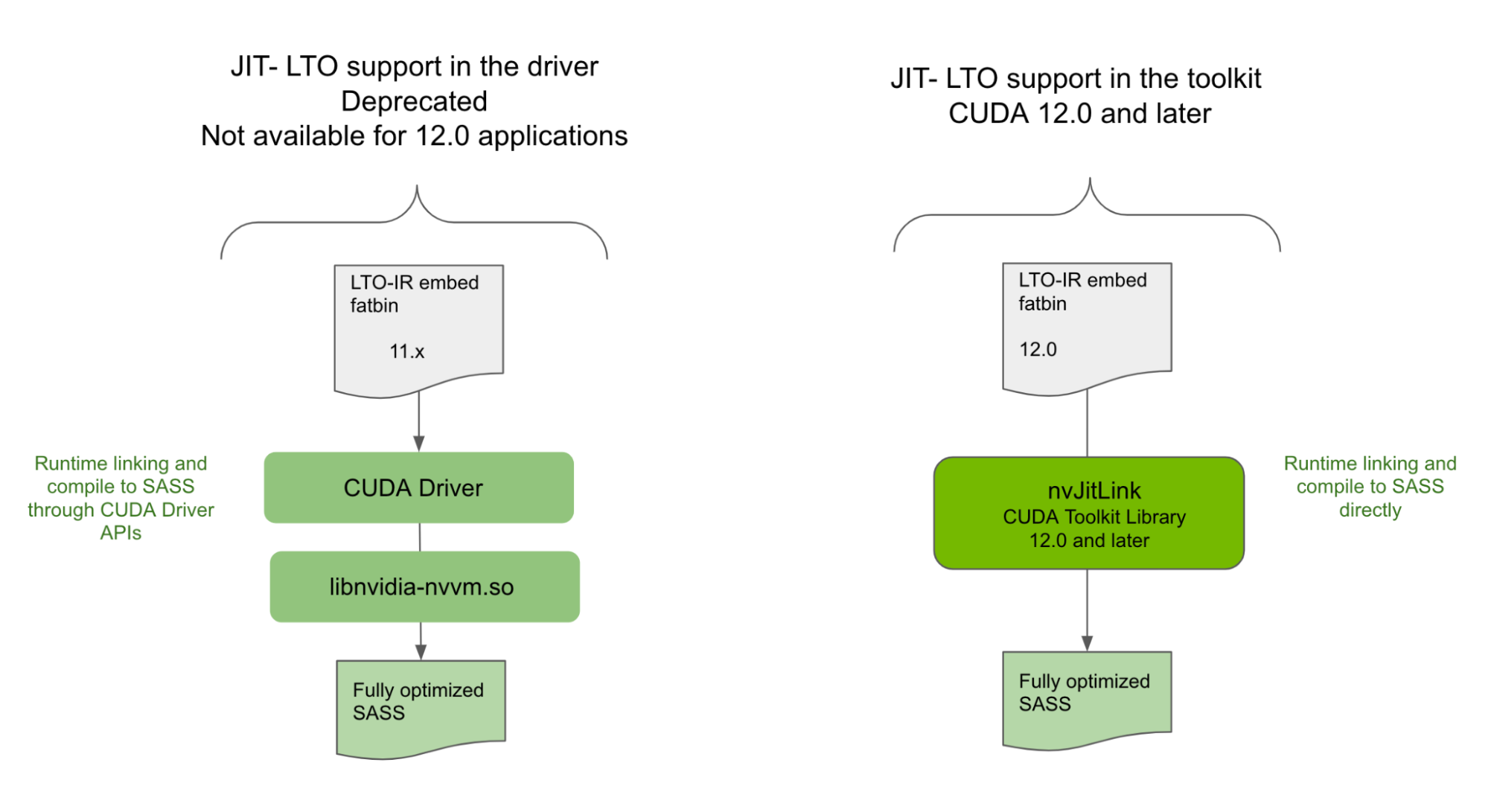
CUDA Toolkit 12.0 引入了一個新的 nvJitLink 庫,用于實時鏈接時間優化( JIT LTO )支持。在 CUDA 的早期,為了獲得最大性能,開發人員必須在整個編程模式下將 CUDA 內核構建和編譯為單個源文件。這限制了 SDK 和應用程序具有大量代碼,跨越多個文件,需要從移植到 CUDA 進行單獨編譯。性能的提高與整個程序的編譯不符。
隨著 CUDA 工具包 11.2 的發布, NVCC 增加了對離線鏈接時間優化( LTO )的支持,以使單獨編譯的應用程序和庫能夠獲得與從單個翻譯單元編譯的完全優化程序類似的 GPU 運行時性能。在某些情況下,據報告,性能增益約為 20% 或更高。要了解更多信息,請參見 Improving GPU Application Performance with NVIDIA CUDA 11.2 Device Link Time Optimization 。
在論文 Enhancements Supporting IC Usage of PEM Libraries on Next-Gen Platforms 中, Lawrence Livermore 國家實驗室報告了通過離線 LTO 獲得的性能改進,“在所有情況下都提供了加速;最大加速為 27.1% ”
CUDA Toolkit12.0 隨著 JIT LTO 的正式引入,進一步擴展了 LTO 支持。這擴展了 LTO 使用運行時鏈接為應用程序提供的相同性能優勢。
驅動程序中不支持 JIT LTO
雖然 JIT LTO 在 CUDA 11.4 中引入,但該版本的 JIT LTO 是通過 CUDA 驅動程序中的 cuLink API 實現的。它還依賴于使用 CUDA 驅動程序附帶的單獨優化器庫在運行時執行鏈接時間優化。由于依賴于 CUDA 驅動程序, 11.4 中發布的 JIT LTO 沒有提供次要版本兼容性,在某些情況下, CUDA 的向后兼容性保證。
因此,我們不得不重新考慮我們的設計,考慮到 CUDA 可以使用的各種部署場景以及庫和獨立應用程序的不同使用模型。
NVIDIA 正在棄用 CUDA 驅動程序中公開的 JIT LTO 功能,并將其作為 CUDA 12.0 及更高版本應用程序的 CUDA Toolkit 功能引入。有關詳細信息,請參閱 CUDA 12.0 Release Notes 中的棄用通知。
新庫提供 JIT LTO 支持
在 CUDA Toolkit12.0 中,您將發現一個新的庫 nvJitLink ,該庫帶有 API ,可在運行時鏈接期間支持 JIT LTO 。 nvJitLink 庫的用法類似于其他任何熟悉的庫,如 nvrtc 和 nvptxcompiler 。將鏈接時間選項 -lnvJitLink 添加到構建選項中。 CUDA 工具包將提供適用于 Linux 、 Windows 和 Linux4Tegra 平臺的 nvJitLink 庫的靜態和動態版本。
考慮到適當的因素,通過 nvJitLink 庫公開的 JIT LTO 將符合 CUDA 兼容性保證。本文主要介紹通過 nvJitLink 庫提供的 JIT LTO 功能,并在適當時強調與早期基于驅動器的實現的差異。我們將通過代碼示例、兼容性保證和好處深入了解該功能的細節。作為額外的獎勵,我們還包括了 NVIDIA 數學庫計劃如何利用該功能以及為什么要利用該功能的預覽。
如何使 JIT LTO 工作
