
視頻質量指標用于評估視頻內容的保真度。它們提供一致的量化測量,用于評估編碼器的性能。
- 峰值信噪比 (PSNR):一種評估圖像質量的老牌指標,用于比較參考圖像的像素值與降質的圖像。
- 結構相似性指數測量 (SSIM) :比較降質圖像的亮度、對比度和結構與原始圖像。
- 視頻多方法評估融合 (VMAF):這一指標由 Netflix 推出,旨在準確捕捉人類視覺感知。
VMAF 將人類視覺建模與不斷發展的機器學習技術相結合,使其能夠適應新內容 .VMAF 通過結合視頻質量因素的詳細分析和人類視覺建模以及先進的機器學習,很好地契合了人類視覺感知。
本文展示了 CUDA 加速的 VMAF(VMAF-CUDA)如何在 NVIDIA GPU 上計算 VMAF 分數。VMAF 圖像特征提取器被移植到 CUDA,使其能夠使用?NVIDIA 視頻編解碼器 SDK。我們觀察到開源工具 FFmpeg 的吞吐量提高了 4.4 倍,4K 時的延遲降低了 37 倍。加速現在正式成為?VMAF 3.0?和?FFmpeg v6.1。
VMAF-CUDA 的實現是 NVIDIA 和 Netflix 成功開源協作的結果。該協作的成果包括擴展的 libvmaf API(帶有 GPU 支持)、libvmaf CUDA 特征提取器以及附帶的上游 FFmpeg 過濾器 libvmaf_cuda.VMAF-CUDA 必須從源代碼構建。使用 Dockerfile.cuda 作為所有必需庫和步驟的參考。
VMAF 關鍵基本指標
VMAF 使用參考圖像和扭曲圖像中的關鍵基本指標來評估視頻質量:
- 視覺信息保真度 (VIF):量化保留原始內容的程度,反映感知信息損失。
- 增量失真測量 (ADM):評估結構變化和紋理破壞情況。尤其對增量扭曲(如噪聲)敏感。
- 運動特征:對于評估動態場景中的動作渲染質量至關重要。
這些指標作為支持向量機 (SVM) 回歸器的輸入特征,將它們融合在一起,以計算最終的 VMAF 評分。這種方法可確保視頻質量的全面、準確表達。
