推理是機器學習生命周期的重要組成部分 并在訓練模型后發生。這是一個企業從他們的人工智能投資中實現價值的時候。人工智能的常見應用包括圖像分類(“這是一張腫瘤圖像”)、推薦(“這是一部你喜歡的電影”)、將語音音頻轉錄成文本,以及決策(“將汽車轉向左側”)。
深度學習培訓系統 需要大量的計算能力,但人工智能模型經過培訓后,在生產中運行它所需的資源就更少了。在確定推理工作負載的系統需求時,最重要的因素是正在運行的模型和部署位置。這篇文章討論了這些領域,特別關注邊緣的人工智能推理。
人工智能模型推理需求
要幫助確定最佳推理部署配置,請使用以下工具: NVIDIA Triton Model Analyzer?根據正在運行的特定 AI 模型提出建議。像 NVIDIA TensorRT 這樣的推理編譯器可以通過優化模型,使其以最高吞吐量和最低延遲運行,同時保持準確性,從而減少推理的資源需求。
即使進行了這些優化, GPU 對于實現業務服務級別目標、 SLA 和推理工作負載要求仍然至關重要。 MLPerf 2.0 推理基準的結果 證明 NVIDIA GPU 比純 CPU 系統快 100 倍以上。 GPU 還可以為需要實時響應的工作負載提供所需的低延遲。
推理工作負載的部署位置
在邊緣的數據中心也可以找到推理工作負載。數據中心中運行的推理工作負載示例包括推薦系統和自然語言處理。
這些工作負載的運行方式多種多樣。例如,許多不同的模型可以從同一臺服務器同時提供服務,并且可以有成百上千甚至上萬個并發推理請求。此外,數據中心服務器通常運行人工智能推理之外的其他工作負載。
在數據中心推理系統設計方面,沒有“一刀切”的解決方案。
在邊緣位置運行的推理應用程序代表著一類重要且不斷增長的工作負載。 Edge computing 的驅動力是對低延遲、實時結果的要求,以及出于成本和安全原因減少數據傳輸的愿望。邊緣系統運行在物理上靠近數據收集或處理位置的位置,如零售店、工廠樓層和手機基站。
與數據中心推理相比,邊緣人工智能推理的系統需求更容易表達,因為這些系統通常設計為專注于狹窄范圍的推理工作負載。
邊緣推斷通常涉及攝像頭或其他傳感器收集必須采取行動的數據。這方面的一個例子是,化工廠中配備傳感器的攝像機被用來 檢測管道中的腐蝕 并在任何損壞發生之前提醒員工。
邊緣推理系統要求
人工智能培訓服務器的設計必須能夠處理大量歷史數據,以了解模型參數的正確值。相比之下,用于邊緣推斷的服務器需要處理在邊緣位置實時收集的流數據,該位置的容量較小。
因此,系統內存不需要那么大, CPU 內核的數量可以更低。網絡適配器不需要那么高的帶寬,服務器上的本地存儲可以更小,因為它不緩存任何訓練數據集。
但是,網絡和存儲都應該配置為使延遲最低,因為盡快響應的能力至關重要。
| Resource | AI training in the data center | AI inferencing at the edge |
