如今,人工智能驅動的應用程序正在實現更豐富的體驗,這是由更大和更復雜的人工智能模型以及許多模型在管道中的應用所推動的。為了滿足注入人工智能的應用程序日益增長的需求,人工智能平臺不僅必須提供高性能,而且必須具有足夠的通用性,以便在各種人工智能模型中提供這種性能。為了最大限度地提高基礎設施利用率并優化 CapEx ,在同一基礎設施上運行整個 AI 工作流的能力至關重要:從數據準備和模型培訓到部署推理。
MLPerf 基準 已成為行業標準、同行評議的深度學習績效衡量標準,涵蓋人工智能培訓、人工智能推理和 高性能計算 ( HPC )。 MLPerf 推斷 2.1 是 MLPerf 推理基準套件的最新迭代,涵蓋了廣泛的常見 AI 用例,包括推薦、自然語言處理、語音識別、醫學成像、圖像分類和對象檢測。
在這一輪中, NVIDIA 在最新 NVIDIA H100 Tensor Core GPU 的基礎上首次提交了 MLPerf ,這是基于 NVIDIA Hopper 架構 的突破。
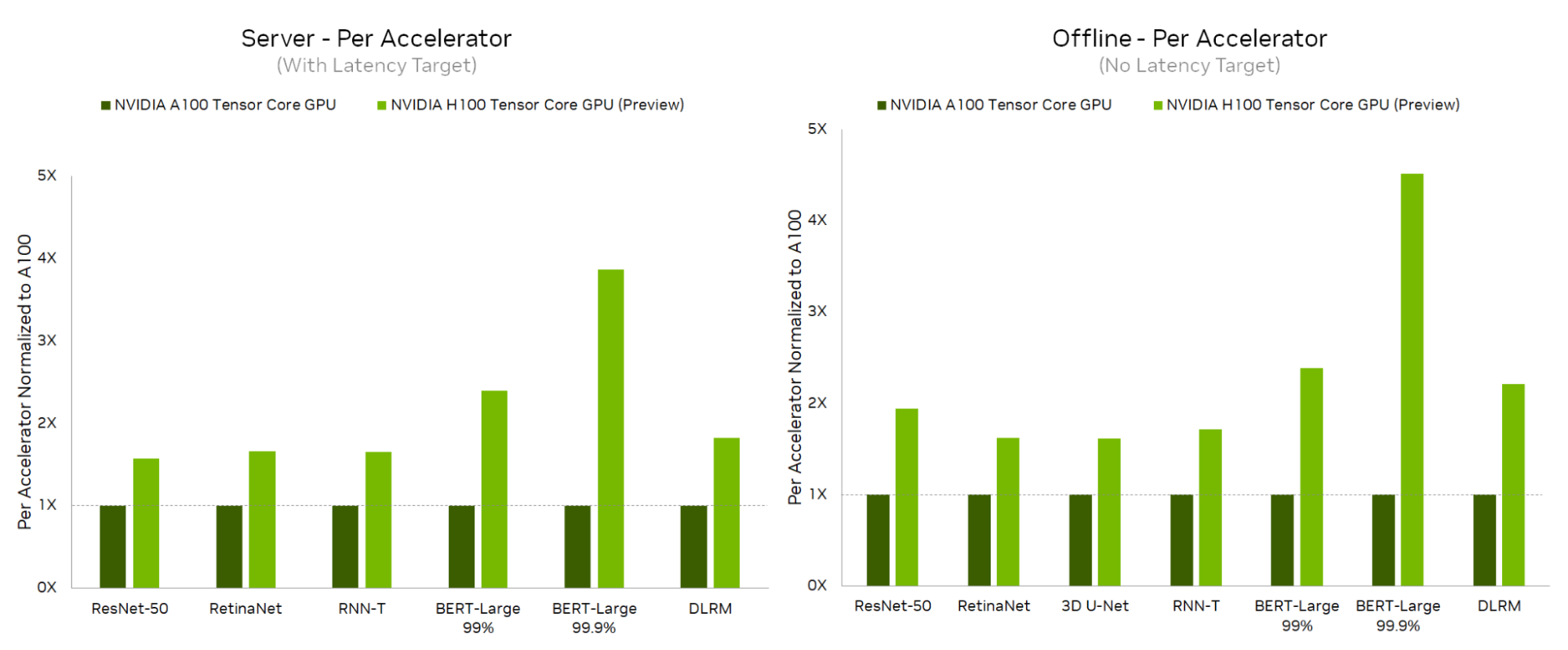
- H100 在所有數據中心測試中都創造了新的加速器記錄,與 NVIDIA A100 Tensor Core GPU 相比,其推理性能提高了 4.5 倍。
- A100 在數據中心和邊緣推斷場景的全套 MLPerf 推斷 2.1 測試中繼續表現出優異的性能。
NVIDIA Jetson AGX Orin 是為邊緣 AI 和機器人應用而構建的,在上一輪 MLPerf 推斷中首次亮相后,每瓦特性能也提高了 50% ,并運行了所有邊緣工作負載和場景。
實現這些性能結果需要深入的軟件和硬件協同優化。在本文中,我們將討論結果,然后深入探討一些關鍵的軟件優化。
NVIDIA H100 Tensor 核心技術
在每個流式多處理器( SM )的基礎上, H100 張量核在使用 相同的數據類型 時為 A100 SM 的時鐘提供兩倍的矩陣乘法累加( MMA )吞吐量時鐘,在比較 A100 SM 上的 FP16 和 H100 SM 上 FP8 時提供四倍的吞吐量時鐘。為了利用 H100 的幾個新功能,并利用這些速度極快的 Tensor Core ,必須開發新的內核。
