CUDA Graphs 是一種將 GPU 運算定義為圖形(而非一系列流啟動)并將其批量處理的方法。CUDA Graph 將一組 CUDA 內核和其他 CUDA 運算分組在一起,并使用指定的依賴關系樹執行這些運算。它將與 CUDA 內核啟動和 CUDA API 調用相關的驅動程序活動結合起來,從而加快工作流程。它還可以執行與硬件加速的依賴關系,而不是在可能的情況下僅依賴 CUDA 流和事件。
CUDA 圖形對于 AI 框架尤為重要,因為它們使您能夠捕獲和回放一系列 CUDA 操作,從而降低 CPU 開銷并提高性能。借助最新的改進,您現在可以更好地利用 CUDA 圖形來加速 AI 工作負載。
在 CUDA 工具包 11.8 和 CUDA 工具包 12.6 以及隨附的驅動程序版本之間,NVIDIA 在幾個方面提高了 CUDA 圖形的性能:
- 圖形構建和實例化時間
- CPU 啟動用度
- 幾種邊緣情況下的一般性能
在本文中,我們為各種圖形提供了一些微基準測試數據,并討論了自首次發布以來的改進。其中包括基準測試代碼。與往常一樣,性能特征取決于 CPU、GPU 和時鐘設置。在測試中,我們使用了 Intel Xeon Silver 4208 處理器 (@ 2.10 GHz) 和 NVIDIA GeForce RTX 3060 GPU。操作系統是 Ubuntu 22.04。本文中的結果是使用默認時鐘設置收集的。
這是 CUDA 12.6 以來性能改進的快照,因此未來 CUDA 版本可能無法展示與本文所述相同的性能。此快照假設您熟悉 CUDA 圖形及其性能特征對應用程序的影響。有關更多信息,請參閱 Getting Started with CUDA Graphs。
定義
以下是在本博文后面討論的一些圖形拓撲術語和性能特征。
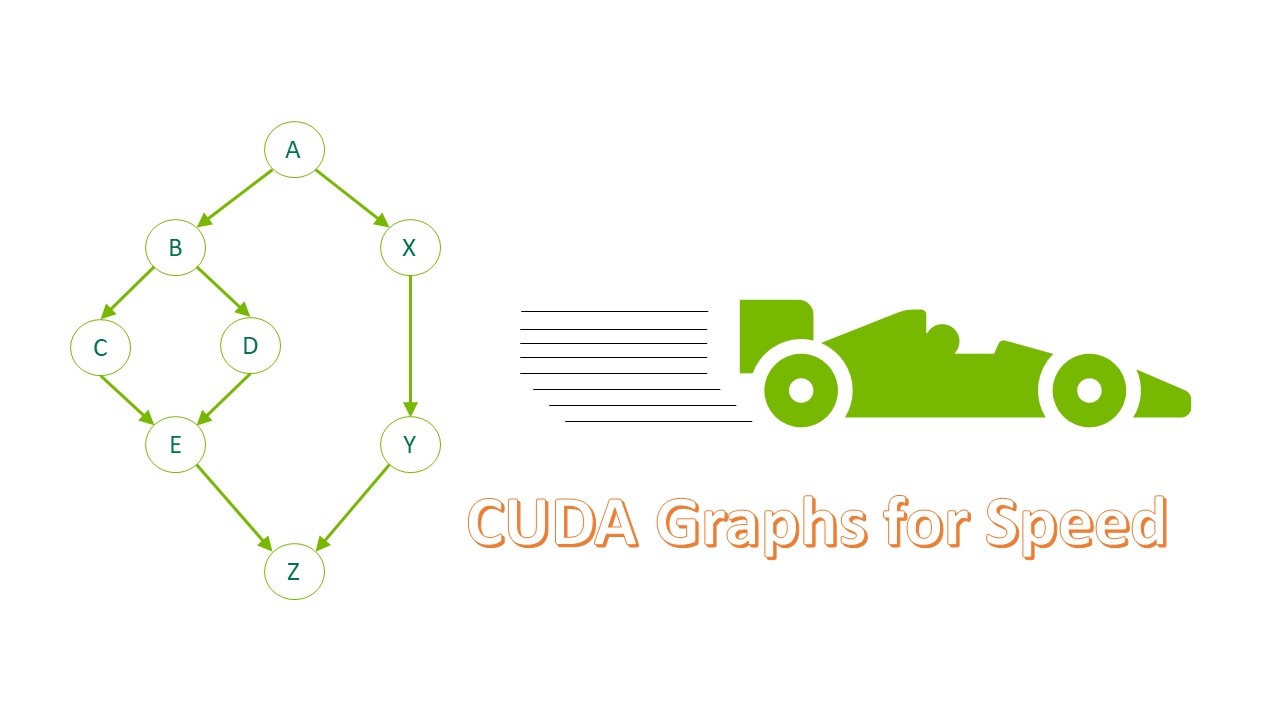
- 直線內核圖形:完全由內核節點組成的 CUDA 圖形,其中每個節點都只有一個依賴節點,除了最后一個節點。
- 并行直線:寬度為入口點數量的 CUDA 圖形。每個入口點后都有自己的一組長度,即以直線形式排列的節點數。這在圖表和源代碼中也稱為并行鏈。
- 首次啟動:首次啟動圖形,其中還包括將實例化圖形上傳到設備。
- 重復啟動:啟動已上傳至設備的圖表。
- 啟動的 CPU 開銷:調用
CUDAGraphLaunch到完成函數之間的 CPU 時間。 - 設備端運行時:設備上運行操作的時間量。
- 重復啟動設備端運行時:之前上傳的圖形在設備上運行所需的時間。
- 解決問題所需時間:從啟動調用到完成在設備上運行的圖形的時間。
重復啟動所需的恒定時間 CPU 開銷
突出顯示的一個顯著改進與在 NVIDIA Ampere 架構上重復啟動的 CPU 開銷有關。對于直線內核圖形,重復啟動期間花費的時間顯著減少。具體來說,時間從每個節點額外 2μs + 200 ns 縮短到幾乎恒定的 2.5μs + (約 1ns per node),這表明具有 10 個或更多節點的圖形的速度持續增強。
在 NVIDIA Ampere 架構之前的硬件上,啟動仍然需要 


由于這里測量的并行直線圖形有四個根節點,因此使用一個節點重復啟動需要6μs,而不是2μs。對于這個拓撲,鏈長對CPU啟動開銷的影響仍然可以忽略不計。本處不分析擁有多個根節點的確切擴展,盡管預期影響與根節點數量呈線性。同樣,非核節點的圖形具有不同的性能特征。

其他可衡量的性能提升
性能的其他幾個方面對于從圖形中受益的應用程序可能很重要:
- 實例化時間
- 首次啟動 CPU 用度
- 重復啟動設備運行時
- 重復圖形啟動到空流的端到端時間
| 指標 | 拓撲 | 拓撲長度 | 11.8 (r520.61.05) | 12.6 (r560.28.03) | 加速百分比 |
| 實例化 | 直線 | 10 | 20 uS | 16 uS | 25% |
| 100 | 168 uS | 127 uS | 32% | ||
