<xmp id="om0om">
<td id="om0om"></td>
<table id="om0om"><noscript id="om0om"></noscript></table>
DEVELOPER
首頁
博客
論壇
論壇 (英文)
文檔
下載
培訓
Search
Join
數據科學
2025年 5月 8日
云端 Apache Spark 加速深度學習和大語言模型推理
Apache Spark 是用于大數據處理和分析的行業領先平臺。隨著非結構化數據(documents、emails、
4 MIN READ
云端 Apache Spark 加速深度學習和大語言模型推理
2025年 5月 7日
使用 Python 通過 OpenUSD 實現 3D 工作流自動化
通用場景描述 (OpenUSD) 提供了一個強大、開放且可擴展的生態系統,用于在復雜的 3D 世界中進行描述、合成、仿真和協作。
2 MIN READ
使用 Python 通過 OpenUSD 實現 3D 工作流自動化
2025年 5月 7日
使用 NVIDIA NeMo Curator 構建 Nemotron-CC:一個高質量萬億令牌數據集,用于大型語言模型預訓練,源自 Common Crawl
對于想要訓練先進的 大語言模型 (LLM) 的企業開發者而言,整理高質量的預訓練數據集至關重要。為了讓開發者能夠構建高度準確的 LLM,
2 MIN READ
使用 NVIDIA NeMo Curator 構建 Nemotron-CC:一個高質量萬億令牌數據集,用于大型語言模型預訓練,源自 Common Crawl
2025年 5月 2日
CUDA 入門教程:更簡單的介紹 (更新版)
注意:本博文最初發布于 2017 年 1 月 25 日,但已進行編輯以反映新的更新。 本文非常簡單地介紹了 CUDA,
5 MIN READ
CUDA 入門教程:更簡單的介紹 (更新版)
2025年 5月 1日
借助超參數優化實現堆疊泛化:使用 NVIDIA cuML 在15分鐘內最大化準確性
堆疊泛化是機器學習 (ML) 工程師廣泛使用的技術,通過組合多個模型來提高整體預測性能。另一方面,超參數優化 (HPO)…
3 MIN READ
借助超參數優化實現堆疊泛化:使用 NVIDIA cuML 在15分鐘內最大化準確性
2025年 4月 29日
Kaggle 大師揭秘數據科學超能力的獲勝策略
來自 NVIDIA 的 Kaggle Grandmaster David Austin 和 Chris Deotte 以及 HP 的…
2 MIN READ
Kaggle 大師揭秘數據科學超能力的獲勝策略
2025年 4月 29日
構建應用程序以安全使用 KV 緩存
在與基于 Transformer 的模型 (如 大語言模型 (LLM) 和 視覺語言模型 (VLM)) 交互時,輸入結構會塑造模型的輸出。
2 MIN READ
構建應用程序以安全使用 KV 緩存
2025年 4月 23日
NVIDIA cuPyNumeric 25.03 現已完全開源,支持 PIP 和 HDF5
NVIDIA cuPyNumeric 是一個庫,旨在為基于 Legate 框架構建的 NumPy 提供分布式和加速的插入式替換。
2 MIN READ
NVIDIA cuPyNumeric 25.03 現已完全開源,支持 PIP 和 HDF5
2025年 4月 17日
頂級大師專業提示:使用 NVIDIA cuDF-pandas 進行特征工程,在 Kaggle 競賽中奪冠
在處理表格數據時,特征工程仍然是提高模型準確性的最有效方法之一。與 NLP 和計算機視覺等神經網絡可以從原始輸入中提取豐富模式的領域不同,
2 MIN READ
頂級大師專業提示:使用 NVIDIA cuDF-pandas 進行特征工程,在 Kaggle 競賽中奪冠
2025年 4月 16日
在大型語言模型時代,通過消息量化和流式傳輸實現高效的聯邦學習
聯邦學習 (Federated Learning, FL) 已成為一種在分布式數據源中訓練機器學習模型的有前景的方法,同時還能保護數據隱私。
2 MIN READ
在大型語言模型時代,通過消息量化和流式傳輸實現高效的聯邦學習
2025年 4月 15日
NVIDIA Llama Nemotron 超開放模型實現突破性的推理準確性
AI 不再只是生成文本或圖像,而是要針對商業、金融、客戶和醫療健康服務中的現實應用進行深度推理、詳細解決問題并實現強大的適應性。
2 MIN READ
NVIDIA Llama Nemotron 超開放模型實現突破性的推理準確性
2025年 4月 11日
使用 NVIDIA NIM 管理科學文獻中的生物研究成果
科學論文多種多樣,通常為同一實體使用不同的術語,使用不同的方法來研究生物現象,并在不同的上下文中展示研究結果。
2 MIN READ
使用 NVIDIA NIM 管理科學文獻中的生物研究成果
2025年 4月 11日
借助 NVIDIA FLARE 和 Meta ExecuTorch,在移動設備上輕松進行聯邦學習
NVIDIA 和 Meta 的 PyTorch 團隊宣布開展突破性合作,通過集成 NVIDIA FLARE 和 ExecuTorch ,
3 MIN READ
借助 NVIDIA FLARE 和 Meta ExecuTorch,在移動設備上輕松進行聯邦學習
2025年 4月 10日
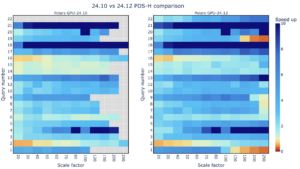
高效擴展 Polars 的 GPU Parquet 讀取器
在處理大型數據集時,數據處理工具的性能變得至關重要。 Polars 是一個以速度和效率聞名的開源數據操作庫,提供由 cuDF 驅動的 GPU…
2 MIN READ
高效擴展 Polars 的 GPU Parquet 讀取器
2025年 4月 7日
使用合成數據評估和增強 RAG 工作流性能
隨著 大語言模型 (LLM) 在各種問答系統中的普及, 檢索增強生成 (RAG) 流程也成為焦點。
1 MIN READ
使用合成數據評估和增強 RAG 工作流性能
2025年 4月 3日
使用 GPU 加速 Apache Spark 上的 Apache Parquet 掃描
隨著各行各業企業的數據規模不斷增長, Apache Parquet 已成為一種重要的數據存儲格式。
3 MIN READ
使用 GPU 加速 Apache Spark 上的 Apache Parquet 掃描
加載更多
人人超碰97caoporen国产