
大語言模型(LLM)因其前所未有的規模理解和處理人類語言的能力,在全球引發轟動,改變了我們與技術互動的方式。
經過大量文本語料庫的訓練, LLM 可以在沒有太多指導或訓練的情況下為各種應用程序操作和生成文本。但是,生成的輸出的質量在很大程度上取決于您給模型的指令,即提示。這對你來說意味著什么?如今,與模型交互是設計提示的藝術,而不是設計模型架構或訓練數據。
考慮到構建和培訓模型所需的專業知識和資源,處理 LLM 可能會付出代價。NVIDIA NeMo 提供了預訓練的語言模型,可以靈活地適應幾乎所有的語言處理任務,同時我們可以完全專注于從可用的 LLM 中獲得最佳輸出。
在本文中,我討論了一些可以充分利用 LLM 的方法。要了解更多關于如何開始使用 LLM 的信息,請參閱《大型語言模型介紹:提示工程和 P-Tuning》。
提示背后的機制
在我進入生成最佳輸出的策略之前,請退后一步,了解當您提示一個模型時會發生什么。提示被分解為稱為令牌的較小塊,并作為輸入發送到 LLM ,然后 LLM 根據提示生成下一個可能的令牌。
符號化
LLM 將文本數據解釋為令牌。標記是單詞或字符塊。例如,單詞“ sandwich ”將被分解為標記“ sand ”和“ wich ”,而像“ time ”和“ like ”這樣的常見單詞將是單個標記。