對于運行時 LTO ,請遵循下面概述的三個主要步驟。
1.創建稍后將引用的鏈接器句柄,以將相關對象鏈接在一起。您需要將-lto作為選項之一傳遞。
nvJitLinkCreate (&handle, numOptions, options)2.添加要與以下任一腳本鏈接在一起的對象:
nvJitLinkAddFile (handle, inputKind, fileName);輸入類型通常可以是 ELF 、 PTX 、 fatbinary 、主機對象和主機庫。對于 JIT LTO ,輸入類型是 LTOIR 或包含 LTOIR 的格式,例如 fatbinary 。
3. 使用以下腳本執行實際鏈接:
nvJitLinkComplete (handle);您還可以檢索生成的鏈接立方體。為此,需要顯式的緩沖區分配。因此,您可以查詢緩沖區的大小,并使用該緩沖區獲取鏈接立方體。例如:
nvJitLinkGetLinkedCubinSize (handle, &size);
void *cubin = malloc(size);
nvJitLinkGetLinkedCubin(handle, cubin);LTO-IR 作為目標格式
JIT LTO 在基于 LLVM : LTO-IR 的中間表示格式上執行。此中間表示與 NVCC 生成的內容相同,并由離線 LTO 中的 nvlink 設備鏈接器使用( CUDA 11.2 )。 JIT LTO 的運行時鏈接輸入需要采用 LTO-IR 格式,或以包含格式嵌入 LTO-IR 。例如, LTO-IR 可以存儲在 fatbinary 中。
有兩種方法可以為 nvJitLink 庫的輸入生成 LTO-IR ,如圖 2 所示。
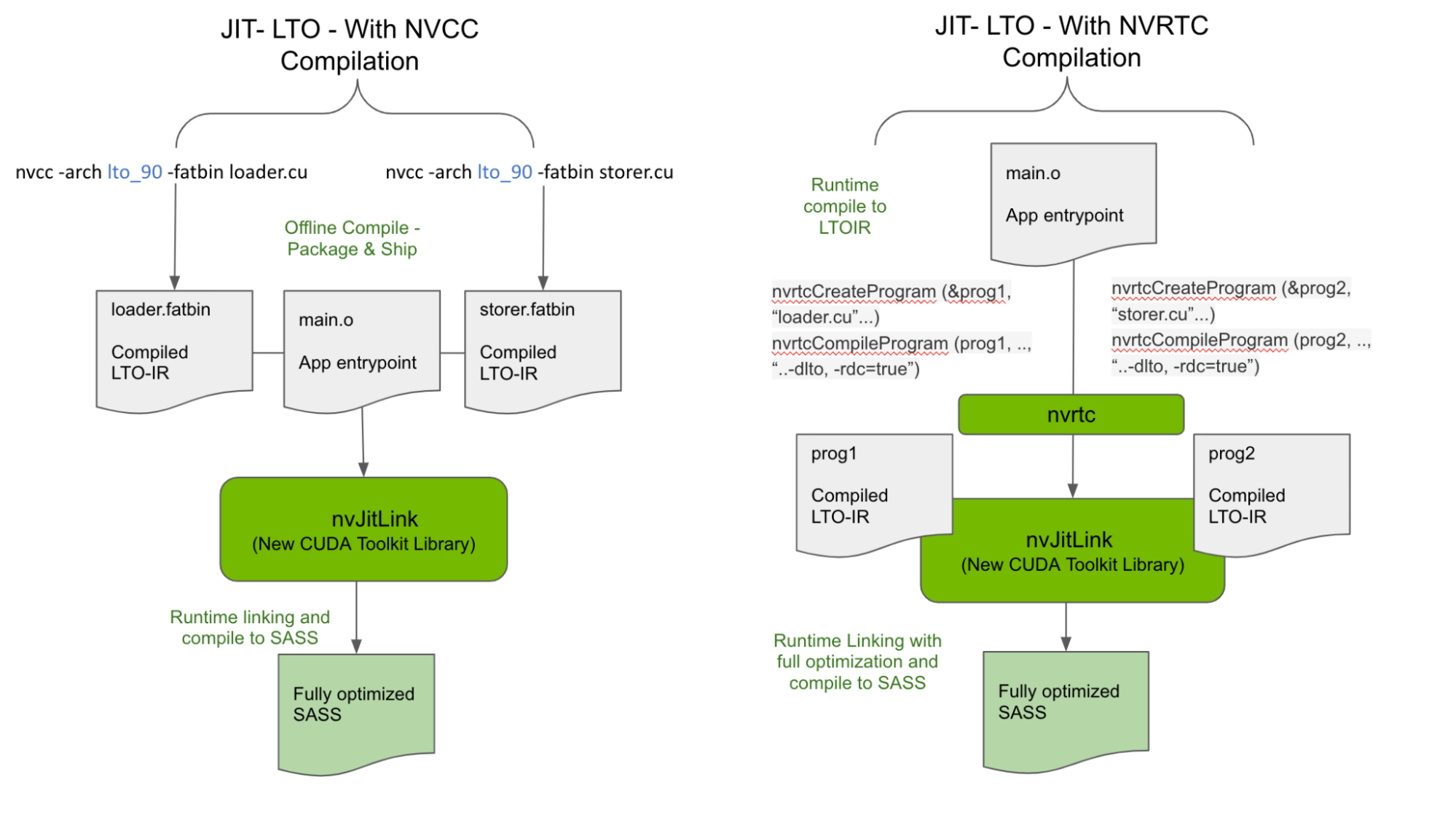
使用 NVCC 離線生成 LTO-IR
CUDA 11.2 介紹了 LTO-IR 格式,以及如何使用-dlto構建選項使用 NVCC 生成 LTO-IR 。我們將此功能保留為運行時 LTO-IR 對象有效鏈接的公認輸入形式之一。因此,離線生成的 LTO-IR 對象存儲在 fatbinary 中,如下面生成的loader.fatbin和storer.fatbin,可以在運行時鏈接起來,以獲得 LTO 的最大性能優勢。
nvcc -arch lto_90 -fatbin loader.cu? // stores LTO-IR inside a fatbinary
nvcc -arch lto_90 -fatbin storer.cu因此,應用程序和庫可以運送獨立的 LTO-IR 片段,而不是 SASS 或 PTX ,以與運行時跨多個 LTO-IR 碎片執行的優化相鏈接。注意,在運送 LTO-IR 時,需要仔細考慮目標上的 nvJitLink 庫版本。
char smbuf[16];
memset(smbuf,0,16);
sprintf(smbuf, "-arch=sm_%d", arch)
// Load the generated LTO IR and link them together
nvJitLinkHandle handle;
const char *lopts[] = {"-lto", smbuf};
nvJitLinkCreate (&handle, 2, lopts)
nvJitLinkAddFile (handle, NVJITLINK_INPUT_FATBIN, loader.fatbin);