H100 Tensor Cores 處理數據的速度如此之快,以至于很難同時向其提供足夠的輸入數據和對其輸出數據進行后期處理。內核必須創建一個高效的管道,以便數據加載、 Tensor Core 處理、后處理和存儲都能同時高效地進行。
新的 H100 異步事務壁壘有助于提高這些管道的效率。異步屏障允許生產者線程在發出數據可用性信號后繼續運行。在數據加載線程的情況下,這大大提高了內核隱藏內存系統延遲的能力,并確保 Tensor Core 可以使用穩定的輸入數據流。異步事務屏障還為使用者線程提供了一種有效的機制來等待資源可用性,以便它們不會在自旋循環中浪費 SM 資源。
張量記憶加速器( TMA )進一步增壓這些內核。 TMA 旨在以本機方式集成到異步管道中,并提供多維張量從全局內存到 SM 共享內存的異步傳輸。
Tensor Core 速度如此之快,以至于地址計算等操作可能成為性能瓶頸; TMA 卸載了這項工作,以便內核能夠盡快集中精力運行數學和后處理。
最后,新內核使用 H100 線程塊集群來利用 GPU 處理集群( GPC )的位置。每個線程塊集群中的線程塊協作以更高效地加載數據,并為 Tensor Cores 提供更高的輸入帶寬。
NVIDIA H100 Tensor Core GPU 性能結果
從數據中心類別開始, NVIDIA H100 Tensor Core GPU 在服務器和脫機場景中的每個工作負載上都提供了最高的每加速器性能,與 A100 Tensor-Core GPU 相比,在脫機場景中性能提高了 4.5 倍,在服務器場景中性能提升了 3.9 倍。
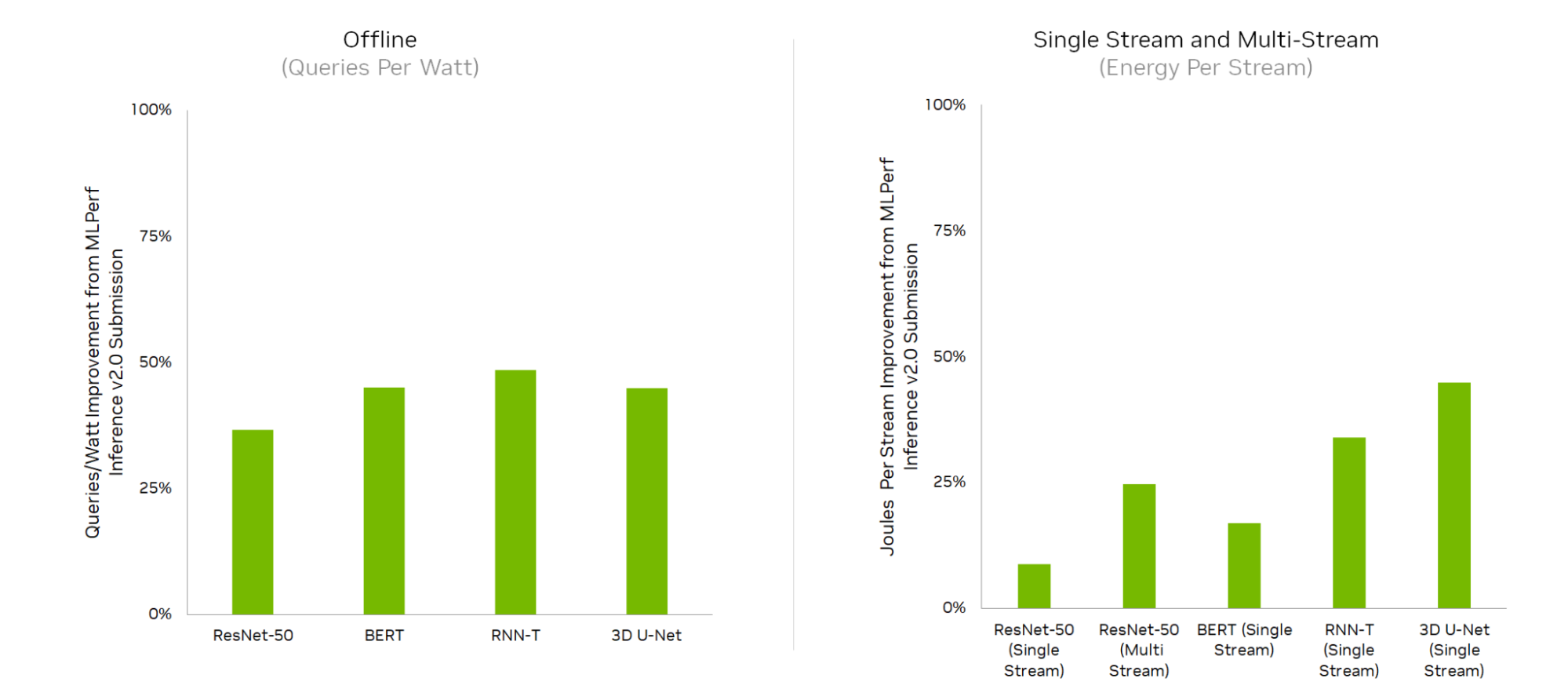
由于全棧改進,與上一輪相比, NVIDIA Jetson AGX Orin 實現了能源效率的大幅提高,效率提高了 50% 。
下面更詳細地看一下使這些結果成為可能的軟件優化。
使用 FP8 的高性能 BERT 推理
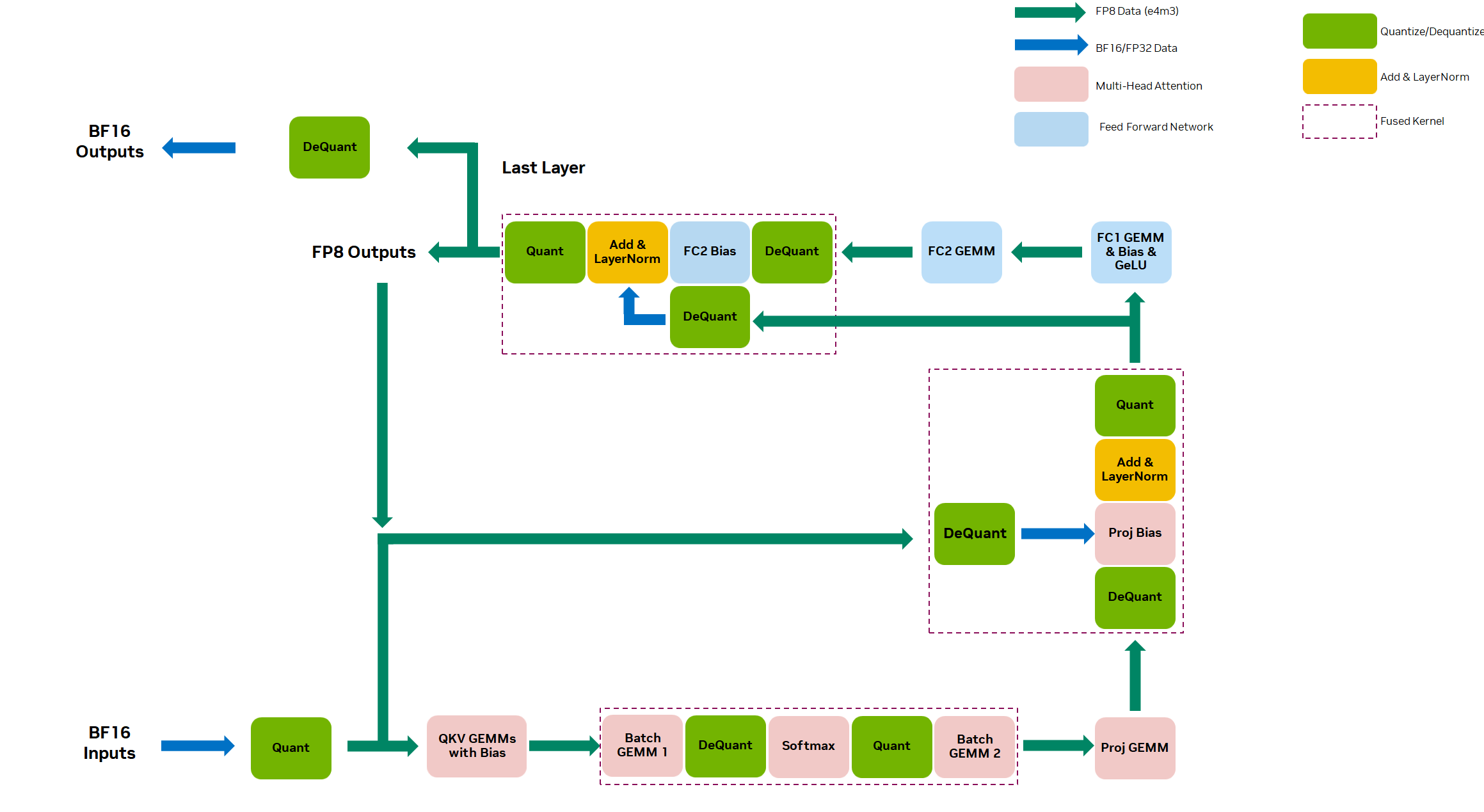