| CPU | Fastest CPUs with high core count | Lower-power CPUs |
| GPU | Fastest GPUs with most memory, more GPUs per system | Lower-power GPU, or larger GPU with MIG, one or two GPUs per system |
| Memory | Large memory size | Average memory size |
| Storage | High bandwidth NVMe flash drive, one per CPU | Average bandwidth, lowest-latency NVMe flash drive, one per system |
| Network | Highest bandwidth network adapter, Ethernet or InfiniBand, one per GPU pair | Average bandwidth network adapter, Ethernet, one per system |
| PCIe System | Devices balanced across PCIe topology; PCIe switch for multi-GPU, multi-NIC deployments | Devices balanced across PCIe topology; PCIe switch not required |
根據定義,邊緣系統部署在傳統數據中心之外,通常位于遠程位置。環境往往在空間和權力方面受到限制。這些限制可以通過使用較小的系統和低功耗的 GPU 來滿足,例如 NVIDIA A2 。
如果推理工作負載要求更高,并且電源預算允許,則可以使用更大的 GPU ,如 NVIDIA A30 或 NVIDIA A100 。多實例 GPU ( MIG )功能使這些 GPU 能夠同時為多個推理流提供服務,從而使整個系統能夠提供高效的性能。
邊緣推斷的其他因素
除了系統要求之外,還有其他需要考慮的因素,這些因素是邊緣獨有的。
主機安全
Security 是邊緣系統的一個關鍵方面。數據中心本質上可以提供一定程度的物理控制和集中管理,以防止或減輕竊取信息或控制服務器的企圖。
在設計邊緣系統時,必須假設其部署位置沒有物理安全性,并且無法從數據中心 IT 管理系統中的許多訪問控制機制中獲益。
可信平臺模塊 ( TPM )是一種可以極大地幫助主機安全的技術。如果配置得當, TPM 可以確保系統只能使用經過數字簽名且未經更改的固件和軟件啟動。附加的安全檢查(如簽名容器)可確保應用程序未被篡改,并且可以使用安全存儲在 TPM 中的密鑰對磁盤卷進行加密。
加密
