新冠肺炎疫情引起了公眾對基于代理的建模與仿真( ABMS )的關注。它是研究行為的一種強大的計算技術,無論是流行病學、生物學、社會學還是其他方面。該過程在概念上很簡單:
- 描述了個人的行為(模型)。
- 提供了模型的輸入。
- 對許多相互作用的個體(或代理)的模擬使復雜的系統級行為得以自然出現。
這里有一個經典的例子:羊群、學校和牛群的行為。通過與群體保持緊密聯系(凝聚力)、避免沖突(分離)和匹配鄰居的速度(對齊)等相對簡單的行為,可以觀察到美麗的涌現模式。
FLAME GPU 是用于模擬復雜系統的開源軟件。它是獨立于領域的,可以用于任何使用基于代理的建模思想的模擬。描述個體行為和觀察緊急輸出的基于代理的建模方法使 FLAME GPU 能夠用于植絨、細胞生物學和運輸等示例。
以下視頻顯示了 FLAME GPU 軟件輸出的植絨示例。
視頻 1 。 FLAME GPU 基于 GPU 上 100K 代理的 Boids 模擬
無論給定模擬的主題如何,使用 ABMS 來模擬大量代理可能會產生顯著的計算成本。通常,此類模擬器被設計用于 CPU 架構上的順序執行,導致解決問題的時間極其緩慢,并限制了模擬模型的可行規模。
GPU ( FLAME GPU )庫的靈活大規模代理建模環境使您能夠利用 GPU 并行性的強大功能,顯著提高 ABMS 的計算性能和規模。該軟件速度極快,因此可以擴展到 NVIDIA A100 和 NVIDIA H100 上的數億代理 GPU 。
FLAME GPU 簡介
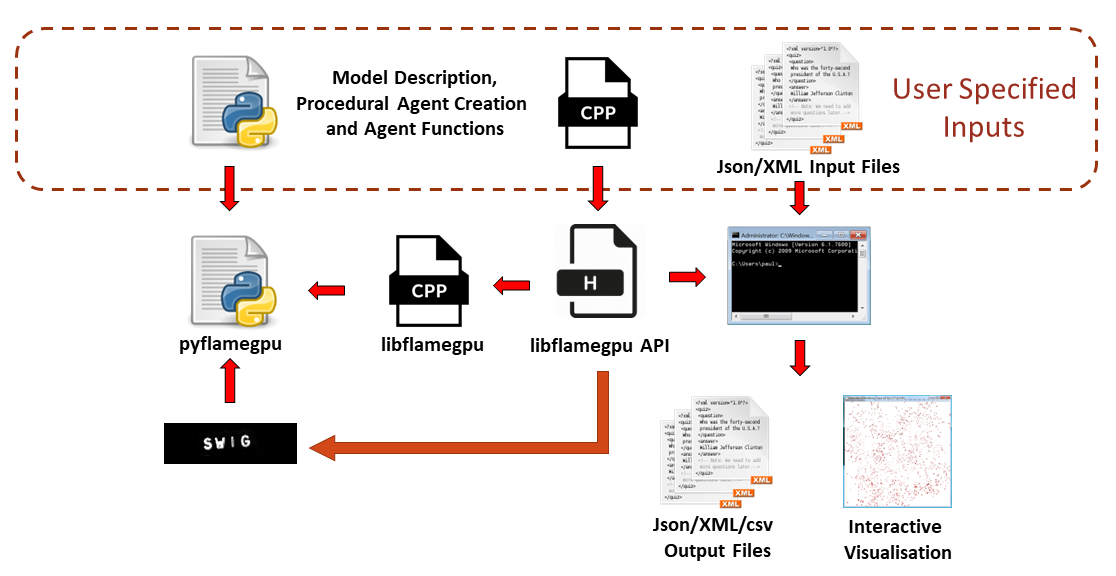
新的 FLAME GPU 軟件通過為模型和代理行為規范提供直觀的界面,抽象了在 GPU 上執行基于代理的模型的復雜性。該軟件通過提供一個抽象底層實現的許多復雜性的 API 來實現這一點。
例如,所有技術考慮都是透明處理的,以確保 GPU 上的出色執行性能。這可能包括空間數據結構的構建、 CUDA 內核執行的調度或內存中同質密集代理陣列的分組。
FLAME GPU 軟件用 CUDA C ++編寫,以在 NVIDIA GPU 上執行模擬。謝菲爾德大學的一個研究軟件工程師團隊已經開發了大約 5 年的版本 2 。它通過使用 C ++和 CUDA 的現代功能,構建并取代了該軟件的傳統 C 版本。我們通過他們的學術加速器和黑客馬拉松程序幫助優化了 NVIDIA 的代碼。
FLAME GPU 還有一個 Python 庫(pyflamegpu),它允許您在 Python 中本地指定模型。這包括代理行為,它是使用 Jitify 和 NVRTC 在運行時轉換和編譯的。有關使用庫的更多信息,請參見 Creating the Circles Model 。
圖 1 顯示了使用 FLAME GPU 庫構建模型的過程。本文將介紹 C ++中模型描述的規范。
- ?
