NVIDIA Jetson Orin 是同類中最優秀的人工智能工作負載嵌入式平臺。Orin 平臺的關鍵組件之一是第二代 Deep Learning Accelerator (DLA),這是一個專用的深度學習推理引擎,在 AGX Orin 平臺上提供了三分之一的人工智能計算能力。
這篇文章深入探討了使用 Orin 平臺的嵌入式開發人員如何使用 YOLOv5 作為參考。要了解 DLA 如何幫助最大限度地提高深度學習應用程序的性能的更多信息,請參閱 Maximizing Deep Learning Performance on NVIDIA Jetson Orin with DLA。
YOLOv5 是一種對象檢測算法。在 YOLOv3 和 YOLOv4 的成功基礎上,YOLOv5 旨在提高實時目標檢測任務的準確性和速度。YOLOv5 因其在準確性和速度之間的出色權衡而備受贊譽,成為計算機視覺領域研究人員和從業者的首選。其開源實現使開發人員能夠利用預先訓練的模型,并根據特定目標進行定制。
以下部分將介紹 end-to-end YOLOv5 cuDLA 示例,它將向您展示如何:
- 使用量化感知訓練(QAT)訓練 YOLOv5 模型,并將其導出以部署在 DLA 上。
- 使用 CUDA 到 TensorRT 和 cuDLA 部署網絡并運行推理。
- 執行目標 YOLOv5 準確性驗證和性能評測。
使用此示例,我們演示了如何使用 DLA INT8 在 COCO 數據集上實現 37.3 毫安時(官方 FP32 毫安時為 37.4)。我們還演示了如何在單個 NVIDIA Jetson Orin DLA 上獲得超過 400 FPS 的 YOLOv5。(Orin 上共有兩個 DLA 實例可用。)
DLA 的 QAT 培訓和出口
為了平衡 YOLOv5 的推理性能和準確性,在模型上應用量化感知訓練(QAT)是至關重要的。由于在撰寫本文時,DLA 不支持通過 TensorRT 的 QAT,因此有必要在推理之前將 QAT 模型轉換為訓練后量化(PTQ)模型。步驟如圖 1 所示。

QAT 培訓工作流程
使用 TensorRT pytorch-quantization 量化 YOLOv5。第一步是將量化器模塊添加到神經網絡圖中。此工具包提供 一套量化層模塊 用于常見的 DL 操作。如果某個模塊不在提供的量化模塊中,則可以為模型中的正確位置創建自定義量化模塊。
第二步是校準模型,獲得每個量化/去量化(Q/DQ)模塊的標度值。校準完成后,選擇一個訓練計劃,并使用 COCO 數據集對校準后的模型進行微調。

添加 Q/DQ 節點
有兩個選項可用于將 Q/DQ 節點添加到網絡中:
