最近,瑞典一家大型銀行利用 NVIDIA GPU 訓練生成式對抗神經網絡(GAN),將其納入其防范欺詐和洗錢的策略中。金融欺詐和洗錢對金融機構和社會構成了巨大挑戰,金融機構在識別和預防可疑及非法活動方面投入了大量資源。根據報告,大型機構通過使用 AI 進行欺詐檢測,在一年內節省了約 1.5 億美元。

識別金融欺詐和洗錢的現有方法依賴于人工設計的規則數據庫,這些規則與金融交易中的可疑模式相匹配。隨著新計劃的識別,新規則會添加到規則庫中。
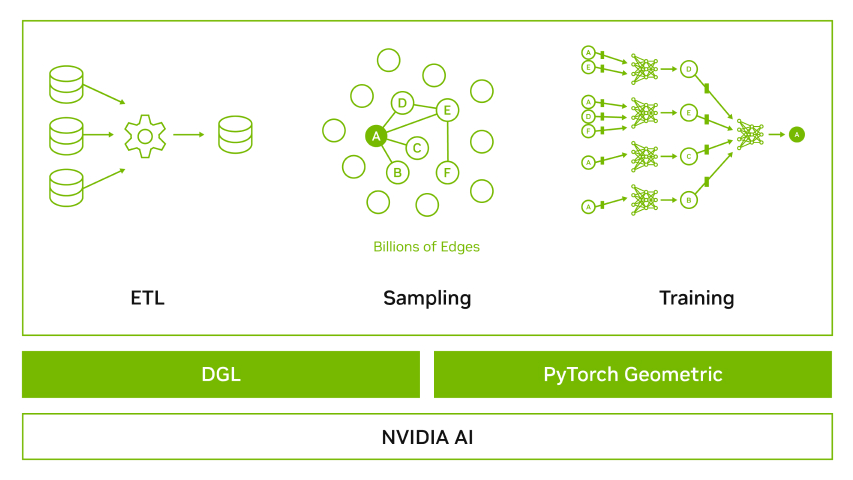
瑞典銀行針對這些問題開發了新的解決方案,在 GPU 上結合使用深度學習技術,從而生成用于識別可疑活動的先進解決方案。這種方法是通過 GAN 進行異常檢測,以半監督式方式對問題建模。該解決方案需要軟件和硬件,可以擴展以處理和訓練基于大量數據的模型。Hopsworks 基于大小高達 40 TB 的數據集訓練模型。為此,我們使用 Hopsworks 軟件平臺,NVIDIA V100 GPU 大規模設計功能,并使用多個 GPU 并行高效訓練 GAN。
基于規則與基于模型的欺詐檢測
現有的識別欺詐和洗錢的方法依賴于人工設計的規則數據庫,這些數據庫試圖匹配表明欺詐的模式。隨著新的欺詐計劃的識別,新的規則被添加到規則引擎中。例如,在洗錢中,存在眾所周知的模式,即在許多賬戶中進行洗錢,然后在中心使用雷達不到的小筆交易匯總這些資金,以便日后支出。
在“Rules-Based Fraud Detection code example”(基于規則的欺詐檢測代碼示例)中,您可以看到識別可疑金融交易的基于規則的方法。在這里,您定義了適用于所有金融交易的大量規則。如果交易符合任何規則,則觸發警報。如果警報被錯誤觸發(誤報),則會產生成本。如果未觸發任何警報,但應該觸發(誤報),則您必須設計新規則來識別欺詐計劃。公司維護這些規則數據庫,并定期向客戶發送更新。
Rules-Based Fraud Detection
# Rule 1
IF transfersLastDay > 10 && amount > $5k
THEN
alert
END
# Rule 2
IF country is LISTED && amount > $1k
THEN
alert
END
…
# Rule N
… Train Fraud Detection Model
dataset=tf.data(“financial_transactions”)
model = …
model.compile(…)
model.fit(dataset, …)
Detect Fraud with Model
IF model.predict(amount,transfersLastDay,