VIF 和 ADM 等特征提取器不需要任何先前信息。它們只需要作為輸入的參考幀和變形幀即可。與其他兩種不同,動態特征提取還需要前一次動態特征提取器迭代的信息 (幀間依賴性)。
GPU 和 CPU 上的 VMAF 實現
VMAF 的 CPU 實現可以將上述特征的計算分配到多個線程中,因此 VMAF 計算可以受益于更多的 CPU 核心 .CPU 實現的 VMAF 計算取決于要提取的最慢特征 (圖 1)。
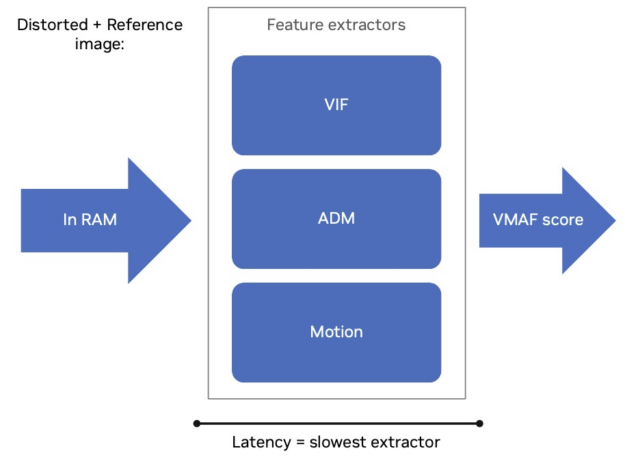
此外,動作特征評分計算具有時間依賴性,因此無法多線程。因此,每幀 VMAF 評分延遲與使用的線程數無關。性能分析表明,VIF 通常需要更長的計算時間,因此它是限制性特征提取器。然而,使用更多線程可以提高每秒幀數 (FPS) 的 VMAF 吞吐量。
VMAF 最近已移植到使用 NVIDIA GPU 的 CUDA 上運行。VMAF-CUDA 需要 CUDA 工具包,但除了 GPU 驅動程序之外,不需要其他額外庫進行部署。
與 CPU 實現相比,VMAF-CUDA 采用了不同的方法 .CUDA 實現不會將 GPU 計算資源分配給特定的特征提取器,而是為每個特征分配整個 GPU 計算資源,并按順序計算 (圖 2)。
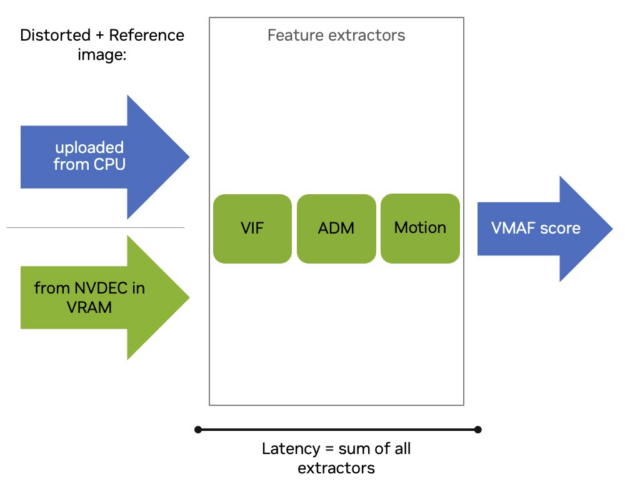
這會加快每個特征的計算速度,使得 VMAF 評分延遲現在取決于所有特征提取器的總和 .CUDA 實現加速了特征提取器,并且兼容不同的 VMAF 功能,例如支持 VMAF 模型 VMAF 4K 和 VMAF NEG。
VMAF-CUDA 可以作為使用 VMAF-CPU 的現有管線的替代品。如果圖像位于 CPU 內存中,它會立即上傳到 GPU。整個 GPU 實施包括從 GPU 到 GPU 的特征提取器計算和內存傳輸。它與 CPU 異步運行。
