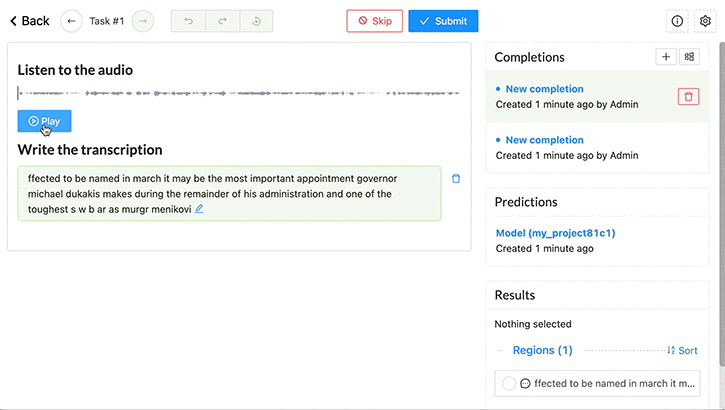
使用 NVIDIA NeMo 和 標簽工作室 中的自動語音識別( ASR )模型處理音頻數據時,可以節省時間并產生更準確的結果。
NVIDIA NeMo 提供了可重用的神經模塊,使得創建新的神經網絡架構變得容易,包括 ASR 的預構建模塊和現成模型。借助 NVIDIA NeMo 的強大功能,您可以從預訓練語音識別模型中獲得音頻轉錄。添加 labelstudio 及其開源數據標記功能,您可以進一步提高轉錄質量。
解決方案
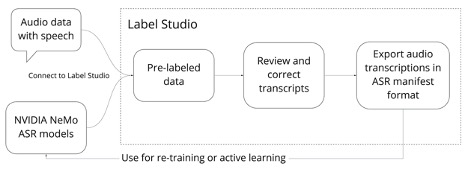
按照本文中的步驟使用 Label Studio 設置 NVIDIA NeMo ASR ,以生成高質量的音頻轉錄本。
- 連接 NVIDIA NeMo 模型,在 Label Studio 中自動轉錄音頻文件。
- 設置音頻轉錄項目。
- 從 Label Studio 驗證和導出修訂的音頻轉錄本。
- 微調 NeMo ASR 模型與修改后的音頻轉錄從標簽工作室。
先決條件
開始之前,請確保您擁有以下資源:
- 音頻數據文件。 此音頻 MIG 可以是客戶服務電話、電話訂單、銷售對話的錄音,也可以是其他與人交談的錄音。音頻文件必須采用以下文件格式之一:
