生成式 AI 具有創建全新內容的能力,這是傳統機器學習(ML)方法難以實現的。在自然語言處理(NLP)領域, 大型語言模型(LLMs) 的出現特別催生了許多創新和創造性的 AI 應用案例,包括客戶支持聊天機器人、語音助手、文本摘要和翻譯等——這些任務以前由人類處理。
LLMs 通過各種方法不斷發展,包括增加參數數量和采用 Mixture of Experts (MoE) 等新算法。預計許多行業 (包括零售、制造和金融) 都會應用和調整 LLMs。
然而,許多目前在 LLM 排行榜上名列前茅的模型在非英語語言(包括日語)方面表現出的理解和性能不足。其中一個原因是訓練語料庫包含大量英語數據。例如, GPT-3 語料庫中只有 0.11%是日語數據 。創建在日語(日語的訓練數據比英語少)中表現良好的 LLM 模型極具挑戰性。
本文介紹了在 生成式 AI 加速器挑戰賽(GENIAC) 項目中訓練具有 172 億個參數的 AI 模型時獲得的見解,該項目使用 NVIDIA Megatron-LM 幫助解決用于日語理解的高性能模型短缺問題。
GENIAC 上的 LLM-JP 計劃?
經濟產業省(METI) 為了提高日本的平臺模型開發能力水平,并鼓勵企業等發揮創造力,啟動了 GENIAC。GENIAC 提供了計算資源,支持了與企業和數據持有者的匹配,促進了與全球技術公司的合作,舉辦了社區活動,并對已開發的平臺模型的性能進行了評估。
LLM-jp 項目旨在開發一個 完全開放的模型,擁有 172 億個參數 (可在 Hugging Face 上獲取),并具備強大的日語能力。 LLM-jp 172B 是當時日本最大的模型開發項目 (2024 年 2 月至 8 月),廣泛分享其開發知識具有重要意義。
LLM-jp 是自然語言處理和計算機系統領域的研究人員 (主要是 NII) 發起的一項計劃,旨在通過持續開發完全開放的商用模型,積累有關訓練原理的數學闡明的專業知識,例如大型模型如何獲得泛化性能和學習效率。目標是積累有關訓練效率的專業知識。
使用 NVIDIA Megatron-LM 訓練模型?
Megatron-LM 是一種輕量級的研究型框架,利用 Megatron-Core 以前所未有的速度訓練大型語言模型(LLMs)。Megatron-Core 是一個開源庫,包含了 GPU 優化技術和大規模訓練所必需的尖端系統級優化。
Megatron-Core 支持各種高級模型并行技術,包括張量、序列、流水線、上下文和 MoE 專家并行。此庫提供 可定制的構建塊 、訓練彈性功能(例如 快速分布式檢查點 )以及許多其他創新,如 基于 Mamba 的混合模型訓練 。它與所有 NVIDIA Tensor Core GPU 兼容,并支持 Transformer Engine(TE), NVIDIA Hopper 架構 引入了 FP8 精度。
模型架構和訓練設置?
表 1 概述了該項目的模型架構,該架構遵循 Llama 2 架構 。
| 參數 | 價值 |
| 隱藏尺寸 | 12288 |
| FFN 中間尺寸 | 38464 |
| 層數量 | 96 |
| 注意力頭數量 | 96 |
| 查詢組數量 | 16 |
| 激活函數 | SwiGLU |
| 位置嵌入 | RoPE |
| 歸一化 | RMS 規范 |
LLM-jp 172B 模型正在使用為該項目開發的多語種語料庫中的 2.1 萬億個令牌從頭開始訓練,該語料庫主要由日語和英語組成。訓練使用 NVIDIA H100 Tensor Core GPU 在 Google Cloud A3 實例上執行,并使用 Transformer Engine 進行 FP8 混合訓練。實驗中使用了 Megatron-Core v0.6 和 Transformer Engine v1.4。
表 2 顯示了用于訓練的超參數設置。
| 參數 | 值 |
| LR | 1E-4 |
| 最小 LR | 1E-5 |
| LR 熱身迭代器 | 2000 |
| 權重衰減 | 0.1 |
| 研究生剪輯 | 1.0 |
| 全局批量大小 | 1728 |
| 上下文長度 | 4096 |
此外,還整合了 PaLM 中使用的 z-loss 和 batch-skipping 技術,以穩定訓練過程,并使用 flash attention 進一步加速訓練過程。
要查看其他訓練配置,請參閱 llm-jp/Megatron-LM 。
訓練吞吐量和結果?