NVIDIA 還利用 VMAF-CUDA 作為加速 PSNR 計算的機會。通常,VMAF 和 PSNR 會同時計算。我們的研究指出,如果 PSNR 在 CPU 上運行,它將成為瓶頸,因為它需要通過 PCIe 總線從 GPU 內存中獲取解碼圖像。PCIe 傳輸速度有限,嚴重影響了性能。為此,可以在 GPU 上計算 PSNR,以實現加速,例如通過 CUDA 加速 PSNR#1175?補丁。
VMAF-CUDA 的優勢
VMAF-CUDA 可在編碼期間使用 . NVIDIA GPU 可在 NVENC 和 NVDEC 之外獨立運行 GPU 核心的計算工作負載。NVENC 可消耗原始視頻幀,而 NVDEC 可將輸出幀轉換為視頻內存。這表示,參考幀和扭曲幀都在視頻內存中,可以輸入到 VMAF-CUDA (圖 2)。因此,編碼期間可以計算 VMAF,因為 NVENC 不需要 GPU 計算資源。
它還可用于質量監控。在將 H.264 比特流轉換為 H.265 時,NVDEC 會解碼輸入比特流并將其幀寫入 GPU VRAM (參考幀)。這個參考幀使用 NVENC 編碼為 H.265,可以直接解碼,從而產生扭曲的幀。這個過程會使 GPU 上的轉碼處于空閑狀態,同時保留在 GPU 內存中的數據 .VMAF-CUDA 可以利用這些空閑資源并計算評分,而不會中斷轉碼,也不會產生額外的內存傳輸。因此,與 CPU 實現相比,它是一個經濟高效的選擇。
VMAF-CUDA 與 FFmpeg v6.1 完全集成,支持 GPU 幀 硬件加速解碼。FFmpeg 是一款行業標準的開源工具,用于處理多媒體文件和視頻流。通過從源構建 VMAF 和 FFmpeg,您只需要最新的 NVIDIA GPU 驅動程序進行執行,而無需掌握 CUDA 的任何先前知識。
在 Docker 容器中的使用使得依賴項處理和編譯變得十分便捷且可移植。FFmpeg 中的 VMAF-CUDA 在 GPU 上異步執行,從而釋放 CPU 用于執行其他任務。
評估
我們使用 VMAF-CUDA 測量了兩個指標:
- 每幀 VMAF 延遲:計算三個特征提取器以獲得一幀的 VMAF 評分所需的時間。
