隨著 AI 工作負載的擴展,快速可靠的 GPU 通信變得至關重要,這不僅適用于訓練,而且越來越適用于大規模推理。NVIDIA 集合通信庫 (NCCL) 可提供高性能、拓撲感知型集合運算:AllReduce、Broadcast、Reduce、AllGather 和 ReduceScatter,這些運算已針對 NVIDIA GPU 以及 PCIe、NVLink、以太網 (RoCE) 和 InfiniBand (IB) 等各種互連產品進行優化。
憑借其通信和計算的單核實現,NCCL 可確保低延遲同步,成為分布式訓練和實時推理場景的理想選擇。得益于 NCCL 動態拓撲檢測和簡化的基于 C 的 API,開發者無需調整特定硬件配置即可跨節點進行擴展。
本文將介紹最新的 NCCL 2.27 版本,展示可增強推理延遲、訓練彈性和開發者可觀察性的功能。如需了解詳情并開始使用,請查看 NVIDIA/nccl GitHub 存儲庫。
解鎖新的性能水平
NCCL 2.27 提供關鍵更新,可增強跨 GPU 的聚合通信,解決延遲、帶寬效率和擴展挑戰。這些改進支持訓練和推理,符合現代 AI 基礎設施不斷變化的需求,其中超低延遲對于實時推理流程至關重要,并且需要強大的容錯能力來保持大規模部署的可靠運行。
主要版本亮點包括具有對稱內存的低延遲內核、直接 NIC 支持以及 NVLink 和 InfiniBand SHARP 支持。
具有對稱內存的低延遲內核
此版本引入了對稱內存支持,允許跨 GPU 具有相同虛擬地址的緩沖區從優化的集合運算中受益。這些內核可顯著降低各種消息大小的延遲,使小消息大小的延遲最多可降低 7.6 倍,如圖 1 所示。
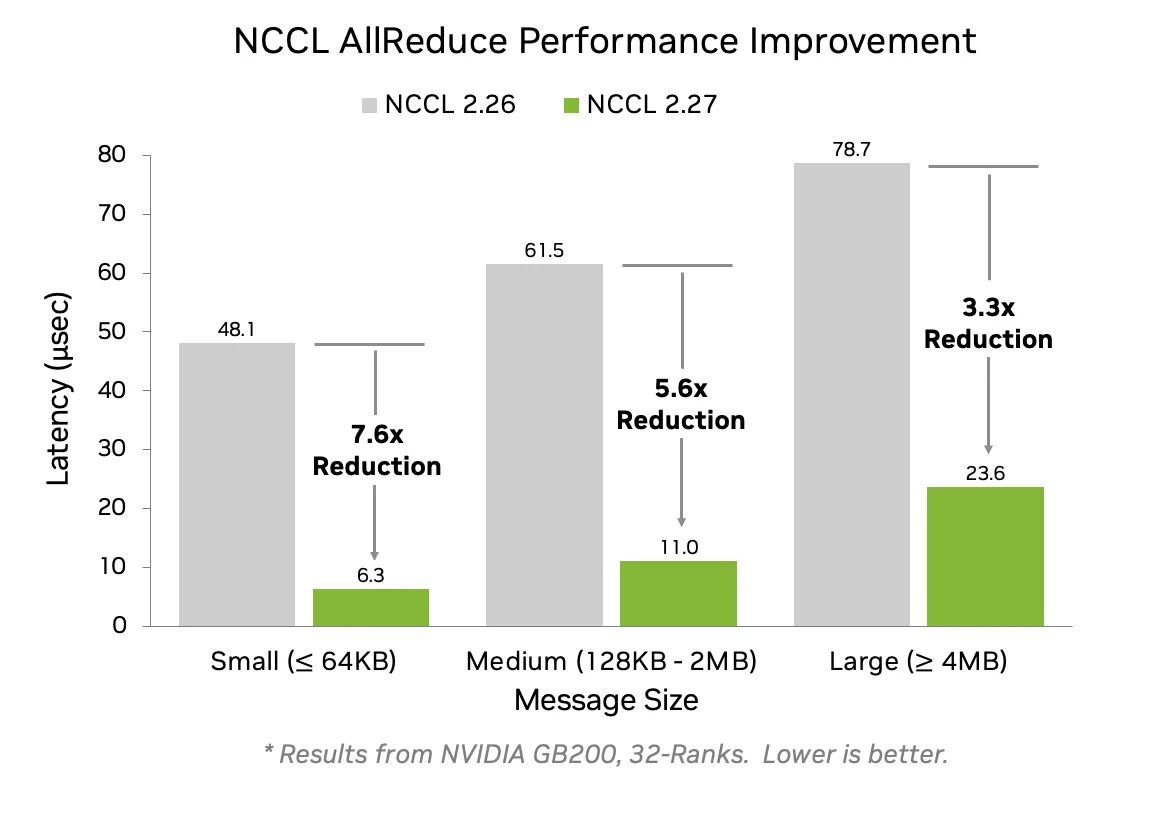
AllReduce 延遲使用 FP32 累加器 (或 FP16 用于 NVLink Switch (NVLS) 系統上的 FP8) 計算縮減,從而提高 AllReduce、tg_ 11 和 tg_ 12 等運算中的準確性和確定性。