代理行為
FLAME GPU 軟件可以被認為是更復雜、通用的粒子模擬版本,如 CUDA 示例中提供的。它支持多種任意的、用戶定義的、粒子或代理類型,在代理之間交換信息,并完全控制代理行為的設計。
代理行為由 agent function 指定,它充當流進程。代理的實例可以更新其內部狀態變量以及可選地輸出或輸入消息數據。
消息是存儲在列表中的狀態變量的集合,有助于代理之間的信息間接通信。向代理函數輸入消息數據是通過遍歷消息數據的 C ++迭代器實現的。不同的消息傳遞類型以不同的方式實現迭代器,但從用戶和模型抽象存儲、數據結構和迭代機制。
下面的示例演示了一個簡單的用戶定義代理函數 output _ message ,它需要三個參數,分別表示函數名、輸入和輸出消息類型。
在該示例中,輸出MessageSpatial2D類型的消息,該消息存在于連續空間 2D 環境中。單例對象FLAMEGPU用于使用getVariable檢索特定類型的命名變量,并使用message_out.setVariable將這些變量作為消息輸出到消息列表。
FLAMEGPU_AGENT_FUNCTION(output_message, flamegpu::MessageNone, flamegpu::MessageSpatial2D) {
FLAMEGPU->message_out.setVariable<int>("id", FLAMEGPU->getID());
FLAMEGPU->message_out.setLocation(
FLAMEGPU->getVariable<float>("x"),
FLAMEGPU->getVariable<float>("y"));
return flamegpu::ALIVE;
}
然后可以指定一個更復雜的代理函數來描述處理output_message輸出的消息的代理的行為。在下面的代碼示例中描述的 input _ message 中,消息循環迭代器遍歷任何空間數據結構以返回候選消息。
給定MessageSpatial2D消息作為輸入,候選消息由距離確定。這種代理的行為是施加排斥力,這取決于鄰居的位置。排斥因子由環境變量控制;即對模型中的所有代理都是只讀的變量。
