
最新一批開源大語言模型 (LLMs) 采用了 Mixture of Experts (MoE) 架構,如 DeepSeek R1、Llama 4 和 Qwen3。與傳統的密集模型不同,MoE 在推理期間僅激活專門參數的子集 (稱為專家參數) 。這種選擇性激活可減少計算開銷,從而縮短推理時間并降低部署成本。
當與 NVIDIA Dynamo 的推理優化技術 (例如分解服務) 和 NVIDIA GB200 NVL72 的縱向擴展架構的大域相結合時,MoE 模型可以從復合效應中受益,從而將推理效率提升到新的水平。這種協同作用可以顯著增加 AI 工廠的利潤,使它們能夠在不犧牲用戶體驗的情況下,為每個 GPU 提供更多的用戶請求。
本博客借鑒了我們最近的研究成果,其中我們使用高保真數據中心級GPU性能模擬器評估了不同硬件配置中的數十萬個設計點。我們分析了分解和寬模型并行對MoE吞吐量的影響。
通過分解服務提升 MoE 模型性能
自 Google 研究人員于 2018 年推出 BERT 模型以來,模型權重增長了 1000 多倍,而生成式推理的吞吐量和交互預期僅有增加。因此,現在的常見做法是使用 Tensor Parallelism (TP) 、Pipeline Parallelism (PP) 和 Data Parallelism (DP) 等模型并行技術跨多個 GPU 對模型進行分片。
