在過去的一年里,NVIDIA 宣布了在對話人工智能方面的幾項重大突破,用于構建和部署自動語音識別( ASR )、自然語言處理( NLP )和文本到語音( TTS )應用程序。
為了讓開發者在云 GPU 加速環境中快速入門, NVIDIA 深度學習培訓中心( DLI ) 提供了三個快速、免費、自定進度的課程。
你會學到什么?
這些教學性 DLI 課程讓開發者體驗如何使用現代工具快速創建對話式 AI 和 NLP GPU 加速應用程序。學習目標包括:
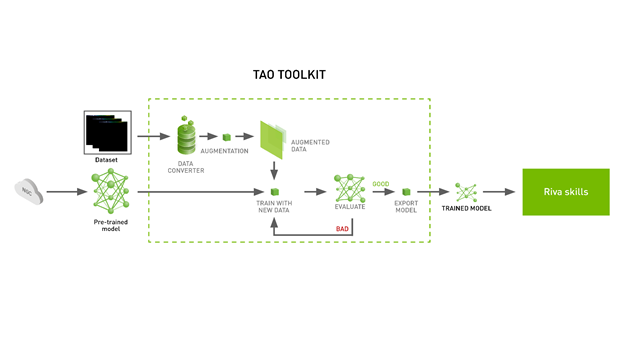
- 使用 TAO 工具箱訓練文本分類模型
- 在 SST-2 數據集上訓練并微調 BERT 文本分類模型。
- 對模型進行評估和推斷。
- 將模型導出為 ONNX 格式或 Riva 格式以進行部署。
- 使用 Riva 部署文本分類模型
- 使用 Riva ServiceMaker 獲取 TAO 導出的 Riva 模型,并將其轉換為最終部署。
- 在 Riva 服務器上本地部署模型。
- 使用 Riva API 綁定從演示客戶端發送推斷請求。
- Riva 語音 API 演示
- 將音頻發送到 ASR 型號并接收回文本。
- 使用 NLP 模型轉換文本、分類文本和分類標記。
- 向 TTS 型號發送文本并接收回音頻。
課程完成后,開發者將熟悉:
- 如何使用 NVIDIA TAO 工具包在 NVIDIA GPU 上訓練、推斷和導出文本分類模型。
- 如何在 NVIDIA GPU 上使用 NVIDIA Riva 部署文本分類模型。
- 如何從示例客戶端構造對 NVIDIA Riva 語音服務器的請求。
為什么文本分類有用?
文本分類回答了這個問題:這段文本屬于哪一類?例如,如果你想知道電影評論是正面的還是負面的,你可以使用兩個類別來建立一個情緒分析項目。
更進一步,使用幾個類別按主題對句子或文檔進行分類。在這兩個用例中,您都從預先訓練好的語言模型開始,然后使用示例分類文本“訓練”分類器來創建文本分類項目。
誠然,文本分類只是使用預先訓練的語言模型來理解書面語言的許多 NLP 任務之一。一旦開發人員嘗試使用 NVIDIA TAO 工具包和 NVIDIA Riva 來培訓和部署 文字分類?項目,他們將能夠將這種經驗擴展到其他 NLP 任務,例如 命名實體識別( NER ) 和 問答?。
NVIDIA Riva 語音 API 是如何工作的?
Riva 語音 API 服務器公開了一個用于執行語音識別、語音合成和各種 NLP 推斷的簡單 API 。在本課程中,開發人員使用 Python 示例從 Riva 示例客戶機中運行其中幾個 API 調用。服務器預填充了 ASR 、 NLP 和 TTS 模型。這些內置模型允許開發人員輕松快速地測試幾個對話 AI 組件。
開始學習 NLP 和對話人工智能
- 使用 TAO 工具箱訓練文本分類模型 ( 60 分鐘)
- 使用 Riva 部署文本分類模型 ( 30 分鐘)
- Riva 語音 API 演示 ( 30 分鐘)
?