?
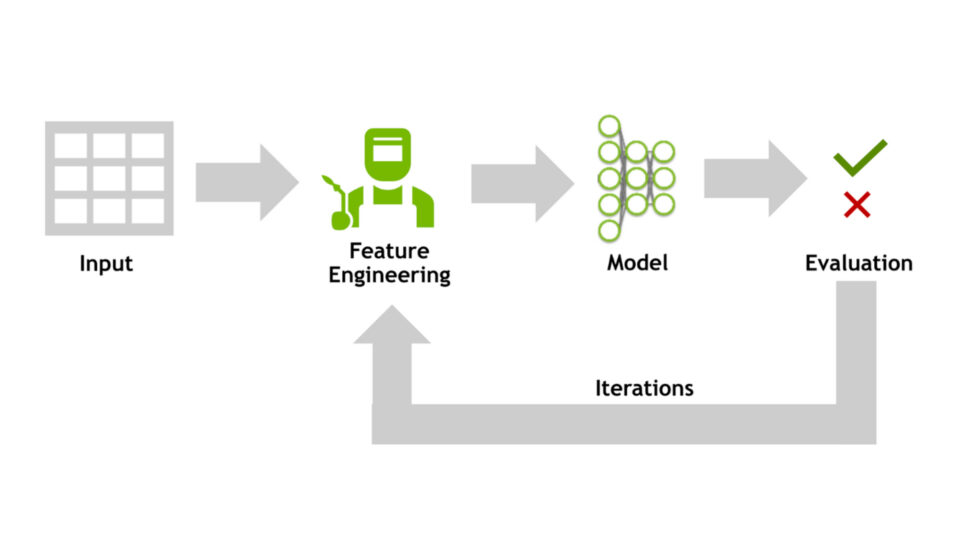
堆疊概述
堆疊是一種先進的表格數據建模技術,通過結合多個不同模型的預測來實現高性能。利用 GPU 的計算速度,可以高效地訓練大量模型。其中包括梯度提升決策樹 (Gradient Boosted Decision Trees, GBDT) 、深度學習神經網絡 (Deep Learning Neural Networks, NN) 以及其他機器學習 (Machine Learning, ML) 模型,例如支持向量回歸 (Support Vector Regression, SVR) 和 K 最近鄰 (K-Nearest Neighbors, KNN) 。這些單獨的模型被稱為 Level 1 模型。
然后訓練 Level 2 模型,這些模型使用 Level 1 模型的輸出作為輸入。Level 2 模型學習使用 Level 1 模型的不同組合來預測不同場景中的目標。最后,訓練簡單的 Level 3 模型,對 Level 2 模型的輸出求平均值。此過程的結果是三級堆棧。
?

不同的目標預測方法
不同的模型通過不同的方式解決問題來構建。可以使用不同類型的模型以及不同的架構和超參數。還可以使用不同的預處理方法和特征工程。
?