最新的 LLM-jp 172B 模型的預訓練目前正在進行中,每隔數千次迭代就會進行定期評估,以監控訓練進度,并確保日語和英語下游任務的準確性成功(圖 1)。到目前為止,在目標 2.1 萬億個令牌中,已經完成了 80%以上。

值得注意的是,在大約 7,000 次迭代后,TFLOP/s 急劇增加,這與從 BF16 到 FP8-hybrid 精度的過渡相對應。在本實驗中,在 7,000 次迭代之前,使用 BF16 和 TE 進行訓練,在 7,000 次迭代之后,使用 FP8-hybrid 和 TE。在 Megatron-LM 中,可以使用簡單的選項 --fp8-format‘hybrid‘啟用混合 FP8 訓練。請注意,此功能是實驗性功能,不久后將會進行進一步優化。
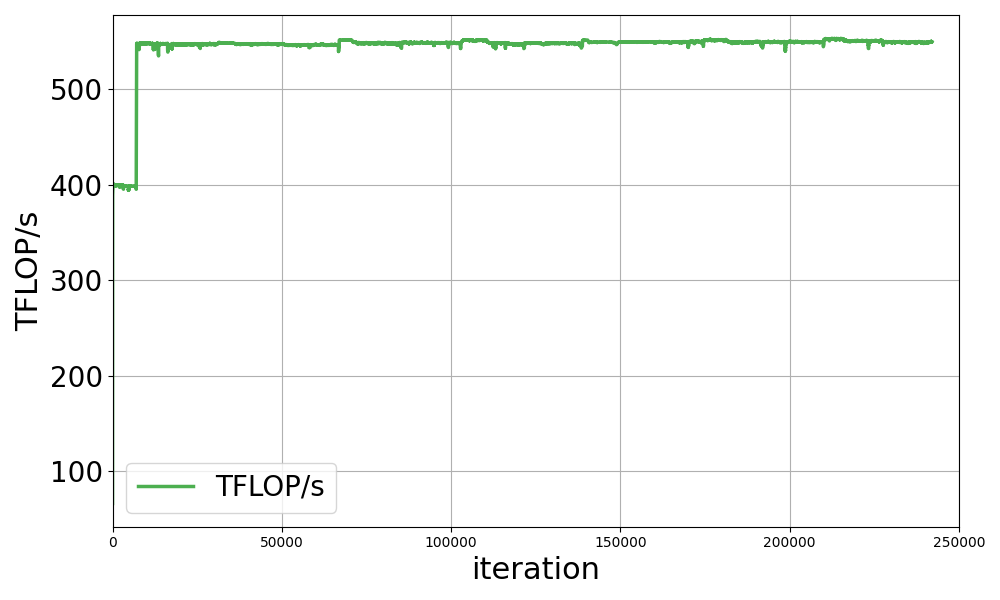
我們開始使用 BF16 和 TE 訓練,然后切換到 FP8 混合,不僅是為了查看 BF16 和 FP8 之間的 tokens/sec 性能差異,也是為了使初始訓練更加穩定。在訓練的早期階段,由于熱身,學習率(LR)增加,導致訓練不穩定。
我們選擇使用 BF16 執行初始訓練,在確認訓練損失、優化器狀態、梯度范數等值沒有問題后,我們切換到 FP8 以加速訓練過程。FP8 混合提高了訓練速度。我們觀察到使用 Megatron-LM 的訓練速度為 545-553 TFLOP/s。

結束語?
如上所述,LLM-jp 172B 的訓練仍在使用 Megatron-LM 進行中。根據使用當前檢查點數據對下游任務的評估結果,我們認為該模型已經具備出色的日語能力,但完整的模型預計將于明年初準備就緒。在需要大量數據集的 LLM 預訓練中,訓練時間通常是一項重大挑戰。因此,像 Megatron-LM 這樣的高效訓練框架對于加速生成式 AI 研究和開發至關重要。對于使用 Megatron-LM 訓練的 172B 模型,我們探討了 FP8-hybrid 訓練作為提高訓練速度的潛在方法,訓練速度從 400 TFLOP/s 提高到 550 TFLOP/s,提高了 1.4 倍。我們觀察到性能加速從 400 TFLOP/s 到 550 TFLOP/s,這表明 FP8-hybrid 可能是提高大規模模型預訓練效率的一種有價值的方法。
?