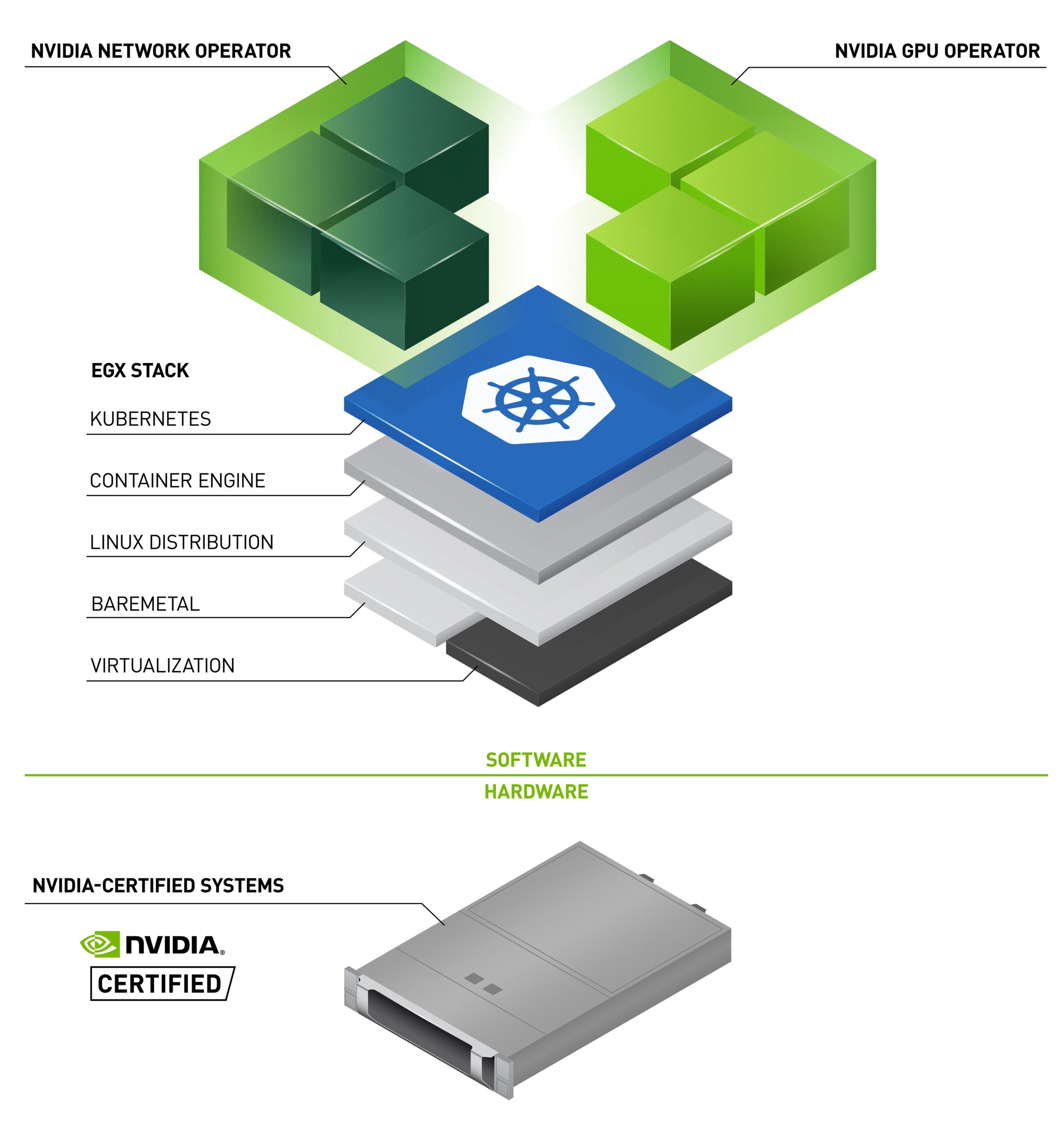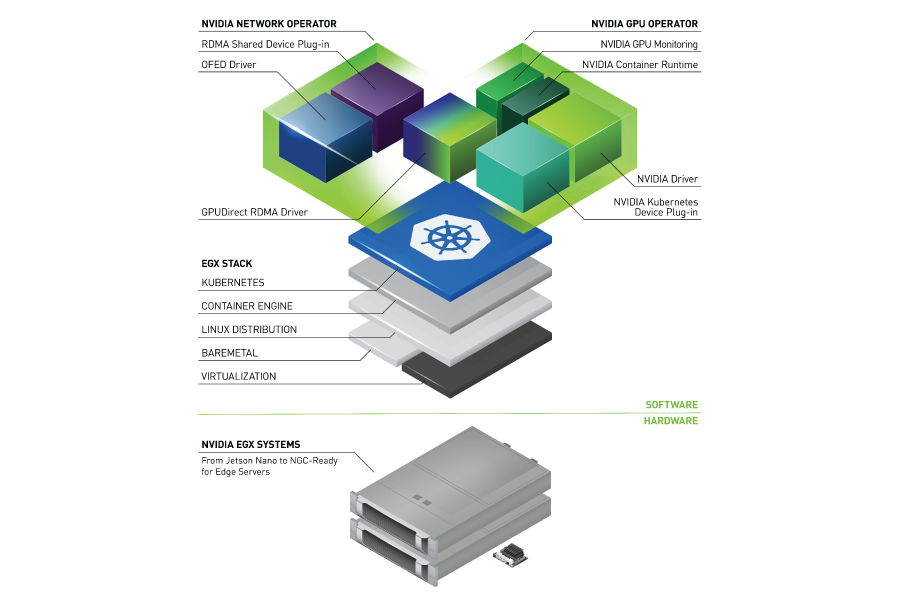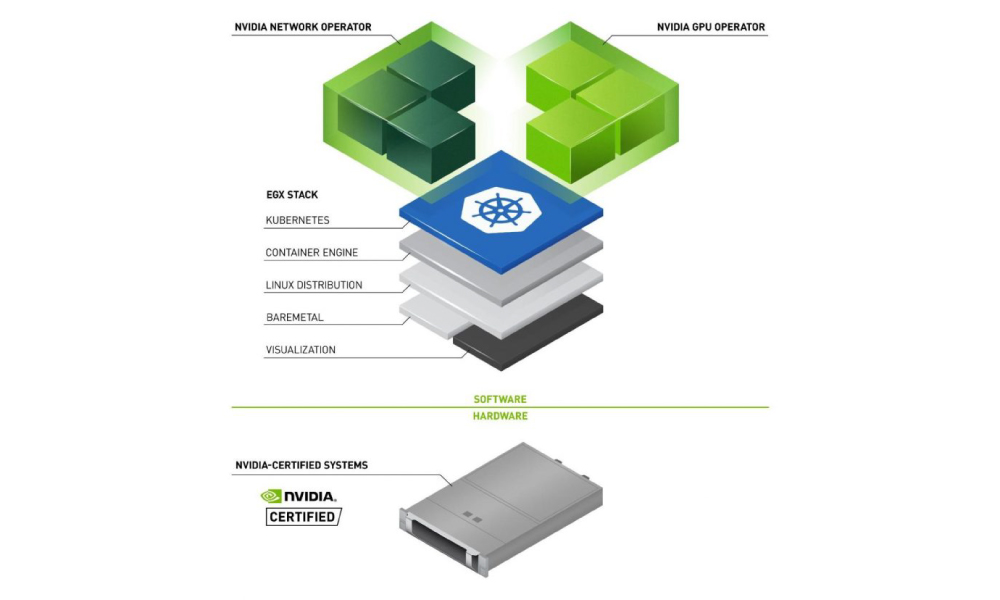
NVIDIA GPU 運營商允許企業在 Kubernetes 上輕松擴展 NVIDIA GPU 。
通過使用 Kubernetes 簡化 GPU 的部署和管理, GPU 運營商使基礎設施團隊能夠在幾分鐘內自動無誤地擴展 GPU 應用程序。
GPU Operator 1.9 現已推出,其中包括幾個關鍵功能,以及其他更新,使用戶可以更快地開始使用并保持不間斷服務。
GPU 操作員 1.9 包括:
- 支持使用 DGX 操作系統的 NVIDIA DGX A100 系統
- 簡化的安裝過程
使用 DGX 操作系統支持 DGX A100
對于 1.9 , GPU 操作員自動在 NVIDIA NVSwitch 系統上部署初始化結構所需的軟件,包括與 DGX OS 一起使用時的 DGX A100 。一旦初始化,所有 GPU 都可以在全 NVLink 帶寬下相互通信,以創建端到端可擴展計算平臺。
DGX A100 配備了世界上最先進的加速器,使企業能夠將培訓、推理和分析整合到統一、易于部署的 AI 基礎設施中。現在,有了 GPU 運營商的支持,企業可以將其應用程序從培訓擴展到與世界上最先進的系統相匹配。
簡化的安裝過程
對于 GPU 運營商的早期版本,使用 GPU 運營商和 OpenShift 的組織需要從 Red Hat 申請額外的權利,以便成功使用 GPU 運營商。由于授權密鑰過期,用戶需要重新應用這些密鑰,以確保其工作流程不會中斷。
