大型語言模型 (LLM)是在具有數千億參數的互聯網級數據集上進行訓練的深度學習算法。LLM 可以讀取、寫入、編碼、繪制和增強人類創造力,以提高各行各業的生產力,并解決世界上最棘手的問題。
LLM 被廣泛應用于各行各業,從零售到醫療健康,以及各種任務。它們學習蛋白質序列的語言,以生成新的可行化合物,從而幫助科學家開發創新的救命疫苗。它們幫助軟件程序員根據自然語言描述生成代碼并修復錯誤。它們還提供生產力 Co-Pilot,以便人類可以更好地完成他們擅長的工作 – 創建、提問和理解。
要在企業應用程序和工作流中有效利用 LLM,需要了解模型選擇、自定義、優化和部署等關鍵主題。本文將探討以下企業 LLM 主題:
無論您是希望構建自定義模型的數據科學家,還是探索 LLM 在組織中的潛力的首席數據官,請繼續閱讀以獲取寶貴見解和指導。
組織如何使用 LLM
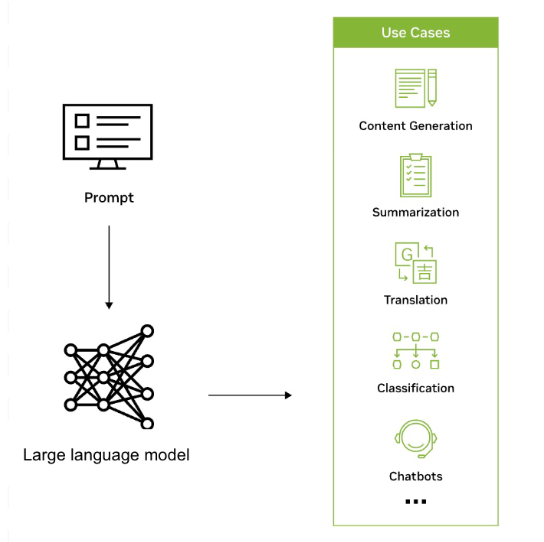
LLM 被用于各種跨行業應用,基于從海量數據集中獲得的知識,高效地識別、匯總、翻譯、預測和生成文本及其他形式的內容。例如,公司正在利用 LLM 開發類似聊天機器人的界面,以支持用戶進行客戶查詢,提供個性化建議,并協助進行內部知識管理。
LLM 還有可能擴大 AI 在各行各業和企業中的覆蓋范圍并推動新一波的研究、創意和生產力浪潮。它們可以幫助生成復雜的解決方案,以解決諸如healthcare和chemistry.LLM 還可用于創建重塑的搜索引擎、輔導聊天機器人、合成工具、營銷材料等等。
ServiceNow 與 NVIDIA 的協作將有助于將自動化提升到新的水平,從而提高生產力并更大限度地提高業務影響。正在探索的生成式 AI 用例包括開發智能虛擬助理和代理,以幫助回答用戶問題和解決支持請求,以及使用生成式 AI 自動解決問題、生成知識庫文章和進行聊天摘要。
瑞典的一個聯盟正在使用 NVIDIA NeMo Megatron 開發先進的語言模型,并將提供給北歐地區的所有用戶。該團隊的目標是訓練具有高達 1750 億參數的 LLM,該 LLM 可以處理北歐語言(瑞典語、丹麥語、挪威語,可能還有冰島語)中的各種語言任務。
該項目被視為一項戰略資產,在一個涵蓋近 200 個國家/地區和數千種語言的世界中,它是數字主權的基石。如需了解詳情,請參閱國王的瑞典:AI 在斯堪的那維亞重寫書籍。
韓國領先的移動運營商 KT 使用 NVIDIA DGX SuperPOD 平臺和 NVIDIA NeMo 框架。NeMo 是一個端到端的云原生企業框架,可提供預構建組件,用于構建、訓練和運行自定義 LLM。
KT 的 LLM 已被用于提高對該公司 AI 驅動的揚聲器 GiGA Genie 的理解,該揚聲器可以控制電視、提供實時交通更新,并根據語音命令完成其他家庭輔助任務。有關詳細信息,請參閱“Hangul 不會掛斷電話:KT 借助 NVIDIA AI 訓練智能揚聲器和客戶呼叫中心”。
關鍵資源
使用、自定義或構建 LLM?
