近年來,大型語言模型( LLM )的數量激增,它們超越了傳統的語言任務,擴展到生成式人工智能這包括像 ChatGPT 和 Stable Diffusion 這樣的模型。隨著這種對生成人工智能的關注不斷增長,人們越來越需要一種現代機器學習( ML )基礎設施,使日常從業者能夠訪問可擴展性。
本文介紹了兩個開源框架,Alpa.ai和Ray.io,共同努力實現訓練 1750 億參數所需的規模JAX transformer具有流水線并行性的模型。我們詳細探討了這兩個集成框架,以及它們的組合架構、對開發人員友好的 API 、可伸縮性和性能。
Alpa 和 Ray 的核心都是為了提高開發人員的速度和有效地擴展模型。 Alpa 框架的流水線并行功能可以輕松地在多個 GPU 上并行化大型模型的計算,并減輕開發人員的認知負擔。 Ray 提供了一個分布式計算框架,可以簡化跨多臺機器的資源擴展和管理。
當 Alpa 和 Ray 一起使用時,它們提供了一個可擴展且高效的解決方案,可以在大型 GPU 集群中訓練 LLM 。通過這種集成,基準測試顯示了以下好處:
- 對于 1750 億參數規模的 LLM , Alpa on Ray 可以擴展到 1000 GPU 以上。
- 所有 LLM 并行化和分區都是通過一行裝飾器自動執行的。
大型語言模型概述
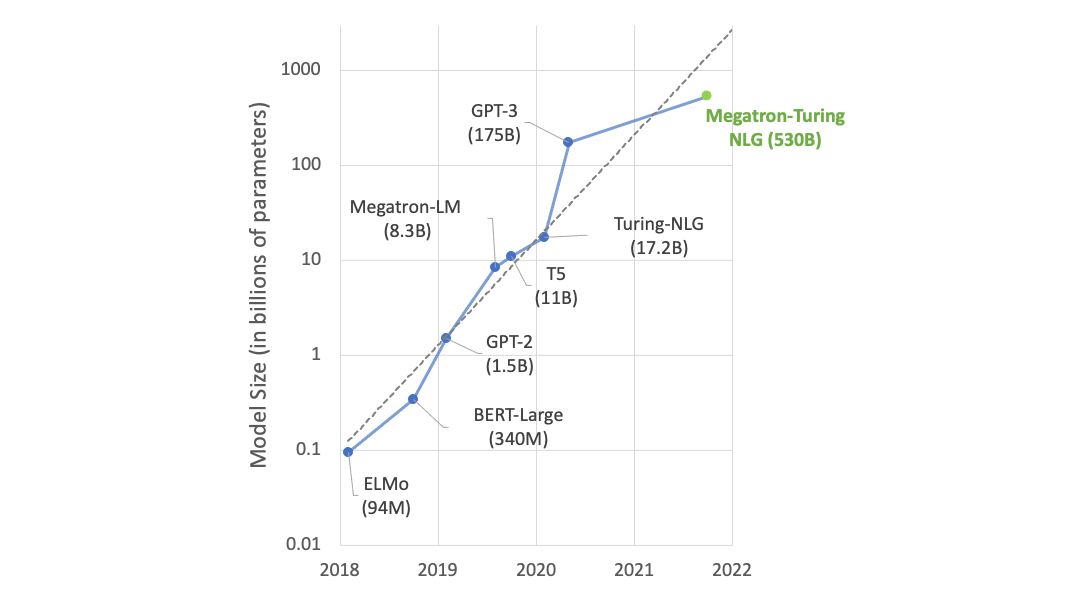
大型語言模型( LLM )主要基于 transformer 體系結構。 2017 年的開創性論文,Attention Is All You Need,刺激了基于 transformer 的模型的無數變化,在數十億的訓練參數中呈指數級增長。這些變化,例如BERT,RoBERTa,GPT-2 and GPT-3和ChatGPT– 都是在變壓器上設計的,變壓器包含了多頭注意力和編碼器/解碼器塊的核心架構組件。
由于學術界和各行業的深入研究,在短時間內迅速發布了訓練參數為數十億的模型。由最近的Diffusion和DALL-E語言模型, LLM 引入了生成人工智能的概念:向模型提供不同的輸入模式文本、視頻、音頻和圖像,以分析、合成和生成新內容,作為簡單的序列到序列任務。
生成人工智能是自然語言處理( NLP )的下一個時代。要了解更多信息,請參閱What Is Generative AI?和What’s the Big Deal with Generative AI? Is it the Future or the Present?
從零開始訓練這些十億參數 LLM 模型或使用新數據對其進行微調,都帶來了獨特的挑戰。訓練和評估 LLM 模型需要巨大的分布式計算能力、基于加速的硬件和內存集群、可靠和可擴展的機器學習框架以及容錯系統。在以下各節中,我們將討論這些挑戰,并提出解決這些挑戰的方法。
LLM 的機器學習系統挑戰
現代 LLM 的參數大小為數千億,超過了單個設備或主機的 GPU 內存。例如, OPT-175B 模型需要 350GB 的 GPU 內存來容納模型參數,更不用說訓練期間梯度和優化器狀態所需的 GPU 內存了,這可能會將內存需求推高到 1TB 以上。要了解更多信息,請參閱Democratizing Access to Large-Scale Language Models with OPT-175B.