- WAV
- AIFF
- MP3
- AU
- FLAC
- 已安裝 Label Studio 。 在本地計算機或云服務器上使用首選方法安裝 Label Studio 。有關更多信息,請參閱 Label Studio 文檔中的 Quickstart 。
- NeMo 工具箱已安裝
免費音頻數據
如果您沒有任何音頻數據,可以使用示例數據集或歷史音頻數據集:
- LJ 語音數據集 是非小說類書籍段落的公共域數據集。
- Librispeech 還提供了一個 基于開放 SLR 的開源 ASR 語料庫 。
您可以使用許多其他 ASR 數據集。有關詳細信息,請參閱 數據集 – 簡介 。您還可以使用國會圖書館網站上的公共域錄音集,如 美國棒球運動員訪談錄 。
確定要轉錄的音頻后,就可以開始處理它了。
安裝 Label Studio ML 后端
安裝 Label Studio 后,請安裝 Label Studio 機器學習后端。從命令行運行以下命令:
git clone https://github.com/heartexlabs/label-studio-ml-backend
設置環境:
cd label-studio-ml-backend # Install label-studio-ml and its dependencies pip install -U -e . # Install the nemo example dependencies pip install -r label_studio_ml/examples/requirements.txt
連接 NVIDIA NeMo 模型,在 Label Studio 中自動轉錄音頻文件
要使用預先訓練的 ASR 模型的預測對數據進行預標記,請在 Label Studio 中將 NeMo 工具箱設置為機器學習后端。 Label Studio 機器學習后端允許您使用預先訓練的模型來預標記數據。
Label Studio 包括使用 利用 NGC 云中的 NeMo 開發的預訓練 QuartzNet15x5 模型 的 一個例子 ,但是如果另一個模型更適合,您可以用您的數據設置一個不同的模型。有關更多信息,請參閱 NeMo 提供的 ASR 型號列表 。
在命令行中,將 NeMo 設置為機器學習后端,并使用該模型啟動一個新的 Label Studio 項目。
- 安裝 NeMo 工具箱 在 Docker 容器中或使用