nvJitLinkAddFile (handle, NVJITLINK_INPUT_FATBIN, storer.fatbin);
nvJitLinkComplete (handle);這種可能性打開了新的途徑,通過在運行時合成內核而不影響性能,從而顯著減少二進制大小。例如,用戶內核和庫內核的片段可以以 LTO-IR 格式單獨發送,并在運行時 JIT 鏈接和編譯到適合目標配置的單個內核。由于片段鏈接和優化在運行時發生,因此優化技術應用于用戶和庫代碼,從而最大化性能。
在運行時生成 LTO-IR
除了上面描述并如圖 2 所示的離線編譯 – 運行時鏈接模型之外, LTO-IR 對象還可以在運行時使用 NVRTC 通過在編譯時傳遞 -dlto 來完全構建,并在運行時通過 nvJitLinkAddData API 進行鏈接。 CUDA 示例的示例代碼如下所示,并對使用 nvJitLink API 進行了相關修改。
nvrtcProgram prog1, prog2;
char *ltoIR1, *ltoIR2
...
...
/* Compile using –dlto option */
const char* opts = (“--gpu-architecture=compute_80”, “--dlto”, "--relocatable-device-code=true"});
NVRTC_SAFE_CALL(nvrtcCompileProgram(&prog1, 3, opts);
NVRTC_SAFE_CALL(nvrtcCompileProgram(&prog2, 3, opts);
...
nvrtcGetLTOIRSize(prog1, <oIR1Size);
ltoIR1 = malloc(ltoIR1Size);
nvrtcGetLTOIRSize(prog2, <oIR2Size);
ltoIR2 = malloc(ltoIR2Size);
nvrtcGetLTOIR(prog1, ltoIR1);
nvrtcGetLTOIR(prog2, ltoIR2);
char smbuf[16];
memset(smbuf,0,16);
sprintf(smbuf, "-arch=sm_%d", arch)
// Load the generated LTO IR and link them together
nvJitLinkHandle handle;
const char *lopts[] = {"-lto", smbuf};
nvJitLinkCreate(&handle, 2, lopts);
nvJitLinkAddData(handle, NVJITLINK_INPUT_LTOIR,
(void *)ltoIR1, ltoIR1Size, "lto_saxpy");
nvJitLinkAddData(handle, NVJITLINK_INPUT_LTOIR,
(void *)ltoIR2, ltoIR2Size,"lto_compute");
// Call to nvJitLinkComplete causes linker to link together the
// two LTO IR modules, do optimization on the linked LTO IR,
// and generate cubin from it.
nvJitLinkComplete(handle);
. . .
