當您在網頁上看到與上下文相關的廣告時,它很可能是由 Taboola 數據管道提供的內容。作為世界領先的內容推薦公司, Taboola 面臨的一大挑戰是經常需要擴展 Apache Spark CPU 集群容量,以滿足不斷增長的計算和存儲需求。
數據中心容量和硬件成本總是面臨壓力。
是什么導致了擴展挑戰? Taboola 使用一個復雜的數據管道,從用戶瀏覽器或移動設備延伸到多個數據中心。部署了復雜的深度學習算法、數據庫、基礎設施服務(如 Apache Kafka )和數千臺服務器,為世界各地的用戶提供最合適的廣告。
這篇文章描述了 Taboola 加入 RAPIDS Apache 加速器 Spark 以優化處理成本的動機,以及對遷移過程、挑戰和迄今為止吸取的經驗教訓的見解
滿足計算需求的管道面臨的挑戰
要計劃解決方案,您必須充分了解問題的嚴重性。在提供廣告內容時, Taboola 構建了一個獨特的頁面視圖其識別每個用戶及其與系統的交互。頁面視圖是一種大而寬的數據結構,使用全球數據中心收集的數據構建在一個巨大的 CPU 集群中。該結構包含 1500 多個不同的列,總計超過 1 TB 的每小時數據,所有這些數據都在我們的 Apache Spark CPU 集群中處理。
許多不同的分析器和 SQL 查詢以每小時 1 TB 的原始數據的速度處理傳入的頁面視圖,并以 2 、 6 、 12 和 48 小時的速度進行追趕。不斷創建新的分析器,以增加 Apache Spark 集群的負載。人們越來越需要更多的計算能力。
我們的主要任務是使需要計算的復雜管道更具可擴展性,同時具有成本效益。為了應對這一挑戰, Taboola 開始努力將數千個 CPU 核心遷移到 GPU ,以幫助我們應對不斷增加的待處理數據負載。
我們考慮的一個加速 Taboola 的 Apache Spark 環境的工具是 GPU 上的 RAPIDS 加速器。因此,與 CPU 相比,嘗試在 GPU 上實現更大的可擴展性是一個自然的決定
主要注意事項
首先,我們定義了成功遷移數千個 CPU 核心以利用 GPU 加速所需的測試內容:
- 真實生活數據集
- 硬件規格
- 最小 X 系數
- 復雜查詢測試
真實生活數據集
我們使用 Cyber Monday 的真實生產數據來測試和基準測試一個大型數據集。數據是每小時 1 . 5 TB 的 ZSTD 壓縮 Parquet 文件。它有 1500 多個所有本機類型的列,包括數組、結構和帶數組的嵌套結構。
硬件規格
對于硬件,我們從以下資源開始:
- 具有三個 A30 GPU 的 72 CPU 核心 Intel 服務器
- 一個 900-GB 的本地 SSD 驅動器,用于 Apache Spark 存儲其中間文件
- 380 GB 內存
- 10 Gb / s NIC 卡
最小 X 系數
將項目從 CPU 遷移到 GPU 時的主要問題通常是,“ X 因素是什么?”對于具有多個 GPU ‘的真實世界集群,問題是,“我需要多少 GPUXCPU 芯?”答案是你的 X 因素。
我們為 GPU 解決方案設置了一個 X 因子為 3 的最小條,在成本方面被認為是成功的。這一因素有助于保證我們的移民努力會得到回報。