NVIDIA Hopper 架構 集成了新的第四代 Tensor Core ,支持兩種新的 FP8 數據類型: E4M3 和 E5M2 。與 16 位浮點型相比,這些新的數據類型將 Tensor Core 吞吐量增加了 2 倍,并將內存需求減少了 2 倍。
E4M3 提供了一個額外的尾數位,這使得計算流程中的第一部份,前向傳播的穩定性增加。 E5M2 的額外指數位更有助于防止反向傳播期間的溢出/下溢。對于我們的 BERT FP8 提交,我們使用了 E4M3 。
我們對 BERT 等 NLP 模型的實驗表明,當將模型從較高精度( FP32 )量化為較低精度(如 FP8 或 INT8 )時,用 FP8 觀察到的精度下降低于 INT8 。
盡管我們可以使用 Quantization Aware Training( QAT )來恢復 INT8 的一些模型精度,但 Post Training Quantization( PTQ )下 INT8 的精度仍然是一個挑戰。這就是 FP8 的優勢所在:它可以在 PTQ 下提供 FP32 模型 99.9% 的精度,而無需運行 QAT 所需的額外成本和努力。因此, FP8 可用于先前需要 FP16 的 MLPerf 99.9% 高精度類別。從本質上講, FP8 為這個工作負載提供了 INT8 的性能和 FP16 的精度。
在 NVIDIA BERT 提交編碼器中的所有全連接和矩陣層都使用 FP8 精度。這些層使用 cuBLASLt 在 H100 Tensor Core上執行 FP8 GEMM 。
擴展了關鍵 BERT 優化以支持 FP8 ,包括以下內容:
- Removing padding: BERT 的輸入具有可變序列長度,并填充到最大序列長度。我們去除填充以避免在填充上浪費計算,并在最終輸出時重新構造填充,以便與輸入形狀相同。
- Fused multi-head attention :這是四種操作的融合:轉置 Q / K 、 Q * K 、 softmax 和 QK * V 來計算注意力。融合這些計算可提高內存效率,跳過填充以防止無用計算。融合式多頭注意力提供大約 2 倍的端到端加速。