// get linked cubin
size_t cubinSize;
NVJITLINK_SAFE_CALL(handle, nvJitLinkGetLinkedCubinSize(handle, &cubinSize));
void *cubin = malloc(cubinSize);
NVJITLINK_SAFE_CALL(handle, nvJitLinkGetLinkedCubin(handle, cubin));
NVJITLINK_SAFE_CALL(handle, nvJitLinkDestroy(&handle));
delete[] ltoIR1;
delete[] ltoIR2;
// cubin is linked, so now load it
CUDA_SAFE_CALL(cuModuleLoadData(&module, cubin));
CUDA_SAFE_CALL(cuModuleGetFunction(&kernel, module, "saxpy"));要查看完整的示例,請訪問 GitHub 上的 NVIDIA/cuda-samples 。
LTO-IR 對象兼容性
nvJitLink 庫直接在 LTO-IR 上執行 JIT 鏈接以生成 SASS ,從而消除了鏈接對 CUDA 驅動程序版本的依賴。處理 LTO-IR 的是 nvJitLink 庫的工具包版本,而重要的是編譯的 LTO-IR 工具包版本。
nvJitLink 庫將保留對舊 LTO-IR 的支持,但前提是它們在主要版本中。這種限制主要源于 LLVM 可能為功能或性能引入的任何破壞 ABI 的更改,這些更改可能在主要發布邊界被吸收。