NeMo 使用字節對編碼來創建這些令牌。提示被分解為一個令牌列表,這些令牌被 LLM 作為輸入。
一代
在窗簾后面,模型首先生成邏輯學家對于每個可能的輸出令牌。 Logits 是一個函數,表示從 0 到 1 的概率值,以及從負無窮大到無窮大的概率值。然后,這些 logits 被傳遞到 softmax 函數,為每個可能的輸出生成概率,從而在詞匯表中給出概率分布。以下是用于計算令牌的實際概率的 softmax 方程:
在該公式中,是的概率
給定先前令牌中的上下文 (
到
和
是神經網絡的輸出
然后,模型將選擇最有可能的單詞并將其添加到提示序列中。

當模型決定什么是最可能的輸出時,你可以通過上下轉動一些模型參數旋鈕來影響這些概率。在下一節中,我將討論這些參數是什么,以及如何調整它們以獲得最佳輸出。
調整參數
為了釋放 LLM 的全部潛力,探索提煉輸出的藝術。以下是需要考慮調整的關鍵參數類別:
- 讓模型知道何時停止
- 可預測性與創造性
- 減少重復
利用這些參數,找出適合您特定用例的最佳組合。在許多情況下,對溫度參數進行實驗可以獲得您可能需要的結果。然而,如果您有一些特定的東西,并且希望對輸出進行更精細的控制,請開始嘗試其他的。
讓模型知道何時停止
有一些參數可以指導模型決定何時停止生成任何進一步的文本:
- 代幣數量
- 停止文字