- Activation fusion: 我們將矩陣與更多計算操作進行合并 ,包括 bias 和激活函數( GeLU )。這種融合還通過刪除額外的內存傳輸來幫助提高內存效率。
用于對象檢測的 RetinaNet
在 MLPerf 推斷 2.1 中,添加了一個名為 RetinaNet 的新的單階段對象檢測模型。這取代了 MLPerf Inference 2.0 的 ssd-resnet34 和 ssd-mobilenet 工作負載。這一更新的模型體系結構及其新的推理數據集為提供快速、準確和高效的推理帶來了新的挑戰。
NVIDIA 提交了所有平臺的 RetinaNet 結果,證明了我們軟件支持的廣度。
RetinaNet 是使用 Open Images 數據集 進行訓練和推斷的,與之前使用的 COCO 數據集相比,它包含的對象類別和對象符號數量級更多。對于 RetinaNet ,為訓練和推理任務選擇了 264 個獨特的類。這比 ssd-resnet34 使用的 81 個類要多得多。

盡管 RetinaNet 也是一種單次目標檢測模型,但與 ssd-resnet34 相比,它有幾個關鍵區別:
- RetinaNet 使用 Feature Pyramid Network ( FPN )作為前饋 ResNeXt 架構之上的主干。 ResNeXt 在其計算塊中使用群卷積,并且與 ResNet34 具有不同的數學特性。
- 對于每個圖像, 120087 個框和 264 個唯一類分數被輸入到非最大抑制( NMS )層,并選擇前 1000 個分數框作為輸出。在 ssd-resnet34 中,這些數字減少了 25 倍: 15130 個盒子,每個盒子 81 個等級, 200 個 topK 。
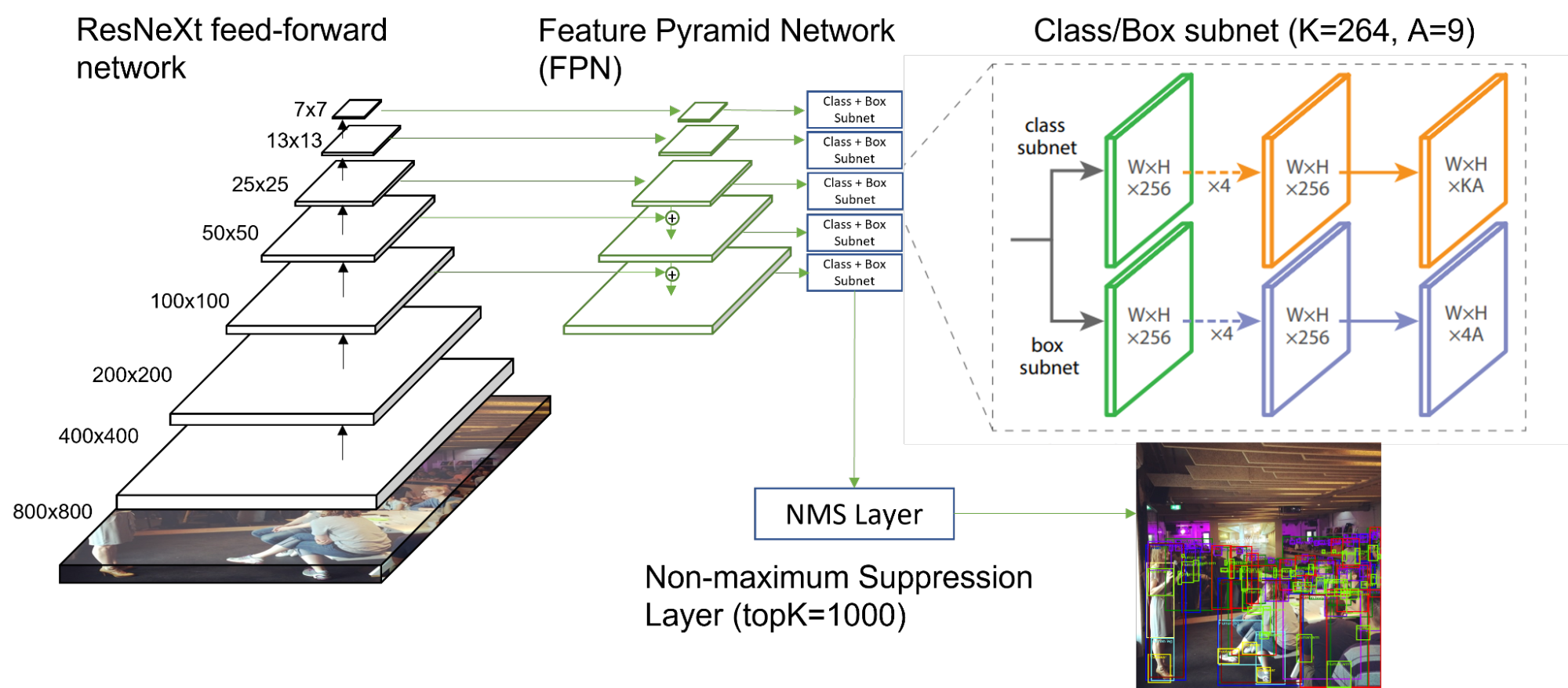
NVIDIA 使用 TensorRT 作為 RetinaNet 的后端。 TensorRT 通過自動優化圖形執行和層執行,顯著加快了推理吞吐量:
- TensorRT 完全支持以 FP32 / INT8 混合精度執行模型推斷,與 FP16 和 FP32 精度相比,精度損失最小。