FLAMEGPU_AGENT_FUNCTION(input_message, flamegpu::MessageSpatial2D, flamegpu::MessageNone) {
const flamegpu::id_t ID = FLAMEGPU->getID();
const float REPULSE_FACTOR =
FLAMEGPU->environment.getProperty<float>("repulse");
const float RADIUS = FLAMEGPU->message_in.radius();
float fx = 0.0;
float fy = 0.0;
const float x1 = FLAMEGPU->getVariable<float>("x");
const float y1 = FLAMEGPU->getVariable<float>("y");
int count = 0;
// message loop iterator
for (const auto &message : FLAMEGPU->message_in(x1, y1)) {
if (message.getVariable<flamegpu::id_t>("id") != ID) {
const float x2 = message.getVariable<float>("x");
const float y2 = message.getVariable<float>("y");
float x21 = x2 - x1;
float y21 = y2 - y1;
const float separation = sqrt(x21*x21 + y21*y21);
if (separation < RADIUS && separation > 0.0f) {
float k = sinf((separation / RADIUS)*3.141f*-2)*REPULSE_FACTOR;
// Normalize without recalculating separation
x21 /= separation;
y21 /= separation;
fx += k * x21;
fy += k * y21;
count++;
}
}
}
fx /= count > 0 ? count : 1;
fy /= count > 0 ? count : 1;