組織可以選擇使用現有 LLM、自定義預訓練 LLM,或從頭開始構建自定義 LLM.使用現有 LLM 可提供快速且經濟高效的解決方案,同時自定義預訓練 LLM 可讓組織針對特定任務調整模型并嵌入專有知識。從頭開始構建 LLM 具有極高的靈活性,但需要大量的專業知識和資源。
NeMo 提供了多種 定制技術,并針對語言和圖像應用程序的模型大規模推理進行了優化,具有多 GPU 和多節點配置。有關更多詳情,請參閱 借助 NVIDIA NeMo 釋放企業就緒型 LLM 的強大功能。
NeMo 使企業能夠簡單、經濟高效且快速地開發生成式 AI模型。它可以在所有主要的云平臺上使用,包括 Google Cloud 的 A3 實例,以及由NVIDIA H100 Tensor Core GPU大規模構建、自定義和部署的 LLM。如需了解詳情,請參閱在 GPU 加速的 Google Cloud 上使用 NVIDIA NeMo 簡化生成式 AI 開發。
如果您想通過易用的界面在瀏覽器中快速試用生成式 AI 模型(例如 Lama 2),請訪問 NVIDIA AI Playground。
關鍵資源
從基礎模型開始
基礎模型是大型 AI 模型,通過自監督式學習對大量未標記數據進行訓練。例如 Lama 2、GPT-3 和 Stable Diffusion。
這些模型可以處理各種任務,例如圖像分類、自然語言處理和問答,并且準確度非常高。
這些基礎模型是構建更專業、更復雜的自定義模型的起點。組織可以自定義基礎模型,使用特定于域的已標記數據,為特定用例創建更準確和上下文感知的模型。
基礎模型通過在可能跟隨輸入的所有項目上生成概率分布,然后從該分布中隨機選擇下一個輸出,從而從單個提示中生成大量獨特的響應。模型使用上下文來放大隨機化。模型每次生成概率分布時,都會考慮最后生成的項目,這意味著每個預測都會影響接下來的每個預測。
NeMo 支持 NVIDIA 訓練的基礎模型以及社區模型,例如 Llama 2、Falcon LLM 和 MPT。您可以直接在 NVIDIA AI Playground 中免費體驗各種經過優化的社區和 NVIDIA 構建的基礎模型。然后,您可以使用專有企業數據自定義基礎模型,從而生成一個適合您的業務和領域的模型。
關鍵資源
構建自定義語言模型
企業通常需要自定義模型來根據其特定用例和領域知識定制#語言處理功能。自定義 LLM 使企業能夠在特定行業或組織環境中更高效、更準確地生成和理解文本。它們使企業能夠創建與品牌語音保持一致的個性化解決方案,優化工作流程,提供更精確的見解,并提供增強的用戶體驗,最終在市場中贏得競爭優勢。
NVIDIA NeMo 是一個功能強大的框架,它提供了一系列組件,可以在本地或所有領先的云服務提供商中構建和訓練自定義的 LLM。這包括 NVIDIA DGX 云。其中包括從提示學習到高效參數調優,再到通過人類反饋 (RLHF) 增強學習的 一套定制技術。NVIDIA 還發布了一種名為 SteerLM 的技術,允許在推理期間進行調整。
訓練 LLM 時,始終存在其變為“垃圾輸入,垃圾輸出”的風險。大部分工作是獲取和整理用于訓練或自定義 LLM 的數據。
