樸素貝葉斯( NB )是一種簡單但功能強大的概率分類技術,具有良好的并行性,可以擴展到大規模數據集。
如果您一直從事數據科學中的文本處理任務,您就會知道 機器學習 模型可能需要很長時間來訓練。在這些模型上使用 GPU 加速計算通常可以顯著提高時間性能, NB 分類器也不例外。
通過使用 CUDA 加速操作,根據使用的 NB 模型,我們實現了從 5 到 20 倍的性能提升。對稀疏數據的智能利用使其中一個模型的速度提高了 120 倍。
在本文中,我們介紹了 RAPIDS cuML 中 NB 實現的最新升級,并將其與 Scikit-learn 在 CPU 上的實現進行了比較。我們提供基準測試來演示性能優勢,并通過算法的每個支持變量的簡單示例來幫助您確定哪個最適合您的用例。
什么是樸素貝葉斯?
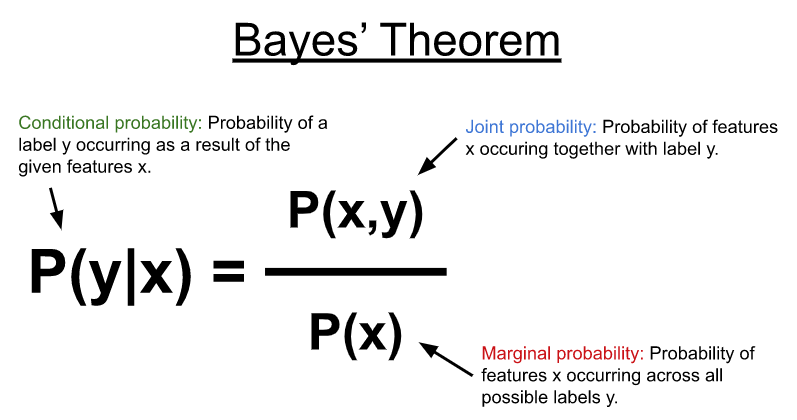
NB 使用 Bayes’ theorem (圖 1 )對如下所示的條件概率分布進行建模,以預測給定一些輸入特征( x )的標簽或類別( y )。在其最簡單的形式中,貝葉斯定理使用特征和可能標簽之間的聯合概率以及特征在所有可能標簽上出現的邊際概率來計算條件概率。
NB 算法在文本分類用例中表現良好。它們通常用于過濾垃圾郵件等任務;預測推特、網頁、博客帖子、用戶評分和論壇帖子的類別和情感;或對文檔和網頁進行排名。
NB 算法通過使每個特征(例如,輸入向量 x 中的每列)在統計上獨立于所有其他特征來簡化條件概率分布 naive assumption 。這使得該算法很棒,因為這種天真的假設提高了算法的并行化能力。此外,計算特征和類標簽之間簡單共生概率的一般方法使模型能夠進行增量訓練,支持不適合內存的數據集。
NB 有幾種變體,它們對各種類別標簽的聯合分布或共同出現的特征進行了某些假設。
樸素貝葉斯假設
為了預測未知輸入特征集的類別,關于聯合分布的不同假設使算法具有幾種不同的變體,該算法通過學習不同概率分布的參數來建模特征分布。
表 1 模擬了一個簡單的文檔/術語矩陣,該矩陣可以來自文本文檔集合。列中的術語代表一個詞匯表。一個簡單的詞匯表可能會將一個文檔分解為一組在所有文檔中出現的唯一單詞。
| I | love | dogs | hate | and | knitting | is | my | hobby | session | |
| Doc 1 | 1 | 1 | 1 | |||||||
| Doc 2 | 1 | 1 | 1 | 1 | 1 | |||||
| Doc 3 | 1 | 1 | 1 | 2 | 1 | 1 |
表 1 . 包含沿行文檔和沿列出現在每個文檔中的詞匯的文檔/術語矩陣
在表 1 中,每個元素可以是一個計數,如此處所示, 0 或 1 表示特征的存在,或其他一些值,如在整個文檔集上出現的每個項的比率、擴散或離散度。
在實踐中,滑動窗口通常在整個文檔或術語上運行,將它們進一步劃分為小塊的單詞序列,稱為 n-grams 。對于下圖的第一個文檔, 2-gram (或 bigram )將是“ I love ”和“ love dogs ”。這類數據集中的詞匯通常會顯著增大并變得稀疏。預處理步驟通常在詞匯表上執行,以過濾噪聲,例如,通過刪除大多數文檔中出現的常見術語。
將文檔轉換為文檔項矩陣的過程稱為矢量化。有一些工具可以加速這個過程,例如 CountVectorizer cuML 中的 CountVectorizer 、 TdfidfVectorizer 或 RAPIDS 估計器對象。
多項式和伯努利分布
表 1 表示一組文檔,這些文檔已矢量化為術語計數,結果矩陣中的每個元素表示特定單詞在其相應文檔中出現的次數。這種簡單的表示方法可以有效地用于分類任務。