選項 1:根據建議,將 Q/DQ 節點放置在 TensorRT 處理 Q/DQ 網絡 中。該方法遵循用于 Q/DQ 層的 TensorRT 融合策略。這些 TensorRT 策略主要針對 GPU 推斷進行調整。要使其與 DLA 兼容,請添加額外的 Q/DQ 節點,這些節點可以使用 Q/DQ 翻譯器。
否則,任何丟失的標尺都會導致 FP16 中運行某些層。這可能導致 mAP 的輕微降低,并且可能導致大的性能下降。Orin-DLA 針對 INT8 卷積進行了優化,大約是 FP16 密集性能的 15 倍(或者當將密集 FP16 與 INT8 稀疏性能進行比較時為 30 倍)。
選項 2:在每一層插入 Q/DQ 節點,以確保所有張量都具有 INT8 標度。使用此選項,可以在模型微調期間獲得所有層的比例。然而,當在 GPU 上運行推理時,這種方法可能會潛在地破壞具有 Q/DQ 層的 TensorRT 融合策略,并導致在 GPU 上出現更高的延遲。另一方面,對于 DLA,PTQ 量表的經驗法則是,“可用量表越多,延遲就越低。”
實驗證實,我們的 YOLOv5 模型在 COCO 2017 驗證數據集上進行了驗證,分辨率為 672 x 672 像素。選項 1 和選項 2 的 mAP 得分分別為 37.1 和 37.0。
根據您的需求選擇最佳選項。如果您已經有了 GPU 的現有 QAT 工作流,并且希望盡可能多地保留它,那么選項 1 可能會更好。(您可能需要擴展 Q/DQ 轉換器,以推斷更多丟失的規模,從而實現最佳 DLA 延遲。)
另一方面,如果您正在尋找一種將 Q/DQ 節點插入所有層并與 DLA 兼容的 QAT 訓練方法,選項 2 可能是您最佳的。
Q/DQ 翻譯器工作流程
Q/DQ 翻譯器的目的是將用 QAT 訓練的 ONNX 圖翻譯為 PTQ 張量尺度和沒有 Q/DQ 節點的 ONNX 模型。
對于該 YOLOv5 模型,從 QAT 模型中的 Q/DQ 節點提取量化尺度。使用相鄰層的信息來推斷其他層的輸入/輸出比例,例如 YOLOv5 的 SiLU 中的 Sigmoid 和 Mul 或 Concat 節點。提取刻度后,導出不帶 Q/DQ 節點的 ONNX 模型和(PTQ)校準緩存文件,以便 TensorRT 可以使用它們來構建 DLA 引擎。
將網絡部署到 DLA 進行推理
下一步是部署網絡,并通過 TensorRT 和 cuDLA 使用 CUDA 運行推理。
帶有 TensorRT 的可加載構建
使用 TensorRT 構建可加載的 DLA。這為 DLA 可加載建筑提供了一個易于使用的界面,并在需要時與 GPU 無縫集成。有關 TensorRT – DLA 的更多信息,請參閱 Working with DLA 在 TensorRT 開發人員指南中。