另一個重要考慮事項是加密進出邊緣系統的所有網絡流量。如 NVIDIA ConnectX 產品 中所述,帶有加密加速硬件的簽名網絡適配器可確保這種保護不會以降低數據傳輸速率為代價。
加固系統
對于某些使用情況,例如在自動化控制的工廠地板上或在電信天線塔旁邊的外殼中,邊緣系統必須在潛在的惡劣條件下運行良好,例如高溫、大沖擊和振動以及灰塵。
GPU 越來越多地提供了用于這些目的的加固服務器,因此,即使是這些極端的用例,也可以從更高的性能中受益。
選擇端到端的推理平臺
NVIDIA 已將 NVIDIA-Certified Systems 計劃擴展到包括在傳統數據中心之外運行的邊緣部署類別。這些系統的設計標準包括以下所有方面:
- NVIDIA GPU
- 提供最佳性能的 CPU 、內存和網絡配置
- 安全和遠程管理功能
合格系統目錄 有一份由 NVIDIA partners 提供的經 NVIDIA 認證的系統列表。該列表可以按系統類別進行篩選,包括以下最適合推理工作負載的類別:
- 數據中心服務器 在各種數據科學工作負載上都經過了性能和擴展功能驗證,非常適合數據中心推斷。
- 企業邊緣系統 設計用于在受控環境中部署,例如零售店的后臺辦公室。這類系統在類似數據中心的環境中進行測試。
- 工業邊緣系統 專為工業或崎嶇環境而設計,如工廠地板或手機基站。獲得該認證的系統必須在系統設計環境中運行時通過所有測試,例如典型數據中心范圍之外的高溫環境。
除了為 edge 認證系統外, NVIDIA 還開發了企業軟件來運行和管理推理工作負載。
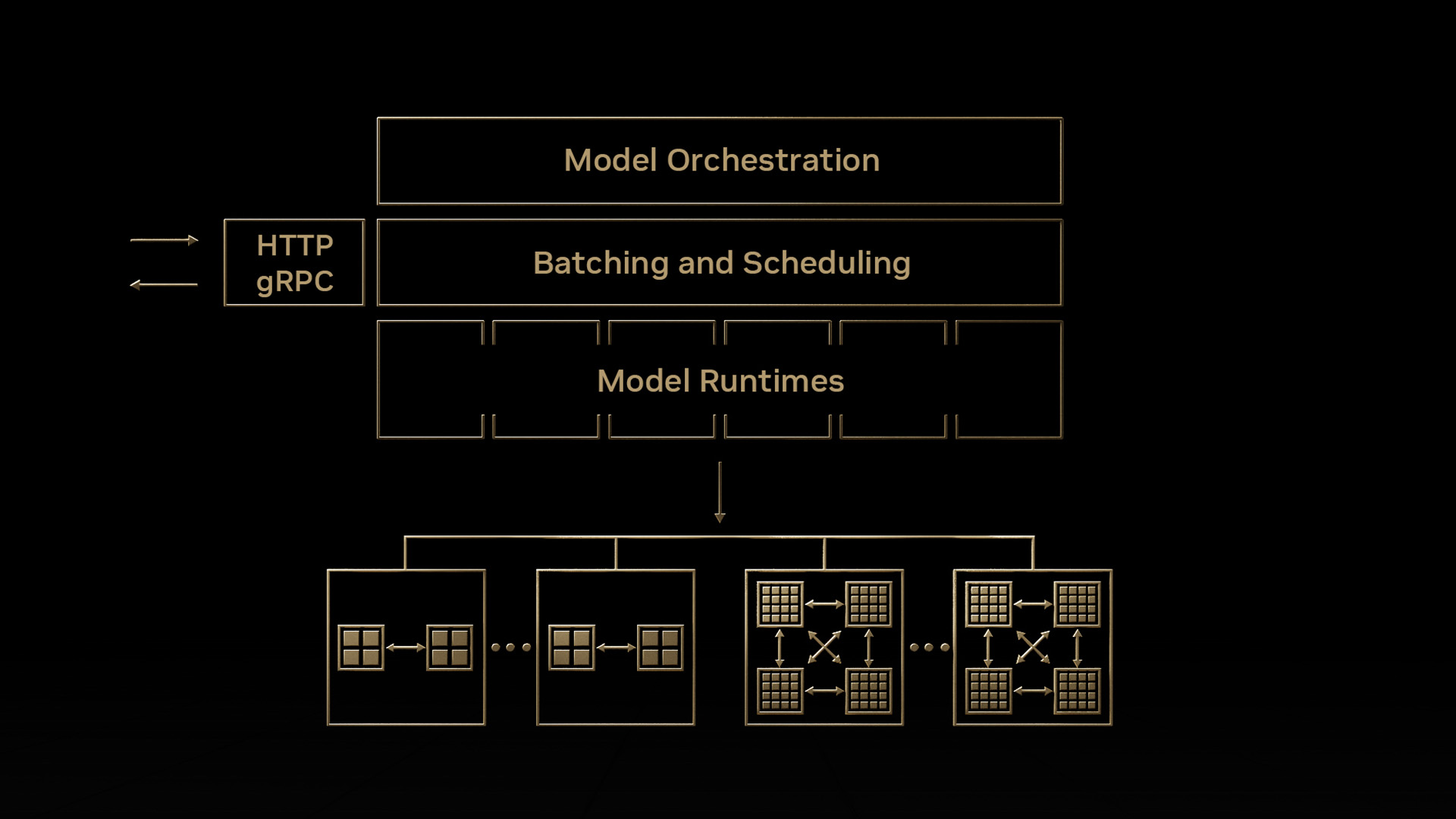
NVIDIA Triton 推理服務器 通過使團隊能夠在任何基于 GPU 或 CPU 的基礎設施上從任何框架部署、運行和擴展經過培訓的人工智能模型,簡化人工智能推理。它可以幫助您跨云、本地、邊緣和嵌入式設備提供高性能推理。
NVIDIA 人工智能企業 是一套端到端、云計算原生的人工智能和數據分析軟件,經過優化,因此每個組織都可以擅長人工智能,經認證可在數據中心和邊緣位置部署。它包括全球企業支持,使人工智能項目保持正常運行。
NVIDIA Fleet Command 是一種云服務,集中連接邊緣位置的系統,從一個儀表板安全地部署、管理和擴展人工智能應用程序。它是一個具有多層安全協議的交鑰匙,可以在數小時內完全運行。
通過選擇一個由認證系統和基礎設施軟件組成的端到端平臺,您可以啟動人工智能生產部署,部署和運行推理應用程序,比嘗試從單個組件組裝解決方案要快得多。
了解有關 NVIDIA AI 推理平臺的更多信息
當涉及到深度學習推理時,會涉及更多內容。 NVIDIA 人工智能推理平臺技術概述 對此主題進行了深入討論,包括端到端深度學習工作流的視圖、將支持人工智能的應用程序從原型部署到生產部署的細節,以及用于構建和運行人工智能推理應用程序的軟件框架。
報名參加 邊緣人工智能新聞 及時了解最新趨勢、客戶用例和技術演練。
?