GPU Operator 1.9 現在支持 OpenShift 的免授權驅動程序容器。這是通過利用 RedHat 提供的 Driver-Toolkit 映像以及為構建 NVIDIA 內核模塊而預先安裝的必要內核包來實現的。用戶不再需要確保運行 GPU 運算符時始終應用具有 RHEL 訂閱的有效證書。更重要的是,對于斷開連接的集群,它消除了對私有包存儲庫的依賴。
版本 1.9 還包括對帶有 MIG Manager 的預裝驅動程序的支持,對預裝 MOFED 使用 GPUDirect RDMA 的支持,對容器運行時的自動檢測,以及對 NOUVEAU 的自動禁用–所有這些都旨在讓用戶更容易開始并繼續使用 GPU 加速的 Kubernetes 。
此外, GPU Operator 1.9 會自動檢測工作節點上安裝的容器運行時。無需在安裝時指定容器運行時。
GPU 操作員 1.9 :
helm install --wait --generate-name nvidia/gpu-operator
GPU 操作員 1.8 及更早版本:
helm install --wait --generate-name nvidia/gpu-operator --set operator.defaultRuntime=containerd
GPU 操作員要求禁用 Nouveau 。在以前的 GPU 操作員版本中, K8s 管理員必須按照文檔 禁用 Nouveau 。 GPU 操作員 1.9 會自動檢測 Nouveau 是否已啟用并為您禁用。
GPU 操作員資源
以下資源可用于使用 NVIDIA GPU 運營商:
NVIDIA GPU 算子是許多 edge computing 解決方案的關鍵組件。了解有關 edge computing 的 NVIDIA 解決方案的更多信息。