數據科學家和機器學習工程師經常面臨“與 深度學習 相比使用 機器學習 分類器解決其業務問題”的困境。根據數據集的性質,一些數據科學家更喜歡經典的機器學習方法。其他人采用最新的深度學習模式,而還有人追求“集成”模式,希望在可解釋性和性能這兩個方面都達到最佳。
機器學習,特別是決策樹,導致了更先進的 XGBoost 模型,比深度學習成熟得更早,并且有一些成熟的方法。深度學習在非表格計算機視覺、語言和語音識別領域表現出色。無論您選擇哪一種, GPU 都在加速數據科學用例,使其達到這樣的程度:對大型數據集的任何數據分析都只需要它們來滿足每天的便利性、快速迭代和結果。
RAPIDS 通過類似于 scikit-learn 和 pandas 等收藏夾的界面,使數據科學家更容易利用 GPU 。這里,我們使用的是一個表格數據集。經典的提取 – 轉換 – 加載過程( ETL )是任何數據科學項目的核心起點。
對于GPU加速用例,NVIDIA NVTabular 應用框架 推薦系統?使用 NVTabular -加速特征工程、預處理和數據加載庫,也可用于其他領域,如金融服務。
在本文中,我們將演示如何檢查相互競爭的模型(稱為 challenger models ),并使用 GPU 加速,通過簡單、經濟高效且可理解的模型可解釋性應用程序獲得成功。當 GPU 加速在模型開發過程中被多次使用時,建模者的時間將通過在數十次模型迭代中攤銷培訓時間和降低成本而得到更有效的利用。
我們是在使用 公共房利美抵押貸款數據集 預測抵押貸款拖欠的情況下這樣做的。我們還展示了用于模型訓練的 NVTabular 數據加載器獲得的簡單加速比。同樣的例子也可以擴展到信用承銷、信用卡拖欠或其他一系列重要的分類問題。
所有金融信用風險建模中的一個共同主題是對預期損失的關注。無論交易是一方欠另一方一定金額的兩個交易對手之間的交易協議,還是借款人欠貸款人每月還款金額的貸款協議,我們都可以通過以下方式查看預期損失 EL :
EL = PD x LGD x EAD
哪里:
- PD :違約概率,考慮到人口中的所有貸款
- LGD :違約造成的損失;介于 0 和 1 之間的值,用于測量未付貸款的百分比
- EAD :違約風險敞口,即剩余未償余額
PD 和 EL 附加到一個時間段,該時間段通常可以設置為每年或每月,具體取決于發放貸款的公司的選擇。
在我們的案例中,我們的目標是根據個人貸款的特征預測最有可能拖欠的具體個人貸款。因此,我們主要關注影響 PD 利率的貸款,也就是說,將有預期損失的貸款與無預期損失的貸款分開。
機器學習與深度學習方法
機器學習( ML )和深度學習( DL )已經發展成為分析預測的合作和競爭方法。考慮兩種方法并權衡每個模型的結果,或者使用集成多個方法來獲得給定應用的兩個世界,這是最好的實踐。這兩種方法都可以從數據中提取深刻、復雜的見解,幫助決策。
在許多情況下,與傳統回歸模型相比,使用更高級的 ML 模型可以提供真正的業務價值。然而,使用更先進的模型解釋特定決策的驅動因素可能很困難、耗時,而且使用傳統的基礎設施成本高昂。模型運行時間與解釋預測的解釋步驟的運行時間同樣重要。
為了對結果充滿信心,我們希望解決對可解釋性的新需求。現有技術速度慢,計算成本高,是 GPU 加速的理想選擇。通過轉向 GPU 加速建模和解釋,團隊可以改進處理、準確性和解釋性,并在業務需要時提供結果。
抵押貸款風險預測
從消費者角度來看,違約風險可能會影響我們個人,也可能會影響發行方。今天,在許多國家,為基礎設施改善項目發放了大量貸款。例如,一條大型公路 橋?可能需要超過 10 億美元的債務融資。顯然,為數十億美元的巨額項目融資會帶來違約風險。
衡量違約概率很重要,因為管理機構的公民當然不希望看到該債券違約。英格蘭銀行的一篇題為 金融學中的機器學習可解釋性:在違約風險分析中的應用 的論文為當前的工作提供了靈感,該工作的重點是住房抵押貸款。
在英格蘭銀行的文件中很容易看到這種解釋透明的好處。作者稱他們的方法為定量輸入影響( QII ), QII 用于線性邏輯和梯度增強樹機器學習預測模型。問題是:哪些因素對違約的影響最大?