傳統的 LLM 部署通常將推理的預填充和解碼階段托管在單個 GPU 或節點上。但是,與自回歸解碼階段相比,令牌并行預填充階段本身具有不同的資源需求。在典型的服務場景中,適用于各個階段的服務水平協議 (SLA) 也各不相同,Time to First Token (TTFT) 要求適用于預填充和 Inter-Token Latency (ITL) 要求,這些要求可指導解碼部署選擇。因此,每個階段都受益于不同的模型并行性選擇。共置這些相位會導致資源利用效率低下,尤其是對于長輸入序列而言。

分解服務將這些階段跨不同的 GPU 或 GPU 節點分離,從而實現獨立優化。這種分離允許應用各種模型并行策略,并分配不同數量的 GPU 設備來滿足每個階段的特定需求,從而提高整體效率。
MoE 模型將模型劃分為專業專家。與為每個 token 激活整個模型不同,門控機制會動態選擇這些專家中的一小部分來處理每個 token。每個傳入的 token 都會傳遞給選定的專家,然后由他們通過多對多 GPU 通信執行計算并交換結果。
MoE 的獨特架構允許引入模型并行的新維度,即 Expert Parallelism (EP) 。在 EP 中,模型專家分布在 GPUs 之間,從而實現更豐富的模型并行映射,并提高資源利用率。
將 EP 添加到現有模型并行技術(例如 TP、PP 和 DP)的組合中,顯著擴展了在解服務中為 MoE 模型提供服務時的模型并行搜索空間,從而為預填充和解碼提供更定制的并行策略。
在 MoE 模型中,解碼階段在廣泛的 EP 設置下表現最佳,其中每個 GPU 僅托管少量專家。這種方法在 GPU 之間更均勻地分配計算,這有助于降低處理延遲。與此同時,每個 GPU 的專家數量減少,從而為 KV 緩存釋放 GPU 顯存,從而使每個 GPU 能夠處理更多的每批請求,從而提高整體吞吐量。