同時,商品 GPU 只有 16GB / 24GB GPU ‘內存,即使是最先進的 NVIDIA A100 和 H100 GPU 每個設備也只有 40GB / 80GB GPU 內存。
為了有效地運行 LLM 的訓練和推理,開發人員需要在其 計算圖、參數和優化器狀態,使得每個分區都適合單個 GPU 主機的內存限制。基于可用的 GPU 集群, ML 研究人員必須堅持在不同的并行化維度上進行優化的策略,以實現高效的訓練
然而,目前,跨不同并行化維度(數據、模型和管道)優化訓練是一個困難的手動過程。 LLM 的現有維度劃分策略包括以下類別:
- 操作員間并行性:將整個計算圖劃分為不相交的子圖。每個設備計算其分配的子圖,并在完成后與其他設備通信。
- 操作員內部并行性:劃分矩陣參與到子矩陣的運算符中。每個設備計算其分配的子矩陣,并在進行乘法或加法時與其他設備通信
- 組合:這兩種策略都可以應用于同一個計算圖。
請注意,一些研究工作將模型并行度分類為“ 3D 并行度”,分別表示數據、張量和管道并行度。在 Alpa 的術語中,數據只是張量并行度的外部維度,映射到操作器內并行度,而流水線并行度是互操作器并行度的結果,通過流水線編排將圖劃分為不同的階段。這些功能是等效的,因此我們將保持分區術語的簡單性和一致性,在文章的剩余部分使用術語“互操作器”和“操作器內”并行性
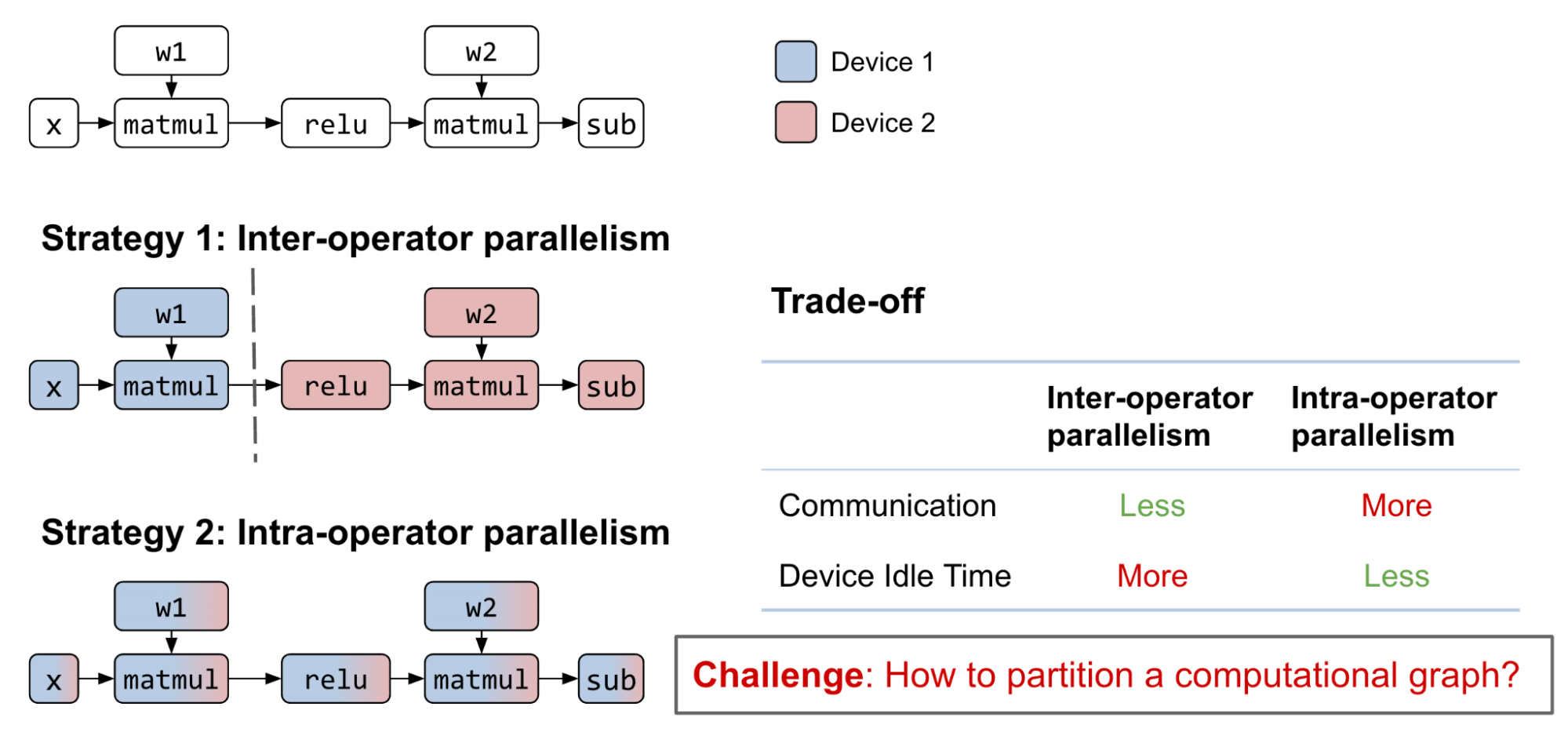
探索互操作和操作內并行的可能策略是一個具有挑戰性的組合問題,需要各種權衡。通過合理的互操作并行計算圖劃分,子圖之間的通信成本可以很小,但會引入數據依賴性。盡管流水線可以幫助緩解這個問題,但設備空閑時間仍然是不可避免的
