
需要高性能信息檢索的應用涉及各個領域,包括搜索引擎、知識管理系統、AI 代理和 AI 助手。這些系統需要準確且計算高效的檢索流程,以提供精確的見解、增強用戶體驗并保持可擴展性。檢索增強生成 (RAG) 用于豐富結果,但其有效性從根本上取決于底層檢索機制的精度。
基于 RAG 的系統的運營成本由兩個主要因素驅動:計算資源和檢索精度欠佳導致的不準確成本。應對這些挑戰需要在不影響性能的情況下優化檢索工作流。重新排序模型有助于提高檢索準確性并降低總體支出。然而,盡管有可能對模型進行重新排序,但由于擔心信息檢索工作流程會增加復雜性和感知到的邊際收益,這些模型一直未得到充分利用。
在本文中,我們公布了 NVIDIA NeMo Retriever 重排序模型的重大性能進步,展示了它如何重新定義計算相關性得分在現代流程中的作用。通過詳細的基準測試,我們將重點介紹成本 – 性能權衡,并展示靈活的配置,這些配置能夠滿足從輕量級實現到企業級部署等各種應用程序的需求。
什么是重新排序模型?
重排序模型 通常稱為重排序器或交叉編碼器,是一種旨在計算兩個文本之間相關性分數的模型。在 RAG 環境中,重排序模型評估一段落與給定查詢的相關性。有些方法只使用嵌入模型,為每個段落生成獨立的語義表示,并依靠啟發式相似度指標 (例如余弦相似度) 來確定相關性,而重排序模型則會直接比較同一模型內的查詢通道對。這一次只創建一段文字的語義表示,然后使用啟發式指標來衡量相關性。重排序模型評估一段落與給定查詢的相關性。
通過同時分析查詢和通道之間的模式、上下文和共享信息,重新排序模型可提供更細致、更準確的相關性評估。這使得交叉編碼器在預測相關性方面比使用嵌入模型的啟發式分數更準確,因此成為高精度檢索工作流的關鍵組件。

使用交叉編碼器為整個語料庫中的每個查詢通道對生成相關性分數,計算成本高昂。為解決此問題,我們通常分兩步流程使用交叉編碼器(圖 2)。
在第一步中,使用嵌入模型創建查詢的語義表示,然后使用該表示將潛在候選項從數百萬個縮小到一個較小的子集,通常是數十個段落。在第二步中,交叉編碼器模型會處理這些入圍候選項,并對其進行重新排序,以生成最終的高度相關集–通常只有五個段落。這種兩階段工作流程平衡了效率和準確性,使交叉編碼器成為重新排序模型的重要工具。
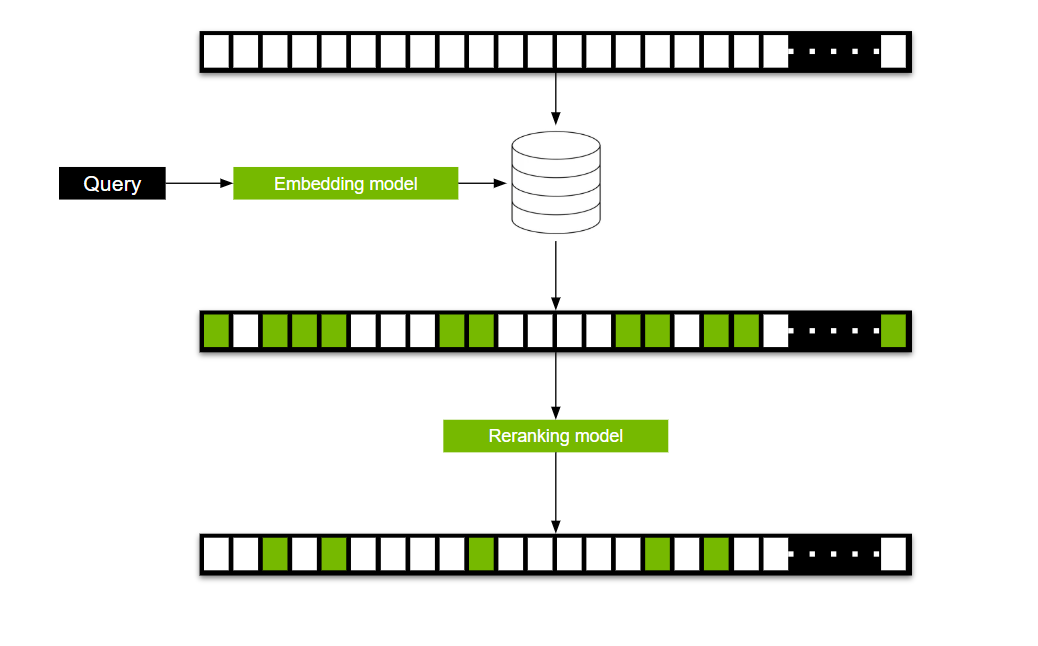
重新排序模型如何改善 RAG?