FLAMEGPU->setVariable<float>("x", x1 + fx);
FLAMEGPU->setVariable<float>("y", y1 + fy);
FLAMEGPU->setVariable<float>("drift", sqrt(fx*fx + fy*fy));
return flamegpu::ALIVE;
}
這里描述的代理函數定義了基于代理的系統的行為規范的完整示例,我們稱之為 circles 模型。這種行為類似于粒子系統、群體或群體,甚至是簡單的細胞生物學模型。
盡管由于所使用的抽象機制,這兩個代理函數并不明顯,但示例中的兩個代理功能都編譯為 CUDA 設備代碼。
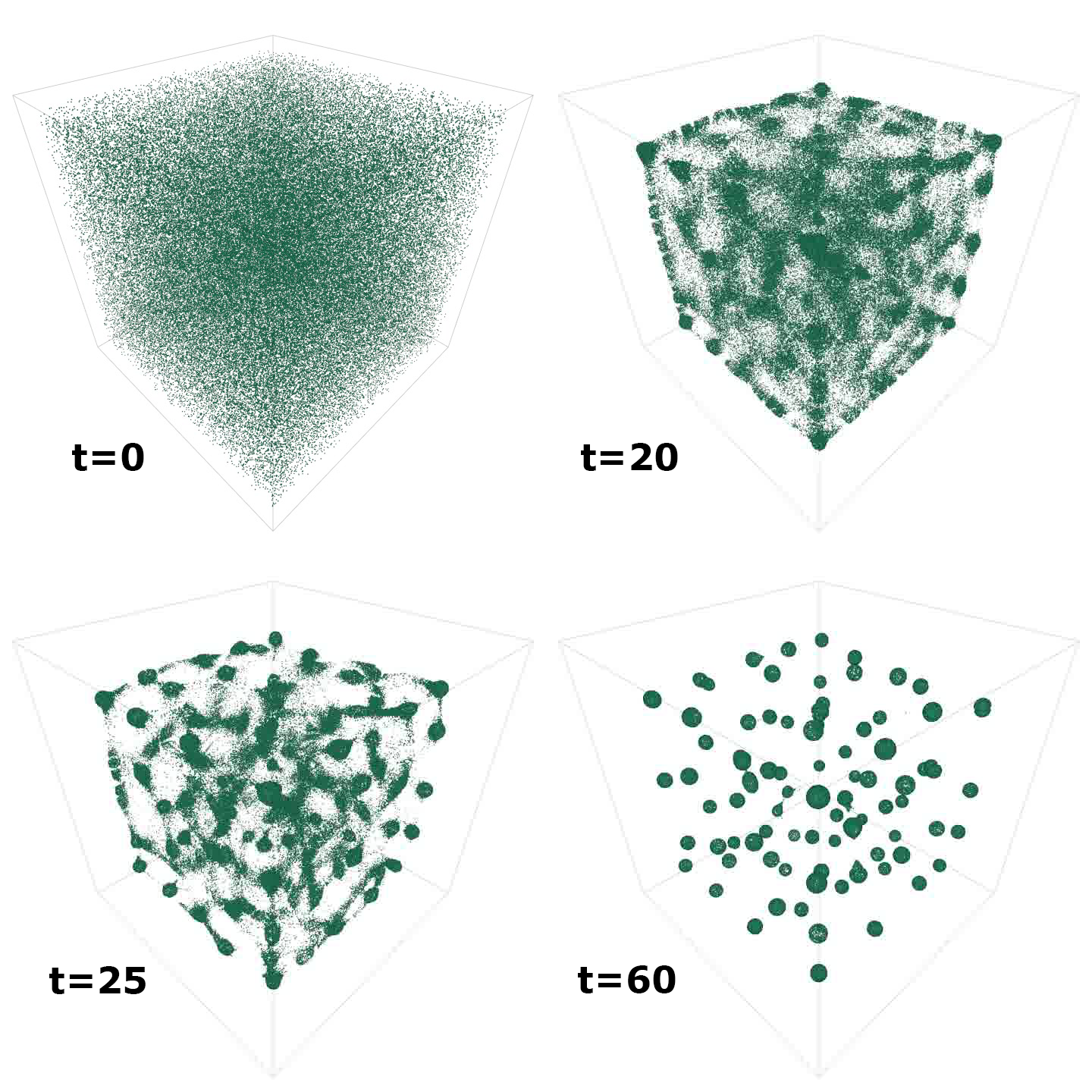
圖 2 顯示了隨著時間的推移(但擴展到 3D )模擬時該模型的緊急輸出。可視化由內置 FLAME GPU 可視化工具的屏幕截圖生成。
- ?
描述模型
FLAME GPU 軟件最重要的特征之一是基于狀態的代理表示,其中狀態只是一種對代理進行分組的方法。對于流行病學模型,藥劑可能處于易感、暴露、感染或恢復( SEIR )狀態。在生物模型中,細胞因子可能處于細胞周期的不同階段。代理的狀態可能決定代理執行的行為。
在 FLAME GPU 中,代理可以具有多個狀態,并且代理函數僅應用于處于特定狀態的代理。狀態的使用確保了在模型中可以發生不同的、異構的行為,避免了高度分散的代碼執行。簡單地說,代理與執行相同行為的其他代理分組。
模型,例如本示例中的圓模型,可以具有單個(默認)狀態,但是,復雜模型可能具有多個。國家在確定職能的執行順序方面也發揮著重要作用。通過函數中的消息使用,代理狀態之間發生間接通信。
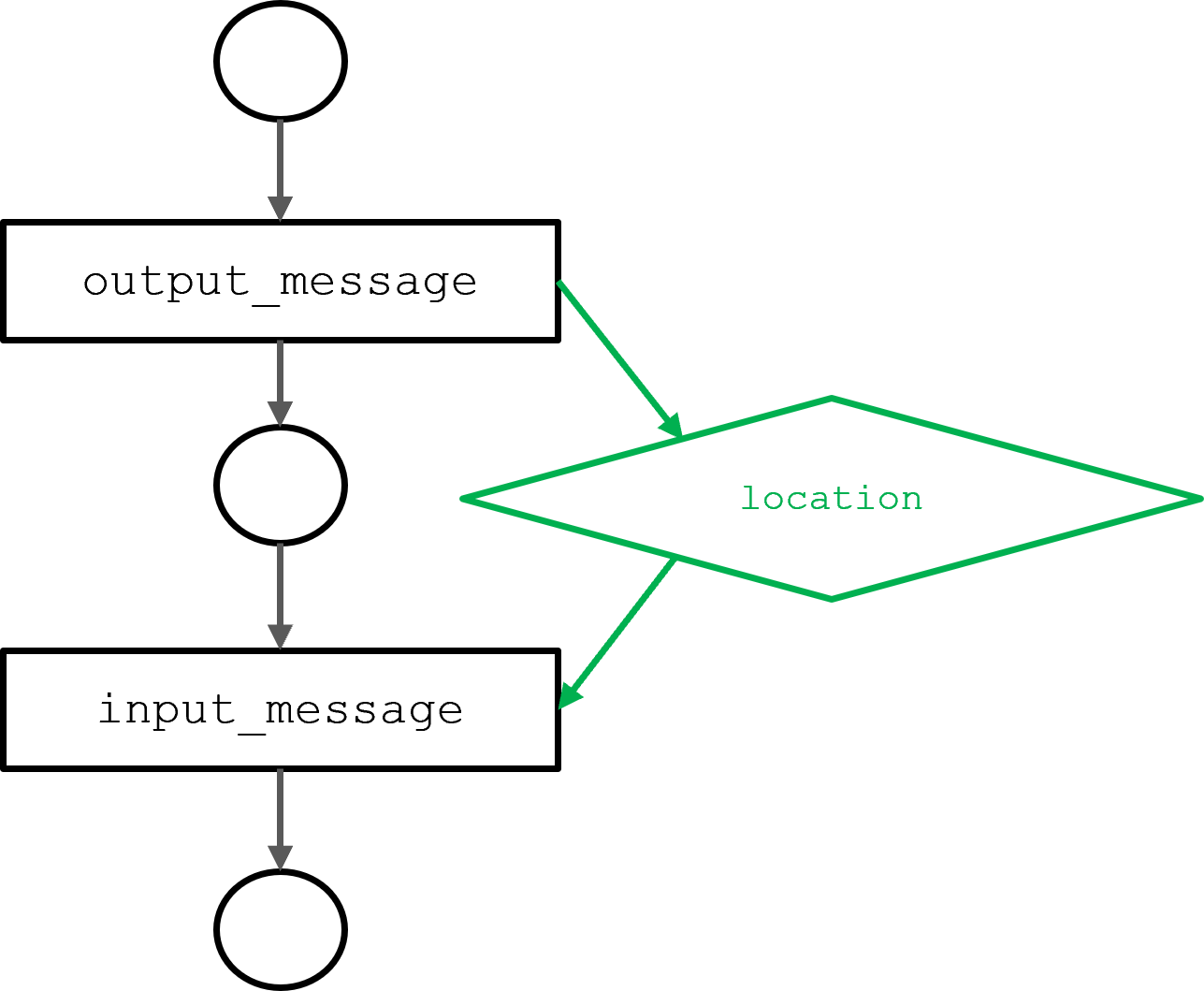
可以通過依賴性分析從程序上確定代理和功能之間的依賴性。結果是一個有向無環圖( DAG ),它表示模型的一次迭代中所有代理的行為。
圖 3 顯示了由上一節中描述的 output _ message 和 input _ message 代理函數生成的圓圈模型的 DAG 。input_message功能取決于output_message功能輸出的位置信息。依賴關系決定執行順序。
- ?