另一方面,當下一個算子不能保留前一個算子的矩陣分區時,算子內并行可以在多個 GPU 設備之間并行化算子計算,空閑時間更少。這種方法帶來了更高的通信成本。
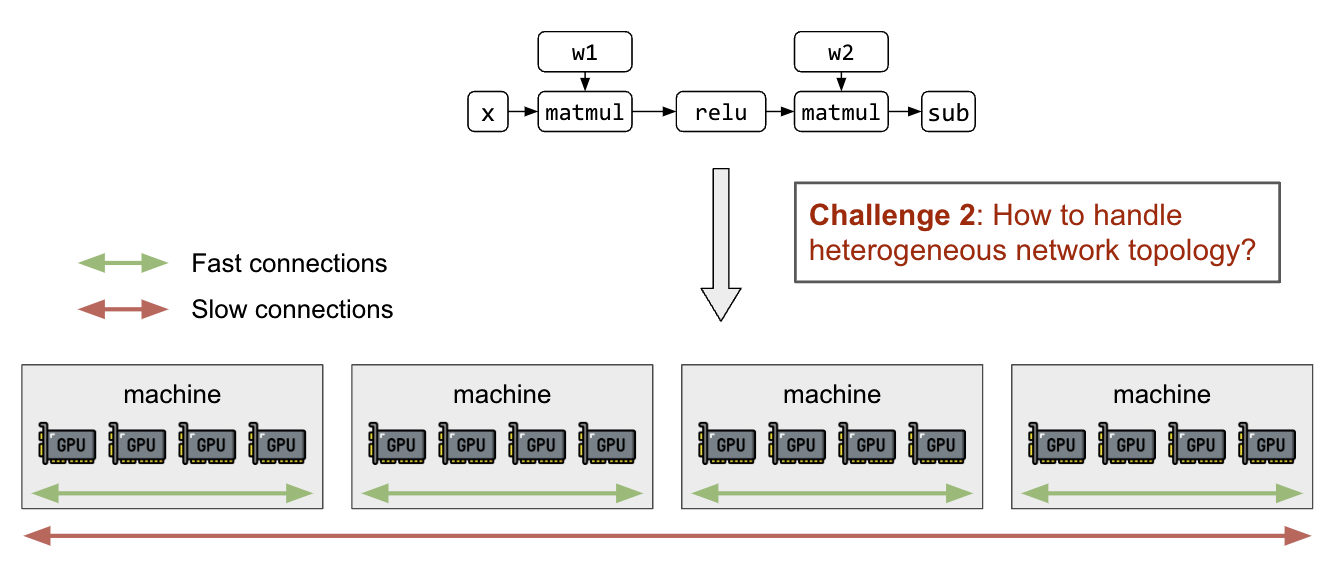
除了分區矩陣和計算圖之外,還需要能夠在了解異構網絡拓撲的情況下將分區映射到 GPU 設備。節點內部的 GPU 連接( NVIDIA NVLink) 比主機間聯網快幾個數量級嗎 (InfiniBand、 EFA 、以太網),并將導致不同分區策略之間的顯著性能差異。
之前的 LLM 分區工作
先前在模型并行領域的工作已經實現了不同的并行技術(圖 3 )。如上所述,確定和執行最佳模型分區策略是一個手動過程,需要深入的領域專業知識
Alpa 通過一行裝飾器自動處理互操作器和操作器內并行性。這為大規模 LLM 的數據、張量和流水線并行性無縫地設計了一種分區策略。 Alpa 還能夠推廣到廣泛的模型體系結構,這大大簡化了模型并行性,使 LLM 更容易被每個人訪問。
體系結構概述
在使用分層技術堆棧描述這些挑戰的解決方案之前,重要的是提供堆棧關鍵組件的體系結構概述(圖 3 )。這些組件包括位于底部的 GPU 加速器,然后是編譯和運行時層、 GPU ‘管理和編排、自動模型并行化( Alpa ),最后是位于頂部的模型定義。

Alpa 簡介
Alpa是一個統一的編譯器,它可以自動發現并執行最佳的互操作程序和操作程序內并行性 深度學習模型。
Alpa 的關鍵 API 是一個簡單的@alpa.parallelizedecorator ,用于自動并行化和優化最佳模型并行策略。給定具有已知大小和形狀的 JAX 靜態圖定義train_step一個樣本批次足以捕獲自動分區和并行化所需的所有信息。考慮下面的簡單代碼:
@alpa.parallelize
def train_step(model_state, batch):
def loss_func(params):
out = model_state.forward(params, batch["x"])
return np.mean((out - batch["y"]) ** 2)
grads = grad(loss_func)(state.params)
new_model_state = model_state.apply_gradient(grads)
return new_model_state
# A typical JAX training loop
model_state = create_train_state()
for batch in data_loader:
model_state = train_step(model_state, batch)
Alpa 中的自動并行通行證
Alpa 引入了一種獨特的方法來處理兩級層次系統的復雜并行策略搜索空間。傳統的方法一直在努力尋找一種統一的算法,該算法從互操作器和操作器內選項的巨大空間中導出最佳并行策略。 Alpa 通過在不同級別解耦和重組搜索空間來應對這一挑戰。
在第一個層次上, Alpa 搜索最有效的互操作并行計劃。然后,在第二個層次上,推導出互操作并行計劃每個階段的最佳操作內并行計劃。
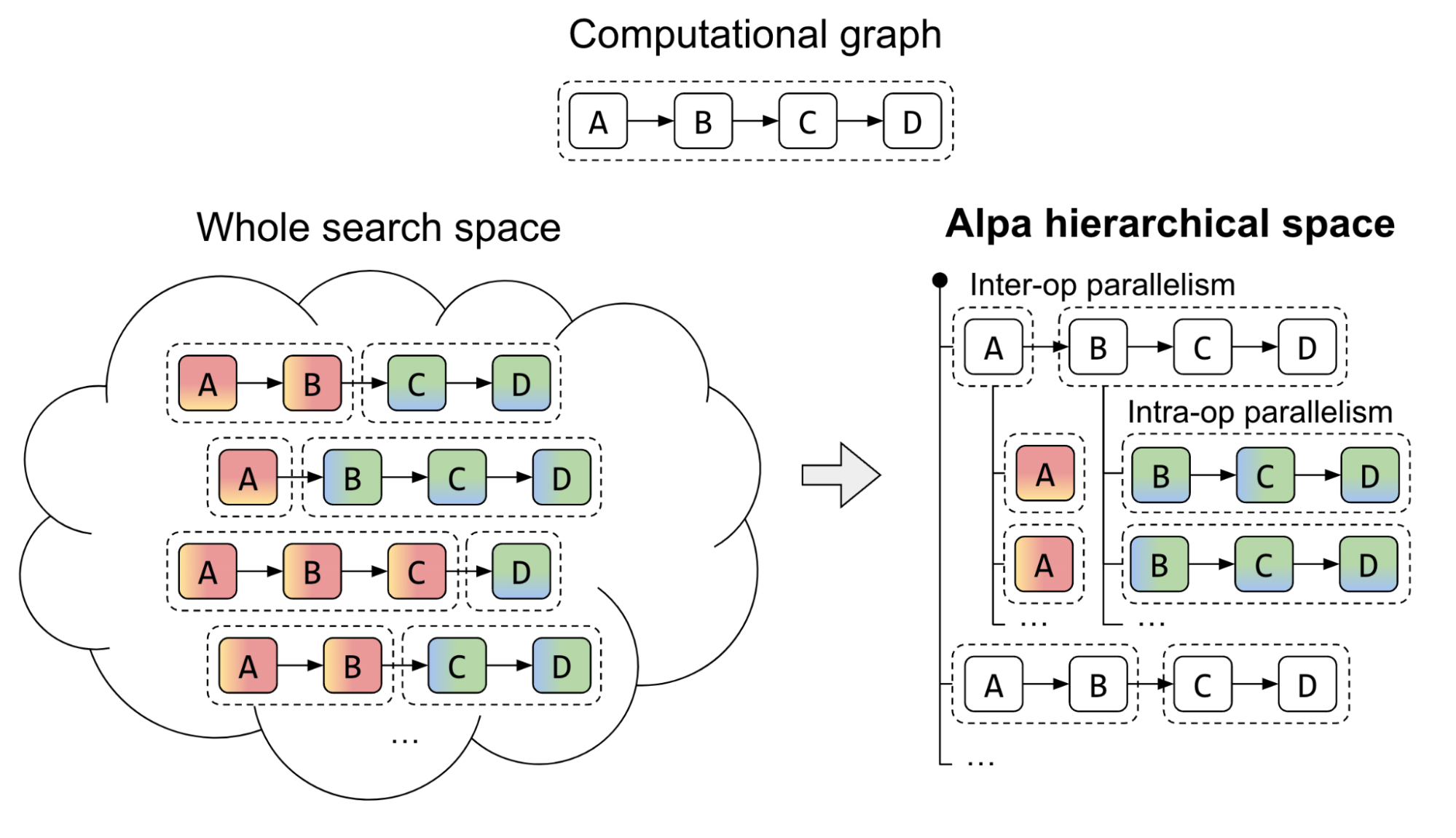
Alpa 編譯器是圍繞前面介紹的搜索空間分解方法構建的。它的輸入包括一個計算圖和一個集群規范。為了優化并行策略, Alpa 進行了兩次編譯:
- 第一次通過: Interoperator 使用動態編程來確定最合適的互操作并行策略。
- 第二次通過:操作員內部使用整數線性規劃來確定最佳的操作員內部并行策略
優化過程是分層的。更高級別的互操作過程多次調用更低級別的操作過程,根據操作過程的反饋做出決策。然后,運行時編排過程執行并行計劃,并將策略付諸實踐。
在下一節中,我們將討論 Ray ,它是 Alpa 構建的分布式編程框架。這將展示 GPU 集群虛擬化和管道并行運行時編排是如何實現的,以大規模地增強 LLM 。
Ray 簡介
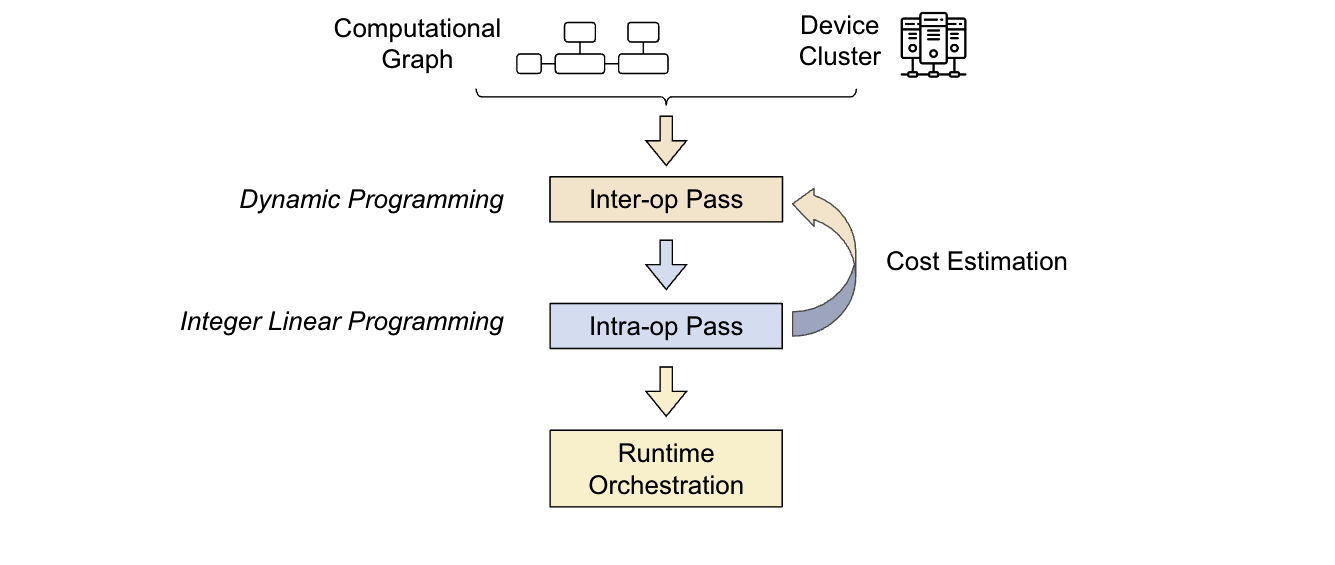
Ray是一個通用的統一框架,用于擴展和簡化 ML 計算。出于本討論的目的,您應該注意兩個關鍵的 Ray 基元:tasks and actors.
射線任務
Ray 任務是無狀態的,當使用@ray.remote可以調度 Ray 任務以在機器集群中的任何地方執行。調用,通過f.remote(args),是并行執行的,本質上是異步的。它們返回一個未來的對象引用,其值使用ray.get(object_ref).

射線演員
Ray actor 是一個 Python 類,它是有狀態的。它是 Ray 中的一個基本構建塊,使類能夠在集群中遠程執行,并保持其狀態。在眾多 GPU 設備上利用 Ray 演員可以訪問各種引人注目的功能
例如,當處理一個有狀態類時,開發人員可以運行一個首選的客戶端,比如XLA運行時或 HTTP 。 XLA 是線性代數的編譯器,它支持 JAX 和 TensorFlow 。 XLA 運行時客戶端可以優化模型圖并自動融合各個操作員。
使用射線模式和基元作為高級抽象