NeMo 數據管理員是一款可擴展的數據整理工具,它可以幫助您為預訓練的 LLM 整理萬億令牌的多語種數據集。這款工具允許您使用精確或模糊的方法刪除預處理和重復的數據集,從而確保模型基于獨特的文檔進行訓練,可能大幅降低訓練成本。
關鍵資源
- NVIDIA NeMo
- NVIDIA DGX 云
- 選擇大語言模型的自定義技術
- 方向盤: NVIDIA NeMo SteerLM 允許公司在推理期間自定義模型的響應
- 整理萬億級令牌數據集:隆重推出 NVIDIA NeMo 數據整理器
將 LLM 連接到外部數據
將 LLM 連接到外部企業數據源可增強其功能。這使 LLM 能夠執行更復雜的任務,并利用自上次訓練以來創建的數據。
檢索增強生成 (RAG) 是一種架構,使 LLM 能夠使用當前經過精心策劃的特定領域數據源,這些數據源易于添加、刪除和更新。借助 RAG,外部數據源被處理為向量(使用嵌入模型),并放入向量數據庫,以便在推理時快速檢索。
除了降低計算和財務成本外,RAG 還提高了準確性,并使 AI 驅動的應用程序更加可靠和可信賴。GPU 加速向量搜索由于其在 LLM 和生成式 AI 中的應用,已成為 AI 領域的熱門話題之一。
關鍵資源
保持 LLM 正常運行并確保其安全
為確保大語言模型 (LLM) 的行為符合預期結果,必須建立指南、監控其性能并根據需要進行自定義。這涉及定義道德界限、解決訓練數據中的偏差,以及根據預定義的指標定期評估模型的輸出(通常與護欄功能配合使用)。有關更多信息,請參閱NVIDIA 實現可信、安全可靠的大型語言模型對話系統。
NVIDIA 為了滿足這一需求,開發了一個開源工具包,NeMo 護欄,它可以幫助開發者確保其生成式 AI 應用準確、合適且安全。該工具包提供了一個可以與所有 LLM(包括 OpenAI 的 ChatGPT)配合使用的框架,使開發者能夠更輕松地構建安全可靠的 LLM 對話系統,從而充分利用基礎模型。
對于 AI 驅動的生成式應用來說,保持 LLM 的安全至關重要。NVIDIA 還推出了加速型機密計算,這是一項突破性的安全功能,可在緩解威脅的同時,為 AI 工作負載提供 NVIDIA H100 Tensor Core GPU 前所未有的加速。此功能可確保敏感數據即使在處理過程中也保持安全和受保護。
關鍵資源
在生產環境中優化 LLM 推理
優化 LLM 推理涉及模型量化、硬件加速和高效部署策略等技術。模型量化可減少模型的內存占用,而硬件加速則利用 GPU 等專用硬件來加快推理速度。高效的部署策略可確保生產環境中的可擴展性和可靠性。
NVIDIA TensorRT-LLM 是一個開源軟件庫,它能在 NVIDIA 加速計算上為大型 LLM 推理提供強大的支持。用戶可以利用它將模型權重轉換為新的 FP8 格式,并編譯模型,以便利用 NVIDIA H100 GPU 優化的 FP8 內核。相比于 NVIDIA A100 GPU,TensorRT-LLM 可以將推理性能提升 4.6 倍。它提供了一種更快、更高效的 LLM 運行方式,使其更易于訪問且更具成本效益。