country, ….) == TRUE
THEN
alert
END給定足夠的歷史金融交易數據,基于模型的方法比基于規則的方法更擅長模式匹配,因為它們可以泛化為學習欺詐方案,就像現有的欺詐方案一樣。在“Train Fraud Detection Model”(訓練欺詐檢測模型)代碼示例中,您可以看到,您必須首先整理已標記的訓練數據集:financial_transactions.借助該數據集,您可以訓練模型,然后將經過訓練的模型用于新的金融交易,以預測它們是否是欺詐或非欺詐。如果金融交易被懷疑存在欺詐,系統會發送警報。
GAN 是金融欺詐預測的自然選擇,因為它們可以從歷史數據中學習合法交易的模式。對于每筆新的金融交易,模型都會計算異常分數;分數高的金融交易被標記為可疑交易。
GAN 在生產環境中的訓練和部署相當具有挑戰性,它們需要大量的 GPU 資源、并行超參數搜索,以及分布式訓練的支持。這一過程必須非常謹慎,并且需要高級的機器學習經驗。其中一個 GAN 的實現是基于使用同步編碼器訓練從受污染圖像數據中進行異常檢測的無監督學習,該研究描述了一種異常檢測架構,它能夠容忍少量錯誤標記的樣本,并支持并行編碼器的訓練。
使用實體和交易的圖形表示來理解欺詐
要檢測欺詐模式并觸發警報,您可以使用圖形和表格特征以及前面介紹的基于 DL 的 GAN 技術。圖形由節點(也稱為頂點)和邊緣(也稱為弧形)組成。在金融應用中,圖形可以對企業和個人的事務交互進行建模。
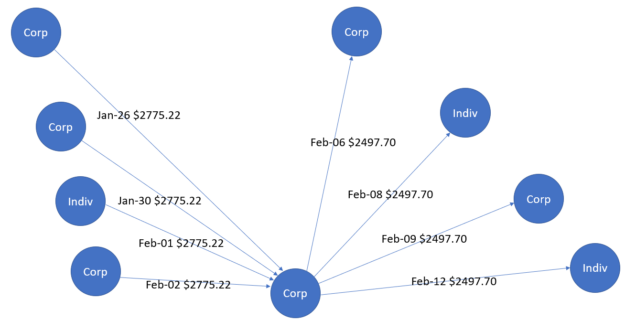
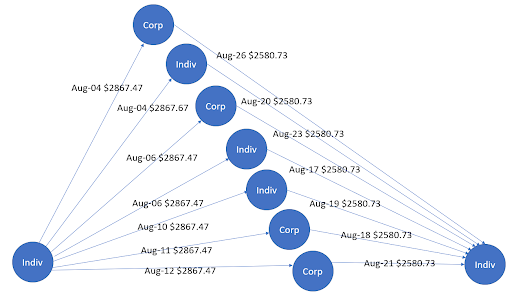
為了展示圖形的效用,我們舉個例子。用不同的標題標記企業和個人:企業標記為“公司”,個人標記為“Indiv”。邊緣用于表示具有關聯日期和金額的交易,箭頭表示交易方向。
有多種預期圖形模式,例如正常散布模式(也稱為公英),會在組織支付薪酬時發生。這種模式發生在特定日期,薪酬相對固定,資金流從單個支付者流出。異常散布模式是指交易的突然爆發,這在以前參與節點或雙向資金流中從未見過。
圖 1 顯示了收集 – 散布模式,即資金最初在 1 月流入中心節點。這些資金隨后在 2 月流出到其他節點。在洗錢領域,這種收集 – 散布模式用于隱藏金融機構的資金分配情況。同樣,圖 2 顯示了在不同日期再次具有雙向資金流的散布 – 收集模式。在這種情況下,資金的來源和目的地是兩個不同的中心實體。
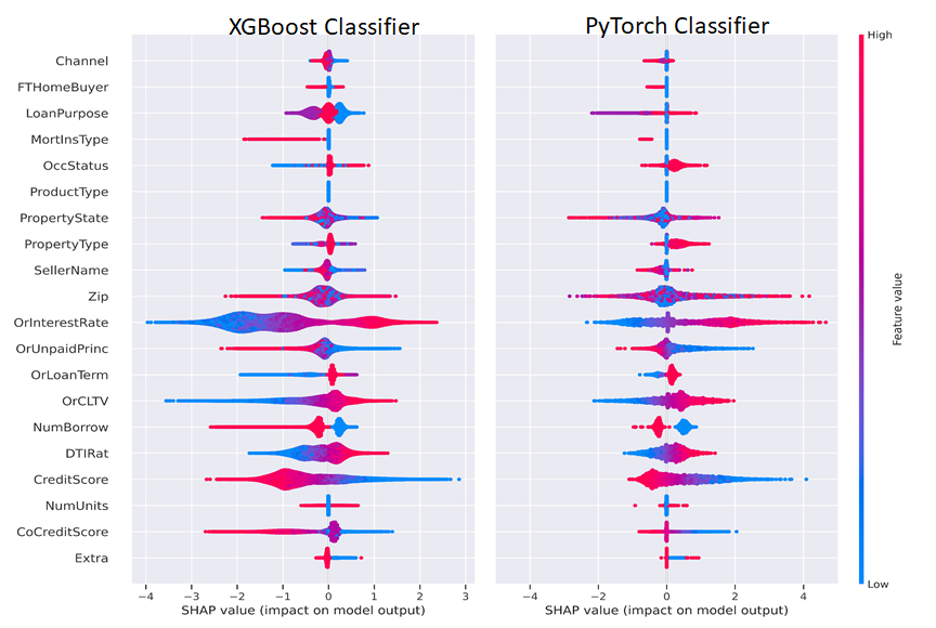
基于 DL 的 GAN 方法基于表格特征和圖形特征,可以檢測此類欺詐模式,其中一個示例基于在 NVIDIA GPU 上使用 Hopsworks.此類方法與基于規則的技術并存,以獲得更好的結果、準確性和混淆矩陣。