- TensorRT 自動為所有 16 個 ResNeXt 塊的組卷積選擇優化的內核。
- TensorRT 為卷積層、激活層和(可選)池層提供融合模式,通過合并層權重和減少操作次數,優化內存移動以加快推理。
- 對于后處理 NMS 層, NVIDIA 利用了 EfficientNMS ,這是一個開源的高性能 CUDA 內核,專門用于 NMS 任務,作為 TensorRT 插件提供。
NVIDIA Jetson AGX Orin 優化
NVIDIA Jetson AGX Orin 是最新的 NVIDIA 邊緣人工智能和機器人應用平臺。在這一輪 MLPerf 推斷中, Jetson AGX Orin 在 MLPerf Inference 2.1 邊緣工作負載的范圍內展示了卓越的性能和能效改進。改進包括 ResNet-50 多流延遲減少 45% ,與上一輪( 2.0 版)相比, BERT 離線吞吐量提高 17% 。在提交的電源中, Orin 在選定基準上實現了高達 52% 的功率降低和 48% 的每瓦性能改進。提交的文件使用了 22.08 Jetson CUDA-X AI Developer Preview 軟件,其中包括優化的 NVIDIA Jetson Linux ( L4T )映像、 TensorRT 8.5.0 、 CUDA 11.4.14 和 cuDNN 8.5.0 ,使客戶能夠輕松地從這些改進中受益。 RetinaNet 通過此軟件堆棧在 Jetson AGX Orin 上得到完全支持并具有性能。這證明了 NVIDIA 平臺和軟件支持開箱即用的高性能 DL 推理的能力。
NVIDIA Orin 性能改進
MLPerf Inference v2.1 的顯著改進來自于系統映像和 22.08 Jetson CUDA-X AI 開發者預覽中 TensorRT 8.5 的總體性能提升。優化后的 Jetson L4T 映像為用戶提供了 MaxN 電源模式,從而提高了 GPU 和 DLA 單元的頻率。同時,此圖像可以選擇使用 64K 的放大頁面大小,這樣可以在運行某些推斷工作負載時減少 TLB 緩存未命中。此外,映像中本機包含的 3.10.1 DLA 編譯器包含一系列優化功能,可將 Orin DLA 上運行的工作負載性能提高 53% 。