作者解釋了這些解釋的直覺力量。他們還進行觀察,這是金融建模從業者應該注意的。本文通過精確召回曲線結果,展示了為默認預測設計足夠的精確性、精確性和召回率的能力。
模型可解釋性可能是與思想領袖、管理層、外部審計師和監管者討論的重要組成部分。[VZX38 ]使用[VZX39 ]計算,其中數據集由英國的六百萬個貸款組成,具有大約2.5%的違約率。
正如 NVIDIA 作者在最近的文章中所描述的,違約風險是資本市場、銀行業和保險業中非常常見的債務用例。例如,信用衍生工具是一種對違約可能性進行投機的方式,通過分期付款和離家較近的方式進行投機。抵押貸款貸款者對他們是否能及時得到償還深感興趣。
歸根結底,保險合同是從客戶的角度覆蓋洪水、盜竊或死亡相關風險的方式。從貸款人或保險承保的角度來看,預測這些事件對其業務的盈利能力至關重要。借助著名的美國房利美公共抵押貸款數據集,我們能夠使用 GPU ML 和 DL 模型的加速訓練,檢查風險方法和樣本外精確度、召回率。
請參見原始 文章?介紹 GPU 加速解釋信用風險和 extension 的形狀值聚類,并參見 相關文章?了解模擬權益工具的其他有趣解釋和加速結果。
本文的重點是 ML 和 DL 模型的細微差別以及可解釋性的方法。如果發生逾期 90 天的貸款事件,貸款公司就會產生擔憂。由于重置成本,違約概率令人擔憂。本文的一個關鍵結果是,當 GPU 加速應用于本 GPUTreeShap paper 中所述的算法時,計算 Shap 值的速度提高了 29 倍。
我們預測美國房利美抵押貸款數據集違約的 Python 程序將使用 GPU 加速框架 RAPIDS 。 RAPIDS 為數據幀操作提供類似于 Python pandas 的應用程序接口( API )。本手冊提供的抵押貸款數據集非常方便 RAPIDS 抵押數據鏈路 擁有近二十年的貸款業績數據,記錄了實際利率、借款人特征和貸款人名稱。我們的抵押貸款表格數據集存在一個經典的 imbalanced class 預測問題,因為只有大約 4% 的貸款拖欠。
分類列的因式分解
因子是編程語言中的一個重要概念。熟悉 R 語言進行統計計算的讀者了解使用 factor() 函數創建的因子,作為將列分類為離散值集的一種方法。 R 、 事實上,默認情況下是對列進行因式分解,可以根據輸入進行因式分解,因此用戶通常應該覆蓋read.csv()帶有 wordy 參數的選項stringsAsFactors=FALSEPython pandas 和 RAPIDS 軟件包包含非常相似的factorize()本 article 中提到的方法。對于我們的抵押貸款數據集,郵政編碼是一個需要分解的經典列。
df['Zip'], Zip = df['Zip'].factorize()
一系列轉換語句是一個熱編碼列的替代方案,減少了轉換數據所需的稀疏性和內存。與使用單一熱編碼相比,因子分解的優勢在于,數據幀不需要隨著列值數量的增加而變寬,但我們仍然具有分類列變量的優勢。
XGBoost 分類器調整
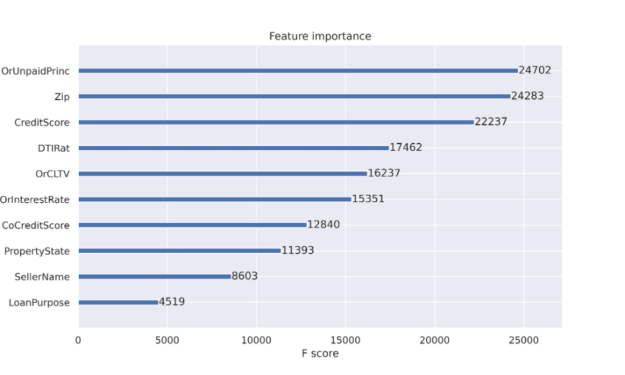