代幣數量
前面,我提到 LLM 的重點是在給定令牌序列的情況下生成下一個令牌。該模型在將預測的令牌附加到輸入序列的循環中完成這一操作。你不會希望 LLM 繼續下去。
雖然 NeMo 模型目前可以接受的令牌數量在 2048 到 4096 之間是有限制的,但我不建議達到這些限制,因為模型可能會產生偏離響應。
停止文字
停止文字是一組字符序列,告訴模型停止生成任何附加文本,即使輸出長度尚未達到指定的標記限制。
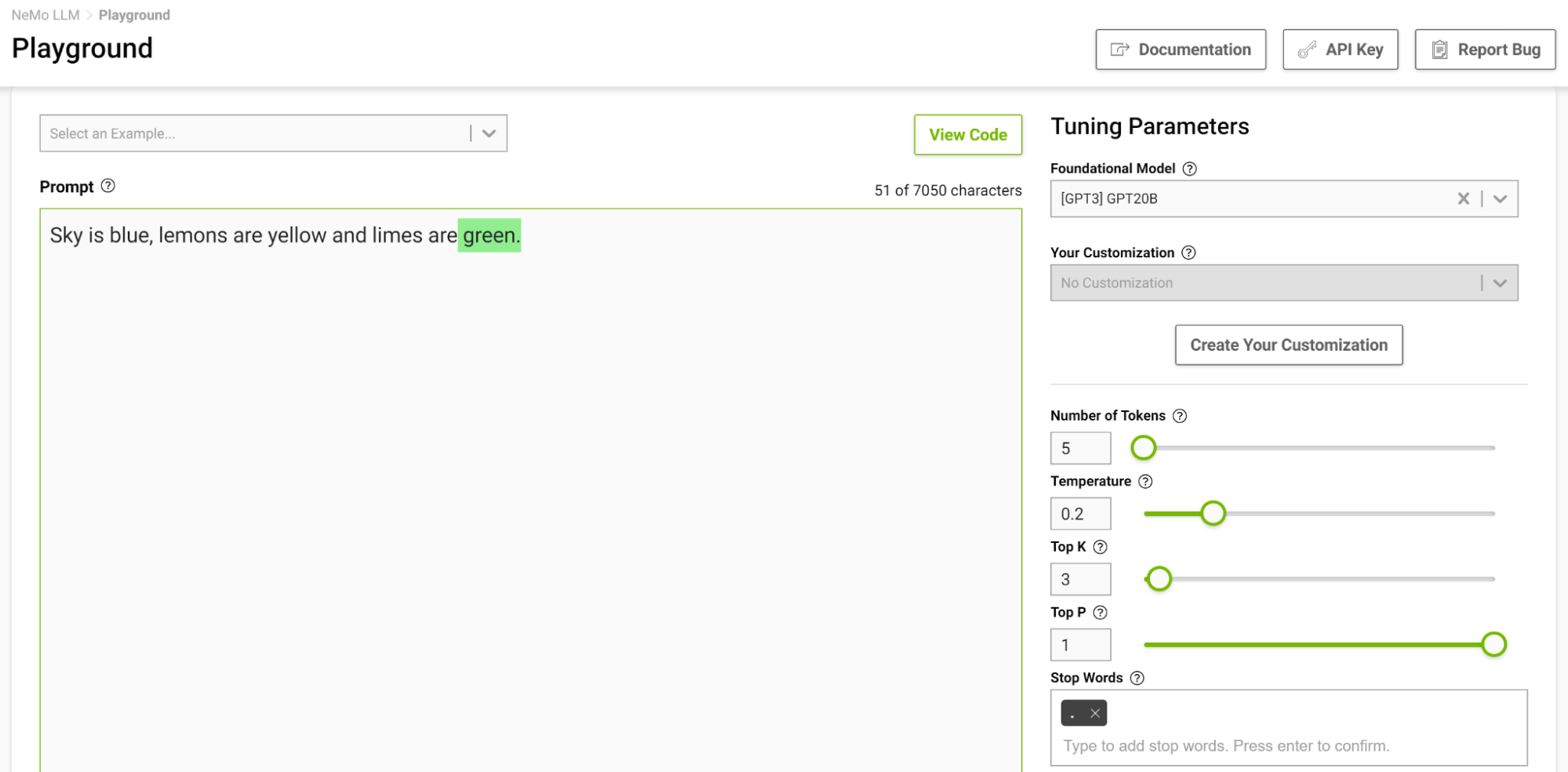
這是控制輸出長度的另一種方法。例如,如果提示模型完成下面的句子“ Sky is blue , lemons is yellow and limes are ”,并且您將停止詞指定為 just “.”,則模型在完成這句話后停止,即使令牌限制高于生成的序列(圖 2 )。
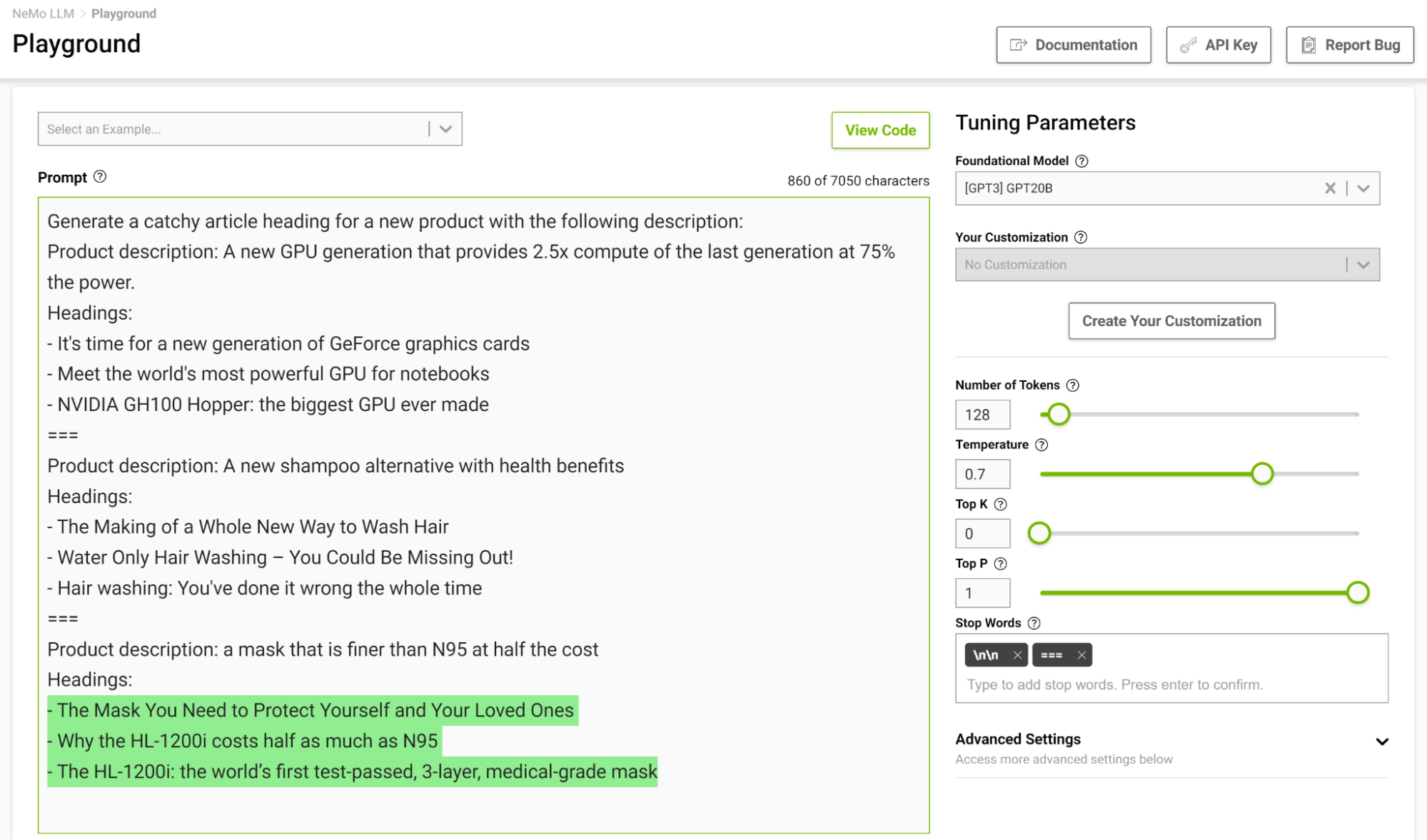
在幾個鏡頭設置中設計一個停止模板尤其有用,這樣模型就可以在完成預期任務時學會適當地停止。圖 3 顯示了用字符串“===”分隔示例,并將其作為停止字傳遞。
可預測性與創造性
如果有提示,可以根據您設置的參數生成不同的輸出。基于 LLM 的應用,您可以選擇增加或減少模型的創新能力。以下是一些可以幫助您做到這一點的參數:
- 溫度
- Top-k 和 Top-p
- 波束搜索寬度
溫度
此參數控制模型的創作能力。如前所述,在生成輸入序列中的下一個令牌時,該模型會得出概率分布。溫度參數可以調整這種分布的形狀,從而使生成的文本更加多樣化。
在較低的溫度下,該模型更保守,并且僅限于選擇具有較高概率的令牌。隨著溫度的升高,這個限制變得寬松,允許模型選擇可能性較小的單詞,從而產生更不可預測和更有創意的文本。
圖 4 顯示了讓模型完成從“海洋”開始的句子,在這里你將溫度設置為 0 . 1 。
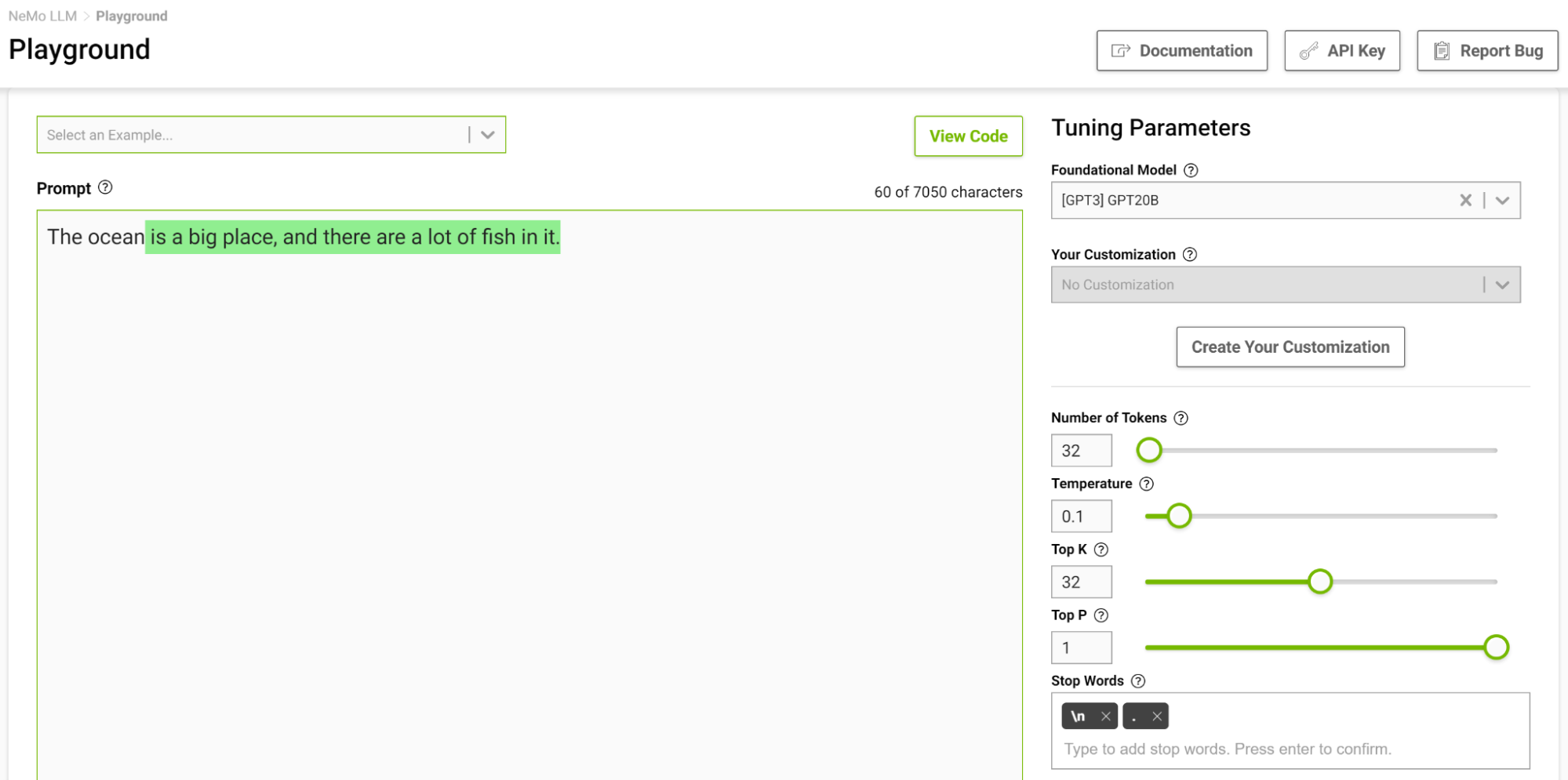
當你想到完成這樣一個短語時,你可能會想到像“…是巨大的”或“…是藍色的”這樣的短語。產量很簡單,海洋很大,有很多魚。
現在,在溫度設置為 1 的情況下再次嘗試此操作(圖 5 )。
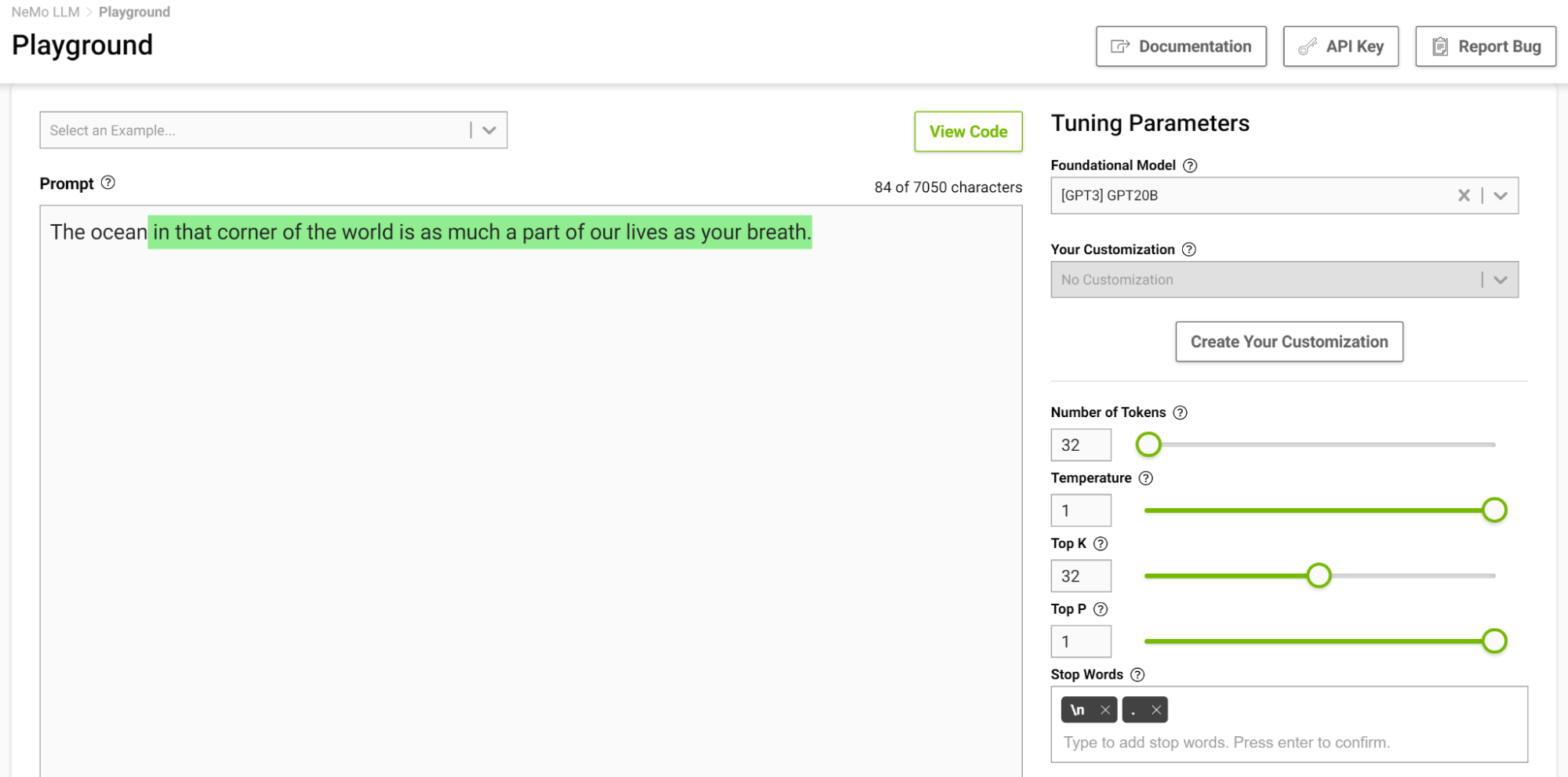
這個模型開始給你一些你通常不會想到的類比。較高的溫度適用于詩歌和故事等需要創造性寫作的任務。但要注意,生成的文本有時也會變得毫無意義。較低的溫度適用于更明確的任務,如問答或總結。
我建議使用不同的溫度值進行實驗,以找到適合您的用例的最佳溫度。范圍[0.5, 0.8]應該是 NeMo 服務游樂場的一個良好起點。