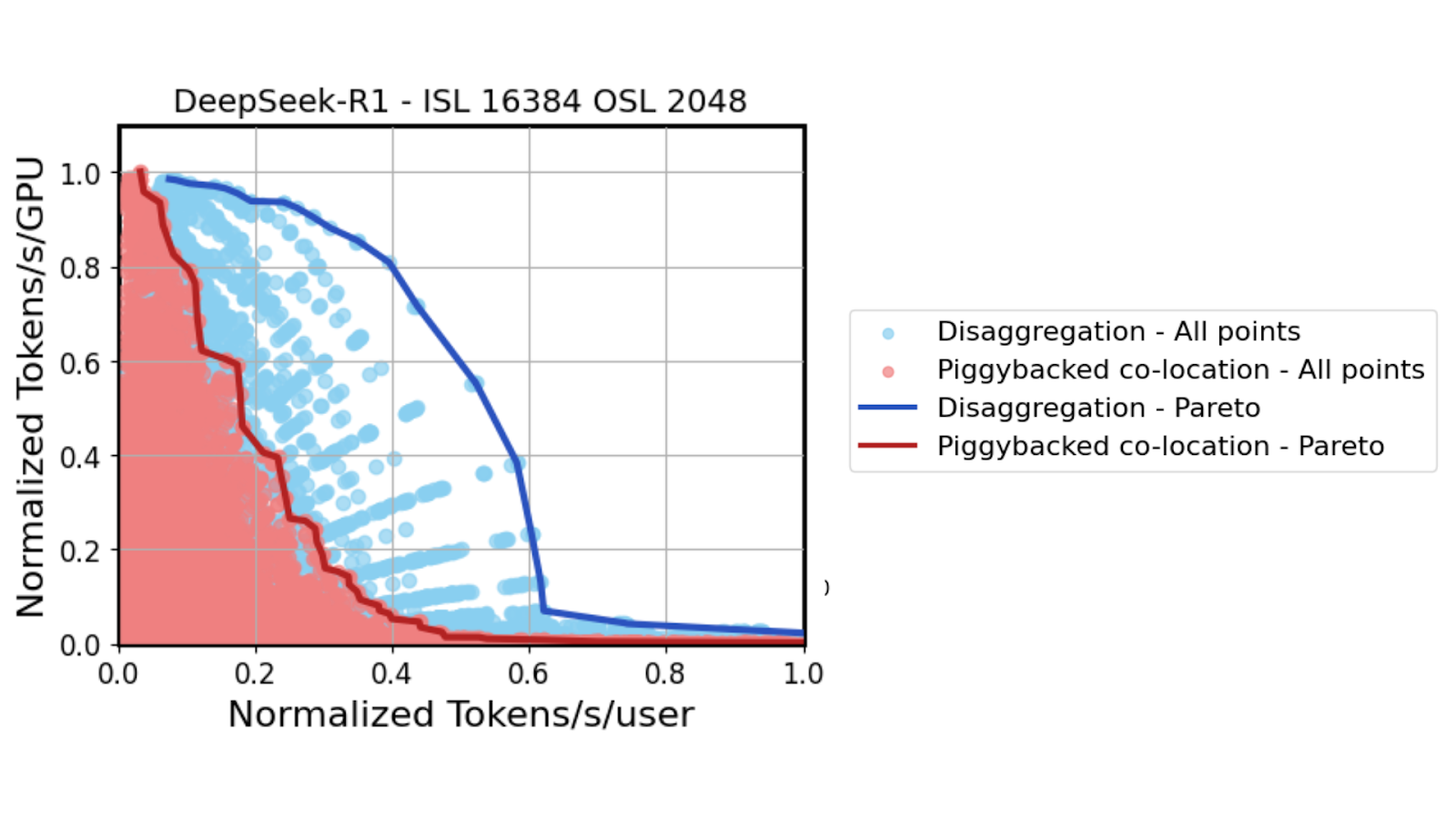
使用高保真數據中心級 GPU 模擬器在數十萬個潛在的模型并行配置中測試 DeepSeek R1 模型時,在中等延遲情況下 ( x 軸上的中點) ,可以實現 6 倍的吞吐量性能提升。
NVIDIA Dynamo 為 MoE 模型提供解耦服務
NVIDIA Dynamo 是一個分布式推理服務框架,專為數據中心規模的模型部署而設計。它簡化了分散式服務架構帶來的復雜性并實現了自動化。其中包括管理預填充和解碼 GPU 之間 KV 緩存的快速傳輸,將傳入請求智能路由到適當的解碼 GPU,這些 GPU 保存相關 KV 緩存以實現高效計算。當用戶需求超過分配容量時,Dynamo 還可以使用 NVIDIA Dynamo Planner 和 Kubernetes 將整個分解設置擴展到數萬個 GPU。
解設置的一個關鍵挑戰是需要在預填充和解碼 GPU 之間進行請求速率匹配。動態速率匹配可確保根據預填充和解碼階段的負載分配資源。它可以防止解碼 GPU 在等待預填充 (即預填充主導場景) 的 KV 緩存時處于空閑狀態,并避免預填充任務在解碼主導的設置中卡在隊列中。實現正確的速率平衡需要仔細考慮預填充隊列中的請求數量、解碼 GPU 中 KV 緩存內存塊的利用率,以及 Service Level Agreements (SLA) ,例如 Time to First Token (TTFT) 和 Inter-Token Latency (ITL) 。