當使用決策樹時,可以獲得特征重要性的好處。特性重要性報告有助于解釋決策中最常用的特性。如圖 1 所示的特征重要性報告是推動決策樹成為流行分類方法的工件之一。決策樹節點對應于一組訓練數據集行。最初,我們從一個節點開始表示所有訓練行。節點純度指的是數據集行相似。當我們開始決策樹訓練過程時,節點雜質更為常見,當我們在掃描數據集時擴展樹時,純度變得更為常見。特征重要性列在 減少節點雜質 中,根據到達該節點的機會進行加權。最有效的節點是那些導致雜質最佳減少的節點,同時也代表數據總體中樣本數量最多的節點。
對于決策樹(如 XGBoost 分類器),當決策樹通過從初始單個節點到數百個節點的拆分進行擴展時,當發生拆分以獲得準確性時,不需要節點雜質。我們將很快討論更多關于可解釋性的問題。
XGBoost 分類器作為 Python Jupyter 筆記本的一部分進行了調整,以檢查貸款拖欠的可預測性。這項工作的靈感來自于 逐條降級 。我們在前一篇文章中重點介紹了 XGBoost 分類器,并且能夠報告通過因子分解在精確度和召回率方面的改進。給定一個包含刺激變量和默認輸出變量的數據集,數據行的可預測性受到限制。我們在圖 2 中的結果來自 2007 年至 2012 年期間 1120 萬份個人抵押貸款,測試集中有 110 萬份貸款。與使用標準值 0.5 相比,對發出的違約概率使用自定義閾值有助于平衡精確度和召回率。我們將在下面用最佳參數顯示代碼序列。 XGBoost 和 PyTorch 分類器說明的代碼可在 https://github.com/NVIDIA/fsi-samples/tree/main/credit_default_risk 上找到,以及有關如何下載抵押貸款數據集的說明。
params = { 'num_rounds': 100, 'max_depth': 12, 'max_leaves': 0, 'alpha': 3, 'lambda': 1, 'eta': 0.17, 'subsample': 1, 'sampling_method': 'gradient_based', 'scale_pos_weight': scaling, # num_negative_samples/num_positive_samples 'max_delta_step': 1, 'max_bin': 2048, 'tree_method': 'gpu_hist', 'grow_policy': 'lossguide', 'n_gpus': 1, 'objective': 'binary:logistic', 'eval_metric': 'aucpr', 'predictor': 'gpu_predictor', 'num_parallel_tree': 1, "min_child_weight": 2, 'verbose': True } if use_cpu: print('training XGBoost model on cpu') params['tree_method'] = 'hist' params['sampling_method'] = 'uniform' params['predictor'] = 'cpu_predictor' dtrain = xgb.DMatrix(X_train, label=y_train) dtest = xgb.DMatrix(X_test, label=y_test) evals = [(dtest, 'test'), (dtrain, 'train')] model = xgb.train(params, dtrain, params['num_rounds'], evals=evals, early_stopping_rounds=10)
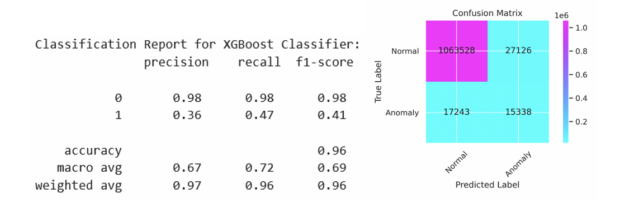
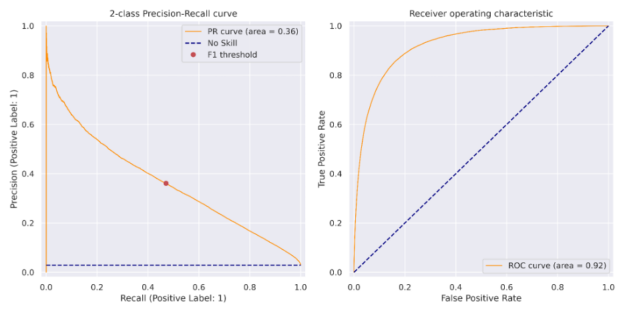
我們可以在前面看到, XGBoost 培訓步驟的目標是binary:logistic評估指標是精確性和召回率曲線下的面積,稱為aucpr. 訓練模型后,在訓練集上計算對應于最大 F1 分數的閾值。該閾值應用于測試集上的預測,結果如圖 2 所示,并在圖 3 的精度召回曲線中顯示為紅點。
使用 NVTABLAR 加速 PyTorch 深度學習培訓
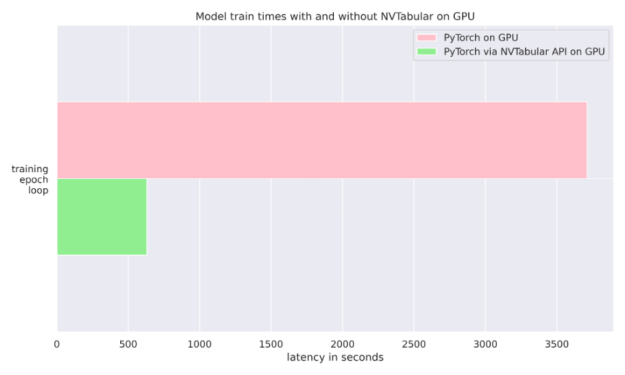
這個 NVIDIA NVTabular Python 軟件包 是一個用于表格數據的功能工程和預處理庫,旨在快速輕松地操作 TB 級數據集,并培訓基于深度學習( DL )的推薦系統。它可以使用 Anaconda 或 Docker 安裝,也可以使用帶有 NVTabular 關鍵字的 pip 安裝。在我們的例子中,我們只是在訓練期間使用它將數據輸入 PyTorch 分類器。我們還比較了使用普通 PyTorch 數據加載器與 NVTABLAR 的異步 PyTorch 數據加載器的運行時。我們發現,對于抵押貸款數據集, NVTabular 比不使用它有 6 倍的優勢,因為兩次運行都是在同一個 GPU 上完成的。有關更多詳細信息,請參見圖 4 和 文章?。
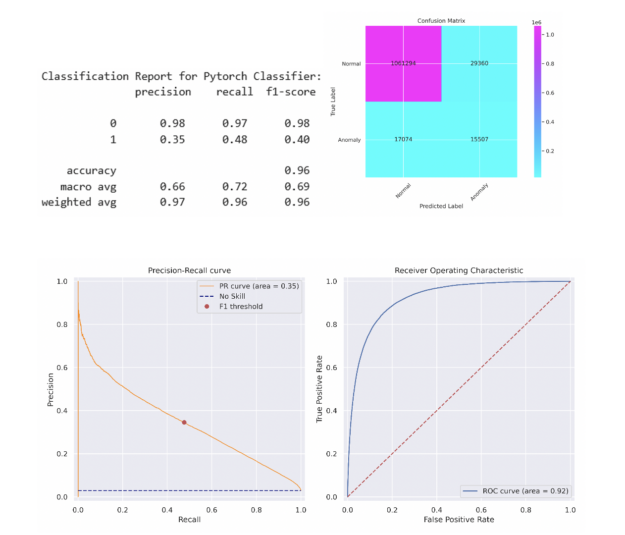
為了簡單起見,我們選擇了一個 5 層多層感知( MLP )神經網絡,其中包含 512 個神經元,包括線性層、預處理、批量歸一化和退出。簡單的 MLP 能夠在測試集上匹配 XGBoost 模型的性能。更復雜的模型可能會超過此性能。在將該閾值應用于測試集之前,采用相同的方法來確定在列車組上產生最大 F1 分數的閾值。分類報告和混淆矩陣如下所述,類似的 PR 曲線和 ROC 曲線如圖 5 所示。
機器學習和深度學習的可解釋性
既然我們對我們的預測模型有信心,那么就必須更多地了解它是如何工作的以及為什么工作的。對于 ML 和 DL 模型,可以使用 SHAP 和 Captum 計算 Shapley 值。對于 SHAP 包,可以很容易地檢索 Shapley 值,以便按照下面的代碼片段解釋我們的 XGBoost ML 模型:
expl = shap.TreeExplainer(model) shap_values = expl.shap_values(X_test) shap.summary_plot(shap_values, X_test.to_pandas(), sort=False, show=False) plt.tight_layout()