有了這些簡單的 Ray 基元,例如 Ray 任務和演員,就可以制定一些簡單的模式。以下部分將揭示如何使用這些基元來構建高級抽象,如 DeviceMesh 、 GPU Buffer 和 Ray Collective ,以大規模增強 LLM 。
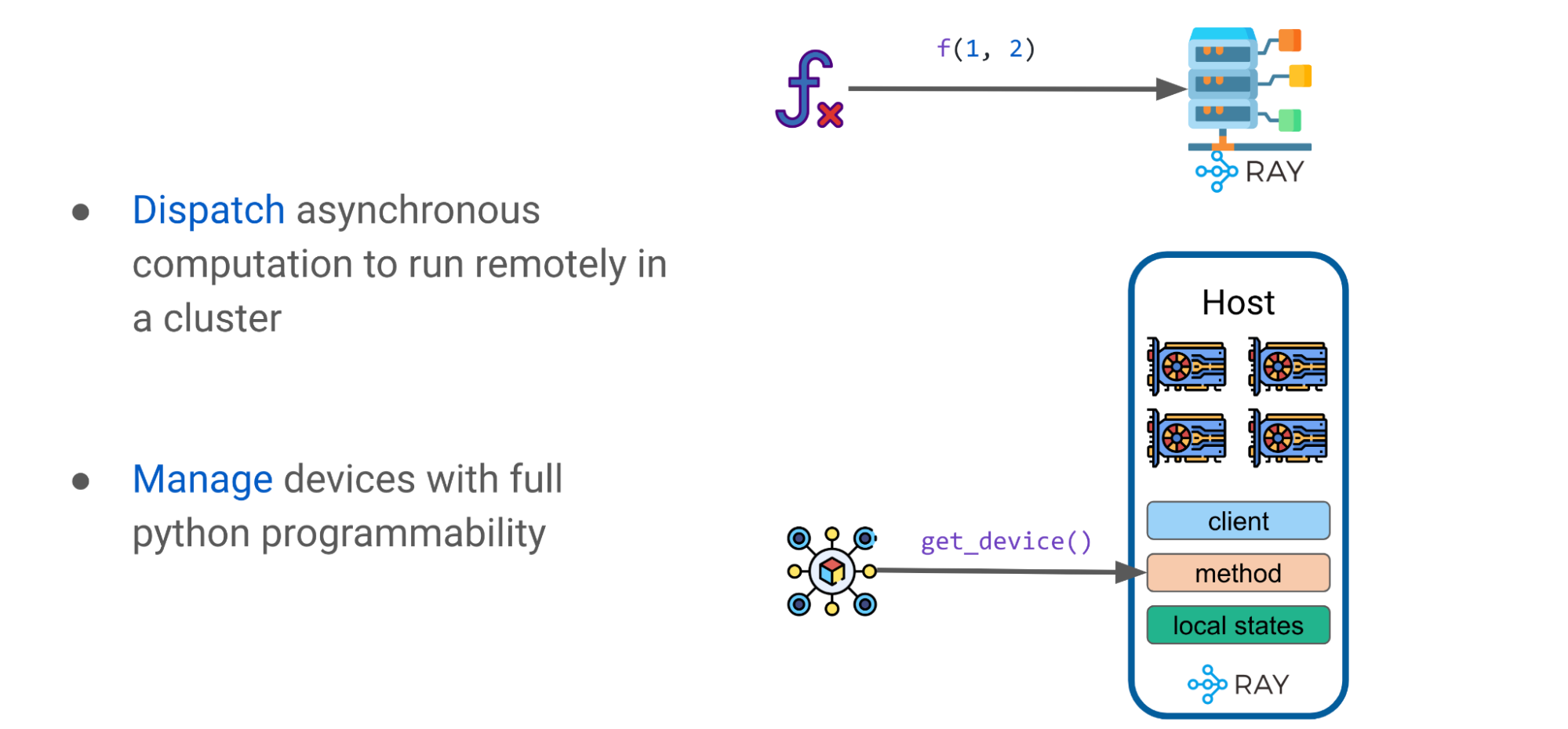
高級模式: DeviceMesh
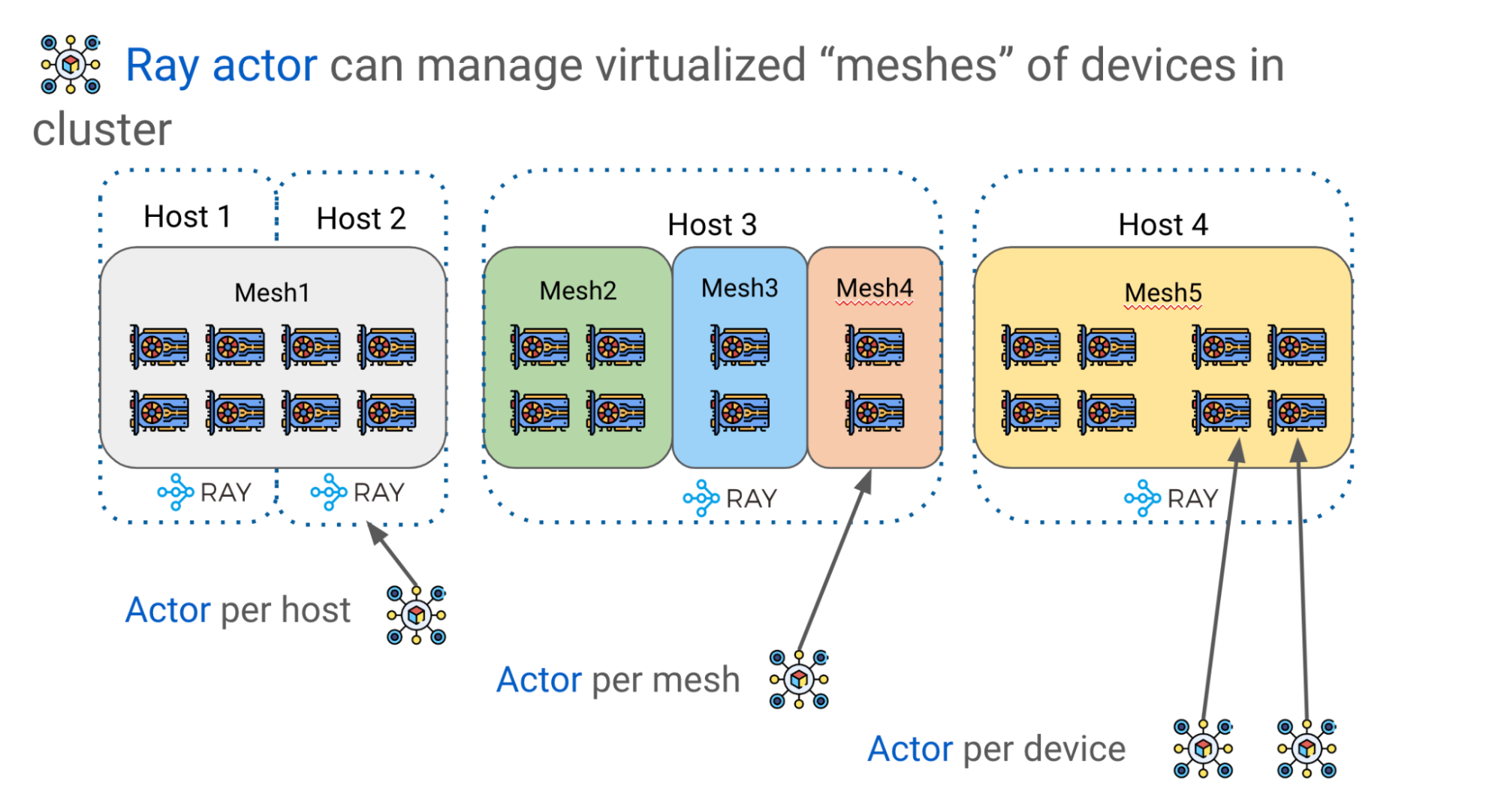
如前所述,有效地縮放 LLM 需要在多個 GPU 設備上進行分區模型權重和計算。 Alpa 使用 Ray actors 創建更高級的設備管理抽象,如 DeviceMesh ,一個由 GPU 設備組成的二維網格(圖 8 )。
邏輯網格可以跨越多個物理主機,包括它們的所有 GPU 設備,每個網格獲取同一主機上所有 GPU 的切片。多個網格可以位于同一主體上,一個網格甚至可以包含整個主體。 Ray actors 在管理集群中的 GPU 設備方面提供了巨大的靈活性
例如,根據所需的編排控制級別,可以選擇每個主機、每個網格或每個設備有一個參與者。
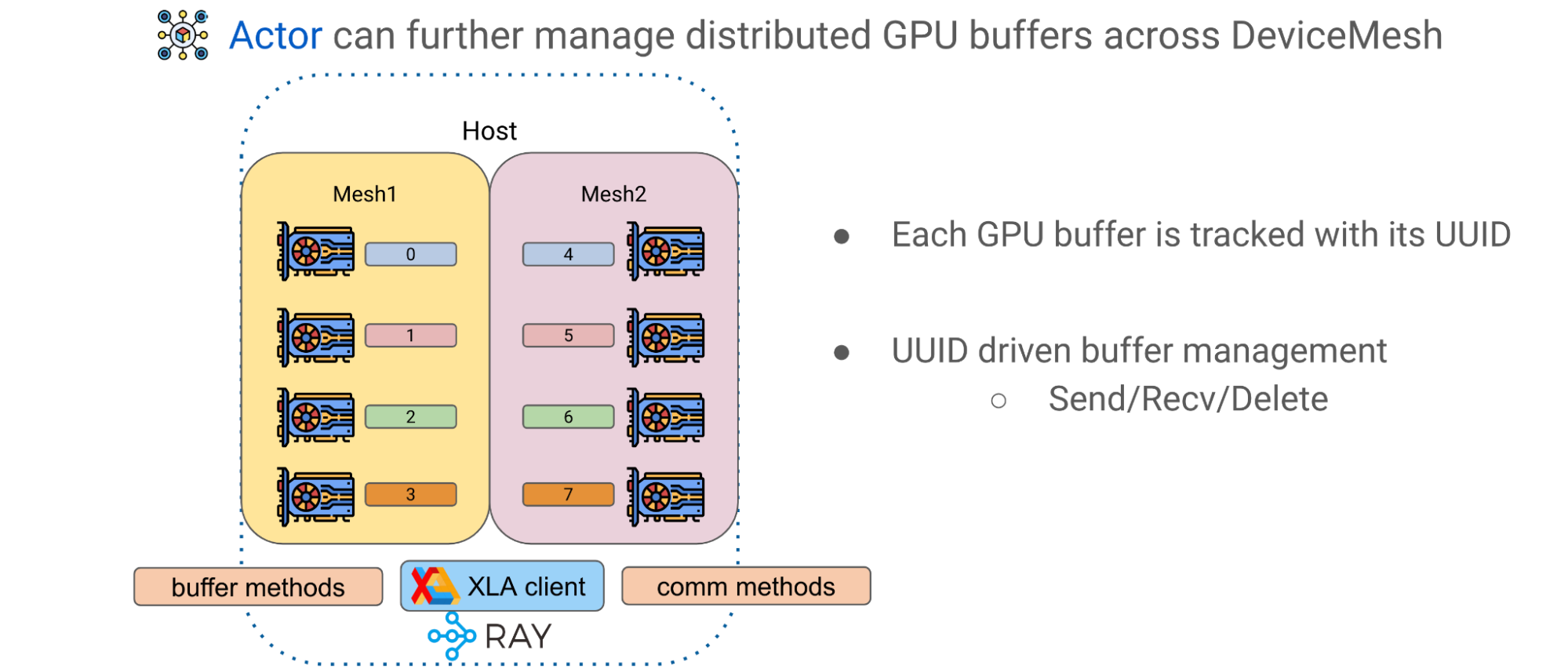
高級模式: GPU 緩沖
Alpa 中的第二個高級模式是跨 DeviceMeshes 的 GPU 緩沖區管理。 GPU 計算通常產生表示較大矩陣的瓦片的 GPU tensors 。 Alpa 有一個應用級 GPU 緩沖區管理系統,該系統為每個 GPU ‘緩沖區分配 UUID ,并提供基本原語,如發送/接收/刪除,以實現跨網格張量移動和生命周期管理
使用 Ray actor 和 DeviceMesh 抽象,可以通過調用主機上的相應方法來管理和傳輸緩沖區,以促進高級模型訓練范式。