然而,即使在同一主要版本中,較舊的 nvJitLink 庫也無法處理來自較新 NVCC 的 LTO-IR 。因此,目標系統上的 nvJitLink 庫版本必須始終來自 CUDA 主要版本中用于生成任何單個模塊 LTO-IR 的工具包的最高版本。
LTO-IR 目標僅在主要版本中與鏈路兼容。因此,為了跨主要版本鏈接對象,請在 PTX 或 SASS 中使用 ELF 級鏈接,遵循用例和安裝配置。為了幫助此工作流, nvJitLink 還將支持 ELF 鏈接的新 API ,類似于驅動程序提供的 cuLinkAPI 。
CUDA 和 JIT LTO 兼容性
The GTC talk on JIT LTO use case 基于基于驅動程序的解決方案。由于 cuLinkAPI 和 nvvm 優化器依賴 CUDA 驅動程序, JIT LTO 的實現不支持 CUDA 的關鍵兼容性保證。
以下部分討論了即使在使用 JIT LTO 時,如何使用新庫來利用 CUDA 兼容性保證。
CUDA 次要版本兼容性
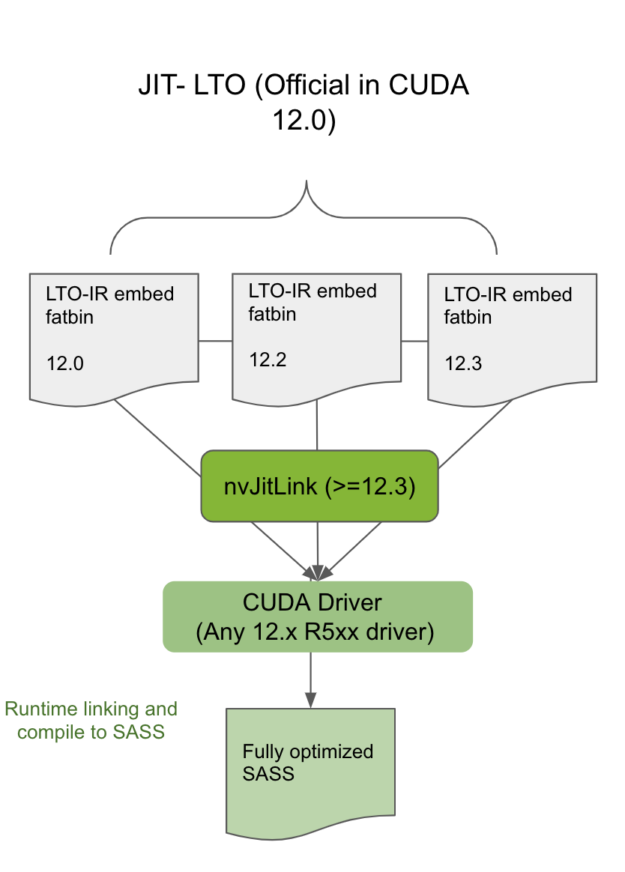
將編譯并包含 LTO-IR 的模塊與同一 CUDA 主要版本中相同或更新的工具包中的 nvJitLink 庫相鏈接,將允許使用 JIT LTO 的此類應用程序在任何次要版本兼容的驅動程序上運行(圖 3 )。從主要版本靜態或動態鏈接 nvJitLink 庫的最高版本。要確定哪個 CUDA 驅動程序是與工具包版本兼容的次要版本,請參見 CUDA 12.0 Release Notes 中的表 2 。
向后兼容性
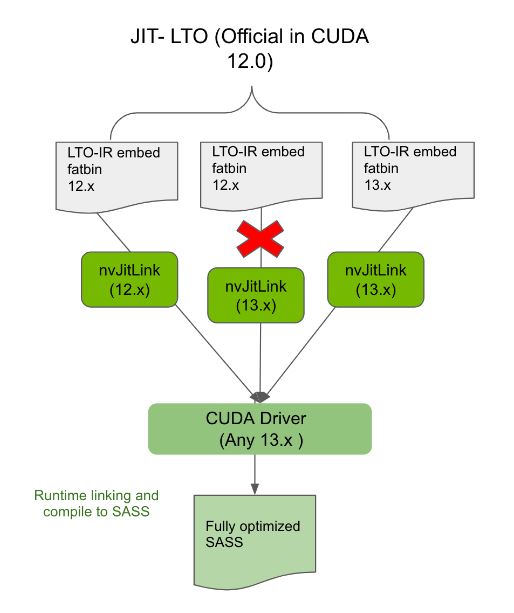