根據圖 2 中描述的見解,您至少可以通過以下四種方式預測目標:
- 按原樣預測 TARGET
- 預測目標比率除以 episode length 分鐘數
- 根據線性關系預測 RESIDUAL
- 預測 MISSING
episode_length_minutes
這四種方法都有兩種情況:
- 88% 的行具有 episode length 分鐘
- 12% 的行缺少 episode length 分鐘
預測目標
構建模型的常用方法是使用給定的目標。您可以從 10 個給定特征列中設計其他特征列,然后使用所有這些特征訓練模型以預測給定目標:
model = Regressor().fit(train[FEATURES],train['Listening_Time_minutes'])PREDICTION = model.predict(train[FEATURES]) |
僅使用這種方法就贏得了 2025 年 2 月 Kaggle Playground 競賽的第一名。有關更多詳細信息,請參閱 Grandmaster 專業提示:使用 cuDF pandas 憑借特征工程在 Kaggle 比賽中獲得第一名。
預測比率
預測給定目標的替代方案是預測目標與特征 Episode_Length_minutes 之間的比率:
train['new_target'] = train.Listening_Time_minutes / train.Episode_Length_minutes |
您可以訓練模型來預測這個新目標。然后將該預測值乘以 Listening_Time_minutes0 或 Episode_Length_minutes 的估算值。
預測殘差
預測給定目標的另一個替代方案是預測目標與 Linear Regression 模型之間的殘差。首先,訓練和推理 Linear Regression 模型。然后,通過從預測 Linear Regression 模型中減去現有目標來創建新目標:
model = LinearRegressor().fit(train[FEATURES],train['Listening_Time_minutes'])LINEAR_REGRESSION_PREDS = model.predict(train[FEATURES])train['new_target'] = train.Listening_Time_minutes - LINEAR_REGRESSION_PREDS |
您可以訓練模型來預測這個新目標。然后,將該預測添加到線性回歸預測中。
預測缺失特征
特征 Episode_Length_minutes 是最重要的特征,但在 12% 的訓練行中缺失。您可以構建單獨的模型來預測此特征。此外,您可以在存在 Episode_Length_minutes 的位置使用訓練數據和測試數據的所有行來訓練模型:
combined = cudf.concat([train,test],axis=0)model = Regressor().fit(combined[FEATURES], combined['Episode_Length_minutes'])Episode_Length_minutes_IMPUTED = model.predict(train[FEATURES]) |
預測 Episode_Length_minutes 后,您至少可以通過三種方式使用它來預測實際目標,包括:
- 使用
Episode_Length_minutes估算缺失值,然后訓練模型 - 替換
Episode_Length_minutes的整列,然后訓練模型 - 將預測的
Episode_Length_minutes與預測比率相乘
預測偽標簽
前幾節展示了一種使用測試數據特征列幫助估算訓練數據中缺失值的方法。這是一種從測試列中提取信息的強大技術。在現實世界中處理其他未標記數據時,它非常有用。使用測試列的另一種方法是使用偽標記。
偽標記(Pseudo labeling)過程分為三步:
- 照常訓練模型
- 測試數據的推理標簽
- 將偽標記測試數據與我們的訓練數據連接起來,然后訓練另一個模型
以下代碼是一個簡單示例。請注意,如果您使用 K-Fold 或 Nested K-Fold,則可以更好地泛化并避免泄漏。
0.72 x Episode_Length_minutes0構建堆棧
在使用 GBDT、NN、ML 以及之前提到的各種技術構建了數百個不同的模型之后,下一步就是構建堆棧。使用前向特征選擇,可將 Level 1 模型的 out-of-fold (OOF) 預測添加為 Level 2 模型的特征。此外,還可以包括原始數據集中的其他特征,以及從 OOF 預測衍生的工程特征,例如模型置信度或平均預測:
df['confidence'] = df[OOF].std(axis=1) df['concensus'] = df[OOF].mean(axis=1) |
對于多樣性,最好訓練多個 Level 2 模型。一個不錯的選擇是 GBDT Level 2 模型和 NN Level 2 模型。對于 Level 3,執行 Level 2 預測的加權平均值。結果是最終預測。
使用先進的堆棧技術實現了 CV 驗證指標 RMSE = 11.54 和私有排行榜 RMSE = 11.44。這在 2025 年 4 月舉辦的預測播客收聽時間的 Kaggle Playground 競賽中獲得了第一名。
總結
cuML 現在支持您以 GPU 速度創建所有統計 ML 模型。您可以使用 GPU 構建 GBDT,使用 GPU 構建 NN,現在使用 GPU 構建 cuML。通過快速創建許多不同的模型,您可以構建堆棧等高級表格數據解決方案。
快速實驗有助于找到更準確的解決方案。cuML 堆棧在 2025 年 4 月舉辦的預測播客收聽時間的 Kaggle Playground 競賽中獲得第一名,證明了這一點。有關參賽作品的更多詳細信息,請參閱第一名 – RAPIDS cuML Stack – 3 個級別。
?
?