隨著 大型語言模型 (LLM) 功能變得更加強大,降低計算需求的技術也日趨成熟,因此出現了兩個令人關注的問題。首先,哪些最先進的 LLM 可以在邊緣設備上運行和部署?其次,現實世界的應用程序如何利用這些技術進步?
運行先進的開源 LLM (如 Llama 2 70B),即使在降低的 FP16 精度下也需要超過 140GB 的 GPU VRAM (在 FP16 中,700 億個參數 x 2 字節=140GB,KV 緩存更多)。對于大多數開發者和較小的公司而言,此數量的 VRAM 并不容易訪問。此外,由于成本、帶寬、延遲或數據隱私問題,應用程序特定的要求可能會排除使用云計算資源托管 LLM 的選項。
NVIDIA IGX Orin 開發者套件 和 NVIDIA Holoscan SDK 應對這些挑戰,將 LLM 的強大功能帶到邊緣。NVIDIA IGX Orin 開發者套件搭配獨立的 NVIDIA RTX A6000 GPU,提供了一個專為工業和醫療環境需求量身打造的工業級邊緣 AI 平臺。該平臺包括 NVIDIA Holoscan,這是一個能夠協調數據移動、加速計算、實時可視化和 AI 推理的 SDK。
該平臺使開發者能夠將開源 LLM 添加到邊緣 AI 串流工作流和產品中,為支持 AI 的實時傳感器處理提供新的可能性,同時確保敏感數據保持在 IGX 硬件的安全邊界內。
用于實時流式傳輸的開源 LLM
開源 LLM 最近的快速發展改變了人們對實時流式傳輸應用程序的可能性的看法。普遍的看法是,任何需要類似人類的能力的應用程序都是由數據中心規模的企業級 GPU 提供支持的閉源 LLM 所獨有。但是,由于新開源 LLM 最近的性能激增,Falcon、MPT 和 Llama 2 等模型現在可以為閉源黑盒 LLM 提供可行的替代方案。
有許多應用程序可以在邊緣上利用這些開源模型,其中許多涉及將流式傳感器數據提煉成自然語言摘要。這些可能性包括實時監控手術視頻以讓家人及時了解進展情況,總結空中交通管制員最近的雷達聯系,甚至將足球比賽的逐場播放評論轉換為另一種語言。
訪問功能強大的開源 LLM 激發了一個社區的熱情,致力于提升這些模型的準確性,并減少運行模型所需的計算資源。這個活躍的社區在Hugging Face Open LLM 排行榜上不斷更新,經常引入最新的優秀模型。
邊緣 AI 功能
我們的 NVIDIA IGX Orin 平臺 搭載 NVIDIA RTX A6000 GPU,具有獨特的優勢,能夠充分利用激增的可用開源 LLM 和支持軟件。NVIDIA RTX A6000 GPU 提供了充足的 48 GB VRAM,使其能夠運行一些大型開源模型。例如,模型權重已量化為 4 位精度(而不是標準的 32 位)的 Llama 2 70B 版本可以完全在 GPU 上運行,速度可達每秒 14 個令牌。
可靠的 Lama 2 模型可以解決各種問題和用例,該模型由 NVIDIA IGX Orin 平臺的安全措施提供支持,并無縫集成到低延遲的 Holoscan SDK 流程中。這種融合不僅標志著邊緣 AI 能力的顯著進步,而且釋放了跨多個領域的變革性解決方案的潛力。
一個值得注意的應用程序可以利用新推出的 臨床 Camel,這是一款經過微調的,專門用于醫學知識的 Lama 2 70B 變體。通過基于此模型創建本地化醫療聊天機器人,它可以確保敏感的患者數據仍然局限于 IGX 硬件的安全邊界內。對于那些隱私、帶寬問題或實時反饋至關重要的應用程序,IGX 平臺是真正的亮點所在。
想象一下,輸入患者的病歷并查詢機器人以發現類似病例,獲得對難以診斷的患者的新見解,甚至為醫療專業人員配備規避與現有處方相互作用的潛在藥物簡短列表。所有這些都可以通過 Holoscan 應用程序實現自動化,該應用程序將醫生與患者互動的實時音頻轉換為文本,并將其無縫輸入到臨床 Camel 模型中。

得益于對低延遲傳感器輸入的出色優化, NVIDIA IGX 平臺進一步發揮了其潛力,將 LLM 的功能擴展到了純文本應用程序之外。雖然醫療聊天機器人提供了令人信服的用例,但 IGX Orin 開發者套件的強大之處在于它能夠無縫集成來自各種傳感器的實時數據。
IGX Orin 專為邊緣環境而設計,可以處理來自攝像頭、激光雷達傳感器、無線電天線、加速傳感器、超聲波探針等的流式傳輸信息。這種通用性為尖端應用程序提供支持,將 LLM 的強大功能與實時數據流無縫融合在一起。
這些 LLM 集成到 Holoscan 運算符中,有可能顯著增強支持 AI 的傳感器處理流程的能力和功能。具體示例詳見下文。
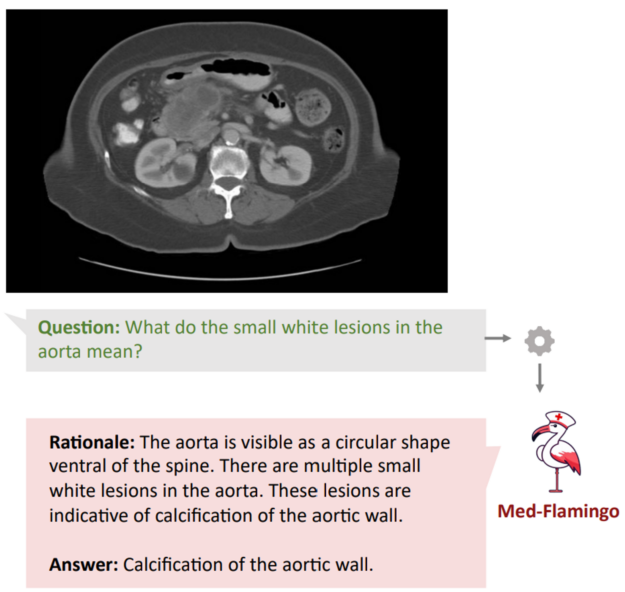