- 總吞吐量:如何快速計算視頻序列的 VMAF 評分。
所用的硬件是一個 56C/112T 雙英特爾至強 8480 計算節點和一個 NVIDIA L4 GPU。
VMAF 延遲改進
使用 NVIDIA 工具擴展程序 (NVTX) 來測量幀級特征提取器的延遲,該程序被放置在 VMAF 庫中的特定范圍內(libvmaf)。此外,還利用 Nsight Systems 工具來捕獲追蹤,這些追蹤基于 VMAF 工具,這些工具來自 VMAF 庫的 GitHub 資源庫。
在本例中,延遲是指計算三個特征提取器所需的時間,以獲得單幀 VMAF 評分 .NVTX 允許您在 CPU 和 GPU 上測量函數或操作的運行時間。在測量中,CPU 和 GPU 特征提取器在 4K 和 1080p 測試序列中獨立運行。
用于這項測量的硬件是一個 56C/112T 雙英特爾至強 8480 計算節點和一個 NVIDIA L4 GPU。測量結果顯示,在 NVIDIA L4 上處理一張圖像的特征提取器延遲比使用英特爾至強 8480 CPU 時快 30 到 90 倍 (圖 3)。
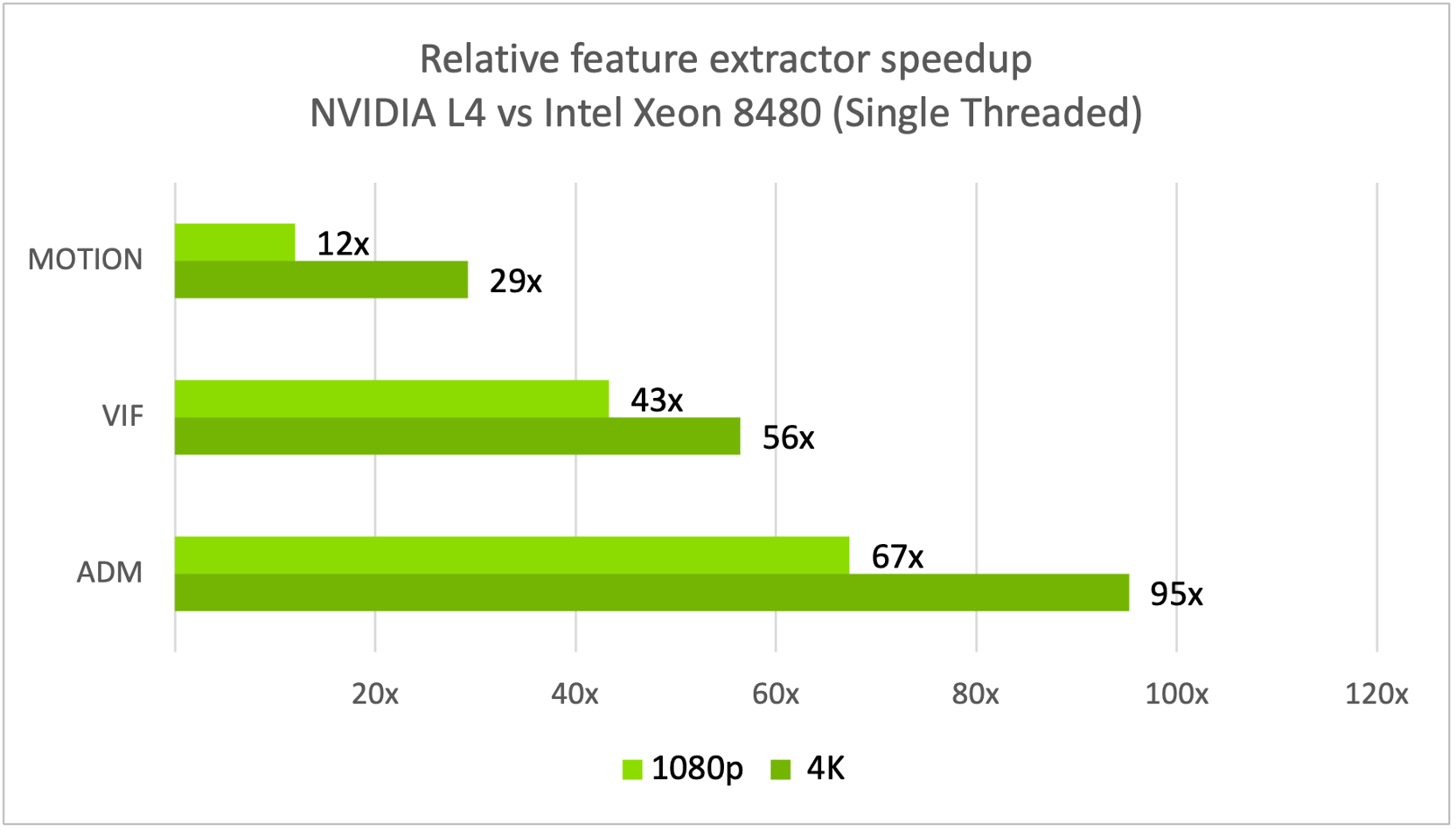
在 1080p 等較低分辨率下,VMAF-CUDA 不會飽和單個 NVIDIA L4,因此與在 4K 等較高分辨率下的 VMAF-CPU 相比,您會看到更好的延遲改進。
圖 4 顯示了平均 VMAF 評分訪問延遲。
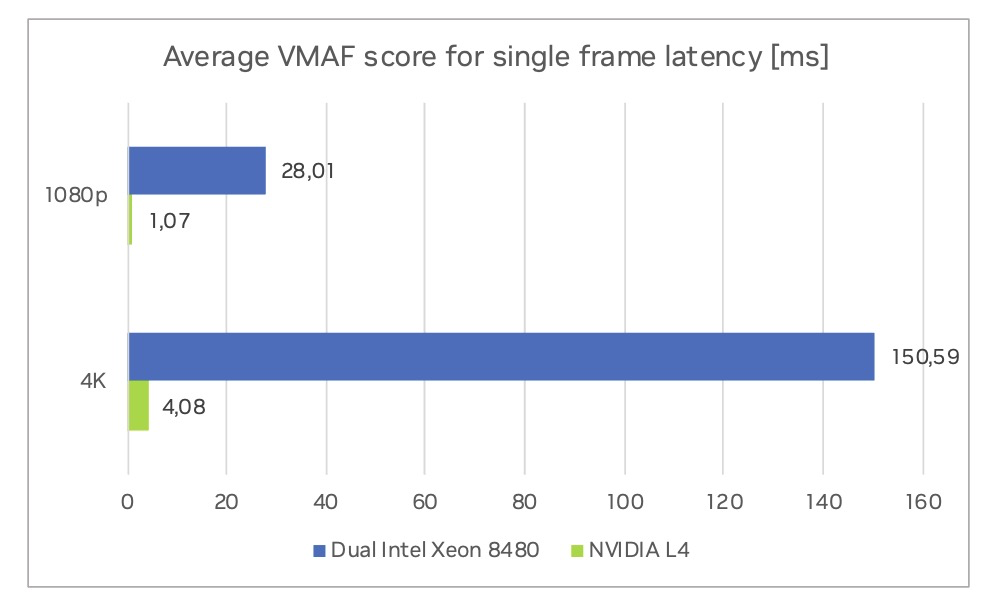
NVIDIA L4 GPU 延遲時間是指在 GPU 上順序運行的每個特征提取器的平均運行時間之和。雙英特爾至強計算節點的平均延遲時間由運行在多個核心上并行的最慢的特征提取器決定。在 4K 分辨率下訪問單幀 VMAF 評分時,VMAF-CUDA 的速度比雙英特爾至強 8480 快 36.9 倍;在 1080p 分辨率下,速度比雙英特爾至強 8480 快 26.1 倍。
FFmpeg 性能提升