始終將編譯為 LTO-IR 的應用程序與同一主要版本的兼容 nvJitLink 庫鏈接,將確保此類應用程序在任何未來的 CUDA 驅動程序上向后兼容。例如,與 12.x nvJitLink 庫鏈接的 12.x 應用程序將在 13.x 驅動程序上運行(圖 4 )。
CUDA 前向兼容性
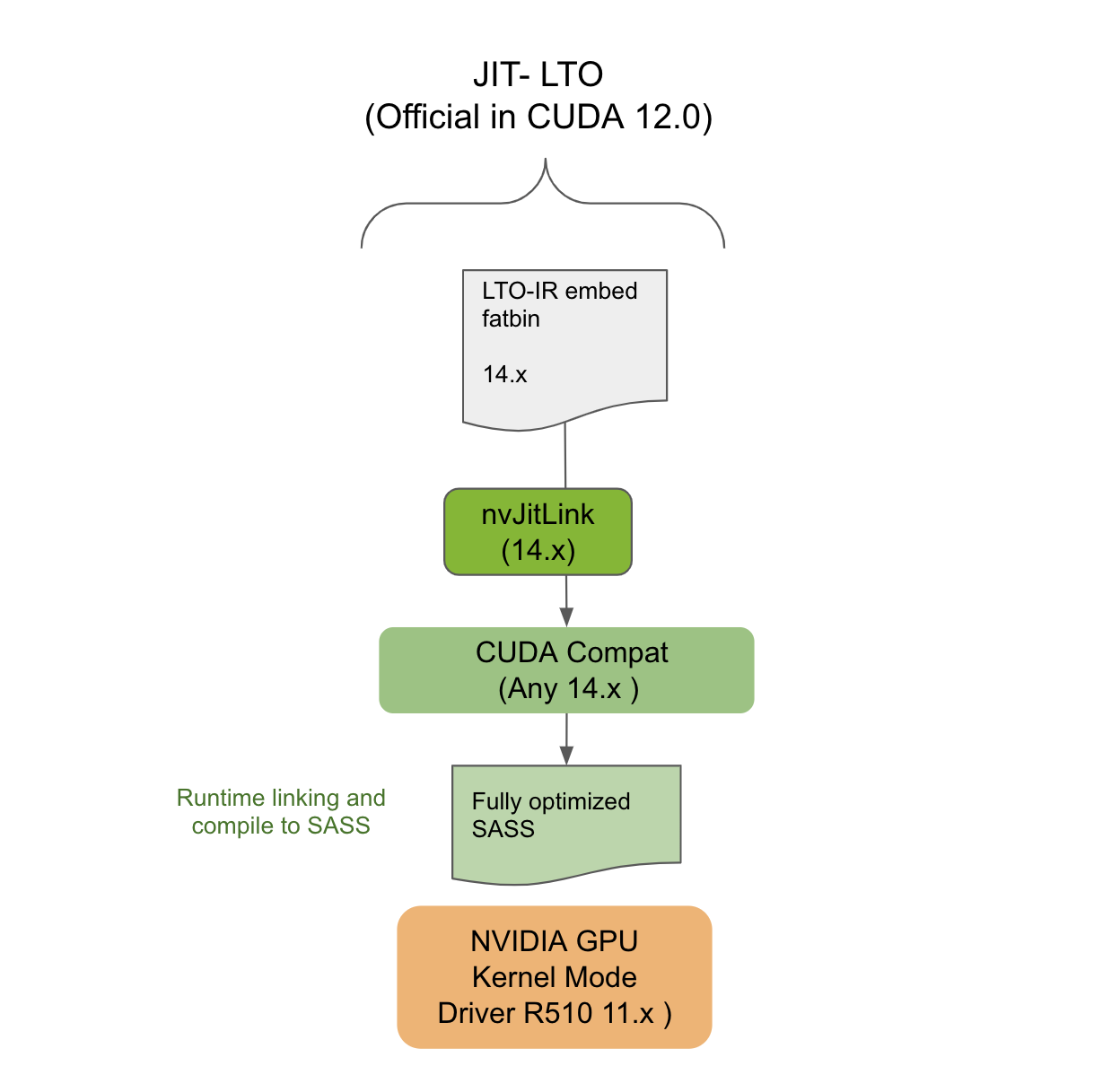
本節介紹了針對 JIT LTO 的 LTO-IR 應用程序如何仍然可以在 CUDA Forward Compatible deployment 中工作。前向兼容性旨在允許在 NVIDIA GPU 驅動程序安裝上部署最新的 CUDA 應用程序,這些應用程序來自不同主要版本的舊版本分支。例如,驅動程序屬于 10.x 時代,但應用程序來自 12.x 時代。
使用前向兼容性需要在目標系統上安裝特殊的 CUDA 兼容包。 CUDA 兼容包與 NVIDIA GPU CUDA 驅動程序關聯,但由工具包進行版本控制。為了使 CUDA 11.4 版本的 JIT LTO 工作, CUDA compat 包包含使 JIT LTO 在前向兼容模式下工作所需的組件。
然而,既然該特性是 CUDA Toolkit 新 nvJitLink 庫的一部分,那么目標系統上該庫的存在就像任何其他工具鏈依賴一樣。它必須確保其在部署系統中的存在。 nvJitLink 庫的版本必須再次與用于生成 LTO-IR 的 NVCC 或 NVRTC 的工具包版本相匹配。如圖 5 所示, JIT LTO 將在前向兼容性模式下的系統上工作。
JIT LTO 和 cuFFT