回顧圖 2,每個藍點不僅代表預填充和解碼模型并行配置的獨特組合,還代表仔細平衡預填充和解碼 GPU 之間的速率匹配。雖然這種速率匹配可以針對固定 Input Sequence Length (ISL) 和 Output Sequence Length (OSL) 組合進行計算,但現實世界的部署面臨更大的挑戰。ISL 和 OSL 通常因請求而異,這使得一致性速率匹配變得更加復雜。
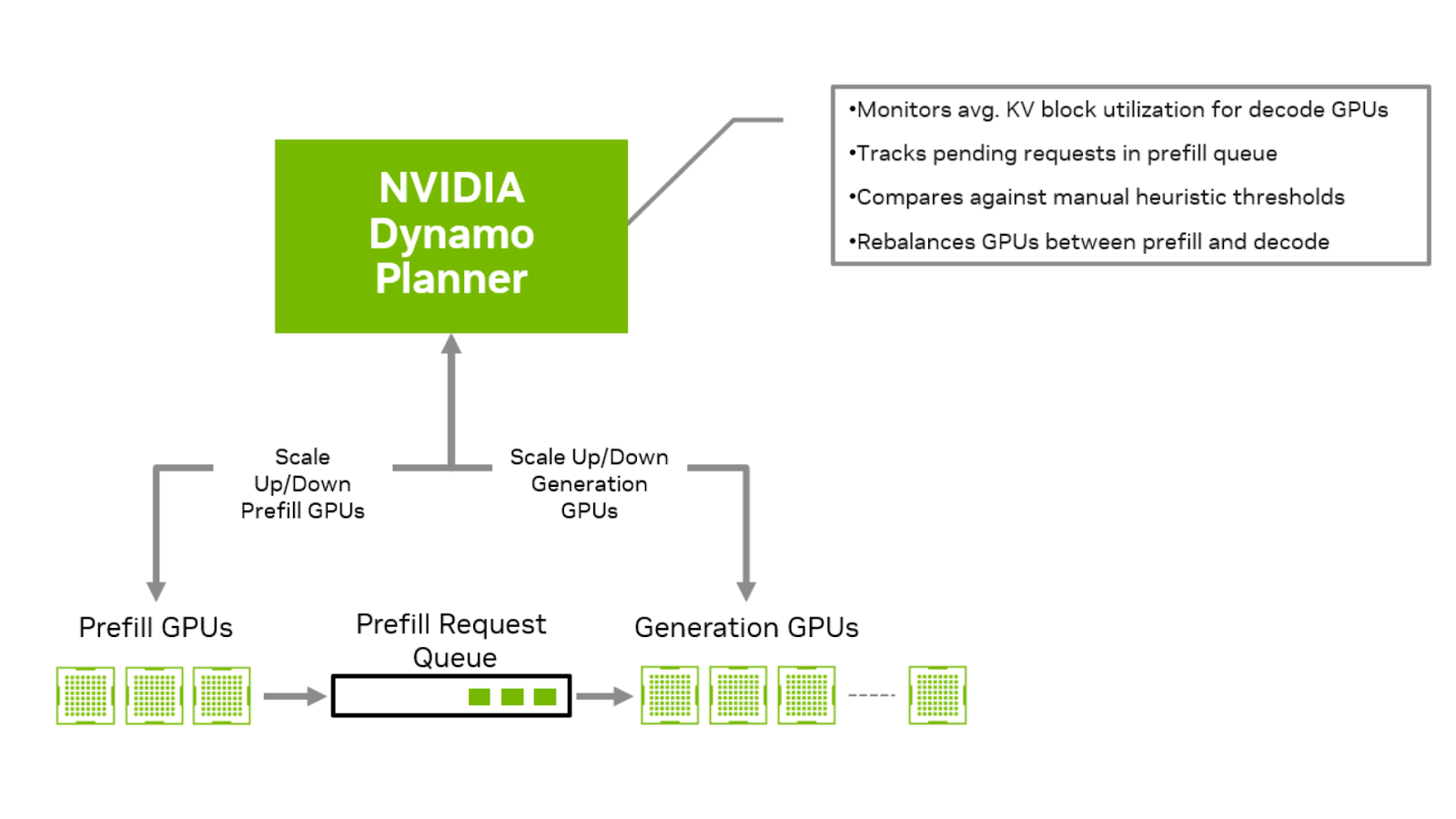
為了解決這一問題,NVIDIA Dynamo 包含一個名為 Planner 的專用引擎,旨在實現此過程的自動化,并確保波動工作負載的預填充和解碼之間的均衡速率匹配。它評估預填充隊列時間、用于解碼的 KV 緩存 GPU 顯存利用率和應用程序 SLA,以確定 GPU 資源的最佳配置。然后,它會根據輸入和輸出序列請求不斷變化的模式,智能地決定要擴展的 GPU 類型、方向和比例。

分解服務有利于各種 ISL/OSL 流量模式,尤其是長 ISL。在試圖平衡解碼速度的聚合部署中,這些系統會對繁重的工作負載進行預填充,而這些工作負載會受到嚴重影響。
如果工作負載在長 ISL 和短 ISL 以及 OSL 之間存在差異,Dynamo Planner 可以檢測和應對這些差異,并決定是否使用解碼 GPU 上的傳統聚合部署來服務傳入請求,還是使用跨預填充和解碼 GPU 的解服務來服務這些請求。它可以適應不斷變化的工作負載,同時保持 GPU 利用率和峰值系統性能。

