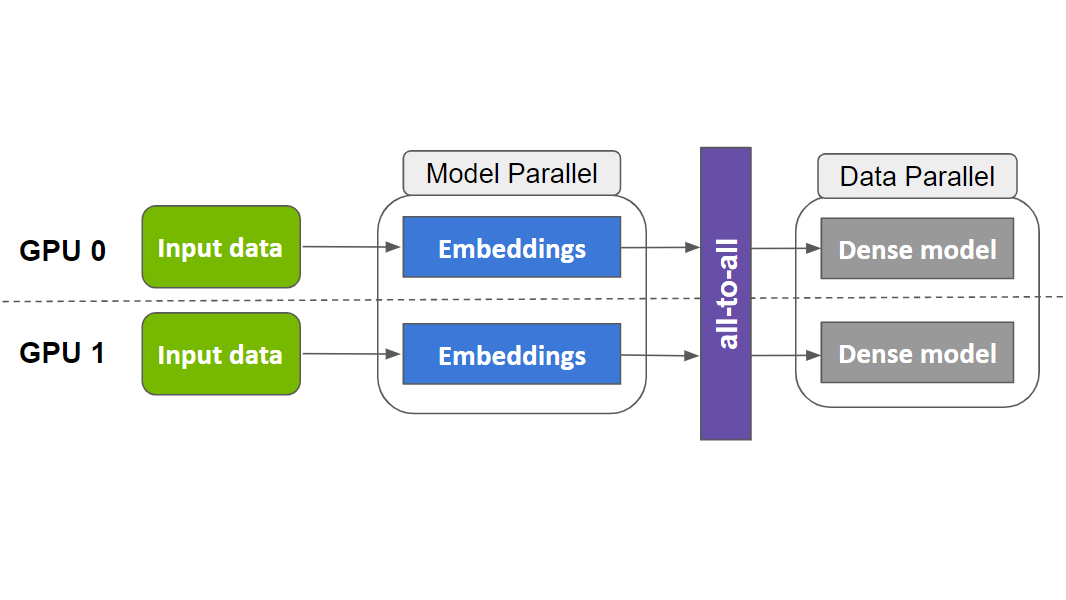
Merlin HugeCTR(以下簡稱 HugeCTR)是 GPU 加速的推薦框架,旨在在多個 GPU 和節點之間分配訓練并估計點擊率(Click-through rate)。
版本新增內容
HugeCTR 第三代 Embedding 更新:
- 第三代 Embedding 功能優化:自從在 v3.7 中引入新一代 HugeCTR Embedding 以來,進行了一些更新和優化,包括代碼重構以提高可用性。此版本的增強功能如下:
- 優化了稀疏查找在 warp 間負載不平衡方面的性能。稀疏操作工具包 (SOK) 利用了此優化來提高性能。
- 修復了用于確定 GlobalEmbeddingData 和 LocalEmbeddingData 類中的最大 Embedding 向量大小的問題。
- Sparse Operation Kit 1.1.4 版可以使用 Pip 安裝,并包括前面提到的優化。
- Embedding 表放置策略的 interface 簡化:第三代 Embedding 現在為您提供了一種更簡單的方法來配置 Embedding 表的放置策略。您可以使用函數參數配置嵌入表放置策略,而不是使用 JSON。您只需提供 shard_matrix、table_group_strategy 和 table_placement_strategy 參數。使用這些參數,第三代 Embedding 可以將不同的表組合在一起,并根據 shard_matrix 參數放置它們。請參閱示例:https://github.com/NVIDIA-Merlin/HugeCTR/blob/master/test/embedding_collection_test/dlrm_train.py
HugeCTR 分層參數服務器(HPS)更新:
- 用于 HPS 查找的 on-device 輸入鍵:HPS 查找支持在推理期間位于 GPU 內存上的輸入 Embedding 鍵。此功能移除了主機到設備的副本,并使用 DLPack lookup_fromdlpack() 接口,使得 embedding key 的 DLPack 包裝 可以是一個 GPU tensor。
- 使用可配置的比例來初始化 Embedding Cache:在以前的版本中,cache_refresh_percentage_per_iteration 參數的默認值為 0.1。在此版本中,默認值更改為 0.0,并且該參數提供了額外的用途。如果您將參數設置為大于 0.0 的值并且還將模型的 use_gpu_embedding_cache 設置為 True,則當分層參數服務器 (HPS) 啟動時,HPS 通過從模型的稀疏文件對 Embedding Cache 進行初始化時,HPS 在會創建日志記錄,日志記錄類似于模型的 EC 初始化:“<model-name>”、num_tables:<int> 和設備上的 EC 初始化:<int>。這樣將會減少預熱階段的持續時間。