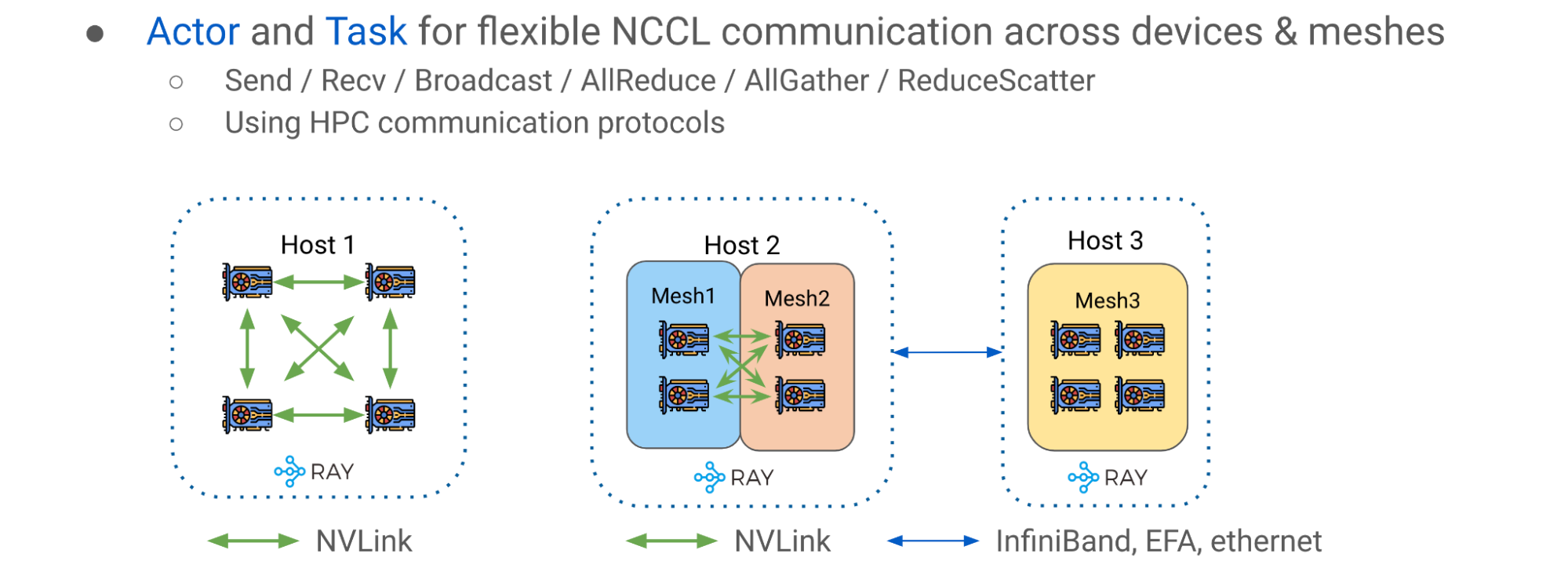
高級模式: Ray 集體通信庫
第三種高級模式是Ray collective communication library,一組通信原語,能夠在不同的 CPU 、 GPU 和 DeviceMeshes 之間進行高效靈活的張量移動。它是實現流水線并行的重要通信層
簡單的主機內情況如圖 10 (主機 1 )左側所示,其中 GPU 設備與 NVlink 互連。圖 10 的右側(主機 2 和 3 )顯示了多網格、多主機場景,其中通信發生在一個潛在的更異構的設置中,該設置混合了主機內 NVLink 和主機間網絡( InfiniBand 、 EFA 或以太網)。
使用 Ray 集體通信庫,您可以通過與NVIDIA Collective Communications Library( NCCL )
管道并行運行時編排
在 JAX 和 Alpa 中,計算、通信和指令通常被創建為靜態的。靜態工件是一個重要的屬性,因為在 JAX 中,用戶程序可以被編譯為中間表示( IR ),然后被饋送到XLA作為一個自包含的可執行文件。用戶可以將輸入傳遞到可執行文件中,并期望結果作為輸出,其中所有張量的大小和形狀都是已知的,就像張量的函數一樣。
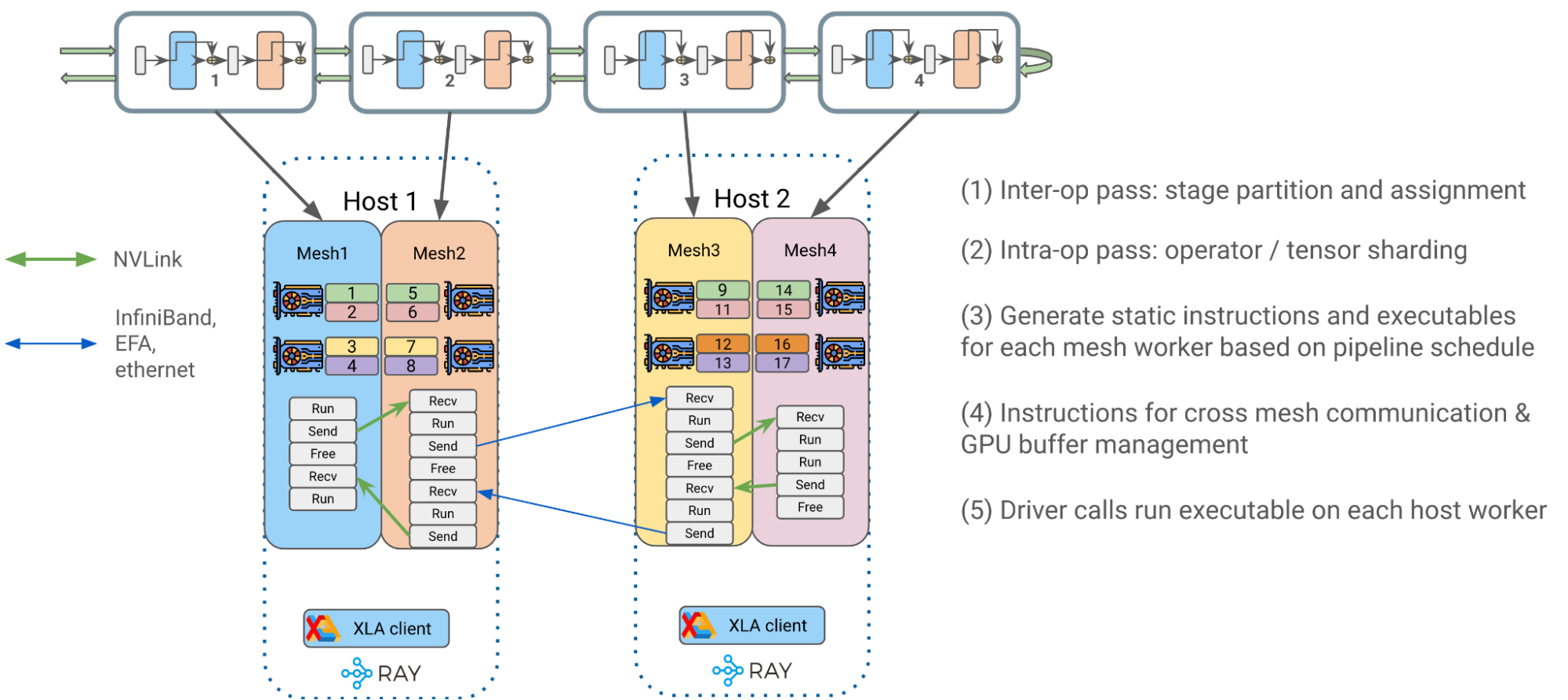
端到端流程大致可分為以下幾個階段:
- 操作員間并行通過:Alpa 將 transformer 塊最佳地劃分為單獨的流水線級,并將它們分配給各自的 DeviceMesh
- 操作員內部并行通行證: Alpa 將居住在同一主機上的 GPU 設備的操作員輸入和輸出矩陣與GSPMD.