采用 NVIDIA GB200 NVL72 NVLink 架構
在 MoE 模型中,每個輸入 token 都會動態路由到一小部分選定的專家。在 DeepSeek R1 模型中,每個 token 會發送給完整的 256 位專家中的 8 位專家。這些選定的專家獨立執行各自的推理計算,然后通過 all-to-all 通信模式彼此共享以及與共享的專家共享輸出。這種交換可確保最終輸出包含所有選定專家的處理結果。
為了在解服務架構中真正利用 MoE 模型的性能優勢,必須設計具有廣泛 EP 設置的解碼階段。具體來說,這意味著在 GPU 之間分配專家的方式是,每個 GPU 只處理少量專家。對于 DeepSeek R1 模型,通常每個 GPU 大約需要四名專家,這需要 64 個 GPU 才能在解碼期間容納全部 256 名路由專家。

但是,選定專家之間的多對多交流模式帶來了重大的網絡挑戰。由于參與解碼的每位專家都必須與為同一 token 選擇的其他七位專家交換數據,因此,所有 256 位專家 (以及托管他們的 64 個 GPU) 在同一低延遲、高帶寬域中運行變得至關重要。如果選定的專家位于位于不同節點上的 GPU 上,則多對多通信會因較慢的節點間通信協議 (例如 InfiniBand) 而成為瓶頸。
要確保 64 個 GPU 之間的這種通信效率水平,需要一種新型縱向擴展加速計算基礎設施,這種基礎設施可以在一個統一的低延遲計算域中緊密互連所有參與的 GPU,以避免通信瓶頸并更大限度地提高吞吐量。