單個 NVLink 域內的 NVLink 通信支持對稱內存 – NVIDIA GB200 和 GB300 系統中支持 NVL72 ( 72 個 GPU) ,NVIDIA DGX 和 HGX 系統中支持 NVL8 ( 8 個 GPU) 。即使在 NVL8 域中,開發者也能看到中小型消息大小的性能提升高達 2.5 倍。有關測試指導,請查看 NCCL-Test 存儲庫。
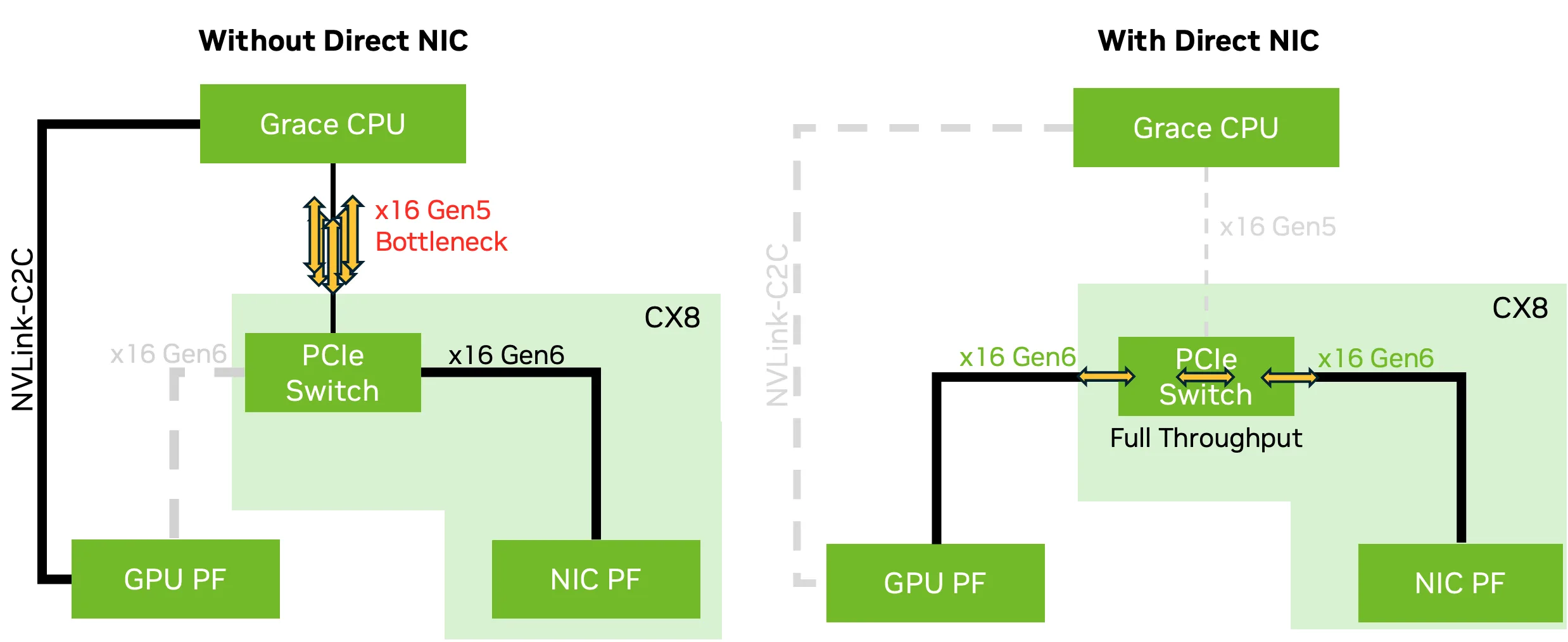
直接網卡支持
NCCL 2.27 引入了對 Direct NIC 配置的支持,可為 GPU 橫向擴展通信解鎖完整的網絡帶寬。在選定的 NVIDIA Grace Blackwell 平臺上,CX8 網卡和 NVIDIA Blackwell GPU 等組件支持 PCIe Gen6 x16,可提供高達 800 Gb/s 的網絡帶寬。但是,Grace CPU 目前僅支持 PCIe 5.0,將吞吐量限制在 400 Gb/s。
為了解決這個問題,CX8 網卡暴露了兩個虛擬 PCIe 樹:在一個樹上,如圖 2 所示,NVIDIA CX8 網卡數據直接功能 ( PF) 通過 PCIe Gen6 x16 鏈路直接連接到 GPU PF,繞過 CPU,避免了帶寬瓶頸。在另一個樹中,常規 NIC PF 連接到 CPU 根端口。
此配置可確保 GPUDirect RDMA 和相關技術能夠實現完整的 800 Gb/s 帶寬,而不會使 CPU 到 GPU 的帶寬飽和,這在多個 GPU 共享單個 CPU 時尤為重要。Direct NIC 是為高吞吐量推理和訓練工作負載實現全速網絡的關鍵。
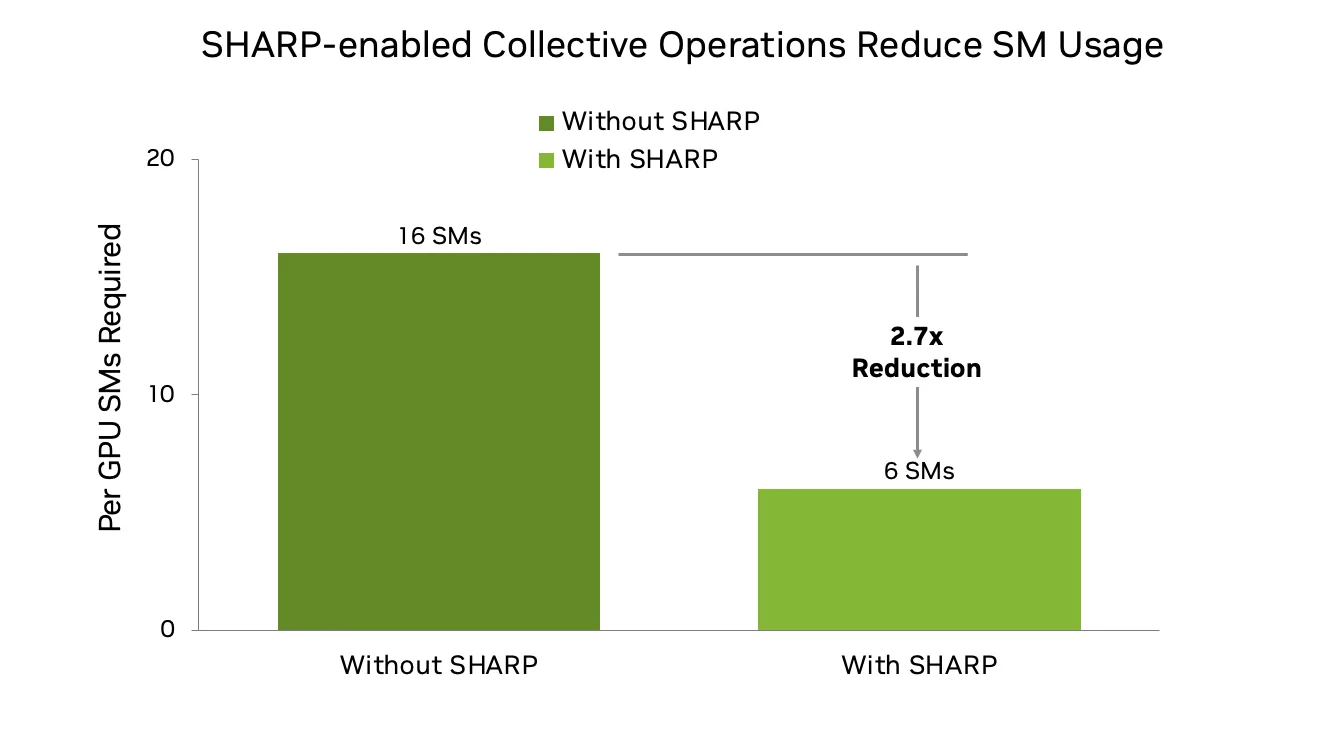
支持 NVLink 和 InfiniBand SHARP