我們通過在 FFmpeg 中計算 VMAF 來測量吞吐量 (FPS)。與 VMAF 工具不同,FFmpeg 能夠直接將編碼視頻讀入 GPU 或 CPU RAM,而不是從磁盤讀取原始字節流。我們使用libvmaf_cudaGPU 實現的視頻濾鏡,libvmafCPU 實現的視頻濾鏡。我們使用 YUV420 每通道 8 位、4K 和 1080p HEVC 編碼測試序列作為輸入。
以下 FFmpeg 命令使用 GPU 實現計算 VMAF 評分:
ffmpeg -hwaccel cuda -hwaccel_output_format cuda -i distorted.mp4 -hwaccel cuda -hwaccel_output_format cuda -i reference.mp4 -filter_complex "[0:v]scale_npp=format=yuv420p[dis],[1:v]scale_npp=format=yuv420p[ref],[dis][ref]libvmaf_cuda" -f null – |
-hwaccel cuda -hwaccel_output_format cuda:為硬件加速的視頻幀啟用 CUDA。使用 NVDEC 在 GPU 上解碼視頻,并將其輸出到 GPU VRAM。這對于實現高吞吐量至關重要,因為它可以避免由于從 CPU 到 GPU 的內存傳輸而導致吞吐量降低。-filter_complex:啟動一個描述視頻處理管線的復雜過濾器。每個步驟都是用逗號分隔的視頻過濾器,并且始于用方括號括起的輸入。[0:v]scale_npp=format=yuv420p[dis]:獲取第一個輸入視頻 (distorted.mp4),在這里0:v并將其格式化為yuv420使用scale_npp,因此,它與 VMAF 兼容 .VMAF 支持 8 位、10 位或 12 位的 YUV420、YUV422 和 YUV444,但 NVDEC 將 YUV420 輸出為 NV12,這需要這種重新格式化。