11 月 8 日至 11 日加入 NVIDIA ,展示超過 500 個GTC課程,涵蓋 AI 和深度學習的最新突破,以及許多其他 GPU 技術興趣領域。
下面是一些頂級人工智能和深度學習課程的預覽,包括培訓、推理、框架和工具等主題,這些主題由 NVIDIA 的演講者提供。
培訓
深度學習揭開神秘面紗:人工智能已經發展并改進了數據分析和復雜計算的方法,解決了幾年前我們還遠遠無法解決的問題。學習加速數據分析、高級用例和問題解決方法的基礎知識,以及深入學習如何改變每個行業。我們將介紹人工智能的去神秘化、機器學習和深度學習;了解組織在采用這種新方法時面臨的主要挑戰;以及有助于取得突破性成果的最新工具和技術。
多 GPU s 的深度學習基礎:現代深度學習挑戰利用越來越大的數據集和更復雜的模型。因此,高效地訓練模型需要大量的計算能力。在本課程中,您將學習如何將深度學習培訓擴展到多個 GPU s 。使用多個 GPU 進行深度學習可以顯著縮短訓練大量數據所需的時間,使通過深度學習解決復雜問題成為可能。
推理
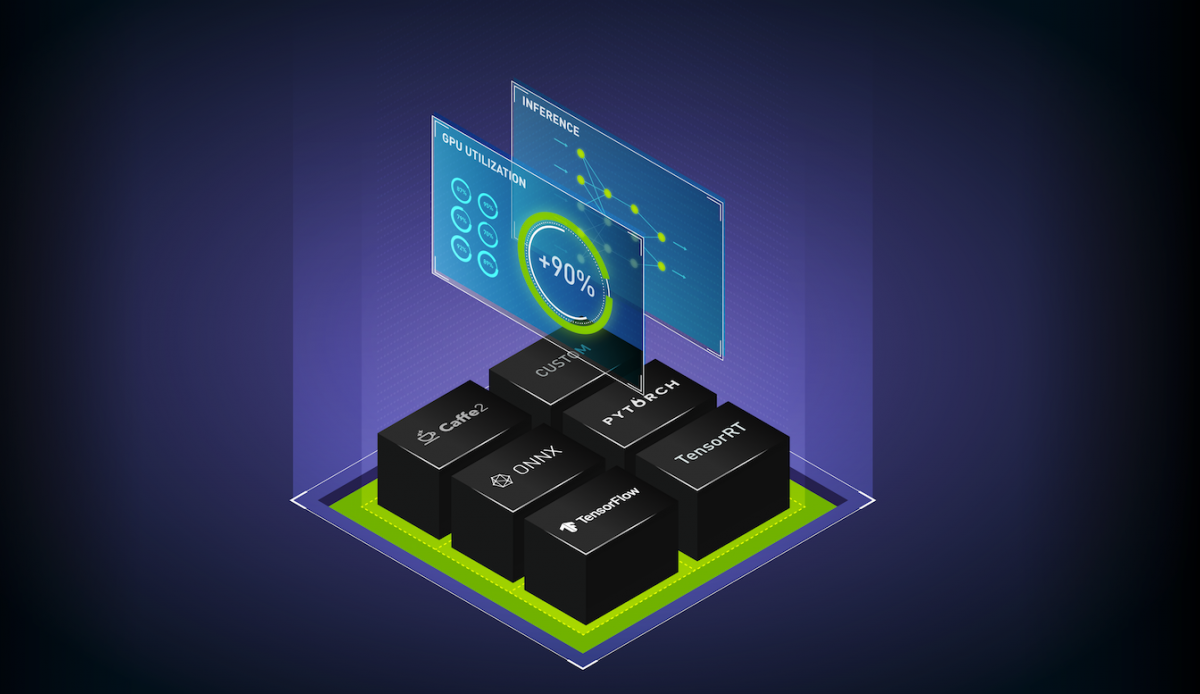
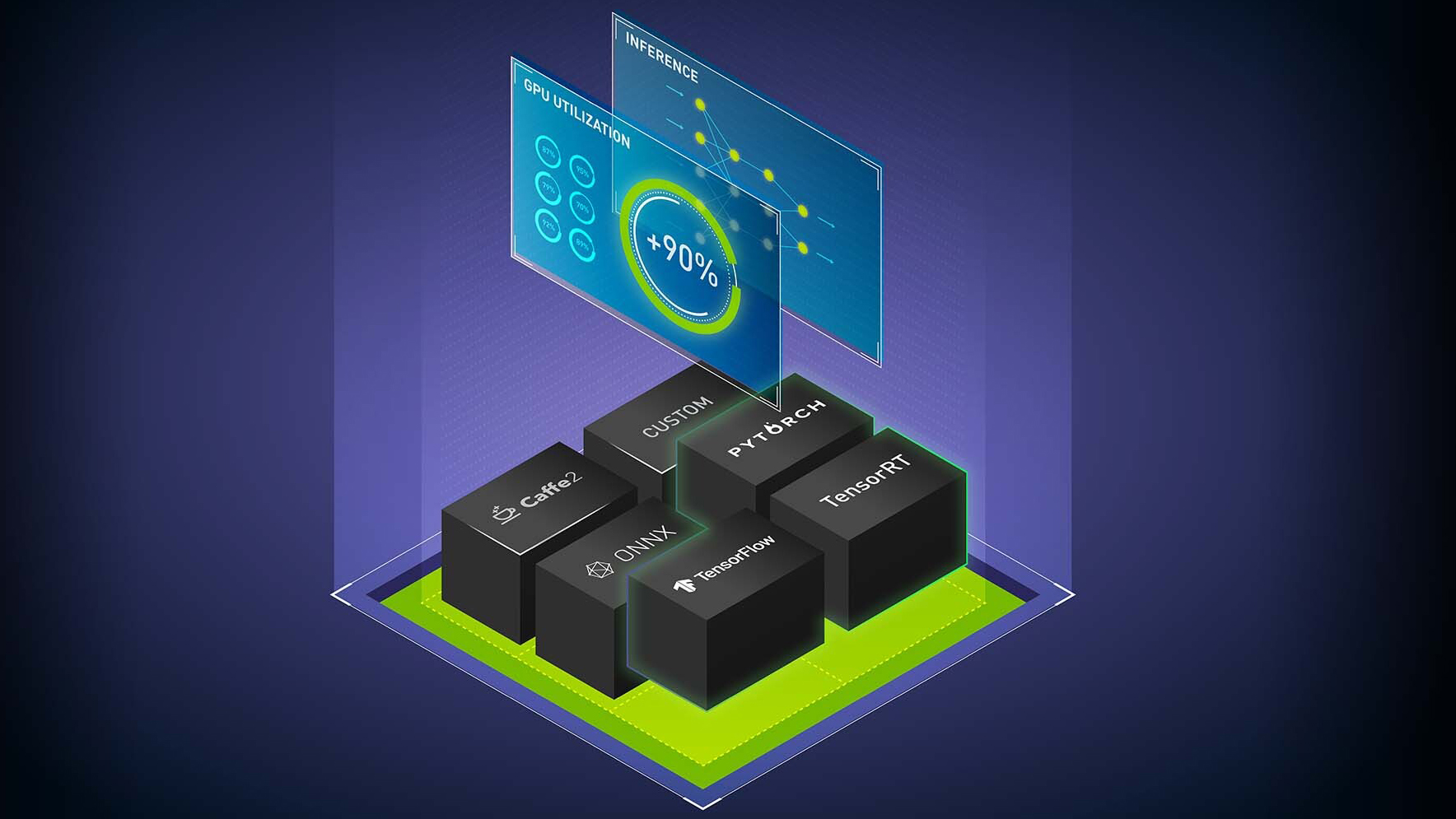
使用 NVIDIA Triton 推理服務器最大化 AI 推理服務性能: NVIDIA Triton 是一款開源推理服務軟件,可簡化人工智能模型在生產中的大規模部署。使用 NVIDIA Triton 在任何基于 Triton 或 CPU 的基礎設施上,從任何框架( TensorFlow 、 TensorRT 、 PyTorch 、 OpenVINO 、 ONNX 運行時、 XGBoost 或 custom )部署深度學習和機器學習模型。我們將討論一些新的后端、對嵌入式設備的支持、公共云上的新集成、模型集成和其他新功能。