復雜查詢測試
我們從多個研發部門的生產中挑選了 15 個查詢,與生產中的數百個查詢一樣多。
查詢大多很復雜,包括許多 SQL 操作:
- 聚合
- 排序
- 橫向視圖爆炸
- 分發者
- 窗口功能
- UDFS
圖 1 顯示了一個示例查詢。
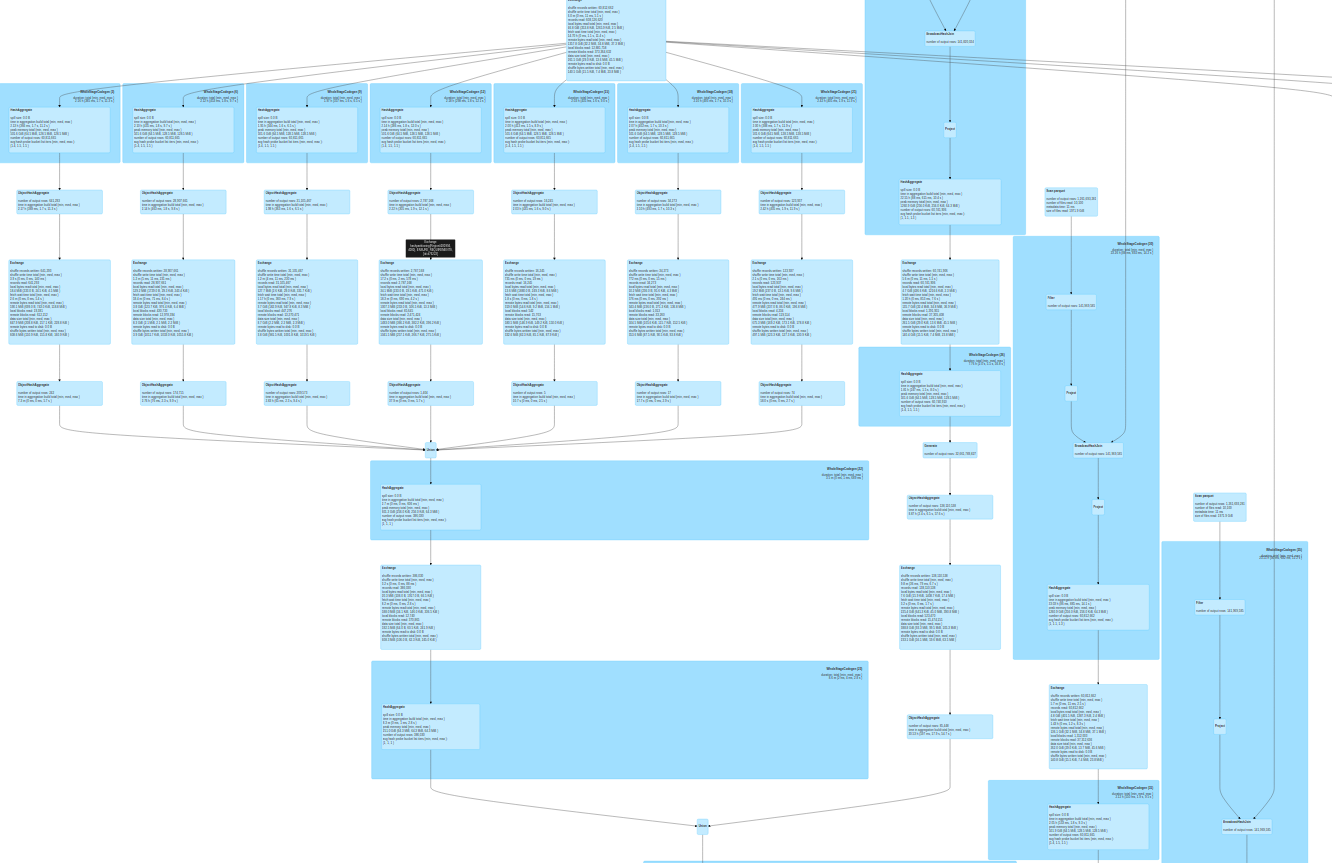
表 1 顯示了 Taboola 的因素。
| 分析儀名稱 | 平均生產時間 CPU | 平均 GPU 時間 | GPU 因子 |
| 播發器維度(按請求) | 586 . 41 | 31 . 91 | 18 . 38 |
| 經驗分析頁面 | 3021 . 6 | 102 . 92 | 29 . 36 |
| 經驗分析安置 | 680 . 84 | 47 . 12 | 14 . 45 |
| 實驗分析請求庫 | 6605 . 44 | 362 . 68 | 18 . 21 |
| 實驗分析會話 | 207 . 87 | 23 . 01 | 9 . 03 |
| 媒體數據趨勢數據庫 | 222 . 94 | 9 . 8 | 22 . 75 |
| 性能測量 | 397 . 17 | 86 . 22 | 4 . 61 |
| 發布者性能 | 965 . 63 | 108 . 95 | 8 . 86 |
| RBoxAB 測試 | 63 . 04 | 2 . 4 | 23 . 88 |
| 每小時由主人狂歡 | 487 . 44 | 95 . 03 | 5 . 13 |
| SlaUnit 可用填充率 | 1199 . 93 | 152 . 38 | 7 . 87 |
| 供應數據趨勢 | 529 . 92 | 45 . 28 | 11 . 7 |
CPU 到 GPU 遷移目標
我們從能夠擴展到多 GPU 和多服務器集群的單個服務器(如前所述)開始。該集群將由 Kubernetes 管理,而不是目前的 Mesos 集群。 Mesos 即將過時, NVIDIA 環境支持 Kubernetes 。
軟件和硬件環境中的任何更改都必須忽略 Taboola 的代碼。在 GPU 上運行的查詢應該以 CPU 的確切結果執行。該團隊意識到了這一挑戰,因為生產穩定性是一個關鍵目標。
最后,我們希望 GPU 的性能優于 CPU ,最小系數為 3 。我們對幾個 GPU 進行了基準測試,包括 NVIDIA P100 、 NVIDIA V100 、 NVID IA A100 和 NVIDIA A30 。我們了解到 A30 GPU 為我們提供了最佳性價比。
RAPIDS 加速器首次實驗
我們使用 RAPIDS 加速器運行 SQL 查詢,結果有些令人失望。一些不太復雜的查詢,主要是橫向視圖爆炸,給出了 CPU 的 3x 到 5x 因子。一些查詢顯示的因子要低得多,而其他查詢則崩潰了。
在 RAPIDS GitHub 回購中提出問題后,我們嘗試了相關的 Apache Spark 和 RAPIDS 加速器參數,并開始看到更好的結果:
sql.files.maxPartitionBytes: CPU 使用 128 MB 的默認值。這對于 GPU 來說太低了。我們使用的是 1 – 2 GB 。sql.shuffle.partitions:我們發現在大多數情況下, 200 的默認值就足夠了。rapids.sql.concurrentGpuTasks:確定可以在 GPU 上同時運行的任務數。至少兩項任務似乎是最好的。
調整這些參數可以幫助查詢更平穩地運行,在某些情況下性能更佳。此外,NVIDIA 加速 Spark 分析工具可以自動生成調整建議。
挑戰# 1 – Parquet 解析開銷
我們在一些性能較差的 SQL 查詢中遇到了瓶頸,其中大多數查詢在解析 CPU 上的 Parquet 頁腳數據時都浪費了時間。 Parquet 數據包含 1500 多列。很明顯,用于解析頁腳的常規 Java 代碼對于如此大的頁腳來說是不夠的。
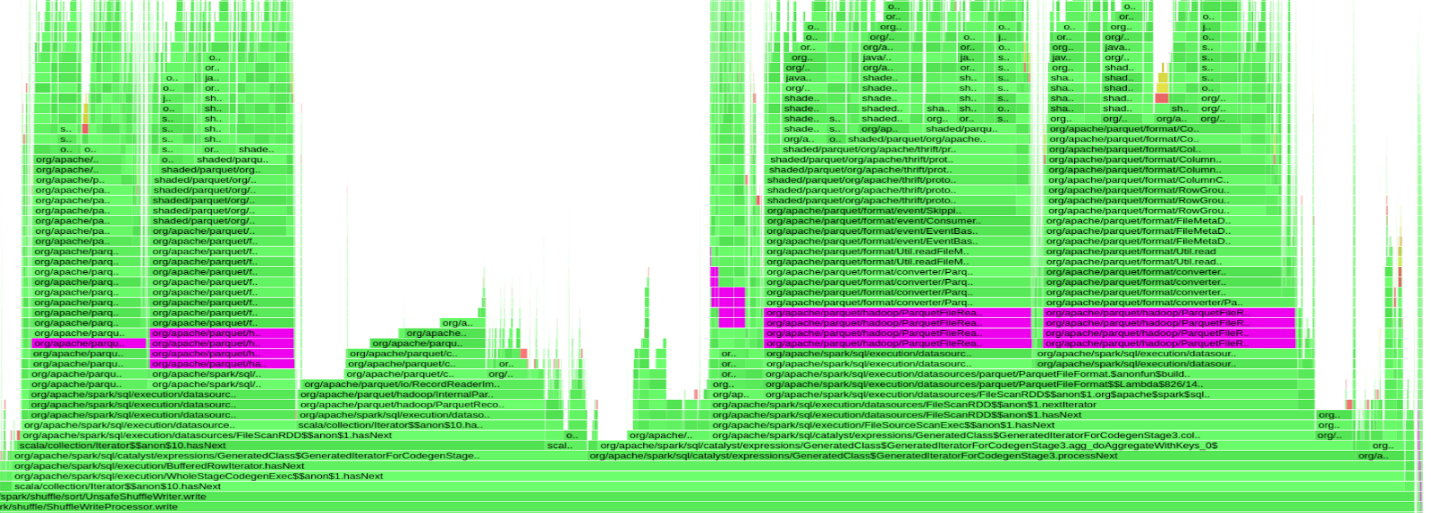
圖 2 顯示了 9 秒 Apache Spark 任務的 NVIDIA 探查器輸出的一小部分,其中 GPU 大部分處于空閑狀態(僅工作 330ms )

圖 3 顯示了遭受這種行為的查詢的火焰圖。紫色條表示在org.apache.parquet.hadoop.ParquetFileReader班當 GPU 空閑時,幾乎 50% 的查詢時間都花在了解析 Parquet 的頁腳上。
因此,我們開始測試另一種解決方案。在解析頁腳時, Parquet 代碼會對每個行組的頁腳元數據進行串行迭代。我們調整了 Parquet 參數以減少每個文件中的行組數量。這給了我們大約 10-15% 的改善。我們發現這種改進是不夠的。
每次讀取元數據時,即使每次查詢只要求 50-100 列,也會連續讀取和解析所有 1500 列元數據。我們想索引頁腳元數據,這樣我們就可以直接訪問它,而不是串行讀取整個 1500 個數據列。我們通過改變Parquet-mrC ++和 Java 中的公共代碼。盡管我們得到了不錯的性能結果,但這太麻煩和復雜了。
幸運的是, NVIDIA RAPIDS 團隊有一個更好的想法。解決方案是優化 Parquet 文件解析。他們用 Arrow 的 C ++實現取代了 Java 代碼。我們現在有了rapids.sql.format.parquet.reader.footer.type 對于我們的 GPU 實現,默認設置為 NATIVE 。瓶頸已經解決,由于 CPU 上的頁腳解析開銷, GPU 不再有空閑的查詢。
挑戰# 2 –網絡瓶頸
一個薄弱的網卡導致了下一個瓶頸。當 10 Gb / s 以太網卡承受 CPU 負載時,它無法承受 GPU 負載
該解決方案是 GPU 負載的最佳網卡。將 10 Gb / s 以太網卡更換為 25 Gb / s 以太網卡消除了這一瓶頸。
挑戰# 3 —磁盤 I / O 瓶頸
即使消除了這兩個瓶頸,查詢仍然運行緩慢。在 Apache Spark 用戶界面上,我們看到了關于發生了什么的清晰指示。
| 公制 | 最小值 | 第 25 百分位 | 中值的 | 第 75 百分位 | 最大值 |
| 期間 | 0 . 4 秒 | 0 . 6 秒 | 0 . 8 秒 | 1 秒 | 1 . 2 分鐘 |