多模態醫療助理:增強了 LLM 的能力,不僅可以解釋文本,還能解釋醫學影像。正如以下項目所示:Med-Flamingo 能夠解讀核磁共振成像 (MRI)、X 射線和組織學圖像。
信號情報 (SIGINT):從通信系統和雷達捕獲的實時電子信號中提取自然語言摘要,提供連接技術數據與人類理解的洞察。
手術案例注釋生成:將內窺鏡視頻、音頻、系統數據和患者記錄傳輸到多模態 LLM,以生成全面的手術案例注釋,并自動上傳至患者的電子病歷中。
智慧農業:通過使用監測 PH 值、濕度和養分水平的土壤傳感器,LLM 能夠提供實用的見解,以優化種植、噴灑和病蟲害控制策略。
用于教育、故障排除或生產力增強代理的軟件開發副駕駛是 LLM 的另一個新用例。這些模型可幫助開發者開發更高效的代碼和全面的文檔。
Holoscan 團隊最近發布了 HoloChat,這是一款 AI 驅動的聊天機器人,在 Holoscan 開發中充當開發者的副駕駛。它可以生成類似人類的回答,回答有關 Holoscan 和編寫代碼的問題。有關詳情,請訪問 nvidia-holoscan/holohub 在 GitHub 上的發布頁面。
HoloChat 本地托管方法旨在為開發者提供與熱門閉源聊天機器人相同的優勢,同時消除與將數據發送到第三方遠程服務器進行處理相關的隱私和安全問題。
通過模型量化實現最佳準確性和顯存占用率
隨著開源模型在 Apache 2、MIT 和商業上可行的許可證下發布,任何人都可以下載和使用這些模型權重。但是,僅僅因為這是可能的,并不意味著它對絕大多數開發者來說是可行的。
模型量化提供了一種解決方案。模型量化通過將權重和激活表示為低精度數據類型(int8 和 int4),而不是更高精度的數據類型(FP16 和 FP32),從而降低運行推理的計算和內存成本。
然而,從模型中降低精度確實會影響模型的準確性。研究顯示,在給定的內存預算下,使用盡可能大的模型可以實現最佳的 LLM 性能。當以 4 位精度存儲參數時,模型能夠適應內存限制。有關更多詳細信息,請參閱4 位精度案例:k 位推理擴展定律。
因此,在 4 位量化中實施時,Lama 2 70B 模型可以實現準確性和顯存占用率的最佳平衡,從而將所需的 RAM 僅減少到 35 GB 左右。小型開發團隊甚至個人都可以實現這一顯存需求。單個 NVIDIA RTX A6000 48 GB GPU (可選包含在 IGX Orin 中)可以輕松滿足這一需求。
開源 LLM 開啟了新的開發機遇
由于能夠在商品硬件上運行先進的 LLM,開源社區迅猛發展,推出了支持本地運行的新庫,并提供工具來擴展這些模型的功能,而不僅僅是預測句子的下一個詞。
借助 Llama.cpp、ExLlama 和 AutoGPTQ 等庫,您可以量化自己的模型,并在本地 GPU 上運行極速推理。不過,量化自己的模型是一個完全可選的步驟,因為 HuggingFace.co 模型庫 提供了大量隨時可用的量化模型。這在很大程度上得益于高級用戶 /TheBloke 每天上傳的新量化模型。
雖然這些模型本身已經提供了令人興奮的開發機會,但通過添加來自大量新創建的庫中的其他工具,可以進一步增強這些模型的功能。示例包括:
- LangChain 是一個擁有 58000 個 GitHub 星標的庫,它提供了從支持文檔問答的向量數據庫集成到支持 LLM 瀏覽網頁的多步驟代理框架等多種功能。
- 通過 Haystack 實現可擴展的語義搜索。
- 通過 Magentic,您可以輕松地將 LLM 集成到您的 Python 代碼中。
- Oobabooga 是一個 Web UI,用于在本地運行量化的 LLM。
如果您有 LLM 用例,則可能會提供開源庫,以滿足您的大部分需求。
開始在邊緣部署 LLM
使用 NVIDIA IGX Orin 開發者套件在邊緣部署先進的 LLM 帶來了前所未有的開發機遇。首先,您可以查看這個全面的教程,它詳細介紹了如何在 IGX Orin 上創建一個簡單的聊天機器人應用程序,在邊緣部署 Lama 2 70B 模型。
本教程說明了 Lama 2 在 IGX Orin 上的無縫集成,并指導您使用 Gradio 開發 Python 應用程序。這是利用本文中提到的任何出色 LLM 庫的第一步。IGX Orin 提供彈性、無與倫比的性能和端到端安全性,使開發者能夠圍繞在邊緣運行的先進 LLM 打造創新的 Holoscan 優化應用程序。
11 月 17 日(星期五),加入 NVIDIA 深度學習培訓中心(DLI)舉辦的 LLM 開發者日,這是一場免費的虛擬活動,專注于探討 LLM 應用程序開發的前沿技術。歡迎注冊參與直播或點播觀看活動。
?