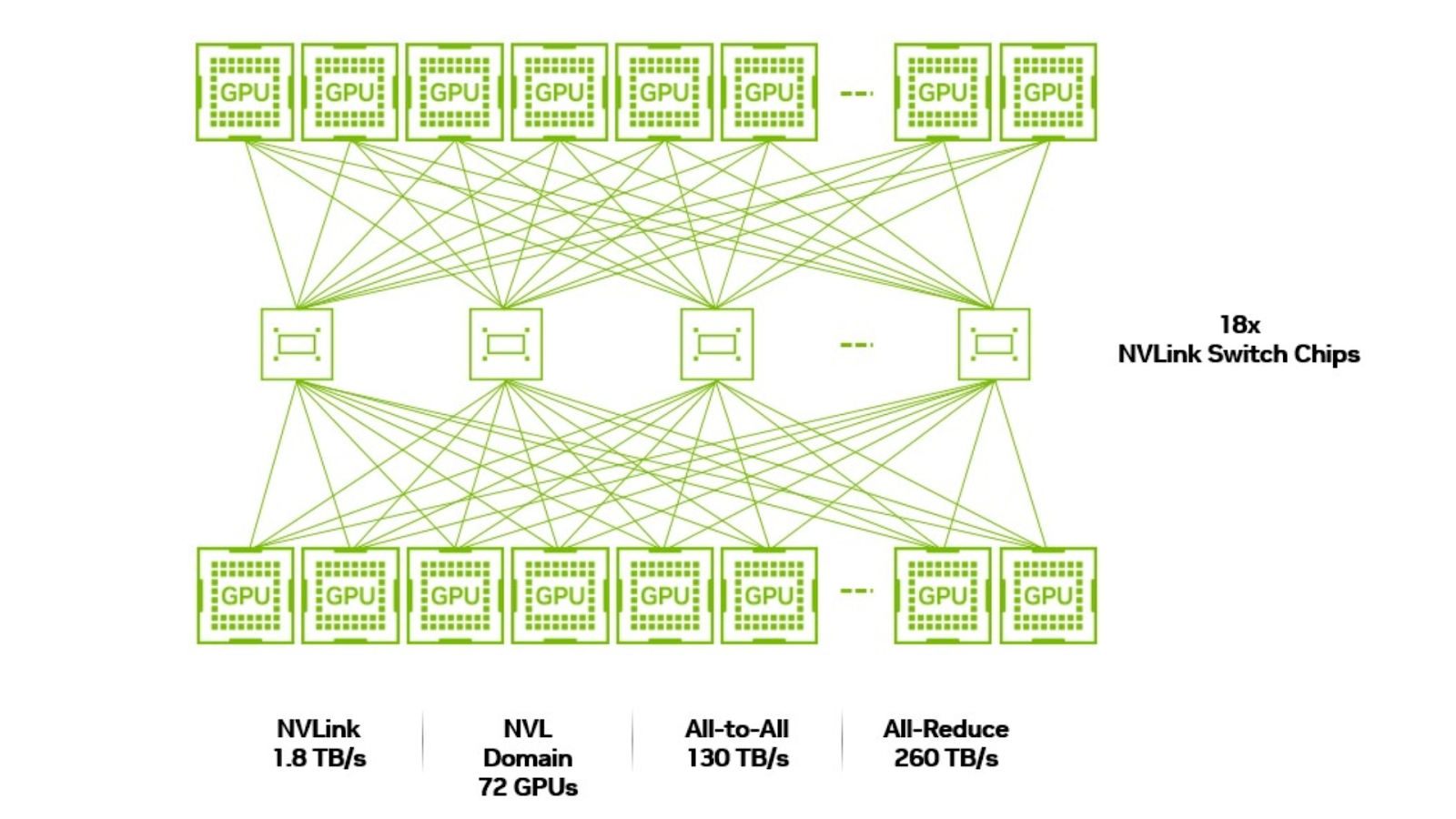
在推出 NVIDIA GB200 NVL72 之前,在 HGX H200 基板上,單個 NVLink 域中可連接的 GPU 最大數量限制為 8 個,每個 GPU 的通信速度為 900 GB/s。GB200 NVL72 設計的引入極大地擴展了這些功能:NVLink 域現在可以支持多達 72 個 NVIDIA Blackwell GPU,每個 GPU 的通信速度為 1.8 TB/s,比 400 Gbps Ethernet 標準快 36 倍。NVLink 域大小和速度的這一飛躍使 GB200 NVL72 成為在分解設置中提供寬 EP 為 64 的 MoE 模型的理想選擇。
不僅僅是 MoE:NVIDIA GB200 NVL72 和 NVIDIA Dynamo 可加速密集模型
除了加速 MoE 模型外,GB200 NVL72 和 Dynamo 在為熱門開源 Llama 70B 模型等傳統密集模型提供服務時協同工作,還可實現巨大的性能提升。
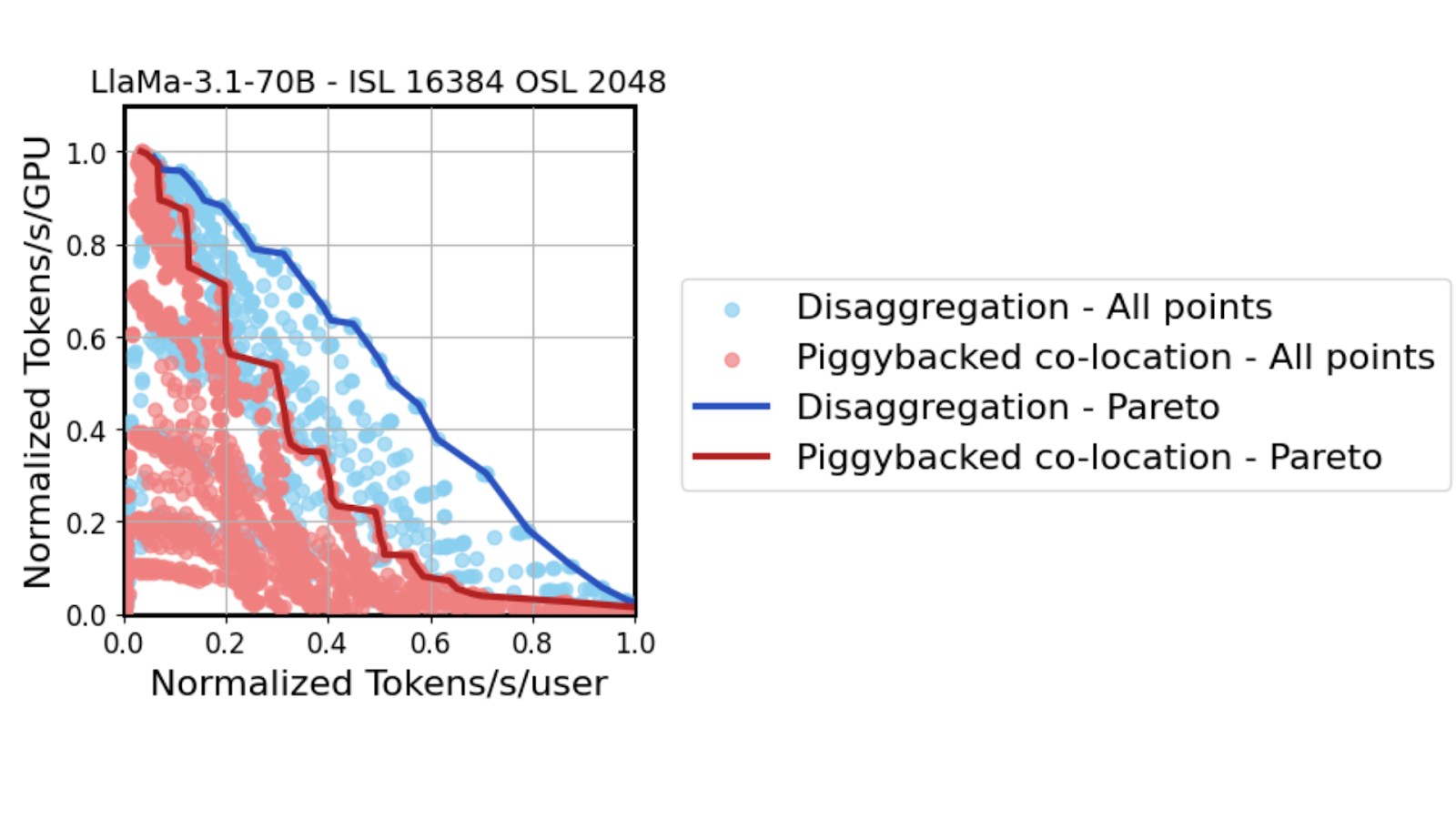
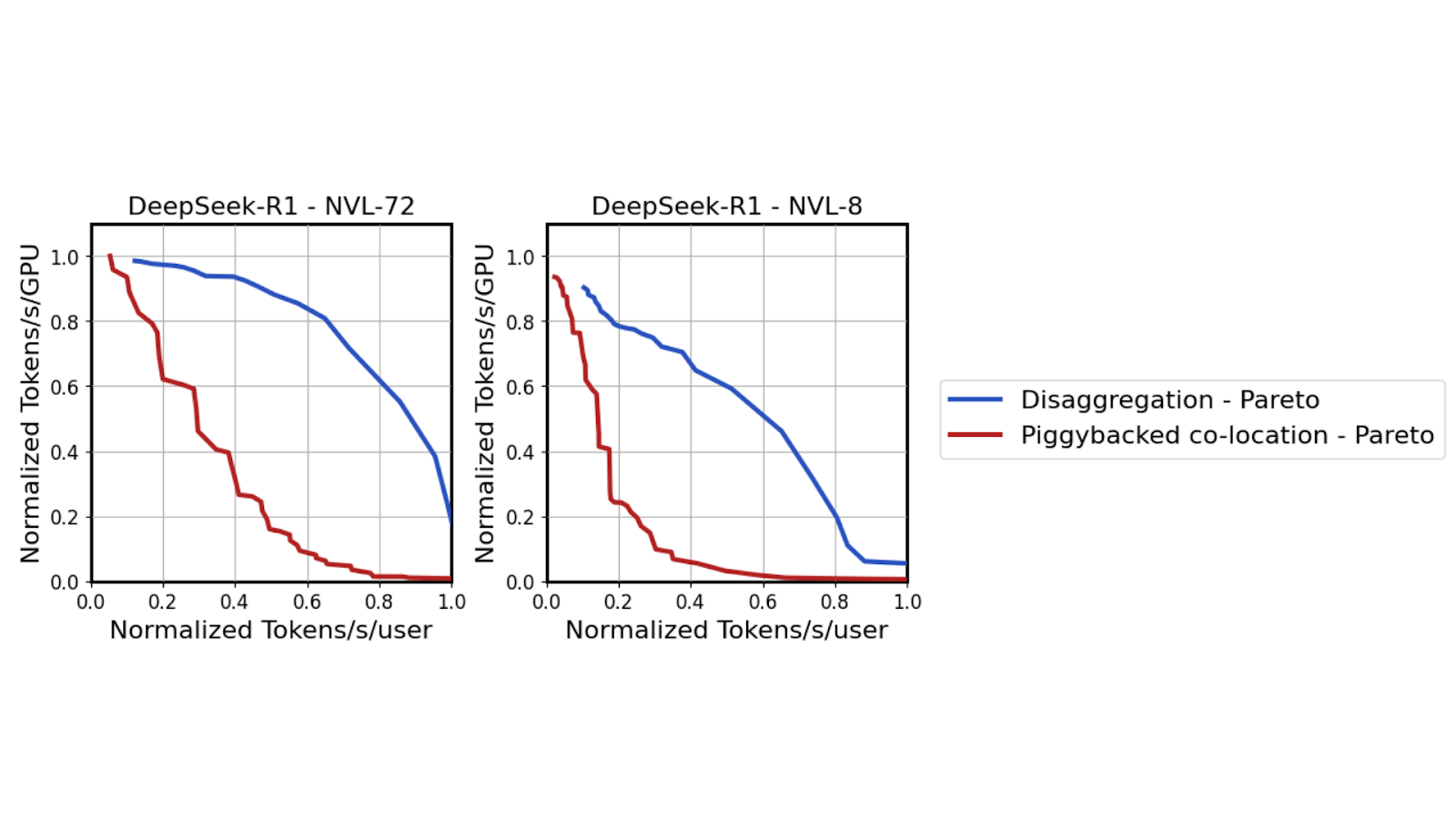
使用為 Llama 70B 模型提供服務的同一高保真 GPU 性能模擬器,結果表明,隨著 TTL 約束條件的收緊 (在 x 軸上從左到右移動) ,tensor parallelism 必須從兩個 GPU 擴展到 64 個 GPU。