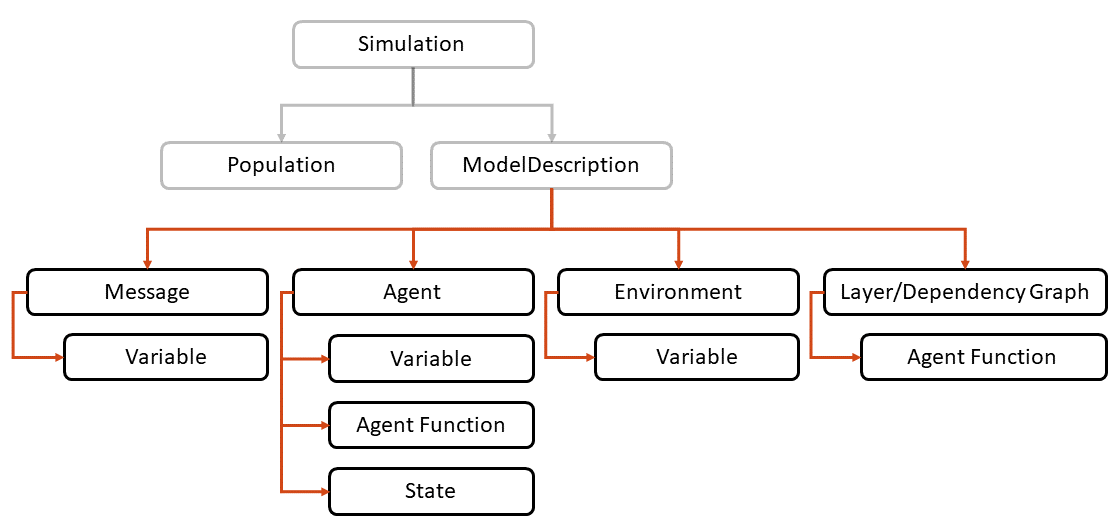
FLAME GPU 模型的完整狀態描述使用 FLAME GPU API 定義(圖 4 )。ModelDescription對象充當所描述模型的根,其描述如下:
// Define the FLAME GPU model
flamegpu::ModelDescription model("Circles Tutorial");
所有其他 API 對象都是ModelDescription對象的同級對象。在下面的示例中,(“ circle ”)代理由三個變量定義,其中每個變量都有一個特定的字符串名稱和一個顯式類型。變量名稱和類型與在代理函數中獲得的名稱和類型相匹配:
// Define an agent named point
flamegpu::AgentDescription agent = model.newAgent("circle");
// Assign the agent some variables (ID is implicit to agents, so we don't define it ourselves)
agent.newVariable<float>("x");
agent.newVariable<float>("y");
agent.newVariable<float>("drift", 0.0f);
與代理一樣,消息包含許多變量。例如,此處定義的消息具有一個變量,用于存儲其源代理的 ID 。消息也有一個特殊性,表明它們是如何存儲和迭代的。
在下一個示例中,消息被描述為type flamegpu::MessageSpatial2D。重要的是,此類型與前面代理函數的輸入和輸出類型相匹配。由于消息類型是 2D 空間的,消息隱式地包括坐標變量x和y。
消息類型還需要定義環境大小(消息存在的邊界)和空間半徑。空間半徑確定消息返回到查詢消息列表的代理的范圍。
// Define a message of type MessageSpatial2D named location
flamegpu::MessageSpatial2D::Description message =
model.newMessage<flamegpu::MessageSpatial2D>("location");
// Configure the message list
message.setMin(0, 0);
message.setMax(ENV_WIDTH, ENV_WIDTH);
message.setRadius(1.0f);
// Add extra variables to the message
// X Y (Z) are implicit for spatial messages
message.newVariable<flamegpu::id_t>("id");
信息專業性是 FLAME GPU 軟件的重要性能考慮因素。不同的消息類型有不同的實現和優化。在所有情況下,它們都使用 NVIDIA Nsight Compute 分析器進行了優化,以提高內存和計算吞吐量。
flamegpu::BruteForce的消息類型相當于每個代理讀取列表中的每個消息。有許多消息類型,包括離散化環境、桶和數組的類型,其中大多數使用 CUB 排序和掃描函數來構建空間數據結構。本示例中使用的空間消息構建了一個裝箱數據結構,使來自固定區域的消息能夠輕松定位。
通過將上一節中定義的代理函數分配給特定代理,可以將它們鏈接到模型。下面的代碼示例中定義的消息輸入和輸出類型需要與FLAMEGPU_AGENT_FUNCTION定義相匹配。
// Set up the two agent functions
flamegpu::AgentFunctionDescription out_fn =
agent.newFunction("output_message", output_message);
out_fn.setMessageOutput("location");
flamegpu::AgentFunctionDescription in_fn =
agent.newFunction("input_message", input_message);
in_fn.setMessageInput("location");
在 FLAME GPU 庫中,變量名(如x)通過哈希轉換為 CUDA 內存地址。編譯時散列用于確保翻譯在運行時開銷最小。特定于函數的哈希表在每個代理函數開始時加載到共享內存中,以最小化延遲。
在開發過程中,可以使用 CMake 中的FLAMEGPU_SEATBELTS選項啟用類型檢查。此選項執行其他額外的運行時檢查,這在開發過程中很有用。模型完成后,可以禁用FLAMEGPU_SEATBELTS以獲得最大的執行性能。
FLAME GPU 還支持運行時編譯的代理函數。在這種情況下,代理函數可以作為字符串提供,并使用 NVIDIA Jitify 庫進行編譯,該庫充當 NVRTC 的前端。設備代碼的運行時編譯對于提供 Python 綁定(pyflamegpu)至關重要。
為了進一步改善 Python 中的用戶體驗,pyflamegpu允許在本地 Python 的子集中描述代理函數。作為運行時編譯過程的一部分,這將被轉換為 C ++。
環境財產可用于參數化模型,并可由所有代理讀取。排斥因子AGENT_COUNT和ENV_WIDTH在代碼示例中指定。所有環境財產都使用與代理變量相同的機制進行散列。
// Define environment properties
flamegpu::EnvironmentDescription env = model.Environment();
env.newProperty<unsigned int>("AGENT_COUNT", AGENT_COUNT);
env.newProperty<float>("ENV_WIDTH", ENV_WIDTH);
env.newProperty<float>("repulse", 0.05f);
建模規范的最后一個階段是定義代理函數的執行順序。這可以手動指定為層,也可以通過相關性分析進行推斷。以下示例演示了通過相關性分析生成層的過程:
// Dependency specification flamegpu::DependencyGraph dependencyGraph = model.getDependencyGraph(); dependencyGraph.addRoot(out_fn); dependencyGraph.generateLayers(model);
將代理功能分離為多個層提供了一個同步框架,其中間接消息通信避免了競爭條件。更復雜的模型允許在同一層內重疊執行功能。層內使用的流支持并發執行,其優點在實現設備的良好利用方面可能非常重要。
執行調度是靜態的,因為 DAG 不變。然而,圖的各個方面可能不會導致特定功能的執行,例如,如果代理不存在于特定狀態中。
- ?