NCCL 2.27 為 NVLink 和 IB 結構增加了對 SHARP (可擴展分層聚合和歸約協議) 的支持。SHARP 支持網絡內歸約操作,可卸載計算密集型任務。在使用 NVLink Sharp 和 IB Sharp 時,此新版本為從 GPU 到網絡的 AllGather (AG) 和 tg_ 15 (RS) 群集提供 SHARP 支持。
這對于大規模 LLM 訓練尤其有益,因為在大規模 LLM 訓練中,為了更好地重疊計算和通信,AG 和 RS 現在比 AllReduce 更受歡迎。傳統的基于環的實現可能會消耗 16 個或更多的 SM,但借助 NVLink 和 IB SHARP,這種需求減少到 6 個或更少,從而騰出資源用于模型計算,并提高整體訓練效率。因此,在 1000 GPU 級別及以上的情況下,可擴展性和性能得到了提升。
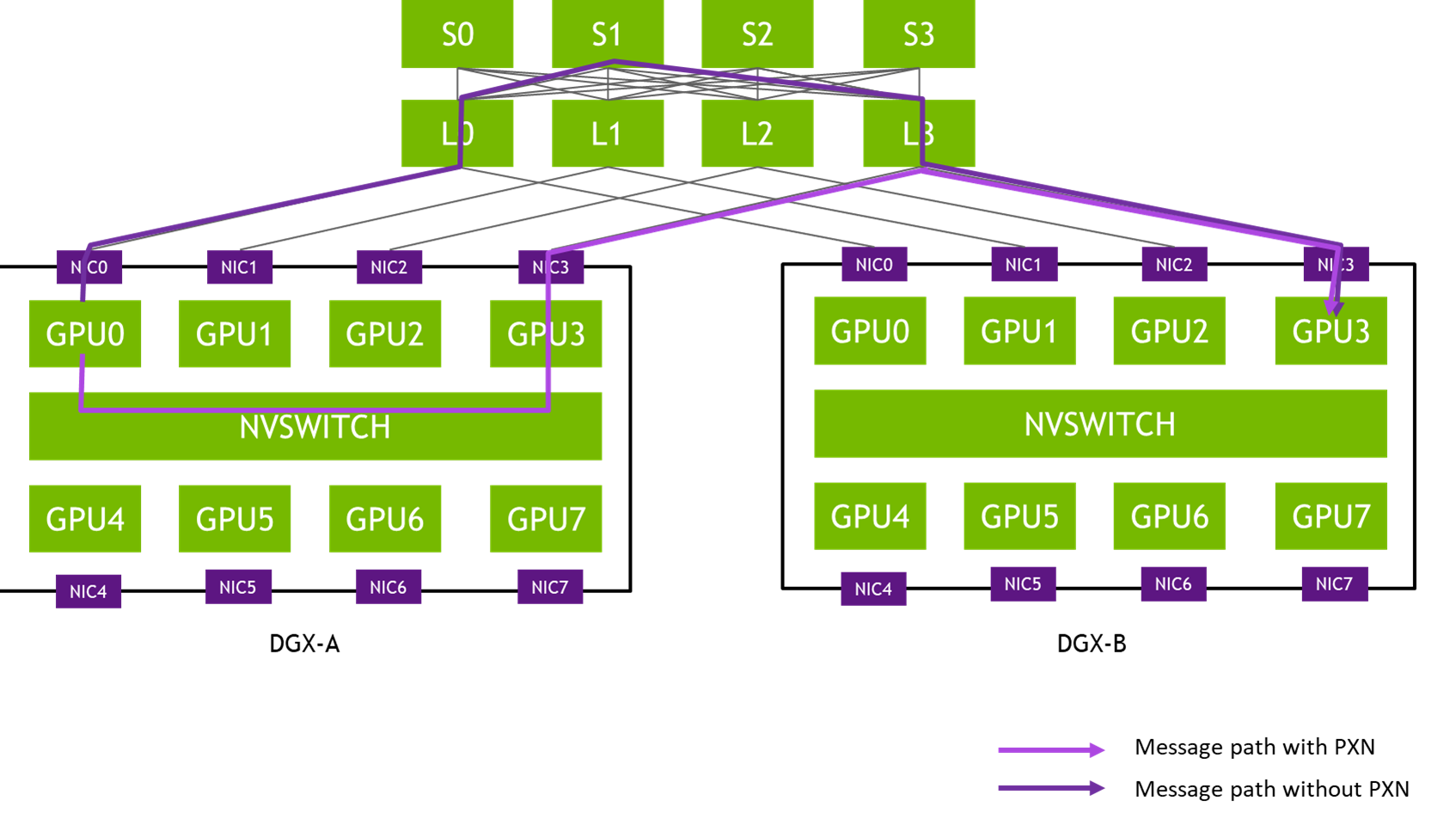
使用 NCCL Shrink 增強大規模訓練的彈性
NCCL 2.27 引入了 Communicator Shrink,該功能旨在使分布式訓練更加穩健、靈活和高效。在數百或數千個 GPU 上運行的訓練作業容易受到設備故障的影響。Communicator Shrink 支持在訓練期間動態排除出現故障或不必要的 GPU。此功能支持兩種操作模式:
- 默認模式:用于有計劃的重新配置,允許修改設備拓撲,同時確保完成所有操作。
- 錯誤模式:自動中止正在進行的操作,以從意外的設備故障中恢復。
NCCL Shrink 使開發者能夠:
- 通過動態重建通信器保持不間斷訓練。
- 通過可配置的資源共享盡可能重復使用資源。
- 以最少的中斷妥善處理設備故障。
NCCL Shrink 在計劃的重新配置和錯誤恢復場景中的使用示例:
// Planned reconfiguration: exclude a rank during normal operationNCCLCHECK(ncclGroupStart());for (int i = 0; i < nGpus; i++) { if (i != excludedRank) { NCCLCHECK(ncclCommShrink( comm[i], &excludeRank, 1, &newcomm[i], NULL, NCCL_SHRINK_DEFAULT)); }}NCCLCHECK(ncclGroupEnd());// Error recovery: exclude a rank after a device failureNCCLCHECK(ncclGroupStart());for (int i = 0; i < nGpus; i++) { if (i != excludedRank) { NCCLCHECK(ncclCommShrink( comm[i], &excludeRank, 1, &newcomm[i], NULL, NCCL_SHRINK_ABORT)); }}NCCLCHECK(ncclGroupEnd()); |
面向開發者的更多功能
此版本中面向開發者的其他功能包括對稱內存 API 和增強型分析。
對稱內存 API
對稱內存是 NCCL 2.27 中的一項基礎功能,可實現高性能、低延遲的集合運算。當內存緩沖區在所有 rank 上以相同的虛擬地址分配時,NCCL 可以執行經過優化的內核,從而減少同步開銷并提高帶寬效率。
為此,NCCL 引入了用于對稱內存集合注冊的窗口 API:
ncclCommWindowRegister(ncclComm_t comm, void* buff, size_t size, ncclWindow_t* win, int winFlags);ncclCommWindowDeregister(ncclComm_t comm, ncclWindow_t win); |