雖然在嚴格的 TTL SLA 下,協同定位和 disaggregated serving 都有利于實現高 tensor parallelism,但 disaggregated decoding 能夠更積極地實現這一策略。
Dynamo 分解解碼設置無需在需要大量計算的預填充性能與解碼速度之間取得平衡,因此可以更好地適應日益嚴格的延遲需求。GB200 NVL72 的縱向擴展架構再次允許 TP 解碼部署中的所有 GPU 以高達 260 TBps 的速度使用 all-reduce 進行通信。這將在高達 3 倍的相同中延遲機制下提高吞吐量性能。
總結
NVIDIA Dynamo 和 NVIDIA GB200 NVL72 的組合可產生強大的復合效果,為正在部署 MoE 模型 (例如 DeepSeek R1 和新發布的 Llama 4 模型) 的 AI 工廠優化推理性能。NVIDIA Dynamo 通過處理預填充和解碼自動縮放以及速率匹配等任務,簡化并自動化了 MoE 模型的 NVIDIA 解服務的復雜挑戰。
同時,NVIDIA GB200 NVL72 提供了一種獨特的縱向擴展架構,能夠在解 MoE 部署中加速廣泛的專家并行解碼設置的多對多通信要求。它們共同助力 AI 工廠更大限度地提高 GPU 利用率,滿足更多的每筆投資請求,并推動利潤持續增長。
如需深入了解使用分解服務在大規模 GPU 集群上部署 DeepSeek R1 和 Llama 模型的技術細節,請參閱此處提供的技術白皮書。
?