Top-k 和 Top-p
這兩個參數還控制選擇下一個令牌的隨機性。 Top-k 告訴模型它必須保持頂部k最高概率令牌,從中隨機選擇下一個令牌。較低的值會減少隨機性,因為您正在剪切生成可預測文本的可能性較小的令牌。如果k如果設置為 0 ,則不使用 Top-k 。當設置為 1 時,它總是會選擇下一個最可能的令牌。
在可能存在許多令牌的情況下,可能的令牌的概率分布可能很廣。也可能存在分布狹窄的情況,其中只有少數代幣更有可能。
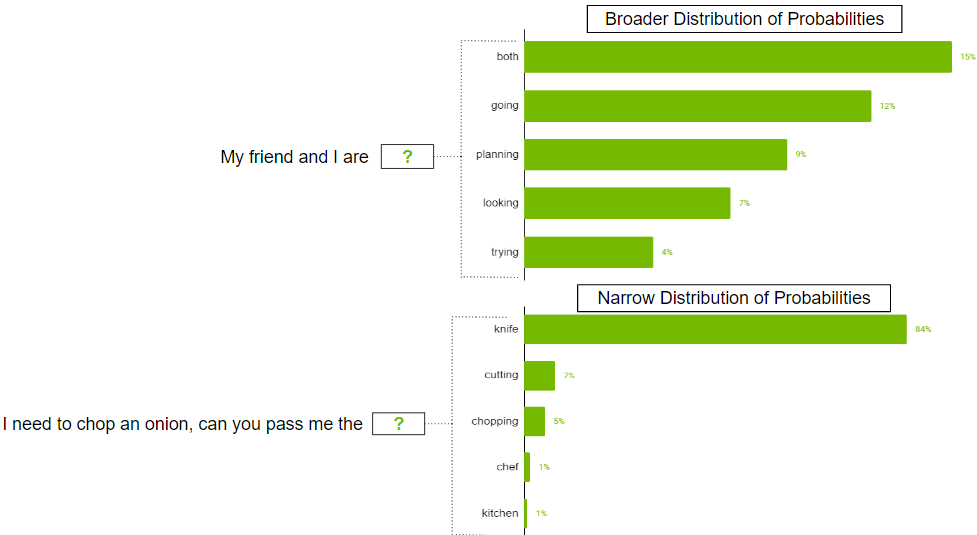
你可能不想嚴格限制模型只選擇頂部k更廣泛的分發場景中的令牌。為了解決這一問題,可以使用參數 top-p ,其中模型從概率總和等于或超過 top-p 值的最高概率令牌中隨機挑選。如果 top-p 設置為 0 . 9 ,則可能出現以下情況之一:
- 在更廣泛的分布示例中,它可以考慮概率之和等于或超過 0 . 9 的前 50 個令牌。
- 在窄分布場景中,僅使用前兩個令牌可能會超過 0 . 9 。通過這種方式,您可以避免從隨機代幣中挑選,同時仍然保留多樣性。
波束搜索寬度
這是另一個有用的參數,可以控制輸出的多樣性。波束搜索是許多 NLP 和語音識別模型中常用的一種算法,作為在給定可能選項的情況下選擇最佳輸出的最終決策步驟。波束搜索寬度是一個參數,用于確定算法在搜索的每個步驟中應該考慮的候選數量。