| GC 時間 | 0 . 0 毫秒 | 0 . 0 毫秒 | 0 . 0 毫秒 | 90 . 0 毫秒 | 0 . 5 秒 |
| 無序讀取大小/記錄 | 214 毫巴/ 1000 | 22 . 3 毫巴/ 1000 | 22 . 5 毫巴/ 1000 | 22 . 7 毫巴/ 1000 | 27 . 3 毫巴/ 1000 |
| 無序寫入大小/記錄 | 175 毫巴/ 1000 | 17 . 9 毫巴/ 1000 | 18 毫巴/ 1000 | 181 毫巴/ 1000 | 181 毫巴/ 1000 |
| 計劃程序延遲 | 3 . 0 毫秒 | 5 . 0 毫秒 | 5 . 0 毫秒 | 7 . 0 毫秒 | 3 秒 |
| 峰值執行內存 | 6400 萬 | 6400 萬 | 6400 萬 | 6400 萬 | 6400 萬 |
| 無序寫入時間 | 9 . 0 毫秒 | 13 . 0 毫秒 | 18 . 0 毫秒 | 21 . 0 毫秒 | 59 秒 |
在表 2 中最大值列中,任務的持續時間為 1 . 2 分鐘,而無序寫入時間耗時 58 秒。當 GPU 處于空閑狀態時,大量時間被浪費在進行混洗工作上。
圖 4 和圖 5 顯示了相應的事件時間線圖。橙色部分表示讀或寫的混洗時間。綠色部分是計算時間。我們在閱讀或編寫 shuffle 文件時浪費了很多時間。
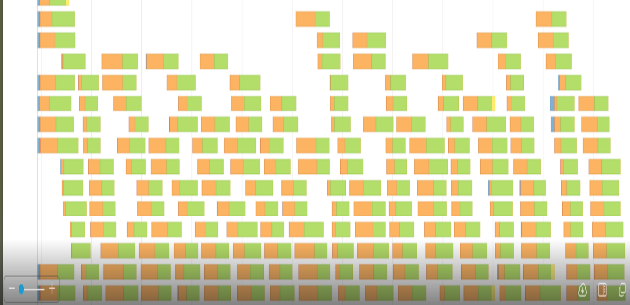
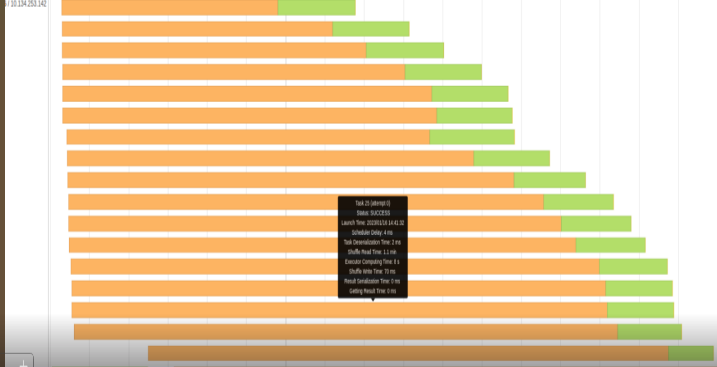
我們的 shuffle 文件在某些查詢中可以達到 500 GB 甚至更高。我們顯然無法將如此大量的數據保存在服務器的 RAM 中,因此 shuffle 文件存儲在本地 SSD 驅動器中。
在與我們的團隊進行快速調查后,我們發現 SSD 驅動器被配置為使用 RAID-1 。每個臨時混洗文件被保存兩次到磁盤。這浪費了很多時間,切換到 RAID-0 在一定程度上改善了這種情況。
GPU 比 CPU 對 SSD 驅動器施加了更大的壓力,因此我們不得不用 NVMe 驅動器更換 SSD 。解決方案是切換到 6 TB NVMe 驅動器。我們刪除了其中一個 GPU ,為 NVMe 驅動器創建了一個插槽。之后,我們沒有出現混洗讀寫性能問題。我們還了解到,一個 NVMe 驅動器可以承受兩個 A30 GPU 的工作負載。
遷移到 Kubernetes
因為我們的 Mesos 集群將變得過時,所以必須從獨立的 POC 機器遷移到 Kubernetes 。這涉及到大量的配置工作和其他次要工作。盡管如此,實施起來還是很簡單。
其基本思想是 Apache Spark 驅動程序位于非 GPU 機器上,而每個 K8s Pod 將與單個 GPU 相關聯。想要了解更多信息,請訪問 RAPIDS 和 Kubernetes 的入門指南。
下面的代碼示例展示了一些主要的相關 Kubernetes 配置。