有關 API 的更多信息,請參閱 FLAME GPU documentation 。
模擬代理
執行代理模型需要CUDASimulation對象為 GPU 設備上的模型分配必要的內存。仿真對象負責配置模型的輸入和輸出以及仿真本身的啟動配置。
程序的主要參數被傳遞給模擬對象,并且可以包括迭代次數(例如--steps 100)。
flamegpu::CUDASimulation cuda_sim(model, argc, argv);
雖然不需要,但可以使用flamegpu::StepLoggingConfig指定模型的日志記錄,該選項設置日志記錄的頻率以及應記錄的變量。可以使用通用的歸約算子(min、man、
FLAMEGPU_AGENT_FUNCTION(output_message, flamegpu::MessageNone, flamegpu::MessageSpatial2D) {
FLAMEGPU->message_out.setVariable<int>("id", FLAMEGPU->getID());
FLAMEGPU->message_out.setLocation(
FLAMEGPU->getVariable<float>("x"),
FLAMEGPU->getVariable<float>("y"));
return flamegpu::ALIVE;
}
、
FLAMEGPU_AGENT_FUNCTION(input_message, flamegpu::MessageSpatial2D, flamegpu::MessageNone) {
const flamegpu::id_t ID = FLAMEGPU->getID();
const float REPULSE_FACTOR =
FLAMEGPU->environment.getProperty<float>("repulse");
const float RADIUS = FLAMEGPU->message_in.radius();
float fx = 0.0;
float fy = 0.0;
const float x1 = FLAMEGPU->getVariable<float>("x");
const float y1 = FLAMEGPU->getVariable<float>("y");
int count = 0;
// message loop iterator
for (const auto &message : FLAMEGPU->message_in(x1, y1)) {
if (message.getVariable<flamegpu::id_t>("id") != ID) {
const float x2 = message.getVariable<float>("x");
const float y2 = message.getVariable<float>("y");
float x21 = x2 - x1;
float y21 = y2 - y1;
const float separation = sqrt(x21*x21 + y21*y21);
if (separation < RADIUS && separation > 0.0f) {
float k = sinf((separation / RADIUS)*3.141f*-2)*REPULSE_FACTOR;
// Normalize without recalculating separation
x21 /= separation;
y21 /= separation;
fx += k * x21;
fy += k * y21;
count++;
}
}
}
fx /= count > 0 ? count : 1;
fy /= count > 0 ? count : 1;
FLAMEGPU->setVariable<float>("x", x1 + fx);