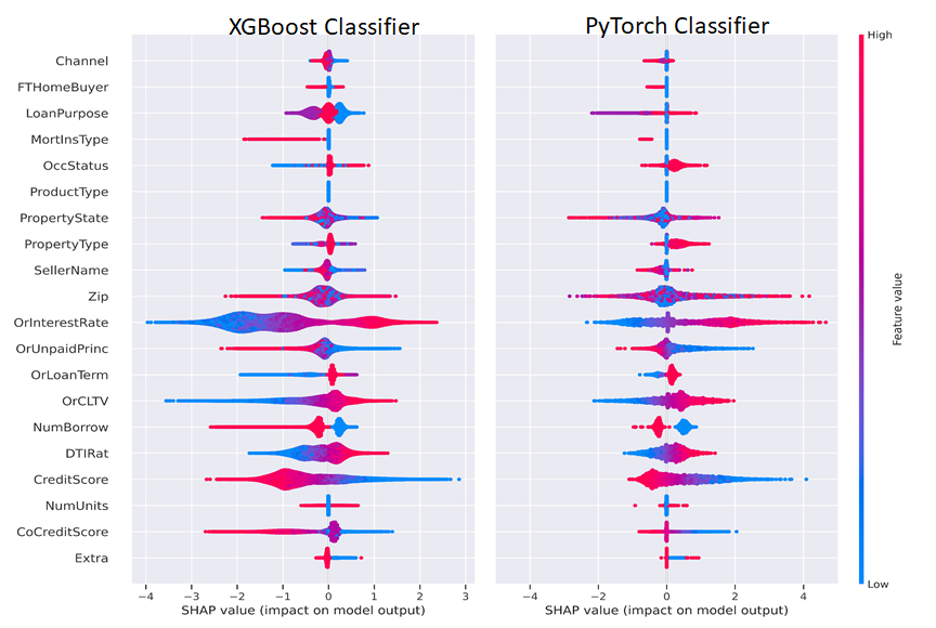
使用 Captum GradientShap 方法計算 PyTorch DL Shapley 值,并使用以下代碼繪制,將 Shapley 值傳遞到 SHAP summary _ plot ()方法中。我們分離出積極和消極的分類變量和連續變量,以便只可視化一個不同的類或兩個類,如圖 6 所示。
from captum.attr import GradientShap Gradshap = GradientShap(model) attr_gs, delta = gradshap.attribute((torch.cat([pos_cats, neg_cats], dim=0), torch.cat([pos_conts, neg_conts], dim=0)), baselines=(torch.zeros_like(neg_cats, device=device), torch.zeros_like(neg_conts, device=device)), n_samples=200, return_convergence_delta=True) df = DataFrame(cp.asarray(torch.cat([torch.cat([pos_cats, pos_conts], dim=1), torch.cat([neg_cats, neg_conts], dim=1)], dim=0))) df.columns = CATEGORICAL_COLUMNS + CONTINUOUS_COLUMNS svals = cp.asnumpy(torch.cat(attr_gs, dim=1)) shap.summary_plot(svals, df[CATEGORICAL_COLUMNS+CONTINUOUS_COLUMNS].to_pandas(), sort=False, show=False) plt.tight_layout()
一般來說,我們想解釋一個單一的預測,并解釋這些特征是如何導致該預測的。 Shapley 功能解釋總結為一行的預測,我們可以跨行聚合以批量解釋模型預測。出于監管目的,這意味著模型可以為任何輸出(有利或不利)提供人類可解釋的解釋。任何持有抵押貸款或在債務工具領域工作的人都可以認識到這些熟悉的因素。
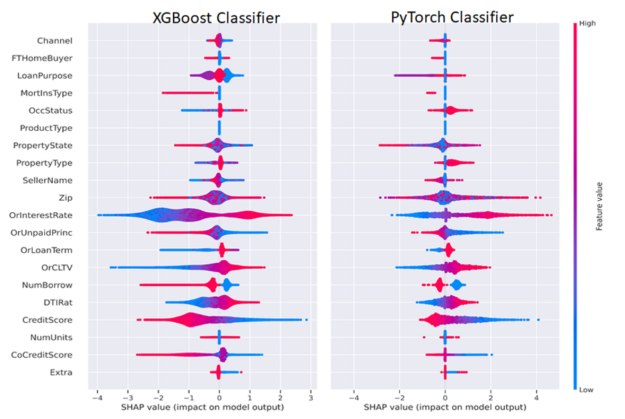
圖 6 并排描述了 ML 和 DL Shapley 值。我們可以以 CreditScore 和利率( OrInterestRate )特性為例,按照以下方式解釋圖 6 。 CreditScore 功能的紅色部分表示較高的信用分數,如圖右側圖例所示,較高的功能值為紅色,較低的功能值為藍色。對于聚集在負 x 軸上的 CreditScore 點,對應于負 SHAP 值,這有助于形成負或非拖欠類別,表明信用分數高的人不太可能拖欠。對稱地, CreditScore 的藍色(低)值位于正 x 軸或正 Shapley 值上,表示對正或拖欠類別的貢獻。