pip。 - 下載 NeMo ASR 模型。提供的 Label Studio 示例腳本從 NGC 云下載預先訓練的 QuartzNet 模型。要使用不同的模型,請從 NGC 下載該模型。
- 從命令行啟動 Label Studio 機器學習后端。
label-studio-ml init my_model --from label_studio_ml/examples/nemo/asr.py - 啟動機器學習后端。默認情況下,模型在本地主機上以端口 9090 啟動。
label-studio-ml start my_model - 用模型啟動 Label Studio 。
label-studio start my_project --ml-backends http://localhost:9090
設置音頻轉錄項目
啟動 Label Studio 后,導入音頻數據并設置正確的模板來配置標簽。 VZX19 是自動語音識別的最佳選擇,它使音頻數據的注釋變得容易。
打開 Label Studio ,導入數據,然后選擇模板。
- 選擇 Import 并以純文本或 JSON 文件的形式導入音頻數據,這些文件引用在線存儲(如 Amazon S3 )中托管的音頻文件的有效 url 。有關詳細信息,請參閱 將數據導入 Label Studio 。
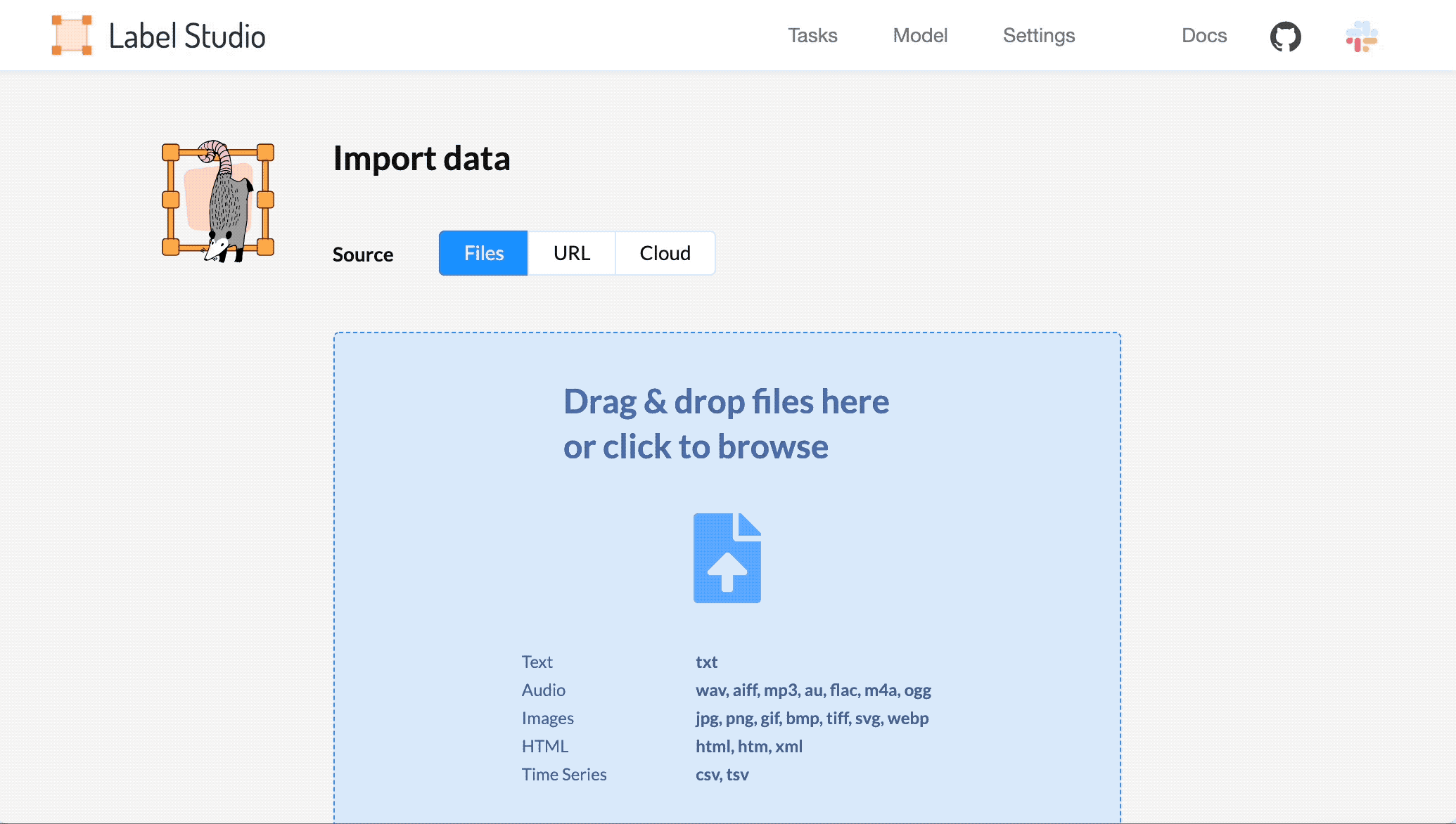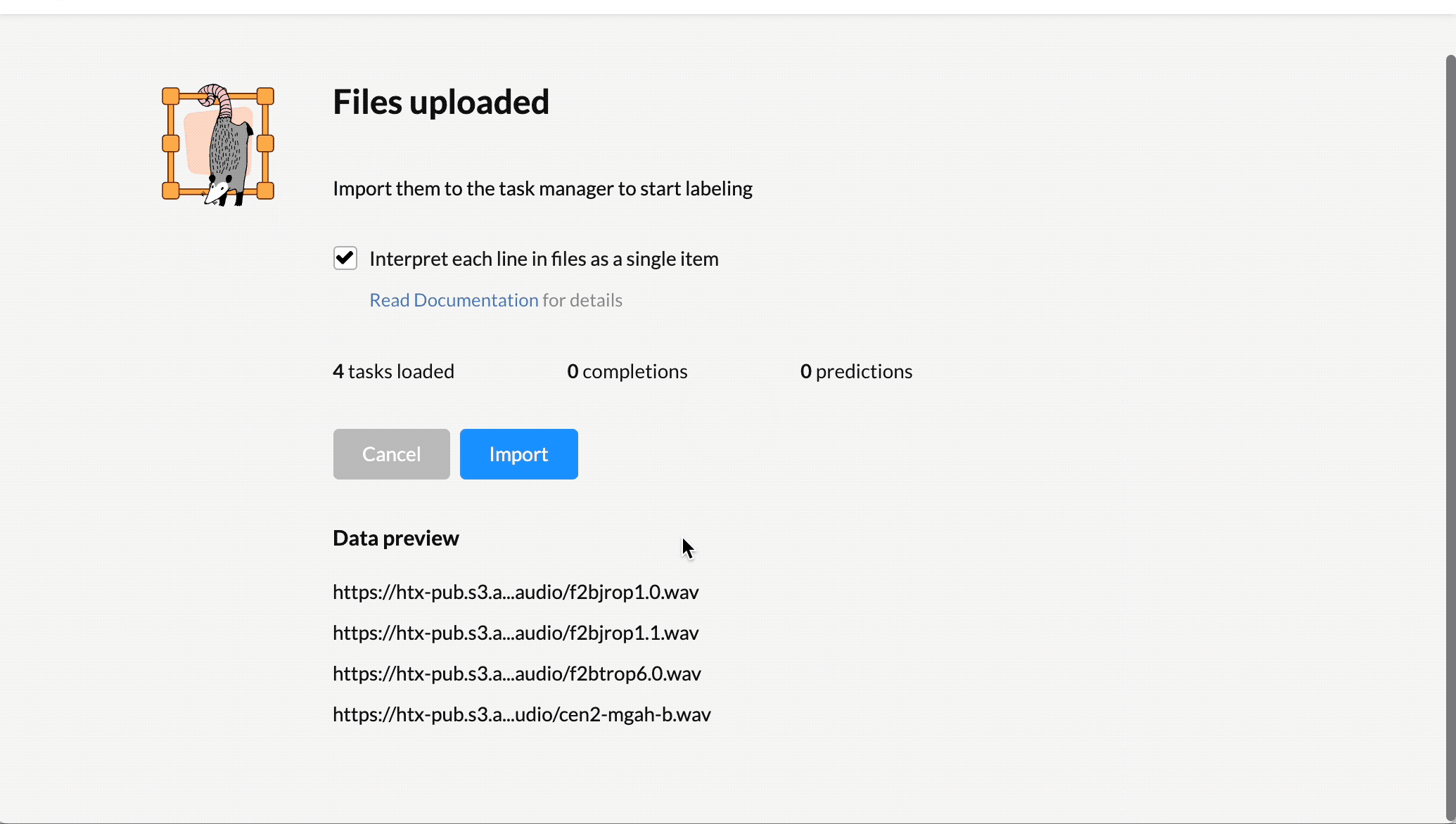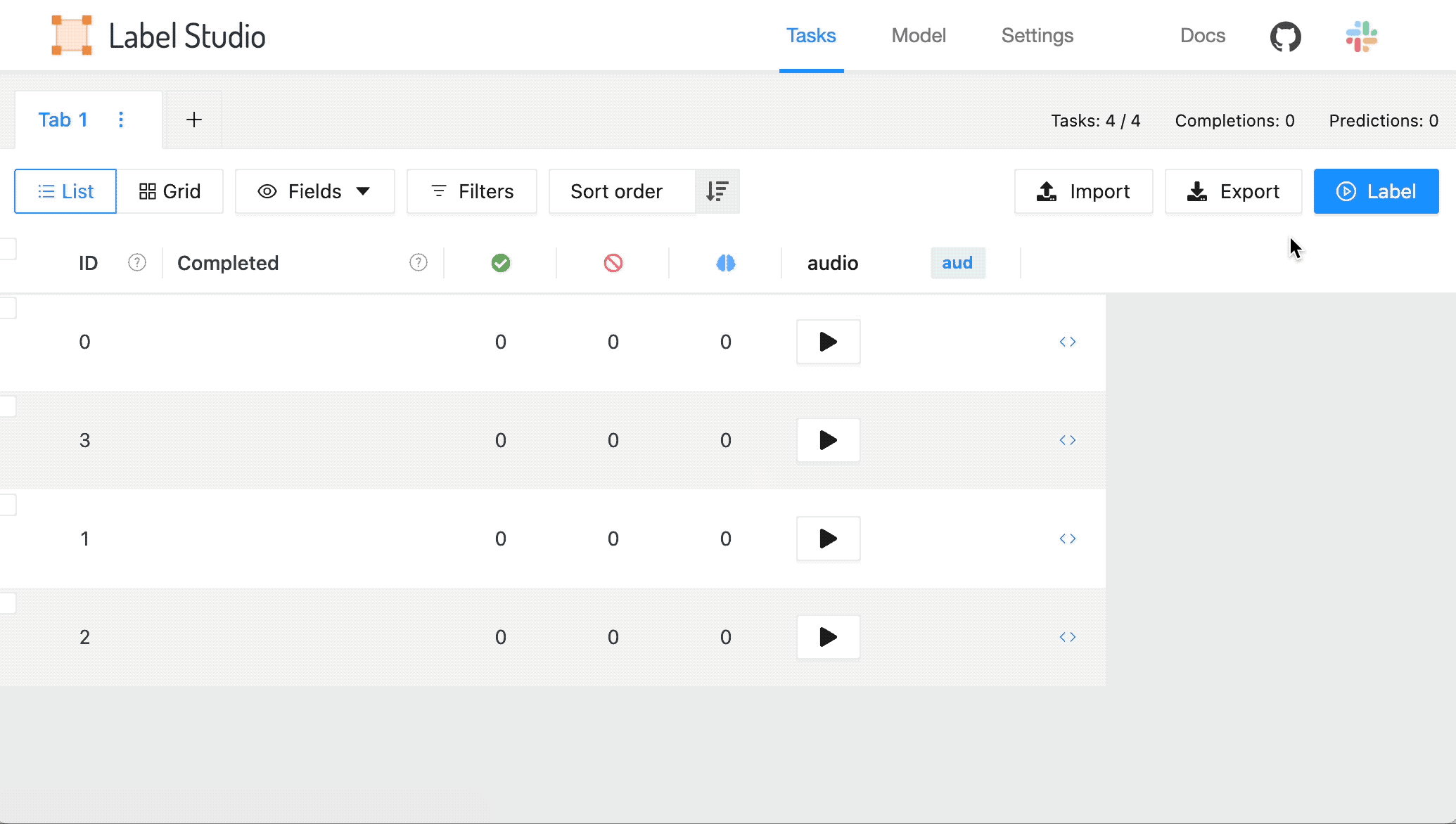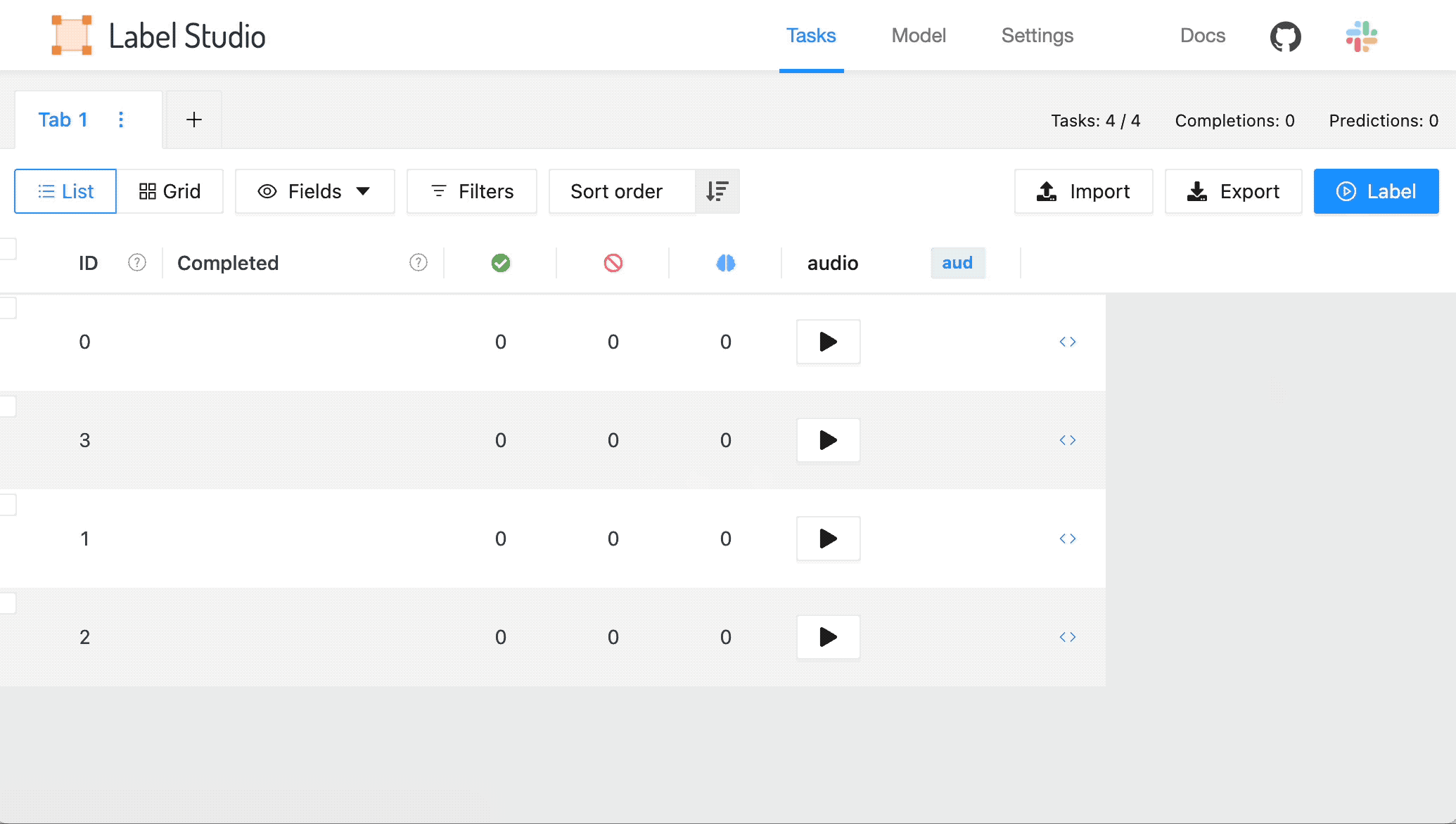
2 .從 Tasks 列表中,選擇 Settings 。
3 .在 標簽界面 選項卡上,瀏覽模板并選擇 自動語音識別 模板。
4 .選擇 Save 。
驗證并輸出模型預測
作為注釋器,檢查任務界面上音頻數據的任務并驗證。如有必要,糾正 NeMo 語音模型預測的轉錄本。
- 從 Label Studio 中的任務列表中,選擇 Label 。
- 對于每個音頻樣本,聆聽音頻并回顧 NeMo 模型產生的轉錄,作為預標記過程的一部分。
- 如果成績單中有任何單詞不正確,請更新。
- 保存對成績單的更改。選擇 Submit 提交成績單并查看下一個音頻樣本。
接下來,按照 NVIDIA NVIDIA 文檔中的 NeMo ASR 集合 所述,以 NeMo 模型所期望的正確格式從 Label Studio 導出完成的音頻轉錄本。
要導出完成的音頻,請執行以下操作:
- 從 Label Studio 中的任務列表中,選擇 Export 。
- 選擇名為 ASR_MANIFEST 的音頻轉錄 JSON 格式。
有關 Label Studio 中可用導出格式的詳細信息,請參閱 從 Label Studio 導出結果 。
使用高質量的成績單來微調您的 ML 模型
當您處理完音頻并調整完轉錄的文本后,剩下的是音頻轉錄本,您可以用來重新培訓 NeMo 中包含的 ASR 模型。 Label Studio 生成與 NeMo 培訓完全兼容的注釋。
要更新 QuartzNet 模型檢查點,您可以在幾行代碼中完成,從頭開始訓練模型,或者使用 PyTorch Lightning 。例子也可以在 NeMo Jupyter 筆記本中找到。有關詳細信息,請參閱 用 NeMo Jupyter 筆記本在 ASR 中進行遷移學習 。
通過同時使用 Label Studio 和 NeMo ,您可以節省從頭開始處理每個音頻文件的時間 NeMo 可以立即為您提供高度準確的預測,而 Label Studio 可以幫助您實現完美的預測 今天就試試 !
?