FLAMEGPU->setVariable<float>("y", y1 + fy);
FLAMEGPU->setVariable<float>("drift", sqrt(fx*fx + fy*fy));
return flamegpu::ALIVE;
}
、sum)來歸約代理變量值,或者可以記錄總體的整個狀態變量。
flamegpu::StepLoggingConfig step_log_cfg(cuda_sim);
step_log_cfg.setFrequency(1);
step_log_cfg.agent("circle").logMean<float>("drift");
// Attach the logging config
cuda_sim.setStepLog(step_log_cfg);
對于工作示例中的圓圈模型,記錄漂移可以測量整體代理移動。漂移是一種新興的特性,隨著藥劑形成結構化的圓形,預計會隨著時間的推移而減少(圖 2 )。
模擬的最后階段是定義代理的初始變量。在下面的示例中, Mersenne Twister 偽隨機生成器用于生成群體中每個代理的x和y變量。flamegpu::AgentVector對象提供了一種設置代理數據的機制。這存儲在設備內存中的密集陣列中,以促進來自代理函數的聯合訪問。
std::mt19937_64 rng;
std::uniform_real_distribution<float> dist(0.0f, ENV_MAX);
flamegpu::AgentVector population(model.Agent("circle"), AGENT_COUNT);
for (unsigned int i = 0; i < AGENT_COUNT; i++) {
flamegpu::AgentVector::Agent instance = population[i];
instance.setVariable<float>("x", dist(rng));
instance.setVariable<float>("y", dist(rng));
}
cuda_sim.setPopulationData(population);
最后,可以執行模擬。
// Run the simulation cuda_sim.simulate();
在這個示例中,只執行一次模擬。step_log_cfg對象可用于處理輸出或將記錄的值轉儲到文件中。 FLAME GPU 還支持集成仿真,允許執行仿真的多個實例化,但輸入和環境財產不同。
模擬實例化可以被安排在單個設備上執行,或者可以在共享內存系統上的設備之間分布。我們已廣泛使用此功能來校準癌癥生長和治療的生物模型。
如果需要圖形模擬,可以使用 FLAME GPU 內置 3D OpenGL 可視化工具( video )對模擬進行可視化。可視化工具支持基于實例的代理渲染,并使用 CUDA OpenGL 互操作性將代理數據直接映射到圖形管道中。
如果你觀看這個模擬的視頻,你會發現每個代理實際上都是一個帶有撲動動畫的 3D 鳥類模型。數百萬代理的交互可視化是可能的,可視化工具允許導航和交互操作環境變量,以觀察緊急效果。
表演
FLAME GPU 在基于代理的模擬中非常有效,但是,很難對基于代理的模擬器進行公平比較。大多數現有的模擬器都是為串行執行而設計的。事實上,許多現有模型甚至依賴于串行操作來確保公平性。”
這方面的一個經典例子是在離散(或棋盤式)環境中移動代理。在串行中,代理的移動確保環境單元從不被多個代理占用。隨機化運動順序可確保模擬公平。
在 FLAME GPU 中實現的這種移動的并行等價物需要使用迭代競價過程,以確保所有代理都有機會移動并避免小區占用中的沖突。
FLAME GPU 引入了子模型的新概念,以封裝遞歸算法來解決此類沖突。基于代理的模型避免了空間沖突并在連續空間中運行,因此在并行環境中性能更好,因為在移動過程中不會發生沖突。