ncclCommWindowRegister使用 NCCL 通信器注冊用戶分配的內存。必須使用 CUDA 虛擬內存管理 (VMM) API 分配內存。winFlags必須包含 tg_ 22 才能啟用對稱內核優化。- 所有 rank 必須為緩沖區提供匹配偏移量,以確保對稱尋址。
- 取消注冊 (
ncclCommWindowDeregister) 是一項本地操作,只能在所有相關集合完成后進行。
ncclCommWindowRegister 是集合和阻塞,這意味著當多個 GPU 由單個線程管理時,它們必須封閉在 tg_ 25 和 tg_ 26 中。
如果不需要對稱內存,用戶可以通過設置 NCCL_WIN_ENABLE=0 來完全禁用該功能。
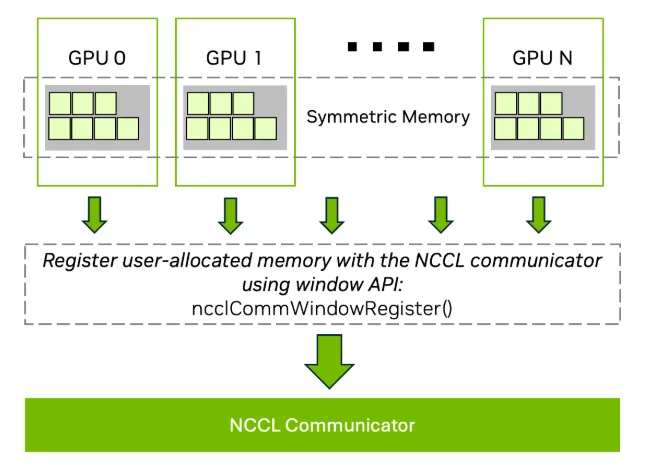
圖 4 顯示了如何使用 NCCL 窗口 API 在多個 GPU 上注冊對稱內存。通過對齊虛擬地址,NCCL 可實現經過優化的低延遲內核,從而提高集合運算的性能。
增強型分析
NCCL 2.27 為其分析基礎設施引入了一系列增強功能,為開發者和工具提供更準確、更高效的儀器來診斷通信性能。
協調代理事件
之前,NCCL 公開了 ncclProfileProxyOp 和 ncclProfileProxyStep 事件,以跟蹤網絡代理線程的進度。雖然這些事件提供了不同級別的粒度,但它們也復制了許多儀器點。在版本 2.27 中,NCCL 通過刪除冗余的 ProxyOp 狀態并引入統一的 tg_ 32 狀態來簡化此模型。這可在不犧牲細節的情況下減少分析器開銷,并在跟蹤通信進度時提高清晰度。
此外,我們還引入了新的 ProxyStep 事件狀態:tg_ 34,以反映發送者秩等待接收者發布清晰發送信號的時間,在集成之前的功能的同時最大限度地減少重復。
GPU 內核事件準確性