由于特征代表頻率分布,多項式樸素貝葉斯變體可以有效地將特征及其相關類別的聯合分布建模為多項式分布。
可以通過合并色散度量來增強每個項的頻率分布,例如項頻率逆文檔頻率( TF-IDF ),它考慮了每個項中出現的文檔數量。這可以通過對出現在較少文檔中的術語賦予更多權重來顯著提高性能,從而提高其識別能力。
雖然多項式分布在直接與項頻率一起使用時效果很好,但它也被證明在分數值上有很好的性能,如 TF-IDF 值。多項式樸素貝葉斯變體涵蓋了大量用例,因此往往是使用最廣泛的。類似的變體是伯努利樸素貝葉斯,它模擬每個項的簡單出現,而不是它們的頻率,從而得到 0 和 1 的矩陣(伯努利分布)。
不等階級分布
在現實世界中,經常會發現不平衡的數據集。例如,您可能有有限的垃圾郵件和惡意活動的數據樣本,但有豐富的正常和良性樣本。
補碼樸素貝葉斯變體通過在訓練期間為每個類使用聯合分布的補碼,例如,在所有其他類的樣本中出現特征的次數,有助于減少不平等類分布的影響。
分類分布
你也可以為你的每一個特征創建存儲箱,可能通過將一些頻率量化到多個存儲桶中,使得 0-5 的頻率進入存儲桶 0 , 6-10 的頻率進入存儲桶 1 ,等等。
另一種選擇是將幾個術語合并到一個功能中,可能是為“動物”和“假日”創建桶,其中“動物”可能有三個桶,零個用于貓科動物,一個用于犬科動物,兩個用于嚙齒動物。“假日”可能有兩個桶,零用于個人假日,如生日或結婚紀念日,一個用于聯邦假日。
分類樸素貝葉斯 變體假設特征遵循分類分布。樸素假設在這種情況下效果很好,因為它允許每個特征都有一組不同的類別,并且它使用(您猜對了)分類分布對聯合分布進行建模。
連續分布
最后,當特征是連續的時,高斯樸素貝葉斯 變體非常有效,可以假設每個類別中的特征分布可以用高斯分布建模,即用簡單的均值和方差。
雖然這種變體在 TF-IDF 歸一化后可能在某些數據集上表現出良好的性能,但它在一般機器學習數據集上也很有用。
| Algorithm | Multinomial | Bernoulli | Complement | Categorical | Gaussian |
| Type of input | Frequencies, Counts | Boolean occurrence | Counts | Categorical | Continuous |
| Advantage | Support count data | Support binary data | Reduce impact of imbalance data | Support categorical data | Support general continuous data |
表 2.不同 NB 算法的比較 s
真實世界的端到端示例
如表 2 所示,為了證明每種算法變體的優點,我們逐步瀏覽了每種算法變體的示例筆記本。有關包含所有示例的全面端到端筆記本,請參閱 news_aggregator_a100.ipynb 。
我們使用新聞聚合器數據集來演示 NB 變體的性能。該數據集可從 Kaggle 公開獲取,由來自多個新聞來源的 422K 條新聞標題組成。每個標題都標有四個可能的標簽之一:商業、科技、娛樂和健康。使用 cuDF RAPIDS 將數據直接加載到 GPU 上,并繼續執行針對每個 NB 變體的預處理步驟。
高斯樸素貝葉斯
從高斯樸素貝葉斯 , 開始,我們運行 TD-IDF 矢量器將文本數據轉換為可用于訓練的實值向量。
通過指定ngram_range=(1,3),我們表示我們將學習單字以及 2-3-gram 。這顯著增加了要學習的術語或功能的數量,從 15K 個單詞增加到 180 萬個組合。由于大多數術語不會出現在大多數標題中,因此生成的矩陣稀疏,許多值等于零。 cuML 支持特殊結構來表示這樣的數據。
