你有沒有試過在你的口音上微調語音識別系統,結果發現,雖然它能很好地識別你的聲音,但卻無法檢測到別人說的話?這在經過數十萬小時語音訓練的語音識別系統中很常見。
在大規模 自動語音識別 ( ASR )中,系統可能在許多但不是所有場景中都表現良好。例如,在嘈雜的環境中,它可能需要更高的精度。或者,它可能需要為具有濃重口音或獨特方言的用戶進行調整。
在這種情況下,一種簡單的方法是根據特定領域的樣本對模型進行微調。盡管如此,這個過程可能會嚴重損害模型在一般語音上的準確性,因為它會過度填充新的域。
本文提出了一種選擇模型的簡單方法,該模型可以在 adapter modules 和 基于傳感器的語音識別系統 的幫助下平衡普通語音的識別精度,并改進自適應域上的識別。
基于適配器模塊和傳感器的語音識別系統
神經網絡通常由多個模塊組成;例如在語音識別或自然語言處理( NLP )中通常使用的編碼器和解碼器模塊。雖然可以微調這些模塊中的所有數百萬個參數,但使用適配器模塊的參數高效訓練可以減少災難性遺忘的影響,并仍然提供強大的結果。
圖 1 顯示了基于傳感器的語音識別系統的三個主要模塊,包括 conformer 編碼器、 LSTM 解碼器(稱為傳感器解碼器)和多層感知器接頭(也稱為傳感器接頭)。它還顯示了適配器如何應用于這些組件。
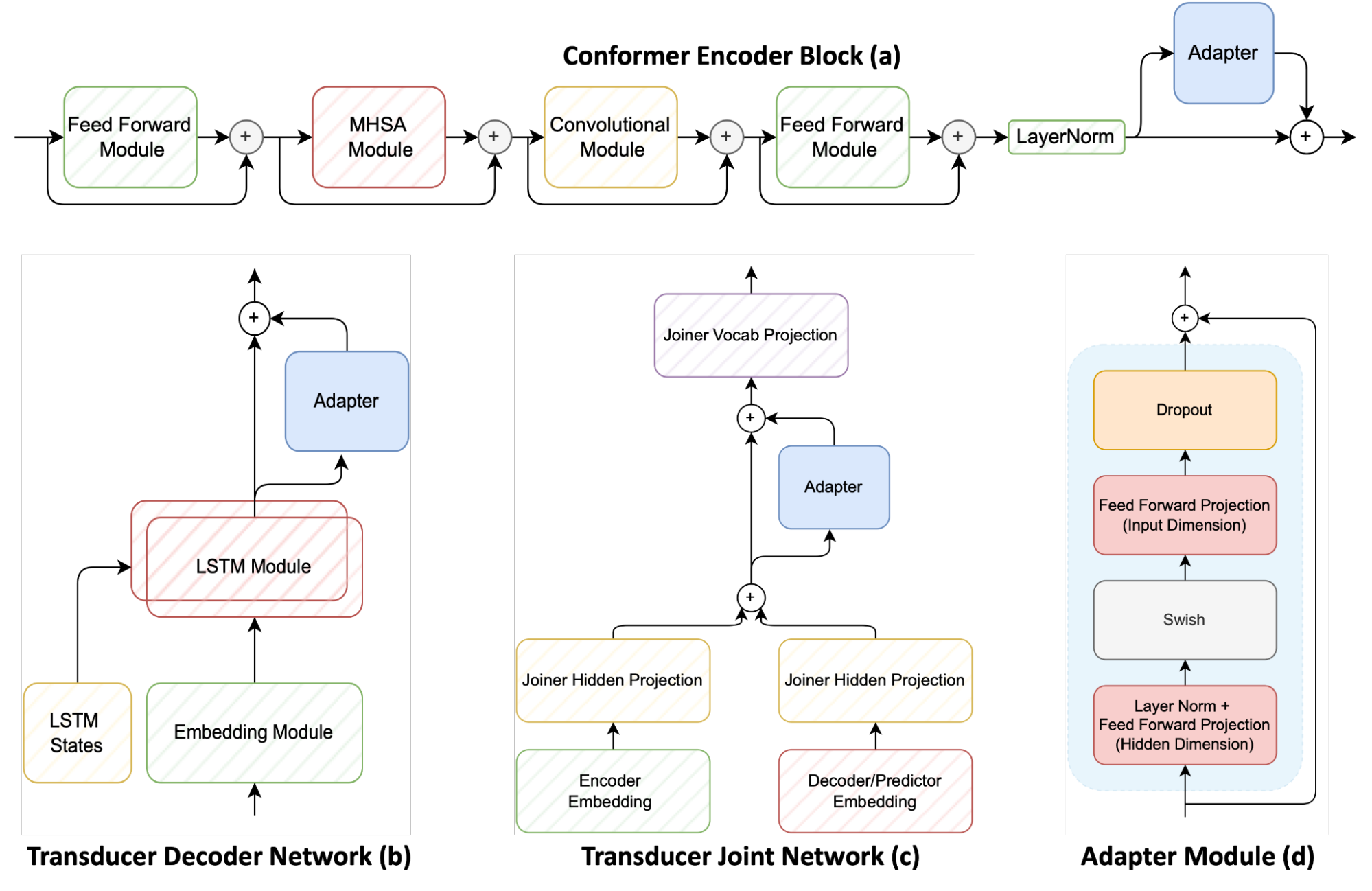
適配器模塊( d )可以是連接到預訓練神經網絡的簡單前饋網絡。這樣做會將其他模型參數添加到原始模型中。然后凍結原始模型參數并僅訓練適配器參數。
適配器網絡通常放置在每個編碼器一致性層( a )上。然而,該方法建議將適配器添加到換能器解碼器( b )和換能器聯合網絡( c ),以提供與普通語音相比在適應新域之間的精細控制。
在訓練多個候選模型之后,有必要確定哪個模型在新域(例如,具有新方言、口音或噪聲環境)的識別精度和通用語音的精度方面具有最佳折衷。
在原始域和新域的評估數據集上測量模型適應前后的精度的簡單方法如下:
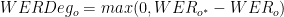
- o* , a* 表示在適配過程之后對原始和適配域的評估
- o 、 a 表示在適配過程之前相同
首先,將 WERDeg 定義為自適應前后的單詞錯誤率( WER )之間的差異。還要確保模型在適應后必須改進 WER 。否則,該值應為 0 。