- HPS 插件的隱式初始化:在此版本中,當您使用 Triton 推理服務器部署 TensorFlow 的 SavedModel 時,首次執行加載的模型時會隱式初始化 HPS。在以前的版本中,您需要顯式運行 hps.Init(ps_config_file, global_batch_size)。
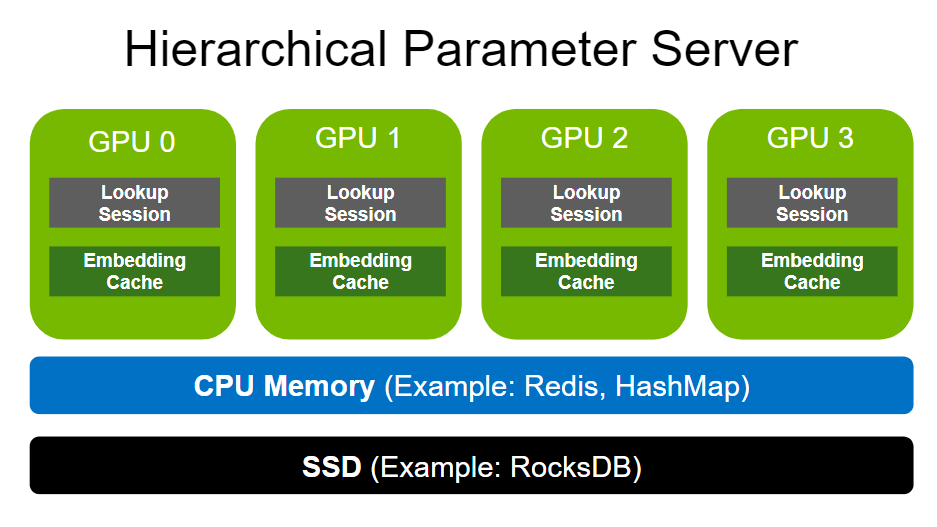
- 圖1:HugeCTR 分層參數服務器(HPS)架構
HugeCTR I/O 模塊更新:
- 支持了 AWS S3 文件系統:Parquet DataReader 現在可以從 Amazon Web Services S3 文件系統讀取數據集。您還可以在訓練期間從 S3 加載和存儲模型。
- 文件系統使用的簡化:您不再需要傳遞 DataSourceParams 來使用遠端文件系統進行模型的加載和存儲。 FileSystem 類會根據您在構建模型時指定的路徑 URI 自動推斷正確的文件系統類型:本地、HDFS 或 S3。例如,路徑 hdfs://localhost:9000/ 將被推斷為 HDFS 文件系統,路徑 https://mybucket.s3.myregion.amazonaws.com/ 將被推斷為 S3 文件系統。
- 支持將模型從遠程文件系統加載到 HPS:此版本使您能夠在推理期間將模型從 HDFS 和 S3 遠程文件系統加載到 HPS。要使用這個新功能,請在 InferenceParams 中為模型文件路徑提供準確的 HDFS 或者 S3 URL。
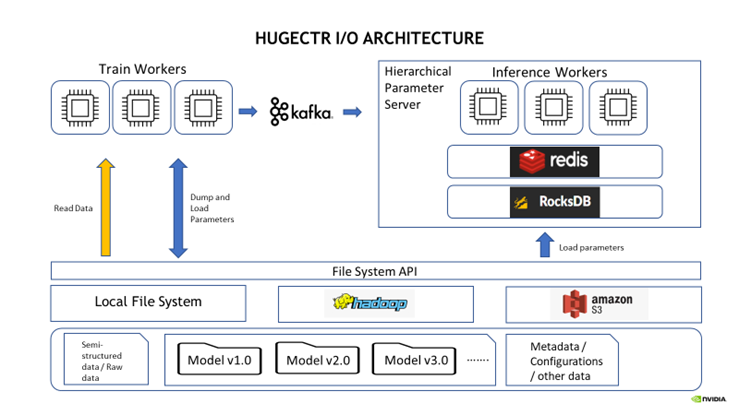
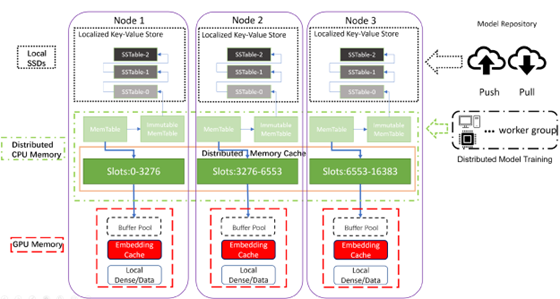
圖2:HugeCTR I/O 框架
文檔和示例更新:
- 新的 MMoE 模型示例:https://github.com/NVIDIA-Merlin/HugeCTR/tree/master/samples/mmoe
- 新的 HPS 示例筆記本: https://github.com/NVIDIA-Merlin/HugeCTR/tree/master/hierarchical_parameter_server/notebooks
- HPS 文檔樣式更新:https://nvidia-merlin.github.io/HugeCTR/master/hierarchical_parameter_server/index.html
- 刪除了兩個已棄用的教程 triton_tf_deploy 和 dump_to_tf。
- 增加了 Performance 相關頁面:https://nvidia-merlin.github.io/HugeCTR/master/performance.html