本節介紹了像 cuFFT 這樣的 NVIDIA 庫如何利用 JIT LTO 。繼續閱讀,了解 cuFFT 用戶的未來。
對于一些 CUDA 數學庫,如 cuFFT ,二進制文件的大小是提供功能和性能時的限制因素。更高的性能通常意味著運送更多的專用內核,這反過來意味著運送更大的二進制文件。例如,為數據類型、問題大小、 GPU 和轉換( R2C 、 C2R 、 C2C )的每種組合提供專用內核可能會導致二進制大小大于所有數學庫的總和。因此,在決定裝運哪些內核時必須做出決定。
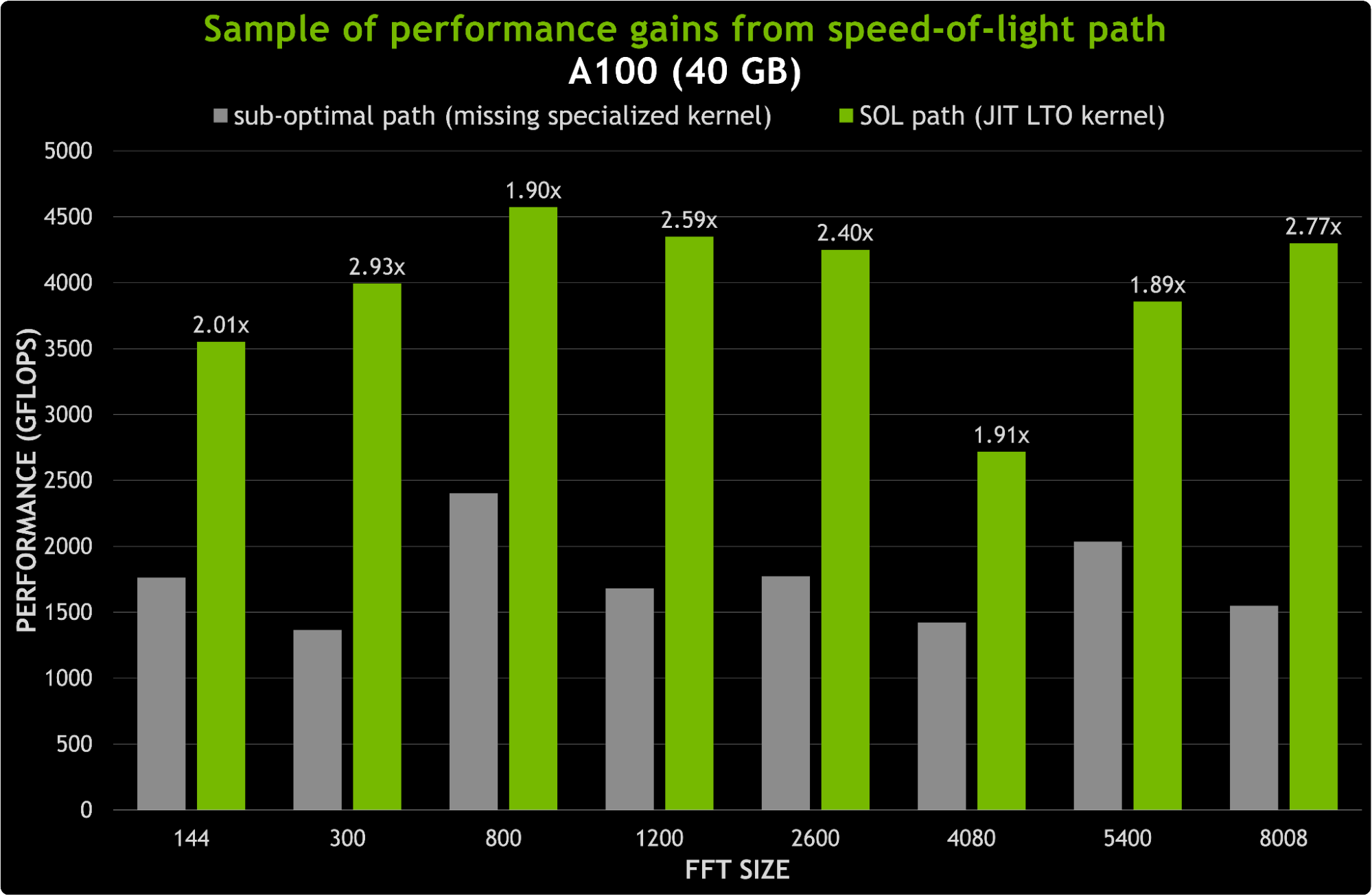
JIT LTO 通過使 cuFFT 庫能夠在運行時為任何參數組合構建 LTO 優化的光速( SOL )內核,最大限度地減少了對二進制大小的影響。這是通過運送 FFT 內核的構建塊而不是專門的 FFT 內核來實現的。圖 6 顯示了用新的 JIT LTO 內核替換次優路徑的可能加速。對于 8K 以下的尺寸,加速可以達到 3 倍。
理想的應用是在 cuFFT 內核中加入用戶回調函數。使用 JIT LTO 專門化內核消除了回調內核和非回調內核之間的區別。
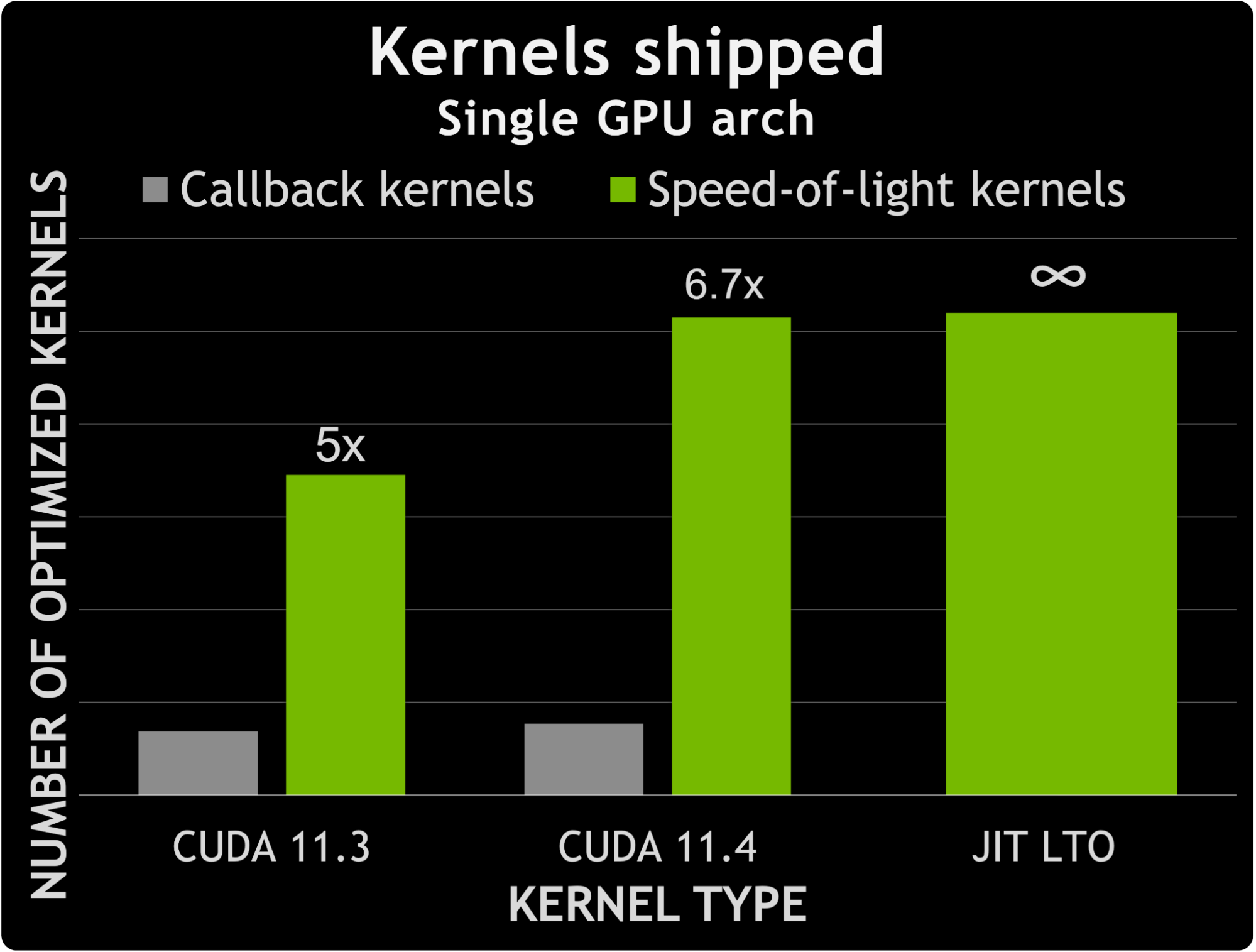
在 CUDA 11.3 和 CUDA 11.4 之間, cuFFT 發現非回調 SOL 內核的數量增加了約 50% 。相比之下,能夠處理用戶回調的內核數量增加了約 12% 。這意味著專用非回調內核數與專用回調內核數之間的差異增加了 1.6 倍。
圖 7 顯示了回調內核數量與 CUDA 11.3 和 11.4 附帶的專用內核數量之間的比較。它還提示了利用 JIT LTO 處理用戶回調所提供的可能性。實際上,專用回調內核的數量增加了近 7 倍,而不會增加內核數量所帶來的二進制大小。