更高的值增加了找到良好輸出的機會,但這也以更多的計算為代價。
減少重復
有時,輸出中可能不希望出現重復的文本。如果是這種情況,請使用重復懲罰參數來幫助減少重復。
重復處罰
此參數可以幫助根據令牌在文本(包括輸入提示)中出現的頻率來懲罰令牌。已經出現五次的代幣比只出現一次的代幣受到的處罰更重。值為 1 意味著沒有懲罰,大于 1 的值會阻止重復的令牌。
有效提示設計的少數射擊策略
及時的設計對于 LLM 產生相關和連貫的輸出至關重要。制定有效的提示設計策略可以幫助創建相關的提示,同時避免偏見、歧義或缺乏特異性等常見陷阱。在本節中,我將分享一些有效提示設計的關鍵策略。
帶約束提示
通過仔細的提示設計來約束模型的行為可能非常有用。你知道,語言模型的核心是試圖預測序列中的下一個單詞。語言模型可能無法理解對人類來說完全有意義的任務描述。這就是為什么少鏡頭學習通常效果良好的原因:當你向模型演示一個模式時,它很好地遵守了它。
考慮以下提示:“將英語翻譯成法語:今天是美好的一天。”
有了這個提示,模型可能會嘗試繼續句子或添加更多句子,而不是進行翻譯。將提示更改為“將此英語句子翻譯成法語:今天是美好的一天”。這增加了模型將此任務理解為翻譯任務的可能性,并生成更可靠的輸出。
角色很重要!