spring: profiles: include: spark_k8s_extra_files spark: driver: sparkConnector: sparkOpts: spark.kubernetes.container.image.pullPolicy: Always spark.kubernetes.authenticate.serviceAccountName: spark spark.kubernetes.executor.deleteOnTermination: true spark.deploy.mode: client spark.executorEnv.preLoadMemoryLibraryName: "/usr/libjemalloc.so" spark.executorEnv.xmxPercentage: 80 spark.kubernetes.memoryOverheadFactor: 0.1 spark.mesos.fetcherCache.enable: false spark.executor.extraJavaOptions: -XX:-UsePerfData -XX:-OmitStackTraceInFastThrow -verbose:gc -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:+PrintFlagsFinal -Dmapreduce.fileoutputcommitter.algorithm.version=2 -XX:NativeMemoryTracking=detail spark.plugins: "com.nvidia.spark.SQLPlugin" spark.kubernetes.executor.podTemplateFile: /conf/k8GPUPodTemplateProduction.yml spark.executor.resource.gpu.vendor: "nvidia.com" spark.executor.resource.gpu.discoveryScript: /conf/getGpusResources.sh spark.executor.resource.gpu.amount: 1 # GPU task configuration spark.rapids.sql.variableFloatAgg.enabled: "true" spark.rapids.sql.castFloatToDecimal.enabled: "true" spark.rapids.sql.rowBasedUDF.enabled: "true" spark.rapids.sql.format.parquet.reader.footer.type: "NATIVE" spark.rapids.sql.explain: "all" # For debug. # Most common spark.rapids.sql.concurrentGpuTasks: 4 spark.sql.files.maxPartitionBytes: "2048m" spark.rapids.sql.batchSizeBytes: "1g" spark.sql.shuffle.partitions: 200 |
要加速多少 GPU ?