TensorRT 8.5 包括兩種新的優化,可提高推理性能。第一個是對 cuDLA 的本機支持,它消除了在 DLA 節點和 GPU 節點之間插入復制節點的強制要求。我們觀察到,從 NVMedia 到 cuDLA , DLA 引擎端到端的改進約為 1.8% 。第二個是為小通道*濾波器大小的卷積添加優化核,與 beta = 1 剩余連接融合。這將 Orin 中 GPU 的 BERT 性能提高了 17% , ResNet50 性能提高了 5% 。
NVIDIA Orin 能效改進
NVIDIA Orin 電源提交文件得益于上述所有性能改進,并重點關注進一步降低功率。使用 Orin 更新的 L4T 映像,可以通過微調每個基準的 CPU 、 GPU 和 DLA 頻率來降低功耗,以實現每瓦特的最佳性能。此圖像還支持新的平臺節能功能,如調節器自動斷相和低負載條件下的低功率狀態。 Orin 中 USB-C 支持的靈活性被用于通過 USB 通信上的以太網整合所有 I / O 。通過禁用以太網、 WiFi 和 DP 等非推理必需的 I / O 子系統,以及使用現成的更高效 GaN 電源適配器,進一步降低了系統功耗。
這些平臺和軟件優化將系統功耗降低了 52% ,每瓦特性能比我們之前在 2.0 中提交的文件提高了 48% 。
3D U-Net 性能改進
在 MLPerf Inference v2.0 中, 3D U-Net 醫學成像工作負載切換到 KITS19 數據集,這將圖像大小增加了 8 倍,并且由于滑動窗口推斷,將給定樣本所需的計算處理量增加了 18 倍。有關 NVIDIA MLPerf Inference v2.0 提交的更多信息,請參閱 Getting the Best Performance on MLPerf Inference 2.0 。
對于 MLPerf Inference 2.1 ,我們使用 TensorRT IPluginV2DDynamicExt 插件進一步改進了第一個卷積層的性能。