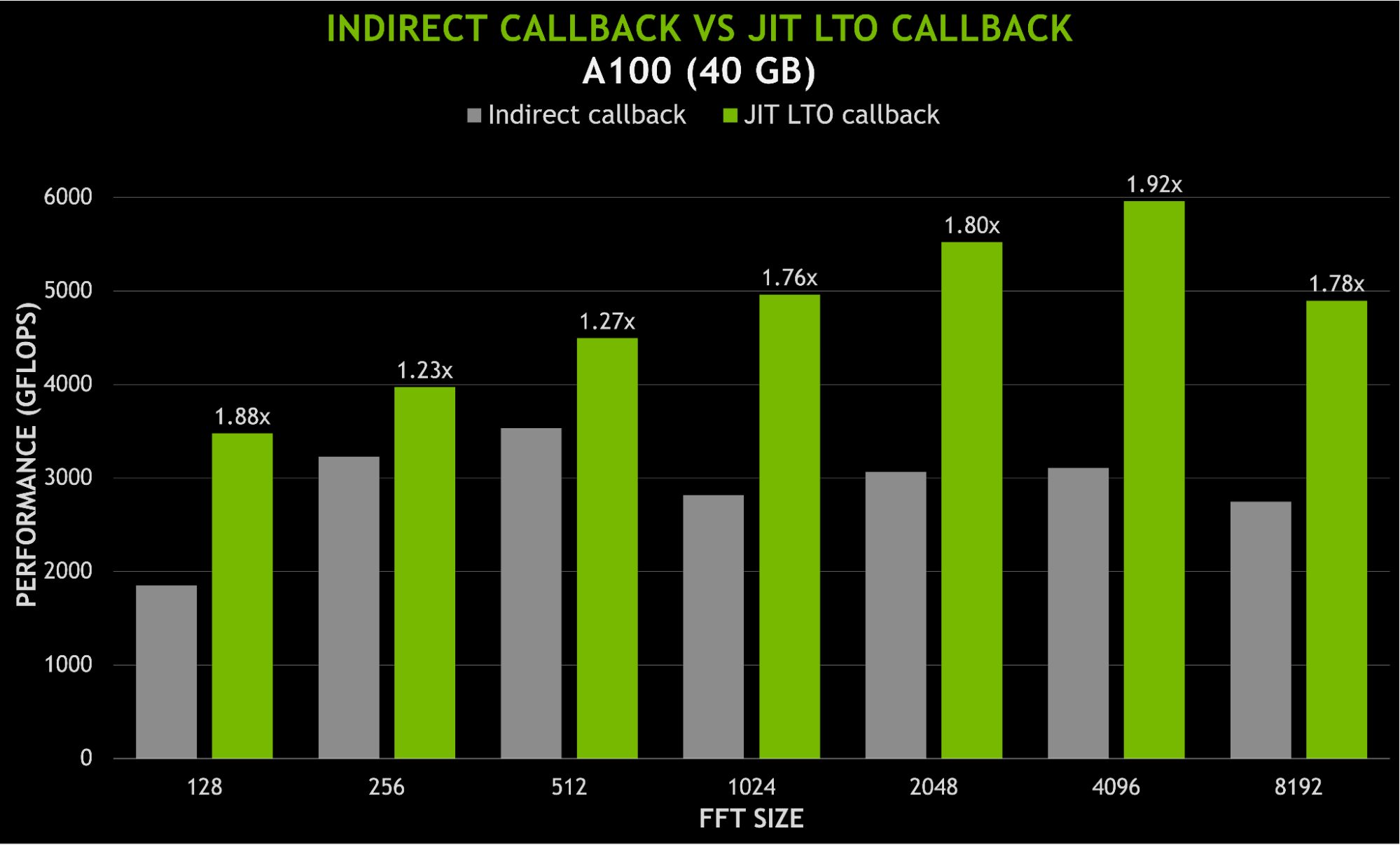
使用 JIT LTO 的另一個好處是能夠將用戶代碼與庫內核鏈接在一起,而不需要針對靜態庫進行單獨的脫機設備鏈接。由于鏈接時間優化(尤其是內聯),間接調用用戶函數所產生的任何開銷都應該最小化。圖 8 顯示了當使用 JIT LTO 回調而不是間接函數調用時,速度提高了近 2 倍。
結論
在較新的形式中, JIT LTO 應該為應用程序開發人員、庫開發人員和系統管理員提供更多好處。表 1 突出顯示了支持的不同場景,以及在使用 LTO (特別是 JIT LTO )時需要記住的約束。
| ? | Within a minor release | Across major release |
| LTO-IR | Link compatible | Not link compatible. Link at PTX or SASS Level. |
| nvJitLink library | Use the highest version of the linking objects | Not compatible for linking. Runtime JIT to link compatible object PTX or SASS. |
CUDA 兼容性和易部署性以及不可協商的性能優勢將以新的形式定義 JIT LTO 。在未來的 CUDA 版本中,為了進一步增強 JIT LTO 的性能,我們正在考慮通過緩存和其他方案來減少運行時鏈接開銷。
?