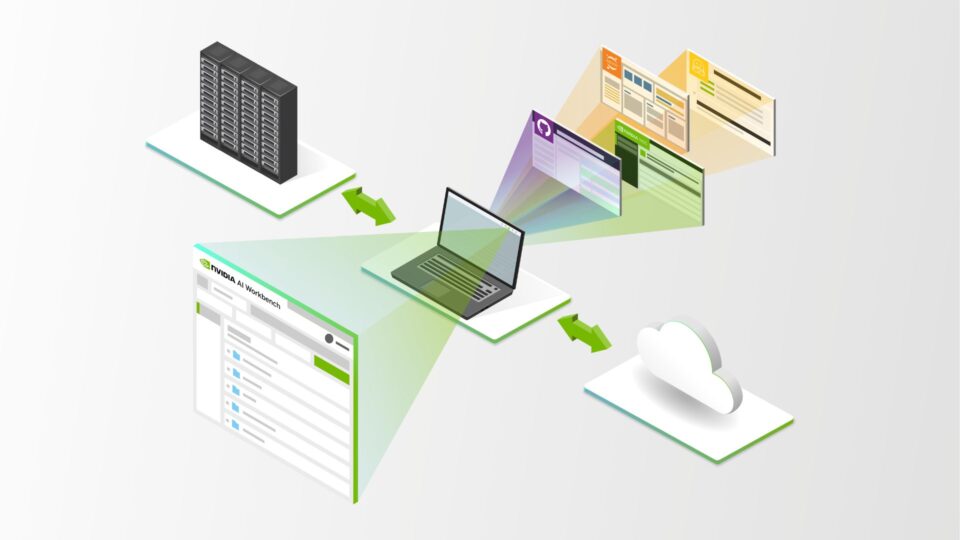
這些自定義生成式 AI 流程涉及將模型、框架、工具包等整合在一起。其中許多工具都是開源工具,需要時間和精力來維護開發項目。該流程可能會變得異常復雜和耗時,尤其是在嘗試跨多個環境和平臺進行協作和部署時。
NVIDIA AI 工作臺 通過提供用于管理數據、模型、資源和計算需求的單一平臺,幫助簡化此流程。這可讓開發者實現無縫協作和部署,從而快速創建經濟高效、可擴展的生成式 AI 模型。
NVIDIA 和 VMware 正在攜手合作,以轉變基于 VMware Cloud Foundation 構建的現代數據中心,并將 AI 引入每個企業。借助 NVIDIA AI Enterprise 套件和 NVIDIA 最先進的 GPU 和數據處理器 (DPU),VMware 客戶可以安全地運行現代加速工作負載和現有的企業應用程序,NVIDIA 認證系統。
關鍵資源
- 借助 NVIDIA TensorRT-LLM 優化大型語言模型的推理(現已公開發布)
- 借助 NVIDIA AI Workbench,無縫開發和部署可擴展的生成式 AI 模型
- 借助 VMware 和 NVIDIA 實現數據中心現代化
開始使用 LLM
要開始使用 LLM,需要權衡成本、工作量、訓練數據可用性和業務目標等因素。組織應權衡使用現有模型并根據特定領域的知識對其進行自定義與在大多數情況下從頭開始構建自定義模型之間的權衡。選擇符合特定用例和技術要求的工具和框架非常重要,包括下面列出的工具和框架。
我們的生成式 AI 知識庫聊天機器人 實驗*向您展示如何調整現有的 AI 基礎模型,以針對您的特定用例準確生成響應。此免費實驗室提供以下方面的實操體驗:使用提示學習自定義模型、將數據提取到向量數據庫,以及鏈接所有組件以創建聊天機器人。
NVIDIA AI Enterprise 是一款云原生 AI 和數據分析軟件套件,可在所有主流云和數據中心平臺上使用,可提供 50 多個框架,包括 NeMo 框架、預訓練模型以及針對加速 GPU 基礎架構優化的開發工具。您可以試用此端到端企業就緒型軟件套件,免費試用 90 天。
NeMo 是一個端到端的云原生企業框架,供開發者構建、自定義和部署具有數十億參數的生成式 AI 模型。它針對具有多 GPU 和多節點配置的模型的大規模推理進行了優化。該框架使企業能夠輕松、經濟高效地開發生成式 AI 模型。開始探索 NeMo 教程。
NVIDIA 培訓 通過提供全面的技術實戰研討會和課程,幫助企業組織培訓其員工掌握最新技術,并彌合技能差距。LLM 學習路徑 由 NVIDIA 主題專家開發,涵蓋與軟件工程和 IT 運營團隊相關的基礎到高級主題。NVIDIA 培訓顧問 可以幫助開發定制的培訓計劃,并提供團隊定價。
關鍵資源
總結
隨著企業競相跟上 AI 進步的步伐,確定采用 LLM 的最佳方法至關重要。基礎模型有助于快速啟動開發流程。使用關鍵工具和環境高效處理和存儲數據以及自定義模型可以顯著提高生產力并推進業務目標。
?