData 工作流,那么可以利用 cuML 的 NumPy 功能逐個嘗試不同的模型。從加速工作流程中最慢的部分開始。 DBSCAN 和 UMAP 是 cuML 中 modInels 的很好例子,即使它們自己使用,沒有完全的 RAPIDS 加速,也能提供巨大的加速和改進。
- 潛在陷阱:這可能會在主系統內存和 GPU 內存之間造成通信瓶頸。
- 如果您的工作流程非常依賴 ETL ,需要大量的 cuDF 工作,而大部分處理和開發時間都在數據加載或轉換中,請將其作為 cuDF 對象,并讓 cuML 管理轉換。
- 潛在的陷阱:這個 MIG ht 限制了 GPU 中單個模型可以容納的數據量。
- 如果訓練或推理的最終速度是關鍵,那么調整您的工作流以盡可能多地使用 CUDA rray 接口庫。
使用所有這些技巧,您可以配置 cuML 來優化您的需求,并更好地估計工作流的影響和瓶頸。您的新工作流現在可能如下所示:

下一步是什么?
以下是我們很高興在接下來的帖子中分享的一些活躍領域:
多節點多 – GPU ( MNMG ) cuML :還有很多額外的工作要做。 RAPIDS cuML 團隊中的許多工程師目前正在構建領先算法的多節點多 – GPU ( MNMG )實現,以實現大規模的分布式機器學習。分布式數據本身就是一個完整的主題,很快就會有更多的帖子發布。但是從版本 0 . 13 開始, mnmgcuml 接受 Dask-cuDF 對象(使用 Dask 的 cuDF 的分布式等價物)和 CuPy 支持的 Dask 陣列 。 cuML 在 MNMG 算法中生成反映您使用的輸入的結果,類似于 cuML 對單個 GPU 的默認行為。我們正在努力為 MNMG-cuML 算法添加更多的可配置性。我們將討論您的數據是如何分布的,以及您使用的格式對 cuML 的影響。
有關數據及其含義的較低級別詳細信息: 許多細節,如數據類型或內存中數據的順序,都會影響 cuML 。我們將討論這些細節如何影響 cuML ,以及它與傳統 PyData 庫的比較和區別。
抽象與設計 :最近在 RAPIDS 軟件堆棧中引入的抽象和機制,如 CumlArray ,允許 cuML 提供此功能,同時降低代碼復雜性和保證結果所需的測試數量。我們將討論這個,連同 CAI ,如何讓用戶能夠使用多個庫,比如 CuPy , cuDF , cuML ,而不費吹灰之力。
Conclusion
這篇文章討論了 cuML 的輸入和輸出可配置能力,支持的不同數據格式,以及 cuML 中每種格式的優缺點。這篇文章展示了在現有工作流中采用 cuML 是多么容易。 cuML 的 sciketlearnapi 和格式輸出鏡像允許您使用它作為現有庫的替代品。為了獲得最大的性能,用戶應該盡量使用 GPU 特定的格式,以及 CuPy 或 Numba 等 CAI 數組。 RAPIDS 團隊正在努力改進 cuML 的功能和支持的數據格式。如果您對某些特定格式或某些功能感興趣,這些格式或功能可以為您的用例改進 cuML ,請在 cuML Github 存儲庫 中提出問題,或者在 RAPIDS 松弛 頻道中與團隊交談。