與使用嵌入或重新排序模型相比,運行 大語言模型 (LLM) 的計算成本要高得多。這種成本直接隨 LLM 處理的 token 數量增加。RAG 系統使用檢索器獲取最重要的 N 個相關信息塊 (通常為 3 到 10 個),然后使用 LLM 根據這些信息生成答案。增加 N 的值通常需要在成本和準確性之間做出權衡。N 越高,檢索器包含最相關信息塊的可能性就越大,但同時也會增加 LLM 步驟的計算成本。
檢索器通常依賴于嵌入模型,但將重新排序模型整合到 pipeline 中可提供三個潛在優勢:
- 最大限度地提高準確性,同時降低運行 RAG 的成本,以抵消重新排序模型的影響。
- 保持準確性,同時大幅降低運行 RAG 的成本。
- 提高 RAG 的準確性并降低運行 RAG 的成本。
有人可能會問,如何使用重新排序模型來實現這些結果?關鍵在于高效利用兩步檢索過程。增加第二步中用于重新排序的候選項數量可提高準確性。然而,這也會增加所產生的成本,盡管與 LLM 相比微不足道。正確看待問題:與使用 NVIDIA NIM 微服務構建的 NeMo Retriever Llama 3.2 重排序模型 相比,Llama 3.1 8B 模型處理五個數據塊并生成答案的成本約高出 75 倍。
重排序模型統計數據
在了解相關前提后,本節將深入探討性能基準測試。需要理解三個數字,才能消化以下信息:
- N_Base: RAG pipeline 在不重新排序的情況下使用的 chunks 數量(Base Case)。
- N_Reranked:RAG pipeline 在重新排序時使用的 chunk 數量。
- K:在第 2 步中使用重新排序過程進行排名的候選人數量。
使用這三個變量,形成三個方程,作為所有三個場景的基礎:
- 方程 1: N_Reranked <= N_Base
- 方程 2:RAG_Savings = LLM_Cost(N_Base) – (Reranking_Cost(K) + LLM_Cost(N_Reranked))
- 方程 3:Accuracy_Improvement = Reranking_Accuracy_Boost(K) + Accuracy(N_Reranked) – Accuracy(N_Base)
最大限度地提高準確性,同時降低運行 RAG 的成本,以抵消重新排序模型的影響
此場景的目標是最大限度地提高準確性,同時將 RAG 節省的成本降至零。因此,方程 2 需要最大化 K,最大化 N_Reranked,并針對給定的 N_Base。這些最大化需要通過遵循方程 3 并在方程 1 中將 RAG_Savings 設置為 0 來實現。
插入 NVIDIA NIM 中的值可得到圖 3 中總結的結果。Base Accuracy 是指具有 N_base 個 chunk 的管道的準確性,而 Improved Accuracy 是指使用 N_base-1 個 chunk 和一個 reranking 模型來實現管道的準確性。