trtexec 是 TensorRT 提供的一個方便的工具,用于構建發動機和基準測試性能。請注意,DLA 可加載文件是通過 DLA 編譯器成功編譯 DLA 的結果,并且 TensorRT 可以將 DLA 可裝載文件封裝在序列化引擎中。
首先,準備 ONNX 模型和上一節中生成的校準緩存。DLA 可加載文件可以使用單個命令構建。通過 — 安全的選項,整個模型可以在 DLA 上運行。這直接將編譯結果保存為可加載的串行 DLA(沒有 TensorRT 引擎)。有關此步驟的更多詳細信息,請參閱 NVIDIA 深度學習 TensorRT 文檔。
trtexec --onnx=model.onnx --useDLACore=0 --safe --saveEngine=model.loadable --inputIOFormats=int8:dla_hwc4 --outputIOFormats=fp16:chw16 --int8 --fp16 --calib=qat2ptq.cache
請注意,從性能的角度來看,如果您的模型輸入合格,強烈建議使用輸入格式 dla_hwc4。輸入最多必須有 四個輸入通道并被卷積消耗。在 INT8 中,DLA 可以從特定的硬件和軟件優化中受益,例如如果您使用 --inputIOFormats=int8:chh32。
使用 cuDLA 運行推理
cuDLA 是 DLA 的 CUDA 運行時接口,它是將 DLA 與 CUDA 集成在一起的 CUDA 編程模型的擴展。cuDLA 使您能夠使用 CUDA 編程構造并提交 DLA 任務。您可以通過 TensorRT 運行時隱式地使用 cuDLA 運行推理,也可以顯式地調用 cuDLA API。此示例演示了后一種方法,即顯式調用 cuDLA API 以在 混合模式 和 獨立模式 中運行。
cuDLA 混合模式和獨立模式主要在同步方面不同。在混合模式中,DLA 任務被提交到 CUDA 流,因此可以與其他 CUDA 任務無縫地進行同步。
在獨立模式下cudlaTask結構有一個規定,指定 cuDLA 必須分別等待和發出信號的等待和信號事件,作為cudla 提交任務。
簡而言之,使用 cuDLA 混合模式可以快速集成其他 CUDA 任務。使用 cuDLA 獨立模式可以防止 CUDA 上下文的創建,因此在管道沒有 CUDA context 的情況下可以節省資源。
YOLOv5 示例中使用的主要 cuDLA API 如下所示。
- cudlaCreateDevice 創建 DLA 設備。