如果目標是使用 GPU 比 CPU 更經濟高效地加速工作負載,那么我們首先必須了解 GPU 的速度有多快。我們用兩個 A30 GPU 建立了一個測試系統,并將生產數據與我們的大型 CPU 核心生產環境并行傳輸到該系統。
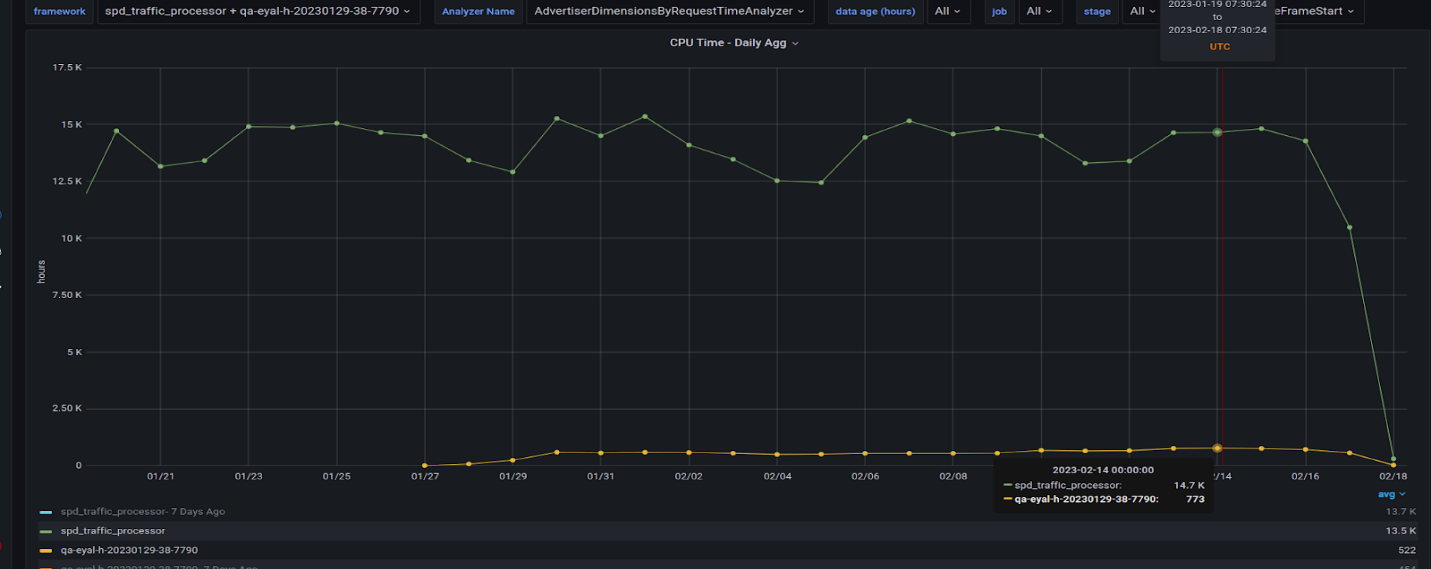
圖 6 顯示了在生產 CPU 集群上以及在具有兩個 A30 GPU 的服務器上運行的兩個最重的查詢。
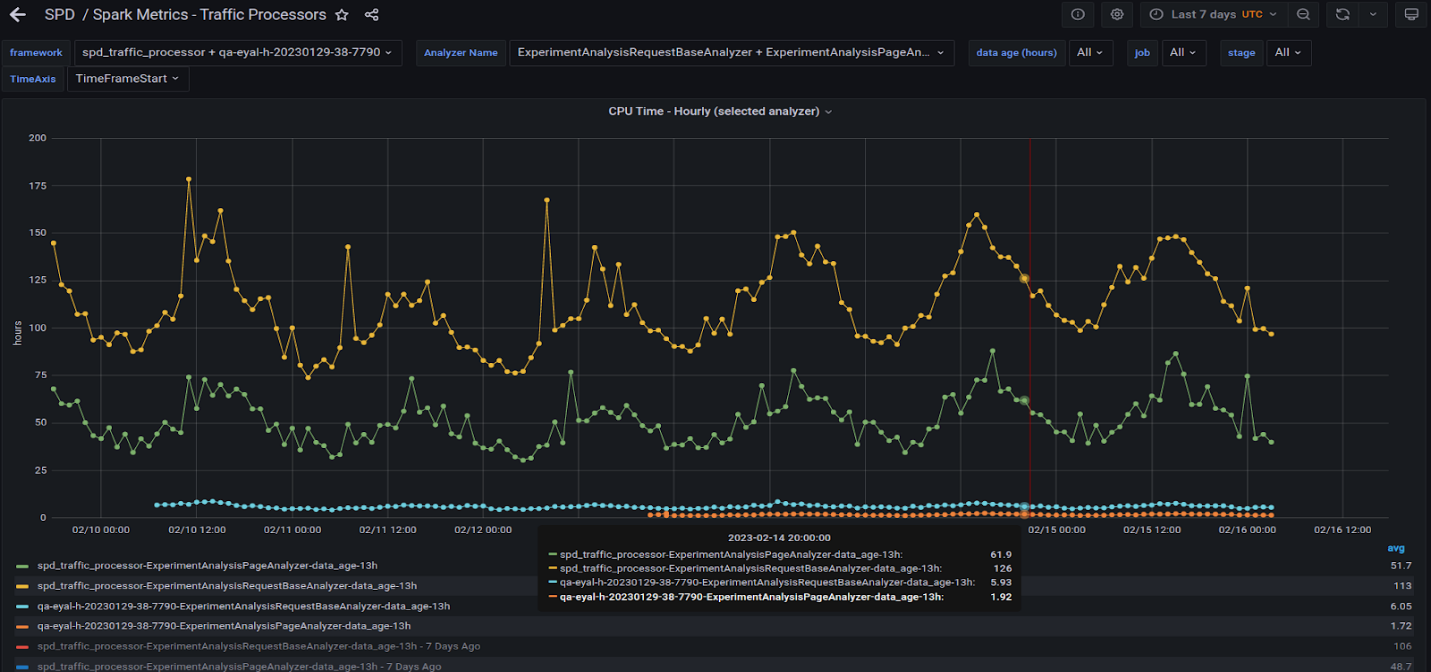
黃線和綠線表示 CPU 集群上運行的兩個查詢的所有任務編號的每小時總時間。藍色和橙色線表示在 GPU 服務器上運行的相同查詢。 GPU 因子為 20 倍或更高。
圖 7 顯示了在圖 6 所示的 GPU 上運行的兩個查詢。觀察到它們的行為與 CPU 相似,因為波峰和波谷在一天中的不同時間大致對齊。
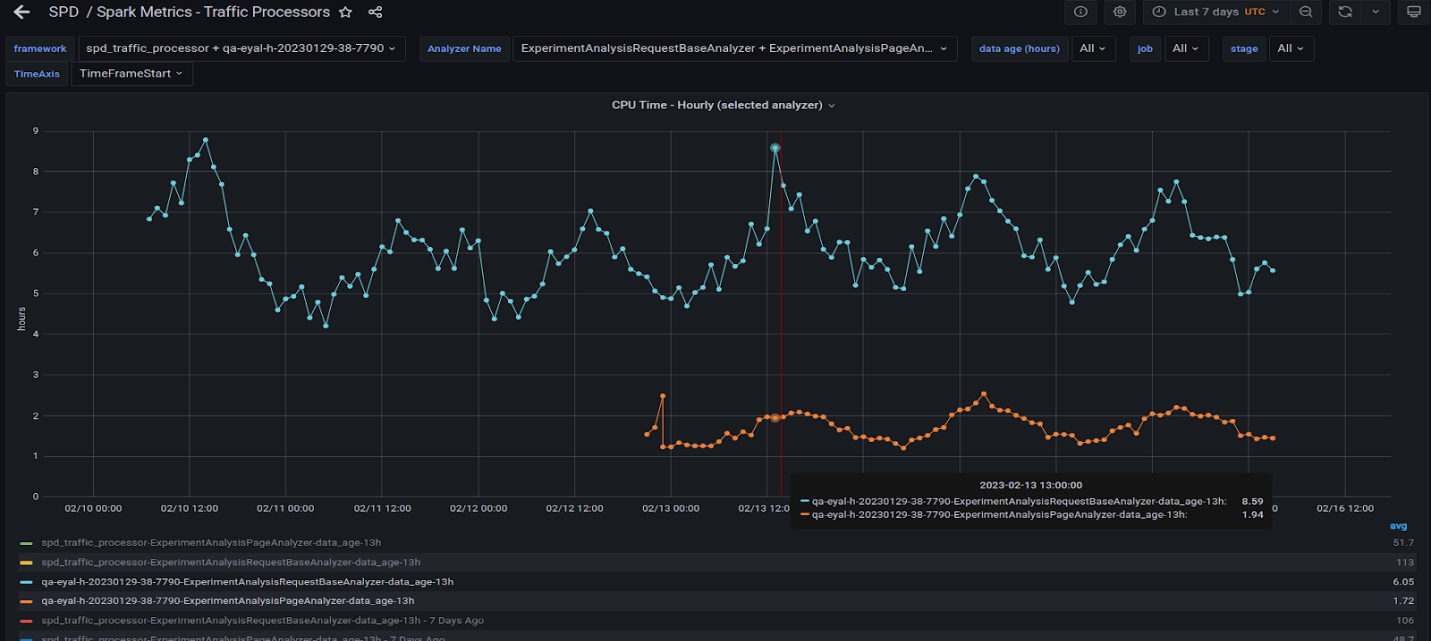