為提高計時準確性,NCCL 現在支持原生 GPU 時間傳播。GPU 工作計數器是一種容易受到延遲偽影 (例如延遲或折疊的核函數) 影響的方法,不再依賴于主機側事件計時,現在 GPU 使用其內部全局計時器記錄和導出開始和停止時間。這使分析器工具能夠直接從 GPU 獲取精確的內核運行時持續時間,但將時間轉換為 CPU 時間的開發者需要應用校準或插值。
網絡插件事件更新
NCCL 分析器接口現在支持用于網絡定義事件的 recordEventState。這種新機制使分析器能夠更新正在進行的操作的狀態,這對于將實時網絡反饋注入到性能時間線 (例如轉發信號或擁塞提示) 非常有用。
其他增強功能
- 分析器初始化:在分析器初始化期間,NCCL 現在報告通信器元數據,包括名稱、ID、節點數量、等級數量和調試級別。
- 通道報告:報告的通道數量反映的是實際使用情況,而非理論限制。其中包括點對點 (P2P) 操作。
- Communicator 標記:
ncclConfig_t已擴展為包含 Communicator 名稱,從而提高分析操作與特定 Communicator 之間的相關性。
這些更新共同提高了 NCCL 分析器插件接口的保真度,使開發者能夠更深入地了解網絡動態、GPU 計時和操作結構,這些對于診斷和調整大規模 AI 工作負載至關重要。
有關 NCCL Profiler 插件的更多信息,請參閱 NVIDIA/nccl GitHub 資源庫。
前瞻性支持
前瞻性支持包括:
- 跨數據中心通信:早期支持允許跨分布在各地的數據中心進行集合操作。
- 多網卡插件可見性:支持同時利用多種網絡配置。
開始使用 NCCL 2.27
探索 NCCL 2.27 中的新功能,并通過更低的延遲、更高的容錯性和更深入的可觀測性提升分布式推理和訓練工作流。
如需獲取詳細文檔和源代碼,以及獲取所需的支持,請訪問 NVIDIA/nccl GitHub 資源庫。如需詳細了解為您的架構配置 NCCL,請參閱 NCCL 文檔。
?