- cudlaModuleLoadFromMemory 用于加載引擎內存以供 DLA 使用。
- cudaMalloc 和 cudlaMemRegister 被調用以首先在 GPU 上分配內存,然后讓 CUDA 指針向 DLA 注冊。(僅用于混合動力模式。)
- cudlaImportExternalMemory 和 cudlaImportExternalSemaphore 被調用以導入外部 NvSci 緩沖區和同步對象。(僅用于獨立模式。)
- cudlaModuleGetAttributes 從加載的模塊中獲取模塊屬性。
- cudlaSubmitTask 用于提交推理任務。在混合模式下,用戶需要指定 CUDA 流,以便 cuDLA 任務在其上運行。在獨立模式下,需要指定信號事件和等待事件,以便 cuDLA 在相應的圍欄到期時等待并發出信號。
目標驗證和分析
注意 GPU 與 DLA 之間的數值差異非常重要。底層硬件不同,因此計算并不精確。因為訓練網絡是在 GPU 上完成的,然后部署到目標上的 DLA,所以在目標上進行驗證很重要。當涉及到量化時,這一點尤其重要。與參考基線進行比較也很重要。
YOLOv5 DLA 準確性驗證
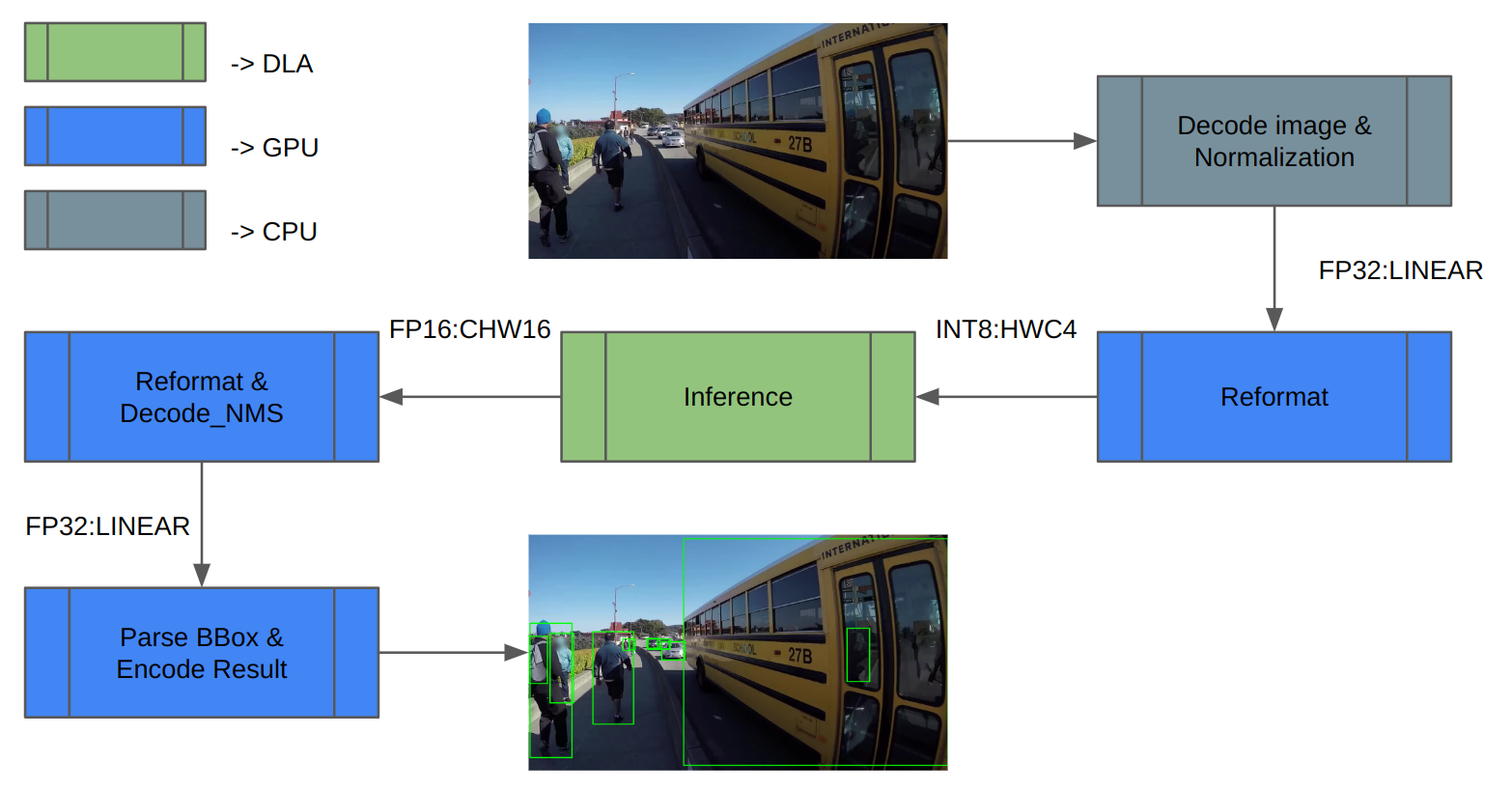
我們使用 COCO 數據集進行驗證。圖 3 顯示了推理管道體系結構。首先,加載圖像數據并對其進行歸一化。由于 DLA 僅支持 INT8/FP16,因此需要對推理輸入和輸出進行額外的重新格式化。
推理后,對推理結果進行解碼,并執行 NMS(非最大值抑制)以獲得檢測結果。最后,保存結果并計算 mAP。
在 YOLOv5 的情況下,最后三個卷積層的特征圖對最終檢測信息進行編碼。當量化為 INT8 時,與 FP16/FP32 相比,邊界框坐標的量化誤差變得明顯,從而影響最終的 mAP。
我們的實驗表明,在 FP16 中運行最后三個卷積層將最終 mAP 從 35.9 提高到 37.1。Orin DLA 具有針對 INT8 高度優化的特殊硬件設計,因此當這三個卷積在 FP16 中運行時,我們觀察到性能下降。
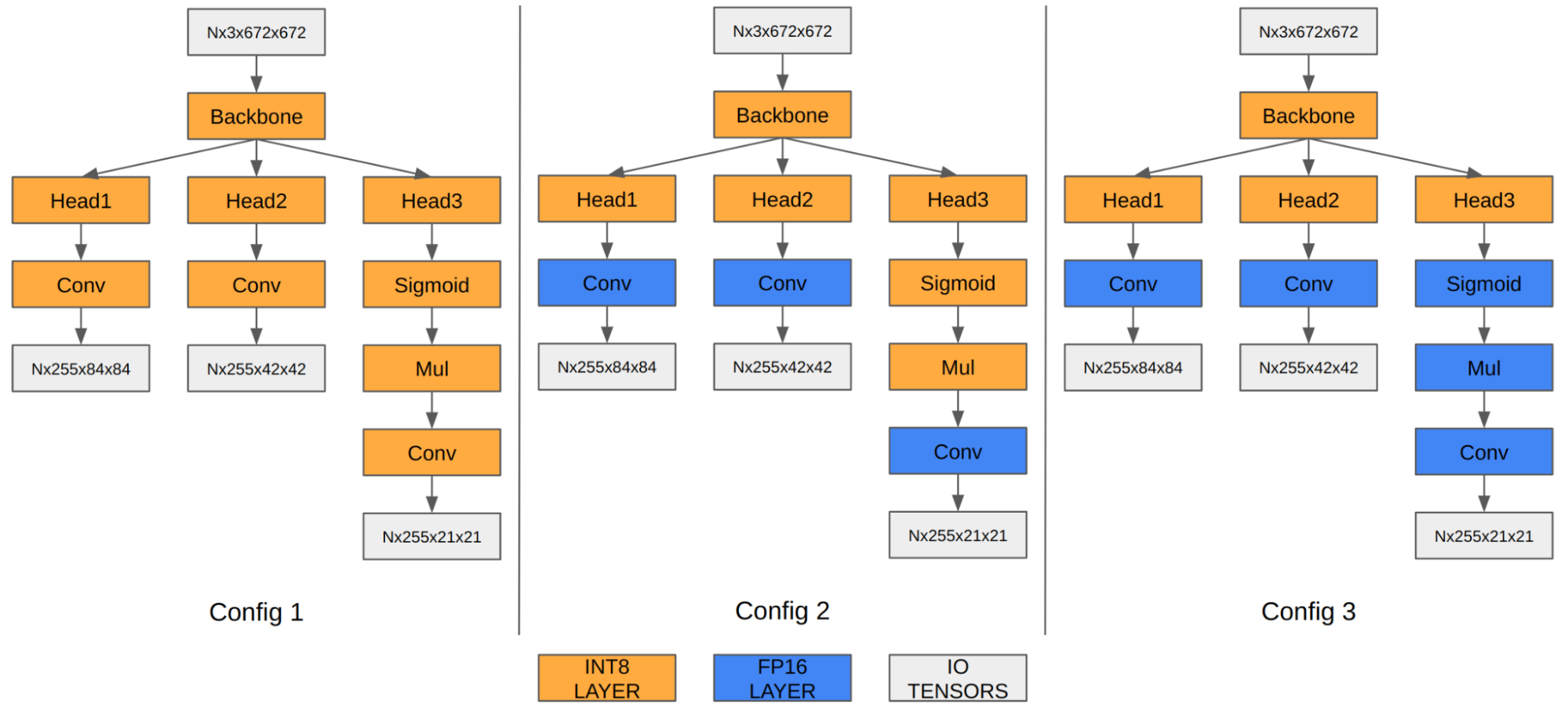
| ? | 配置 1 | 配置 2 | 配置 3 |
| 輸入張量格式 | INT8:DLA_HWC4 | INT8:DLA_HWC4 | INT8:DLA_HWC4 |
| 輸出張量格式 | INT8:chh32 | FP16:CHW16 | FP16:CHW16 |
| COCO Val mAP | 35.9 | 37.1 | 37.3 |