正如您在前面的翻譯示例中看到的,微小的更改可能會導致不同的輸出。另一件需要注意的事情是,令牌通常是用前導空格生成的,所以空格和下一行等字符也會影響您的輸出。如果提示不起作用,請嘗試更改其結構方式。
考慮某些短語
通常,當你想讓你的模型合乎邏輯地回答你的提示并得出準確的結論,或者只是為了讓模型取得一定的結果時,你可以考慮使用以下短語:
- 讓我們一步一步地思考:這鼓勵模型以邏輯的方式處理問題并得出準確的答案。這種提示方式也稱為思想促進鏈( CoT )。
- 以<名人>的風格:這與這位名人的寫作風格相匹配。例如,要生成像莎士比亞或埃德加·艾倫·坡這樣的文本,將其添加到提示中,生成的文本將與他們的寫作風格緊密匹配。
- 作為<職業/角色>:這有助于模型更好地理解問題的上下文。有了更好的理解,模型通常會給出更好的答案。
用生成的知識提示
為了獲得更準確的答案,您可以在生成最終答案之前提示 LLM 生成關于給定問題的潛在有用知識(圖 7 )。

這種類型的錯誤表明 LLM 有時需要更多的知識來回答問題。下面的例子展示了在幾桿的情況下生成關于高爾夫得分的一些事實。