將欺詐建模為二進制分類問題所面臨的挑戰
圖 3 顯示了金融欺詐二進制分類器的混淆矩陣。對于洗錢等問題,應大幅提高假陰性的權重。使用 F1 分數的變體來評估模型:精度、召回和輻射的權重不應相等。
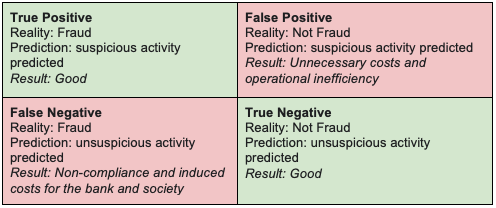
在檢測洗錢模式方面還有其他挑戰:
- 嚴重的類別不平衡:被標記為可疑的交易可能不到歷史交易總數的 0.0001%。
- 非平穩性:不斷有人發明新的洗錢計劃。為了識別新出現的模式,相關技術必須能夠自我調整或易于調整。
Logical Clocks,開源 Hopsworks 平臺的開發者,已發布一個用于檢測欺詐的完整端到端開源示例。
- 金融交易的原始數據集樣本
- 特征工程程序,用于計算圖形嵌入等復雜特征,并將其存儲在特征存儲中
- 用于查找 GAN 良好超參數的 Notebook
- 使用多個 GPU 對 GAN 進行分布式訓練。
代碼可以在任何 Hopsworks 集群 上運行,包括 AWS 和 Microsoft Azure 上提供的托管 Hopsworks 集群,以及在本地使用 NVIDIA GPU 安裝的 Hopsworks。Hopsworks 集群能夠管理多達數千個 GPU,并可按需分配給應用程序。
用于加速金融數據科學的 NVIDIA GPU
在大量客戶記錄中識別欺詐和洗錢是金融機器學習(ML)和深度學習(DL)的經典用例。由于需要數萬億次浮點運算(TOPS),因此應用 GPU 可顯著加速神經網絡訓練過程。許多數據科學家都知道 NVIDIA GPU 多年來一直在幫助 ML 訓練過程。
當神經網絡訓練完成且推理階段變得更加重要時,最近推出的開源軟件 NVIDIA Triton 推理服務器 可以幫助簡化和管理推理加速和生產模型部署。Triton 服務器可以作為 Docker 容器、在 bare metal 上運行,也可以在虛擬化環境中的虛擬機中運行。Hopsworks 支持在 使用 KFServing 的 Triton 服務器。
Hopsworks 支持使用 TensorFlow、PyTorch 和 Scikit-Learn 進行 ML/DL 訓練,并額外支持使用 TensorFlow 和 PyTorch 上的透明數據并行訓練、超參數調優和并行消融研究 Maggy。Hopsworks 適用于多 GPU、單節點系統以及多 GPU 系統集群。DGX A100 系統 現在是用于在 GPU 上進行分布式訓練的 AI 基礎設施的通用系統。每個 DGX A100 系統都提供以下配置:
- 8 塊 NVIDIA 100 Tensor Core GPU
- 80GB GPU 顯存,總計 640GB
- SXM (NVLink) 外形規格
- 與 NVIDIA NVLink 交換機 相關