最后,它將結果存儲在一個變量中:dis同樣,參考輸入視頻 (reference.mp4),在這里1:v并將其存儲在ref。[dis][ref]libvmaf_cuda:獲取輸出dis和ref從上一個過濾器和輸入中獲取libvmaf_cuda視頻濾鏡,可計算兩個輸入視頻的 VMAF 評分。與其他指標不同,這里的輸入順序非常重要,因為指標不是對稱的。
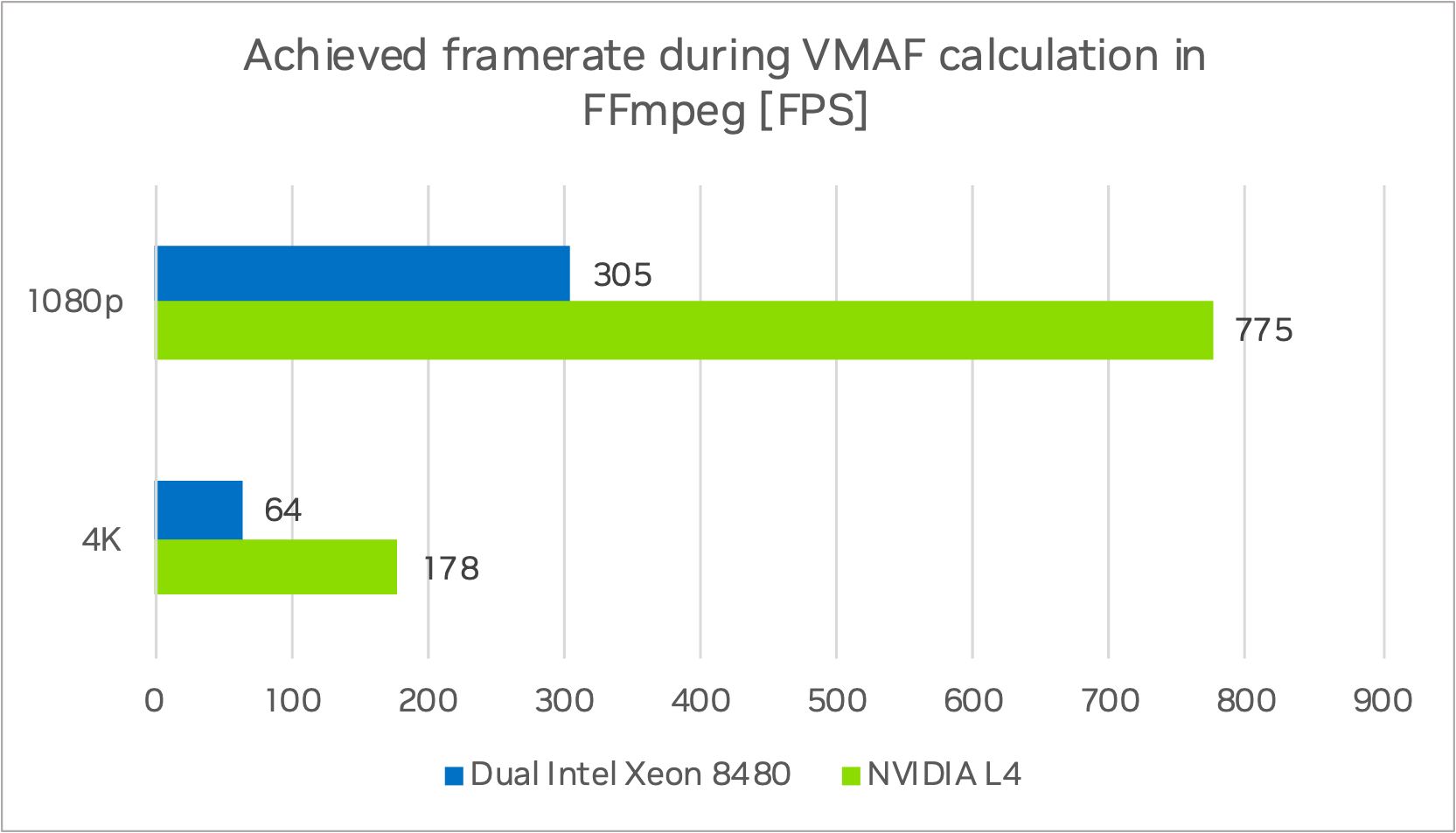
NVIDIA L4 在 4K 分辨率下達到 178 FPS,在 1080p 分辨率下達到 775 FPS,而雙路英特爾至強 8480 計算節點在 4K 分辨率下達到 64 FPS,在 1080p 分辨率下達到 176 FPS (圖 5)。在處理單個視頻流時,4K 序列的速度提升了 2.8 倍,1080p 序列的速度提升了 2.5 倍。
美元成本分析
對于成本分析,我們基于通常在數據中心中使用的標準 2U 服務器進行計算。
NVIDIA L4 采用單插槽半高外形規格,可以在配備廉價英特爾至強或 AMD Rome 處理器的 2U 服務器中安裝 8 個 NVIDIA L4 單元。在 VMAF 計算期間,單個 FFmpeg 進程/實例無法充分利用雙路英特爾至強 8480 計算節點,而 NVIDIA L4 處于 100%占用率。
圖 6 顯示了使用多個 FFmpeg 進程對 2U 雙英特爾至強系統的總計算性能進行測試,以充分利用 CPU 的結果,以及 2U 八個 L4 服務器的 FPS 數字。
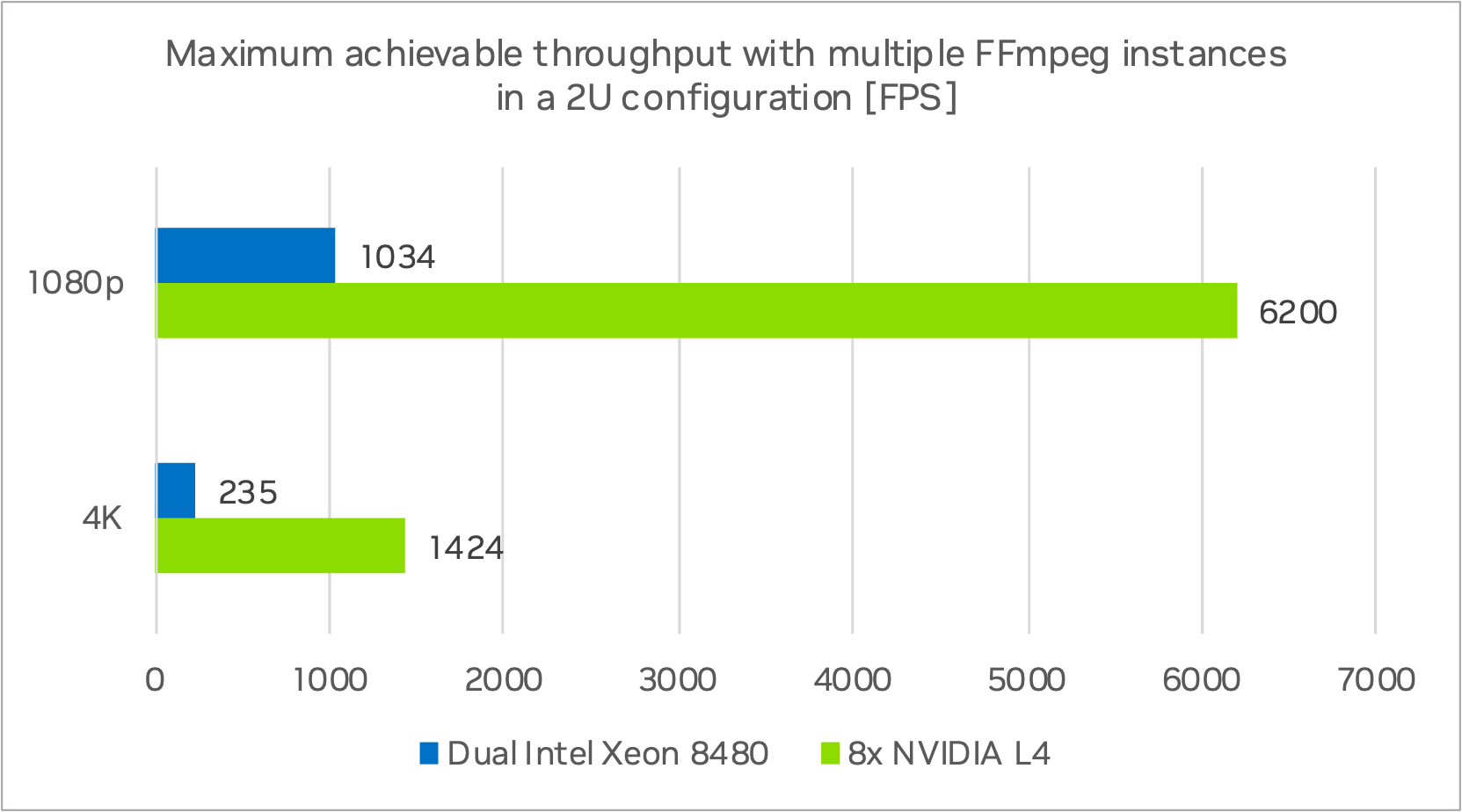
Dual Intel Xeon 8480 和八個 NVIDIA L4 上的多個 FFmpeg 實例
Dual Intel Platinum 8480 節點的總吞吐量為 1034 FPS 在 1080p 分辨率下和 235 FPS 在 4K 分辨率下,使用多個 FFmpeg 實例/進程.8 臺 NVIDIA L4 GPU 的 2U 服務器系統的總吞吐量為 6200 FPS 在 1080p 分辨率下和 1424 FPS 在 4K 分辨率下。在相同功耗水平下,1080p 和 4K 分辨率的速度提升了約 6 倍。