OrInterestRate 功能也可以采用類似但相反的解釋:低(藍色)利率產生負 Shapley 值,并與較低的拖欠率相關,這是直觀的,因為較低的利率意味著較低的抵押付款。有些特性可能不太清晰,為數據科學家或機器學習工程師提供了改進模型的機會。例如,在我們的簡單 MLP 模型中,我們在傳遞到 MLP 之前將因式分類特征與連續特征連接起來。該模型的一個改進可能是使用分類嵌入,這既可以提高模型性能,也可以增強可解釋性。通過這種方式,數據科學家或機器學習工程師可以嘗試優化模型的可解釋性和性能。
GPU-Acceleration results
圖 7 和圖 8 重點測試了讀取輸入數據集、合并兩個數據集所需的時間,以及與 Ice Lake 24 核雙 CPU 相比, NVIDIA Ampere A100 GPU 上的 DL 推斷步驟。如表 1 所示,每個步驟都有穩定的加速。
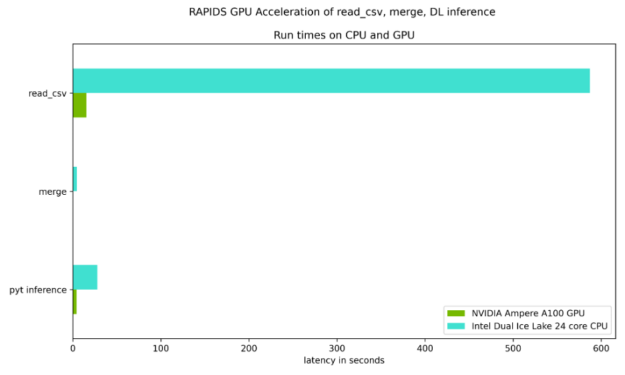

表 1 量化了圖 7 和圖 8 所示的加速,并強調了 GPU 加速的好處。
| ? | CPU only | NVIDIA Ampere A100 40GB GPU |
Speed up Factor |
| Read cvs files | 587.0 sec | 15.3 sec | 38X |
| merge | 4.6 sec | 0.04 sec | 115X |
| PyTorch inference | 27.7 sec | 4.3 sec | 6X |
| XGBoost train | 134.0 sec. | 10.7 sec | 12.5X |
| XGBoost shap | 265.0 sec | 9.2 sec | 29X |
| PyTorch train | 13314.6 sec | 2567.3 sec | 5X |
| PyTorch train with NVTabular | NA | 382.2 sec | 6X over PyTorch train w/GPU |
| Captum GradientShap | 289.1 sec | 166.8 sec | 2x |
在這篇文章中,我們擴展了先前的一篇相關文章,通過深入學習討論了信用違約風險預測,并討論了:
- 如何使用 RAPIDS 來 GPU 加速完整的默認分析工作流
- 如何使用 GPU 在 RAPIDS 內部應用 XGBoost 實現
- 如何將深度學習lib庫應用于 GPU 表格數據
- 如何使用 查看 NVTabular 包 對于 GPU 上的 PyTorch DL ,只需更改數據加載器即可獲得 6 倍的運行時性能。
- 如何使用 Shap 和 Captum 包以及 GPU 訪問可解釋的預測,并使用這些可解釋的結果進一步改進模型。
我們建議采取以下步驟:
- 訪問網站 http://ngc.nvidia.com,為NVIDIA GPU 云存儲容器,以幫助建立可用的人工智能解決方案。
- 回顧或參加最新的 NVIDIA 全球技術會議 ,分享想法和技術解決方案。
- 有關更多信息,請向列出的作者之一發送電子郵件。
?