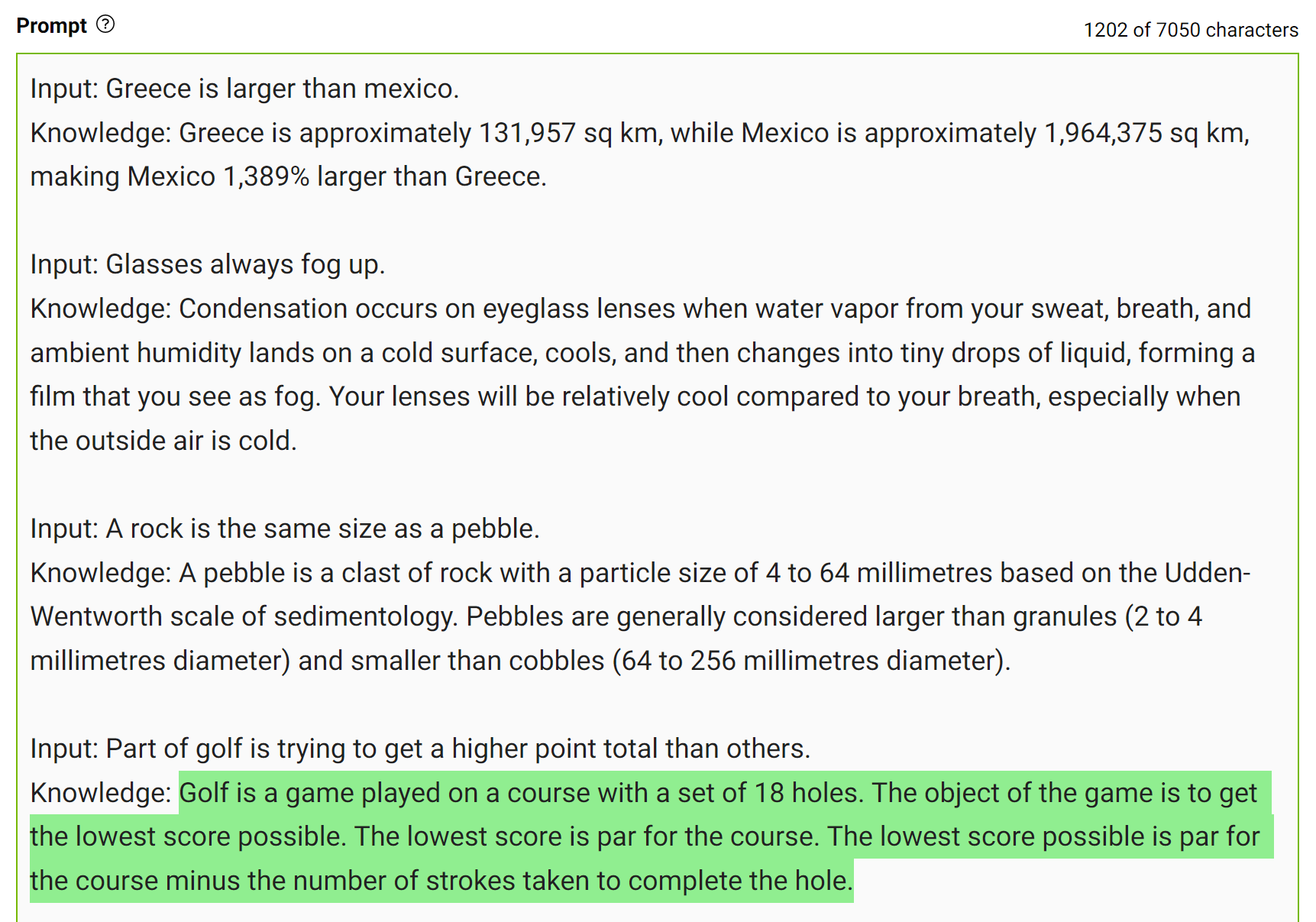
將這些知識整合到提示中,然后再次提問。
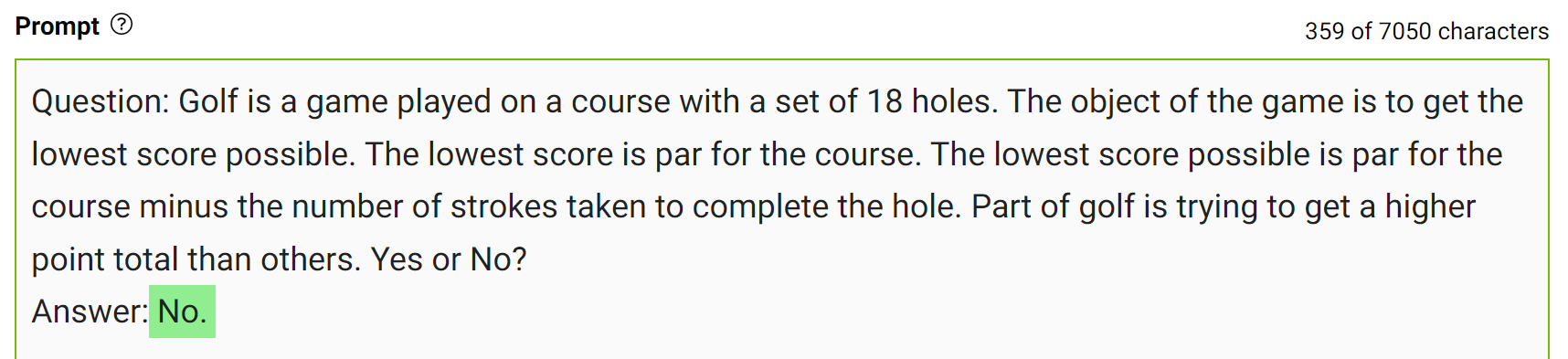
對于同樣的問題,模特自信地回答“不”。這是一個簡單的演示,但在得出最終答案之前,還有更多的細節需要考慮。更多詳細信息,請參閱 Generated Knowledge Prompting for Commonsense Reasoning。
在實踐中,您生成多個答案,并選擇最頻繁出現的答案作為最終答案。
試試看!
編寫適合您的用例的提示的最好方法是進行實驗和嘗試。設計一個可以為您提供正確輸出的提示是一種學習體驗,無論是如何編寫,還是如何設置模型參數。
如果您想進入 NeMo 服務游樂場,可以幫助您測試提示并設計用例,請參閱 NVIDIA NeMo Service。
結論
在這篇文章中,我分享了從 LLM 生成更好輸出的方法。我討論了如何調整模型參數以獲得所需的輸出,以及一些設計提示的策略。
注冊了解 LLM 技術、學習和突破的最新情況,請訂閱 LLM newsletter。
?