下表對 2U 服務器的每 VMAF 幀的成本進行了細分。
| ? | NVIDIA L4 | Dual Intel Platinum 84801 |
| 1000 小時的 4K 視頻,幀速率為 30 FPS | 1 億幀 | 1 億幀 |
| 服務器類型 | 2U | 2U |
| 處理器數量 | 8 | 2 |
| 總吞吐量 | 1424 FPS | 235 FPS |
| 計算 VMAF 評分所需的時間 | 21.0 小時 | 127.6 小時 |
| 3 年總體擁有成本 | 3 萬美元 | 20000 美元 |
| 計算 1000 小時 4K 視頻 30 FPS 時的 VMAF 成本 | 24 美元 | 97 美元 |
1僅使用 CPU 的服務器 (2U 機箱,雙 Intel Platinum 8480,512GB RAM,1TB SSD,網卡) | L4 服務器 (2U 機箱、2S 32C CPU、128GB RAM、1TB SSD、CX6 網卡)
與 Dual Intel Platinum 8480 相比, NVIDIA 系統可節省高達 75%的成本。
合作伙伴成功案例
我們希望展示我們的合作伙伴取得的一些成就和經驗,重點介紹他們在軟件和視頻處理流程中使用 VMAF-CUDA 和 NVIDIA GPU 取得的成就 .Snap (作為測試版用戶) 提供的寶貴反饋對于 VMAF-CUDA 的發展至關重要。
捕捉
Snap 可以跟蹤視頻質量指標的時間變化,其中包括 CUDA 加速的 VMAF,以確保轉碼質量始終如一。
他們目前正在使用 VMAF-CUDA 來確定特定編碼是否達到質量閾值,并根據需要重新編碼。引入 VMAF-CUDA 優化了處理流程。以前,由于 VMAF 計算的高計算成本,Snap 不敢使用優化的轉碼設置。但是,借助 VMAF-CUDA,他們可以在每次轉碼后評估 Snapchat Memories,并使用優化的設置進行重新編碼,而不會產生額外的開銷。