- N 是原始域中評估數據集的數量
- K 是原始域上字錯誤率的最大容許絕對降級
接下來,計算原始數據集上模型的有效相對退化。首先為 K 選擇一個值,即可以接受的最大容許退化。在本例中, 3% 是最大容許降解率。
然后計算原始數據集上 K 和 WERDeg 之間的相對差值( o )。最后,將原始域中 N 個評估數據集的所有得分相加。如果在任何數據集上,模型超過退化極限 K ,則將該數據集的得分設置為 0 。
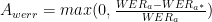
- 新領域 WER 的相對改進
- 下標指的是在將模型訓練到自適應數據集之前( a )還是之后( a* )在自適應數據集上計算度量
接下來,在自適應數據集上計算模型的相對改進。在本例中,選擇了相對權重,因為在某些情況下,在已優化的生產系統中,即使是很小的改進也可能是顯著的。

然后將得分度量計算為兩個度量的簡單乘法。在最大化時對度量進行評分會產生在新域上獲得最大改進、在舊域上退化最小的候選。
適配器對方言適應的有效性
為了評估適配器在這種受限域適配設置中的有效性,在英國和愛爾蘭英語方言數據集上適配一個 1.2 億參數的 conformer 傳感器模型。結果如圖 2 所示。
雖然簡單的微調會快速損害普通語音的識別精度,但適配器可以提供與模型的完全微調類似的結果,而不會對普通語音造成顯著惡化。
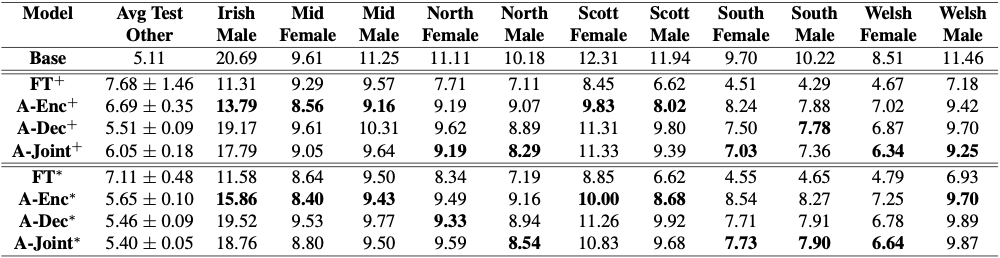
在圖 2 中,+表示模型無約束自適應(無限制微調),*表示受限域自適應。完全微調在新領域獲得最佳結果,但嚴重損害了通用語音識別。
粗體單元格表示最大化先前定義的評分度量的候選項,從而在新域上獲得強大的結果,同時最小化對一般語音識別的損害。在開放詞匯語音命令識別這一具有挑戰性的任務中,受限域自適應的效果更為明顯。
語音命令識別
接下來,語音識別模型適用于 Google 語音命令數據集中的 35 個命令詞。這 35 個命令是執行動作的常用詞,例如“走”、“停止”、“開始”和“離開”這些命令詞都是 Librispeech 訓練數據集的一部分,因此一個高度魯棒的 ASR 模型應該很容易對這些詞進行分類。然而,與最先進的語音分類模型相比,該模型的準確率大約只有 60% ,而最先進的語言分類模型可以達到接近 97% 。