 by
by NB 分類器的另一個優點是,可以使用partial_fit方法對Estimator對象進行增量訓練。這種技術適用于可能無法一次性放入內存或必須分布在多個 GPU 中的大規模數據集。
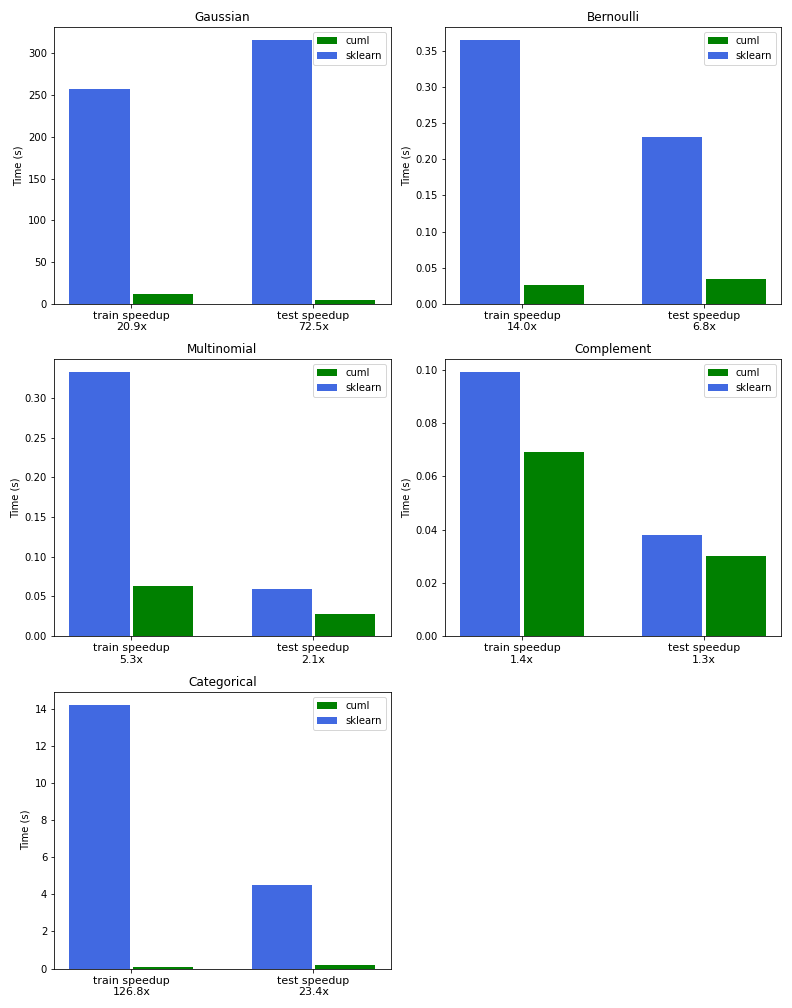
我們的第一個示例演示了使用高斯樸素貝葉斯的增量訓練,方法是在使用 TF-IDF 預處理為連續特征后,將數據分割成多個塊。高斯樸素貝葉斯的 cuML 版本在訓練方面比 Scikit 學習快 21 倍,在推理方面快 72 倍。
伯努利樸素貝葉斯
下一個示例演示了伯努利樸素貝葉斯,無需增量訓練,使用表示每個項存在或不存在的二進制特征。CountVectorizer對象可以通過設置binary=True來實現這一點。在本例中,我們發現比 Scikit learn 快 14 倍。
多項式樸素貝葉斯
多項式樸素貝葉斯是最通用和最廣泛使用的變體,如以下示例所示。我們使用 TF-IDF 矢量器而不是CountVectorizer來實現比 Scikit learn 快 5 倍的速度。
補碼樸素貝葉斯
我們使用CountVectorizer證明了補碼樸素貝葉斯的威力,并表明在我們的不平衡數據集上,它比伯努利和多項式 NB 變體產生了更好的分類分數。
范疇樸素貝葉斯
最后但絕對不是最不重要的是一個分類樸素貝葉斯的例子,我們使用 k-means 和之前在另一個 NB 變體上訓練的模型對其進行矢量化,以根據相似項對結果類的貢獻將其分組到相同的類別中。
我們發現,與 Scikit 相比,使用 315K 條新聞標題訓練模型的速度提高了 126 倍,使用 23 倍的速度進行推理和計算模型的準確性。
基準
圖 2 中的圖表比較了 RAPIDS cuML 和 Scikit learn 之間的 NB 訓練和推理的性能,以及本文中概述的所有變體。
基準測試是在a2-highgpu-8g谷歌云平臺( GCP )實例上執行的,該實例配備了 NVIDIA Tesla A100 GPU 和 96 Intel Cascade Lake v CPU ,頻率為 2.2Ghz 。
GPU 加速樸素貝葉斯
我們能夠使用 CuPy 在 Python 中實現所有 NB 變體,這是一種 GPU 加速,幾乎可以替代 NumPy 和 SciPy 。 CuPy 還提供了用 Python 編寫自定義 CUDA 內核的功能。當 Python 應用程序運行時,它使用 NVRTC 的即時( JIT )編譯功能在 GPU 上編譯和執行它們。
所有 NB 變體的核心是兩個使用 CuPy 的 JIT 編寫的簡單原語,用于匯總和計算每個類的特征。
當單個文檔項矩陣過大而無法在單個 GPU 上處理時, Dask 庫可以利用增量訓練功能將處理擴展到多個 GPU 和多個節點。目前,多項式變量可以在 cuML 中與 Dask 一起分布。
結論
NB 算法應該在每個數據科學家的工具包中。使用 RAPIDS cuML ,您可以在 GPU 上加速 NB 的實現,而無需大幅更改代碼。這些強大而基本的算法,再加上 cuML 的加速,提供了您必須在超大或稀疏數據集上執行分類的一切。
如果你認為 RAPIDS cuML 可以幫助加速你的數據科學和機器學習工作流程,或者已經在這樣做了,那么請留下評論,因為我們很樂意聽到。
一如既往,請訪問 rapidsai GitHub repo ,讓我們知道我們可以如何幫助您。你也可以在推特上 @rapidsai 關注我們。
如果您是 RAPIDS 新手,請務必查看 Getting Started 資源以快速啟動和運行。
?