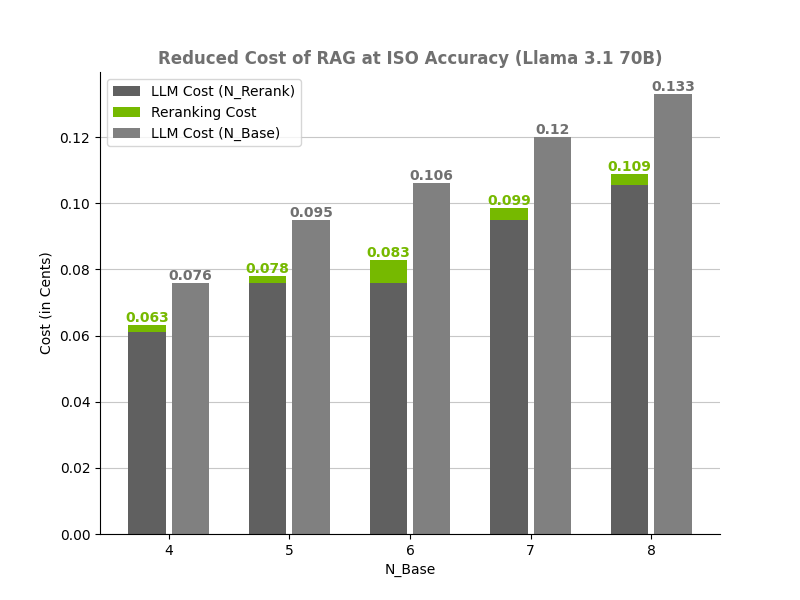
保持準確性,同時降低運行 RAG 的成本
此場景的目標是最大限度地節省成本,同時不會對準確性造成不利影響。看看方程 1。為了最大限度地節省 RAG,對于給定的 N_Base,我們需要最小化 K 和 N_Reranked。要執行此操作,請將準確性改進設置為 0,并在處理 N_Base 數據塊時平衡 K 和 N_Reranked 以匹配準確性。平衡這些變量會得到圖 4 所示的結果。
提高準確性并降低運行 RAG 的成本
在滑塊上,前兩個場景可視為兩個極端。一個極端是最大限度地降低成本,另一個極端是最大限度地提高準確性。用戶可以選擇增加或減少要減少的 chunks 數量以及要重新排序的 chunks 數量,以在兩個極端之間保持平衡。
使用 NVIDIA NeMo Retriever 升級您的 RAG 系統
重排序模型不僅是可選的增強功能,還是對 RAG 流程的變革性補充,將效率和精度提升到新的水平。 NVIDIA NeMo Retriever 重排序 NIM 微服務 通過在降低成本和提高準確性方面提供顯著優勢,重新定義了范式。基準測試表明,顯著節省了 21.54% 的成本。
重新排序模型配置的靈活性使開發者能夠在成本效益和性能提升之間實現理想的平衡,滿足任何組織中不同的用例和可擴展性需求。其優勢主要在于降低了 RAG 的生成成本。通過減少 LLM 為生成答案而必須處理的輸入 token 數量,可以降低成本。
這些結果對將重新排序模型視為復雜性微不足道的改進的過時看法提出了挑戰,展示了它們在優化現代機器學習工作流程中的重要作用。
要立即開始使用此 NeMo Retriever Llama 3.1 重排序 NIM 微服務并升級您的 RAG 系統,請在 build.nvidia.com 上試用。您還可以訪問 NVIDIA AI Blueprint for RAG ,作為使用 NVIDIA NIM 構建的 embedding 和 reranking 模型構建自己的 pipeline 的起點。
與我們一起參加 NVIDIA GTC 2025 ,探索用于構建檢索工作流和代理工作流的最新技術,這些技術可以在您的數據中發現快速、準確的見解。查看以下相關會議:
- NVIDIA 創始人兼首席執行官 Jensen Huang 先生的 GTC 2025 主題演講
- 利用生成式 AI 和 RAG 實現企業數據平臺轉型【S72205】
- 如何構建多模態代理式 AI 檢索系統【S72208】
- 構建 Agentic 和 Retrieval Pipelines 的最佳實踐和技術[CWE72181]:解決棘手的數據處理和檢索挑戰,與 NVIDIA 專家一對一合作
?
?