人們會認為,僅限于 35 個單詞的語音識別比學習轉錄數千小時的語音更容易。事實上,這可以擴展到“開放詞匯語音命令識別”,這是一項任務,在該任務中,語言中的任何單詞都可以成為模型識別的命令。
例如,假設您希望一個模型識別一個用戶,并在該用戶說“打開芝麻”時激活。在這種情況下收集數據非常困難,但這些單詞在大型 ASR 數據集中可能足夠常見,因此 ASR 模型應該高精度地識別這些單詞。然而,這遠比預期的更具挑戰性。
適應開放詞匯關鍵詞檢測的語音識別模型
這一挑戰的原因是,與特定命令相比,轉錄一般語音的準確性存在巨大差異。這是因為模型的訓練方式與評估方式不同。
訓練語音識別模型需要使用包含幾十個單詞的 15-20 秒長的樣本。然而,當執行語音命令識別時,這些模型僅用 1 秒的音頻進行訓練和評估。訓練和評估團的這一大規模轉變嚴重影響了模型,導致了通用語音識別的災難性退化。
如果你試圖進行不受約束的改編,模型幾乎忘記了如何轉錄一般語音。然而,當使用適配器在受限場景下進行訓練時,您可以快速提高命令的識別精度,同時保持對普通語音的強大識別能力。
開放詞匯命令識別的約束自適應
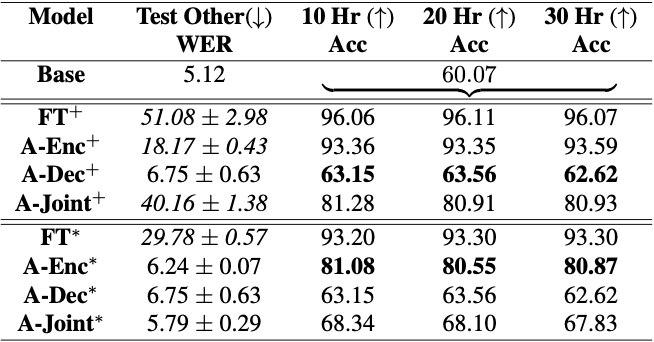
圖 3 顯示了使語音識別系統適應開放詞匯命令識別數據的困難。只要對整個模型進行微調, WER 就會從 5% 增加到近 30-50% ,從而使模型完全無法使用。盡管如此,它在數據集上的準確性從 60% 顯著提高到 96% 。然后施加約束自適應,并獲得在其先前的一般語音識別知識與準確檢測語音命令之間取得平衡的候選。
Conclusion
在受限域自適應的情況下,只需少量數據即可自適應任何預訓練模型。使用適配器進行參數有效訓練可以減少一般語音識別中災難性遺忘的影響。這一點可以通過適應大量的英語和愛爾蘭方言來體現。此外,使用這些技術可以提高開放詞匯語音命令識別的準確性。
語音識別系統適應其部署的定制需求是一項重要的努力。獲得更有效的方法來動態適應大型模型將實現高效的語音識別。很快有一天,可能只需要幾分鐘的適應數據就可以為每個用戶個性化語音識別系統,同時保持其總體準確性而不會顯著降低。
有關此工作的更多信息,請參見 基于傳感器的自動語音識別領域自適應過程中的損傷控制 。
要了解有關如何使用適配器使 ASR 模型適應新域的更多信息,請訪問 GitHub 上的 ASR_with_Adapters.ipynb NVIDIA NeMo 教程。
?