| 1025 | 2143 uS | 1526 uS | 40% | ||
| 4 個并行鏈 | 10 | 71 uS | 58 uS | 22% | |
| 100 | 695 uS | 552 uS | 26% | ||
| 首次啟動 CPU 開銷 | 直線 | 10 | 4 uS | 4uS | 距離 0 公里 |
| 100 | 25 uS | 15 uS | 66% | ||
| 1025 | 278 uS | 175 uS | 59% | ||
| 4 個并行鏈 | 100 | 73 uS | 67 uS | 9 小時以上 | |
| 重復啟動設備運行時 | 直線 | 10 | 7 uS | 7 uS | 改善 0% |
| 100 | 61 uS | 53 uS | 性能提升 15% | ||
| 1025 | 629 uS | 567 uS | 性能提升 11% | ||
| 重復圖形啟動到空流的端到端時間 | 直線 | 10 | 12 uS | 9 uS | 性能提升 30% |
| 100 | 69 uS | 55 uS | 性能提升 25% | ||
| 1025 | 628 uS | 567 uS | 性能提升 11% |
實例化時間
圖形實例化所需的時間量在采用圖形的運行時成本中占主導地位。這是一次圖形實例化的成本。圖形創建時間通常出現在應用程序啟動的關鍵路徑上,或者對于在 GPU 上沒有運行工作時需要定期創建新圖形的工作流而言。此處的改進可能會影響應用程序的啟動時間,因為這些應用程序在程序啟動時準備了許多圖形,并最大限度地減少了對其他應用程序的端到端延遲損失,從而在其他工作執行背后隱藏圖形構建延遲。
首次啟動 CPU 用度
由于首次啟動需要負責將 CUDA 圖形的工作描述上傳至 GPU,因此仍需消耗 
重復啟動設備運行時
即使運行空內核也需要時間。針對直線圖形優化內核間延遲可縮短設備時間,高達每節點 60 ns
重復圖形啟動到空流的端到端時間
CUDA 圖形包含的邏輯允許在啟動操作處理圖形中的所有節點之前開始執行,從而隱藏部分啟動成本。因此,在完成工作的時間內,啟動開銷優勢并不完全可見。
相反,您可以看到,在求解直線圖形時,每個節點的解決時間提高了大約 60ns。
根據節點創建順序進行調度
在 CUDA 工具包 12.0 中,CUDA 開始關注節點創建順序,將其作為調度決策的一種啟發式方法。CUDA 開始傾向于為先前創建的節點調度節點操作,而不是為稍后創建的節點調度節點操作。
具體來說,根節點的順序固定了,并且刪除了按廣度優先遍歷順序排列節點的通道。該邏輯最初的設計目的是將根節點保持在圖形節點列表的開頭,并優先為GPU運行提供并行工作。
在將 memcopy 操作分配給同一復制引擎并對其進行錯誤序列化的情況下,舊的啟發式算法通常會在無意中對首個計算項目所需的 memcopy 操作進行序列化,而這些操作是后續計算任務僅需執行的 memcopy 操作。這導致圖形在可用于計算引擎的工作中出現氣泡。因此,開發者通常會刻意按順序創建圖形節點:首先創建圖形早期所需的節點,然后創建稍后所需的節點。
通過在做出一些調度決策時關注節點創建順序,CUDA 可以為您提供更好地滿足您直觀期望的調度。
微基準測試源代碼
已將微基準測試代碼添加到/NVIDIA/cuda-samples 中,作為 cudaGraphsPerfScaling 應用程序。編譯應用程序并運行包含 GPU 名稱和 CUDA 驅動程序版本的 dataCollection.bash 腳本,以生成數據。
總結
對 CUDA 圖形的新優化提出了令人信服的論據,表明它們是否在使用圖形的應用程序中轉化為實際性能改進。
在本文中,我們討論了 CUDA 11.8 之后的 CUDA 圖形性能改進。這些改進包括圖形構建和實例化時間、CPU 啟動開銷,以及各種場景中的整體性能方面的增強。
有關更多信息,請參閱以下資源:
?