| FPS(DLA 3.14.0,1.33 GHz 時為 1x DLA,3.2 GHz 時為 EMC) | 410 | 255 | 252 |
注意,mAP 結果基于前面關于添加 Q/DQ 節點的部分中描述的選項 1。您也可以將相同的原則應用于選項 2。
YOLOv5 DLA 性能
得益于兩個 DLA 核心,DLA 在 Orin AGX 平臺上提供了三分之一的人工智能計算能力。如果您想了解有關 Orin DLA 性能的一般基線,請參閱 Deep-Learning-Accelerator-SW 在 GitHub 上的信息。
在最新版本 DLA 3.14.0(DOS 6.0.8.0 和 JetPack 6.0)中,DLA 編譯器添加了幾個性能優化,專門適用于基于 INT8 CNN 體系結構的模型:
- 原生 INT8 Sigmoid(之前在 FP16 中運行,必須在 INT8 之間鑄造;也適用于 Tanh)
- INT8 SiLU 融合到單個 DLA 硬件操作中(而不是獨立的 Sigmoid 加上獨立的 elementwise Mul)
- 將 INT8 SiLU 硬件操作與之前的 INT8 Conv 硬件操作融合(也適用于獨立的 Sigmoid 或 Tanh)
與之前的版本相比,這些改進可以為 YOLO 架構提供 6 倍的加速。例如,在 YOLOv5 的情況下,INT8 中的推理性能從 13ms 提升到 2.4ms(FP16 中運行了一些層),這是 5.4 倍的改進。此外,您可以使用 cuDLA 示例 以逐層分析 DNN,識別瓶頸,并修改網絡以提高其性能。
DLA 入門
這篇文章解釋了如何在 Orin 的專用深度學習加速器上使用 YOLOv5 以最有效的方式運行整個對象檢測管道。請記住,其他 SoC 組件,如 GPU ,要么處于空轉狀態,要么在非常小的負載下運行。如果您有一個以每秒 30 幀的速度產生輸入的相機,那么一個 DLA 實例將僅以大約 10%的速度加載。因此,有足夠的空間為您的應用程序添加更多的功能。
準備好潛水了嗎?YOLOv5 示例復制了這里討論的整個工作流程。您可以將其用作您自己的用例的參考點。
對于初學者來說,在 GitHub 上的?Jetson_dla_tutorial 展示了一個基本的 DLA 工作流程,以幫助您開始部署一個簡單的 DLA 模型。
如需獲取更多關于如何最大限度地利用 DLA 的示例和資源,請訪問 NVIDIA DRIVE 或 NVIDIA Jetson,或者訪問在 GitHub 上的 Deep-Learning-Accelerator-SW。有關 cuDLA 的更多信息,請訪問 Deep-Learning-Accelerator-SW/samples/cuDLA。
?
?