KiTS19 圖像是單通道張量,這對 3D U-Net 中第一個 3D 卷積的性能提出了挑戰。在 3D 卷積中,此通道尺寸通常會影響 GEMM 的 K 尺寸。這一點特別重要,因為 3D U-Net 的總體性能主要由前兩個和后兩個 3D 卷積決定。在 MLPerf Inference v2.0 中,這四個卷積約占整個網絡運行時間的 38% ;第一層占 8% 。一個非常重要的因素解釋了這一點,即需要使用零填充來適應 NC / 32DHW32 矢量化格式布局,其中張量核心可以得到最有效的利用。
在我們更新的插件中,我們使用 INT8 Linear 格式對這個單通道有限的 3D 形狀輸入進行高效計算。這樣做有兩個好處:
- 更有效地使用觸發器 :不執行不必要的計算
- PCIe 傳輸 B / W 節省 :避免在主機和 GPU 內存之間移動零填充輸入張量或在將輸入張量發送到 TensorRT 之前在 GPU 上進行零填充的開銷
此優化將第一層性能提高了 2.7 倍。此外,切片內核不再需要處理零填充,因此其性能也提高了 2 倍。最終, 3D UNet 在 MLPerf Inference 2.1 中的端到端性能提高了 5% 。
打破跨工作負載的性能記錄
在 MLPerf Inference 2.1 中,首次提交的 NVIDIA H100 為數據中心場景中的所有工作負載創造了新的每加速器性能記錄,性能比 A100 高出 4.5 倍。由于 NVIDIA Hopper 體系結構的許多突破以及利用這些功能的巨大軟件優化,這一代性能提升是可能的。
NVIDIA Jetson AGX Orin 僅在一輪中就實現了高達 50% 的能效提升,并繼續為邊緣人工智能和機器人應用提供整體推理性能領先。
最新一輪 MLPerf 推斷展示了 NVIDIA AI 平臺在全方位 AI 工作負載和場景中的領先性能和多功能性。憑借 H100 Tensor Core GPU ,我們正在為 NVIDIA AI 平臺提供最先進的型號,并為用戶提供更高級別的性能和能力,以滿足最苛刻的工作負載。
有關詳細信息,請參閱 NVIDIA Hopper Architecture In-Depth 。
?