<xmp id="om0om">
<td id="om0om"></td>
<table id="om0om"><noscript id="om0om"></noscript></table>
DEVELOPER
首頁
博客
論壇
論壇 (英文)
文檔
下載
培訓
Search
Join
Technical Blog
Subscribe
數據科學
2025年 7月 23日
在 Azure 上使用 Apache Spark 和 NVIDIA AI 進行無服務器分布式數據處理
將大量文本庫轉換為數字表示 (稱為嵌入) 的過程對于生成式 AI 至關重要。從語義搜索和推薦引擎到檢索增強生成 (RAG) ,
2 MIN READ
在 Azure 上使用 Apache Spark 和 NVIDIA AI 進行無服務器分布式數據處理
2025年 7月 18日
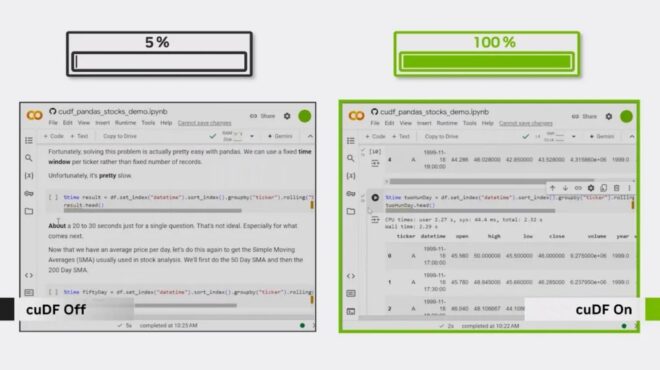
3 個 pandas 工作流在大型數據集上嚴重變慢,直到啟用了 GPU 加速
如果您使用 pandas,您可能已經撞到了墻壁。正是在這個時刻,您值得信賴的工作流程在處理較小的數據集時表現出色,在處理大型數據集時陷入停頓。
1 MIN READ
3 個 pandas 工作流在大型數據集上嚴重變慢,直到啟用了 GPU 加速
2025年 7月 17日
大規模特征工程:利用 NVIDIA CUDA-X 數據科學優化半導體制造的機器學習模型
在上一篇博文中,我們介紹了芯片制造和運營中的預測建模設置,重點介紹了數據集不平衡等常見挑戰,以及對更細致的評估指標的需求。
2 MIN READ
大規模特征工程:利用 NVIDIA CUDA-X 數據科學優化半導體制造的機器學習模型
2025年 7月 11日
使用 NVIDIA Earth-2 預測兩周以上的天氣
能夠預測極端天氣事件至關重要,因為此類條件變得更加常見且更具破壞性。次季節性氣候預測 (預測未來兩周或兩周以上的天氣)…
2 MIN READ
使用 NVIDIA Earth-2 預測兩周以上的天氣
2025年 7月 10日
從 TB 級到一站式解決方案:AI 驅動的氣候模型走向主流
在了解地球不斷變化的氣候的競賽中,速度和準確性至關重要。但當今使用最廣泛的氣候模擬器往往難以滿足需求:由于計算能力的限制,
2 MIN READ
從 TB 級到一站式解決方案:AI 驅動的氣候模型走向主流
2025年 7月 9日
為 NVIDIA CUDA 內核融合提供 Python 中缺失的構建模塊
CUB 和 Thrust 等 C++ 庫提供高級構建塊,使 NVIDIA CUDA 應用和庫開發者能夠編寫跨架構可移植的光速代碼。
2 MIN READ
為 NVIDIA CUDA 內核融合提供 Python 中缺失的構建模塊
2025年 7月 7日
提出一個維基百科規模的問題:如何利用數百萬 token 的實時推理使世界更加智能
現代 AI 應用越來越依賴于將龐大的參數數量與數百萬個令牌的上下文窗口相結合的模型。無論是經過數月對話的 AI 智能體、
3 MIN READ
提出一個維基百科規模的問題:如何利用數百萬 token 的實時推理使世界更加智能
2025年 7月 3日
RAPIDS 新增 GPU Polars 串流、統一 GNN API 和零代碼 ML 加速功能
RAPIDS 是一套用于 Python 數據科學的 NVIDIA CUDA-X 庫,發布了 25.06 版本,引入了令人興奮的新功能。
2 MIN READ
RAPIDS 新增 GPU Polars 串流、統一 GNN API 和零代碼 ML 加速功能
2025年 7月 1日
適用于有效 FP8 訓練的按張量和按塊擴展策略
在本博文中,我們將分解主要的 FP8 縮放策略 (按張量縮放、延遲和電流縮放以及按塊縮放 (包括 Blackwell 支持的 MXFP8…
2 MIN READ
適用于有效 FP8 訓練的按張量和按塊擴展策略
2025年 6月 27日
AI 分析護士觀察記錄以降低患者危險
研究人員開發了一款 AI 賦能的工具,可以分析護士的輪班筆記,從而比傳統方法更早地識別入院患者的健康狀況可能惡化或處于“崩潰”的邊緣…
1 MIN READ
AI 分析護士觀察記錄以降低患者危險
2025年 6月 27日
如何在 Polars GPU 引擎中處理超過 VRAM 的數據
在量化金融、算法交易和欺詐檢測等高風險領域,數據從業者經常需要處理數百 GB 的數據,才能快速做出明智的決策。
1 MIN READ
如何在 Polars GPU 引擎中處理超過 VRAM 的數據
2025年 6月 25日
提高嵌入模型準確性,實現定制化信息檢索
自定義嵌入模型對于有效的信息檢索至關重要,尤其是在處理法律文本、病歷或多輪客戶對話等特定領域的數據時。通用、
2 MIN READ
提高嵌入模型準確性,實現定制化信息檢索
2025年 6月 25日
如何使用 NVIDIA NeMo 技能簡化復雜的 LLM 工作流程
改進 LLM 的典型方法涉及多個階段:合成數據生成 (SDG) 、通過監督式微調 (SFT) 或強化學習 (RL) 進行模型訓練以及模型評估。
4 MIN READ
如何使用 NVIDIA NeMo 技能簡化復雜的 LLM 工作流程
2025年 6月 18日
NVIDIA 在制造和運營領域的 AI 應用:借助 NVIDIA CUDA-X 數據科學加速 ML 模型
從晶圓制造和電路探測到封裝芯片測試,NVIDIA 利用數據科學和機器學習來優化芯片制造和運營工作流程。這些階段會產生 TB 級的數據,
3 MIN READ
NVIDIA 在制造和運營領域的 AI 應用:借助 NVIDIA CUDA-X 數據科學加速 ML 模型
2025年 6月 18日
借助 NVIDIA NIM 推理微服務和 ITMonitron 實現實時 IT 事故檢測和情報
在當今快節奏的 IT 環境中,并非所有事件都始于明顯的警報。這些問題可能始于細微的分散信號、錯過的警報、悄無聲息的 SLO 漏洞,
2 MIN READ
借助 NVIDIA NIM 推理微服務和 ITMonitron 實現實時 IT 事故檢測和情報
2025年 6月 16日
人工智能致力于為法律領域帶來秩序
斯坦福大學的一個研究團隊開發了一個 LLM 系統,以減少官樣文章。 被稱為“System for Statutory Research”…
1 MIN READ
人工智能致力于為法律領域帶來秩序
加載更多
人人超碰97caoporen国产
Search
Join
首頁
博客
論壇
論壇 (英文)
文檔
下載
培訓