使用 TensorRT 加速 PyTorch 推理:學習如何在不使用 Torch- TensorRT 離開框架的情況下加速 PyTorch 推理。 Torch- TensorRT 使 NVIDIA TensorRT GPU 優化的性能在 PyTorch 中可用于任何型號。您將了解 Torch- TensorRT 的關鍵功能、如何使用它們以及您可以預期的性能優勢。我們將介紹如何從經過訓練的模型過渡到針對特定硬件進行微調的推理部署,只需幾行熟悉的代碼。
使用 TensorRT 加速生產中的深度學習推理: TensorRT 是一款用于生產中使用的高性能深度學習推理的 SDK ,可最大限度地減少延遲和提高吞吐量。最新一代的 TensorRT 提供了一個新的編譯器來加速為 NVIDIA GPU 優化的特定工作負載。深度學習編譯器需要有一種健壯的方法來導入、優化和部署模型。我們將展示一個加速框架的工作流,包括 PyTorch 、 TensorFlow 和 ONNX 。
工具和框架
創建生產就緒 AI 模型的零代碼方法: NVIDIA TAO 是一種用戶界面驅動、基于工作流的模型自適應引導解決方案,允許用戶在數小時而不是數月內生成高度準確的計算機視覺或對話人工智能模型。這樣就不需要大量的訓練和深入的人工智能專業知識。我們將演示 TAO 如何通過采用預先訓練好的模型、使用數據對其進行微調,以及在不編寫任何代碼的情況下優化推理來授權用戶。
使用 NGC 加速 AI 工作流:為了簡化人工智能的開發, NVIDIA NGC 提供了開發工具和 SDK ,可以加速人工智能在醫療、智能城市和機器人等行業的培訓、推理和部署。我們將介紹數據科學家和開發人員如何使用 NGC (通過容器、預訓練模型和 SDK )跨本地、混合和邊緣平臺更快地構建和部署 AI 解決方案。我們將以演示結束,演示如何輕松開始構建計算機視覺解決方案,并為您留下一個 Jupyter 筆記本,以便您可以脫機重建自定義解決方案。
?