其他更新:
- 對重疊 Pipeline 進行了更精細的粒度控制:我們棄用了舊的重疊 Pipeline knob,并引入了四個新的 knob:
- train_intra_iteration_overlap
- train_inter_iteration_overlap
- eval_intra_iteration_overlap
- eval_inter_iteration_overlap
以幫助用戶更好地控制重疊行為。有關詳細信息,請參閱 API 文檔 https://nvidia-merlin.github.io/HugeCTR/master/api/python_interface.html#createsolver-method
- 支持在訓練過程中將 Tensor 的值導出到 Numpy Array: 為 Model 和 InferenceModel 類新增了 check_out_tensor() 方法。現在用戶可以使用這個 Pyhon 方法將 Tensor 的值導出,方便 debug。
修復的問題
- InteractionLayer 類已修復,它可以在 num_feas > 30 時正常工作了。
- 通過增加工作空間大小和添加結尾掩碼來更正 cuBLASLt 配置。
- 用于演示特征交叉的示例的預處理腳本已修復。
- 異步數據讀取器是固定的。以前,由于不正確的 I/O 塊大小和 I/O 對齊問題,它會掛起并報錯。 AsyncParam 類已更改以實現修復。 io_block_size 參數被 max_nr_request 參數替換,并且異步讀取器使用的實際 I/O 塊大小會相應計算
- 修復了在調試模式下觸發的構建錯誤。
- 使用 Parquet DataReader 時,如果 metadata.json 中指定的 Parquet 數據集文件不存在,HugeCTR 不再崩潰,而是跳過丟失的文件并顯示警告消息。
已知問題
以下是目前 HugeCTR 存在的已知問題,我們將在之后的版本中盡快修復:
- HugeCTR 使用 NCCL 在隊列之間共享數據,并且 NCCL 可能需要共享系統內存用于 IPC 和固定(頁面鎖定)系統內存資源。如果您在容器內使用 NCCL,請在啟動容器時通過指定參數 -shm-size=1g -ulimit memlock=-1 來增加這些資源。
- 即使目標 Kafka 代理沒有響應,KafkaProducers 啟動也會成功。為避免與來自 Kafka 的流模型更新相關的數據丟失,您必須確保足夠數量的 Kafka 代理正在運行、正常運行,并且可以從運行 HugeCTR 的節點訪問。
- 文件列表中的數據文件數量應大于或等于數據讀取器工作人員的數量。否則,不同的 worker 會映射到同一個文件,并且數據加載不會按預期進行。
- 暫時不支持使用正則化器的聯合損失訓練。
- 暫時不支持將 Adam 優化器狀態導出到 AWS S3。