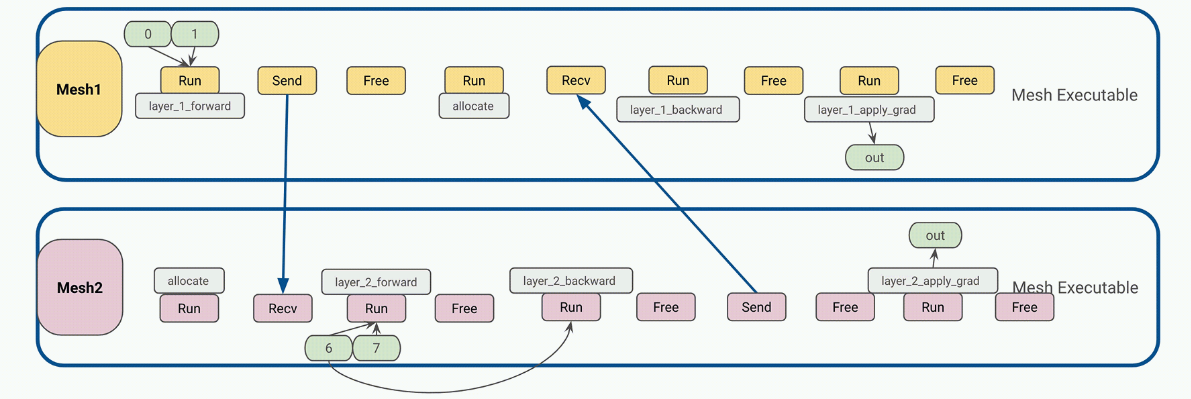
- 為網格工作者生成靜態指令:為每個 DeviceMesh 編譯一個關于用戶配置(如管道計劃)的靜態可執行文件 (1F1B,GPipe) 、微聚集、梯度積累等等。
- 每條指令都是一個獨立的 JAX HLO / XLA 程序,可以是 RUN 、 SEND 、 RECV 或 FREE 類型。每個都可以在 DeviceMesh 上分配、傳輸或釋放 GPU 緩沖區。
- 靜態指令大大降低了 Ray 單控制器級別的調度頻率和開銷,從而獲得更好的性能和可擴展性。
- 將編譯后的可執行文件放入相應的主機 Ray actor 中,以便稍后調用。
4 .驅動程序在每個主機工作程序上調用并編排已編譯的可執行文件,以開始端到端流水線 transformer 訓練。
Alpa on Ray 基準測試結果
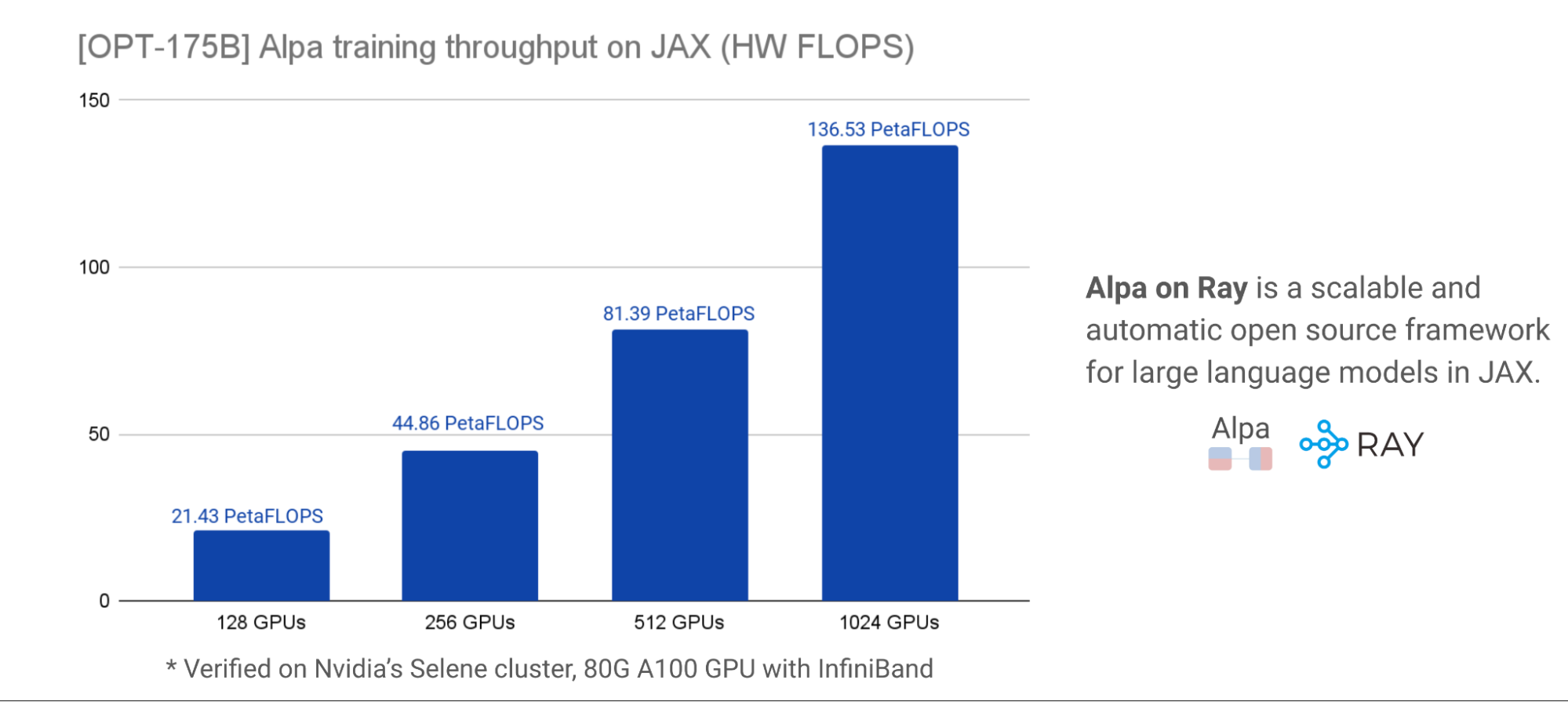
我們與 NVIDIA 密切合作,對這項工作進行了基準測試,以獲得準確的性能和可擴展性結果。對于可擴展性和性能,下面的圖表在NVIDIA Selene集群,展示了OPT-175B使用不同的 GPU 簇大小,在每個 GPU ~ 179 個 TFLOP 時, HW FLOP 的峰值利用率約為 57 . 5% 。模型并行化和分區是用一行裝飾器自動完成的。
這些基準測試結果有力地表明, Alpa-on-Ray 是在 JAX 中訓練 LLM 模型的最具性能和可擴展性的框架之一,即使規模為 1750 億。此外, Alpa-on-Ray 能夠自動找到并執行最佳并行化策略。
圖 13 提供了有關模型定義和用于實現結果的其他配置的更多詳細信息。
總結
結合 Alpa 和 Ray OSS 框架,開發人員可以在 JAX 上的大型集群中高效地擴展 LLM 培訓。使用 Alpa 自動編譯您的網絡體系結構,并使用 Ray 在機器集群中協調和運行您的任務。
我們的團隊估計將添加以下功能,以使用戶具有更高的性能和靈活性:
- 在更大范圍內支持具有 bf16 +管道并行性的 T5 。我們已經在容量限制范圍內啟用了四主機規模并進行了基準測試。
- 進一步簡化了商品的 LLM 可訪問性 GPU
額外資源
想要更多關于 Ray 、 Ray AIR 和 Ray on Alpa 的信息嗎?
- 學How Ray Solves Common Production Challenges for Generative AI Infrastructure.
- 退房Ray on GitHub來源和更多信息。
- 探索Ray documentation.
- 每月加入Ray Meetup討論所有的事情雷。
- 連接Ray community.
- 注冊Ray Summit 2023.
想了解更多關于 Alpa 的信息嗎?
- 退房Alpa on GitHub以獲取 LLM 訓練和推理的最新示例。
- 連接Alpa community on Slack.
鳴謝
感謝我們的團隊AWS和CoreWeave感謝他們對我們在NVIDIA A100 Tensor Core GPUs以促進我們的互動發展。我們也感謝 NVIDIA 的內部NVIDIA Selene集群訪問,以進行大規模的基準測試,并在整個合作過程中與我們合作
?