Snap 通常可以將處理時間加快 2.5 倍,這是因為它能夠在 GPU 上獨立運行 VMAF 計算,從而使 VMAF 比基于 CPU 的方法更具成本效益 .Snap 使用 Amazon EC2 g4dn.2xlarge 實例和 T4 GPU 進行 VMAF 計算。
CUDA 加速的 VMAF 使 Snap 能夠實現之前無法實現的項目 .Snap 希望擴大 VMAF-CUDA 的使用范圍,并完全從基于 CPU 的 VMAF 計算過渡到基于 GPU 的 VMAF 計算。
V-Nova
V-Nova 正在探索 CUDA 加速的 VMAF 計算在幾個用例中的優勢。這些用例包括在 LCEVC (MPEG-5 第 2 部分) 編碼過程中的離線指標計算和實時決策中的實用性。集成 VMAF-CUDA 可顯著加速離線指標計算。
2023 年,V-Nova 的視頻質量工具 (包括 Video Quality Framework 和 Parallel Performance Runner (PAPER)) 每周處理大約 2 萬個編碼作業 .VMAF-CUDA 已證明能夠至少將指標計算速度提升 2 倍。
從長遠來看,由 VMAF-CUDA 提供支持的實時內環 VMAF 計算可為算法增強提供額外優勢,例如優化 LCEVC 模式決策和速率控制這一指標。
更多資源
關于 VMAF 及其相關主題(如 VMAF 黑客)的更多信息,請參閱以下資源。請務必參加我們的 NVIDIA GTC 2024 會議,VMAF CUDA:以轉碼的速度運行。
- 實用的感知視頻質量指標
- 為視頻社區提供更好的質量指標
- Hacking VMAF and VMAF-NEG: Exploiting Vulnerabilities in Different Preprocessing Methods
?