圖 8 很有趣,因為它顯示了我們遷移到 GPU 的所有查詢及其在 CPU 上的對應查詢的因子。 GPU 運行缺少最大的查詢,我們仍在將其遷移到 GPU 。這可能會使 GPU 的總時間每天增加 200 小時。
經驗教訓
展望我們的下一步遷移步驟, Taboola 希望將查詢從其他研發部門轉移到 GPU ,從而在生產中產生更多的 GPU 。這意味著 QA 必須在生產過程中更密切地監控系統。
熟悉 RAPIDS Apache 加速器 Spark 是一項令人驚嘆的“快樂之旅”。從處理 Parquet 文件到將 GPU 推向極限,我們在處理大型數據管道以及管理數據中心容量和硬件成本方面變得更加得心應手。用這種方法識別和應對硬件限制被證明是有益的。
以下是 Taboola 為那些考慮 CPU 到 GPU 遷移的人提供的最重要的收獲:
- 在具有多個變量的復雜環境中調整參數從來都不是一件簡單的事。盡可能將此任務自動化。使用 NVIDIA Accelerated Spark 分析工具來幫助解決這一挑戰可能是個好主意,因為它可以很容易地建議優化的參數。
- 超越 CPU 和 GPU 尋找瓶頸的解決方案。再多的 GPU 馬力也無法解決基本上與網絡、磁盤、帶寬或配置和解析相關的問題。
- 多個 GPU 并不妨礙性能,但 GPU ‘非常強大,因此您可能會使用比最初想象的更少的 GPU 來獲得良好的性能。最好對此進行測試以降低成本。
- 我們通過 RAPIDS 加速器和 NVIDIA GPU 實現了我們的 20 倍因子。最大的教訓是,在受益于 GPU 加速之前,我們需要更好地了解現有環境中發生了什么。一個 A30 GPU 在某些工作負載下保持與~ 200- CPU 核心測試集群相同的生產負載。
想要了解如何在基于 Apache Spark CPU 的環境中實現性能倍數的更多信息,請訪問 GPU 加速 Apache Spark。
鳴謝
在兩個偉大群體的支持、援助和耐心下,我們的巨大努力更加成功。在塔布拉:安德烈·古林、吉拉德·扎莫欽斯基、伊戈爾·伯曼、科倫·科西亞、利奧爾·查加和邁克爾·塔拉諾夫。 NVIDIA RAPIDS 團隊成員: Alessandro Bellina 、 Hao Zhu 、 Karthikeyan Rajendran 、 Robert Evans 和 Sameer Raheja 。
?