我們選擇比較兩個不同的模型,以顯示 FLAME GPU 與其他知名 CPU 模擬器 Mesa 、 NetLogo 和 Agents.jl (Julia) 的比較。我們選擇了兩個眾所周知的模型,其中每個框架中都有現有的實現。
其中的第一個是 2D 中的 Boids 植絨模型的實現,在連續空間中運行,與本文中的示例類似,只是代理之間的交互稍微復雜一些。
第二,謝林的社會隔離模式,是高度系列化模式的一個例子。它可以在棋盤式環境中移動。在 FLAME GPU 中,它使用子模型來解決移動中的沖突。
Boids 模型的性能在 100 次迭代中進行了測量,僅限于 80k 個代理,這不足以完全使用現代 GPU 設備。除此之外,串行模擬器是合理基準測試時間的限制因素。在 Schelling 模型中,規模增加到 250K 個代理( 80% 的單元占用率),因為由于受限的基于網格的環境,它在所有模擬器中的執行效率更高。
包含這兩個模型的基準是容器化的,可在 FLAMEGPU/ABM_Framework_Comparisons GitHub repo 上使用。這是 forked 來自為 Agents.js 框架進行的現有基準活動。為了生成圖 5 ,每次模擬總共重復 10 次。為了節省時間, NetLogo 和 MESA 的重復次數減少為三次。
通過測量主模擬回路報告平均模擬時間,不包括所有模擬器中常見的模式初始化。結果是從具有以下配置的機器上獲得的:
- Ubuntu 22.04 Apptainer 映像
- AMD EPYC 7413 24 核處理器
- NVIDIA A100-SXM4 80 GB (驅動程序 515.65.01 )
- Flame GPU 2.0.0-rc0
- Netlogo 6.3
- Mesa 1.0
- CUDA 11.7
- GCC 11.3
- Python 3.10
- Julia 1.8.2
- Agents.jl 5.5
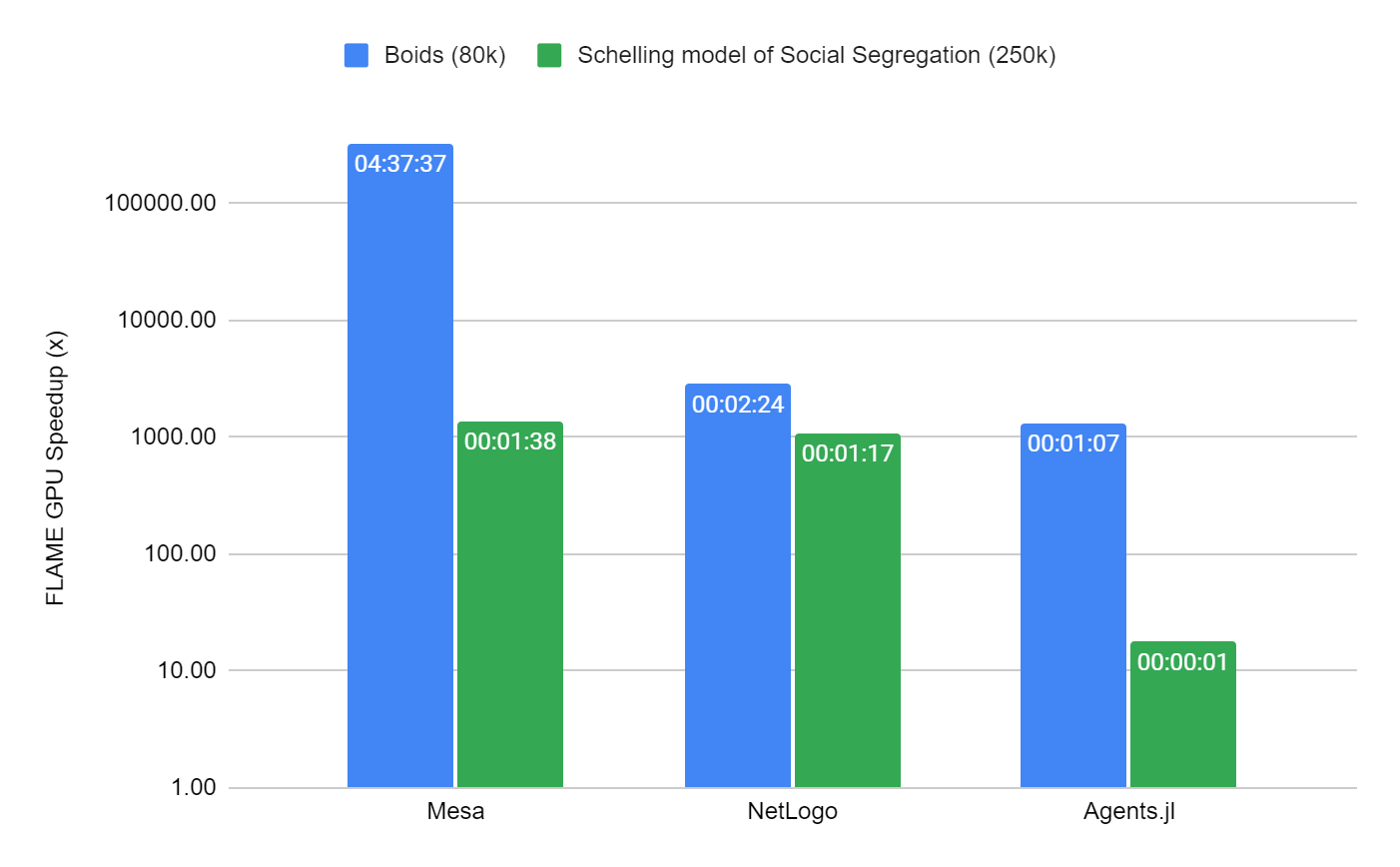
考慮到 Boids 模型的性能, FLAME GPU 至少比次優模擬器( Agents.jl )快 1000 倍,比最差模擬器( Mesa )快數十萬倍。 FLAME GPU 的模擬時間僅為約 51 毫秒。
對于 Schelling 模型, FLAME GPU 比第二快的模擬器 Agents.jsl 快約 18 倍,耗時約 70 毫秒,比 NetLogo 和 Mesa 快 1000 多倍。
FLAME GPU 的性能可歸因于 FLAME GPU 轉換模型以利用 GPU 高水平并行性的能力。該框架的設計考慮到了并行性和性能,并平衡了內存帶寬和計算,以實現高水平的設備利用率。
FLAME GPU 軟件確實需要一些模型串行初始化以及 CUDA 上下文創建的開銷。其他模擬器具有相同的開銷,例如, Agents.jar 使用實時編譯。然而,固定成本管理費用可以通過運行時間較長的模型輕松攤銷。
FLAME GPU 有可能大大提高桌面用戶可用的模擬性能和規模。正在進行的研究活動的一個領域正在考慮巨大的挑戰問題,其中模擬規模可以擴展到數十億個代理。
一個這樣的例子是 EU Horizon 2020 PRIMAGE project ,它支持了軟件的開發。在該項目中, FLAME GPU 用于支持神經母細胞瘤( NB )的決策和臨床管理, NB 是兒童早期最常見的實體癌癥。該項目使用精心策劃的模擬方法來研究藥物治療對超過 30 億細胞的全腫瘤的影響。
立即嘗試 FLAME GPU
FLAME GPU 軟件是 MIT 許可證下的開源軟件。它可以從 FLAMEGPU/FLAMEGPU2 GitHub repo 或 FLAME GPU website 下載,其中包括使用 CMake 的構建指令。您可以使用pip安裝托管在 GitHub 上的預打包 Python 模塊。
致謝
該項目的支持由 Applied Research Accelerator Program at NVIDIA.
?
?