- 分別為 5 petaFLOPS 或 10 petaOPS INT8
多 GPU、多節點 DGX A100 系統構成 Hopsworks 平臺上的 Superpod,可顯著加速 DL 訓練和推理工作負載。通過與 OEM 合作伙伴、系統集成商和增值經銷商的 NVIDIA 合作伙伴網絡 (NPN) 合作,您可以在 NVIDIA GPU 上實現類似的配置。
圖 4 展示了使用 Hopsworks 的 DL 系統架構,這些系統可以利用 TensorFlow 和 CollectiveAllReduceStrategy 進行數據并行分布式 GPU 訓練。Hopsworks 中支持的 Maggy 框架有助于簡化 TensorFlow 開發流程。 CollectiveAllReduceStrategy 通過使用 Spark 對分布式計算進行透明管理,在多 GPU、多節點系統上運行。大型集群還受益于使用 NVSwitch 的 GPU 互連。未來,我們還將看到使用 NVSwitch 的 NVIDIA Rapids.ai 框架和 Spark 在 GPU 上的應用。
在 NVIDIA 認證的多 GPU、多節點系統上使用 Hopsworks 優化分布式訓練
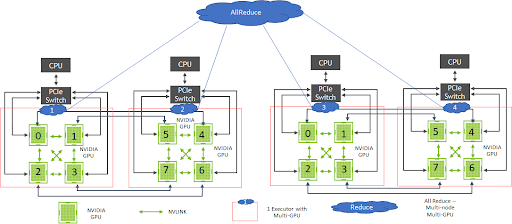
為了使用其他架構對經過訓練的模型進行推理, NVIDIA 通過 NVIDIA Triton 推理服務器框架支持多個推理工作負載、并發應用程序和 DL 模型實例,從而提高了 GPU 利用率。Hopsworks 客戶已使用 GAN、視覺和其他需要在 GPU 上進行大量分布式訓練的 DL 模型來開發尖端 AI 系統。
以下內容 LogicalClocks 中的端到端洗錢示例 在 DGX 系統上使用多 GPU、多節點框架上的設置訓練用于異常檢測的 GAN 模型。使用此類設置的訓練時間幾乎可以實現線性擴展,也稱為 強擴展 加速 DL 訓練。此外,使用 Triton 服務器框架進行此類模型的推理可以高效使用 GPU。
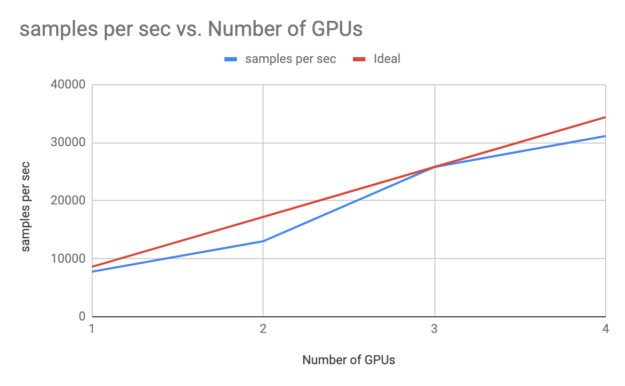
您還可以使用其他框架(包括 RAPIDS.ai、基于 GPU 的 Spark 和 NVIDIA GRAPH 框架 CuGraph)在 Hopsworks 平臺上的 GPU 上加速此類功能。
聯系我們
團隊合作是設計準確的金融欺詐和洗錢解決方案的關鍵。從基于規則的方法到基于模型的方法是一個常見的技術目標。其目標是減少金融機構在生產中使用欺詐檢測或洗錢模型時可能收到的錯誤分類結果的數量。如今,客戶期望其金融機構在預防欺詐和限制錯誤警報方面更準確。
如需了解更多信息以及分享您在此重要用例和先進方法方面的經驗,請在下方發表評論。
?