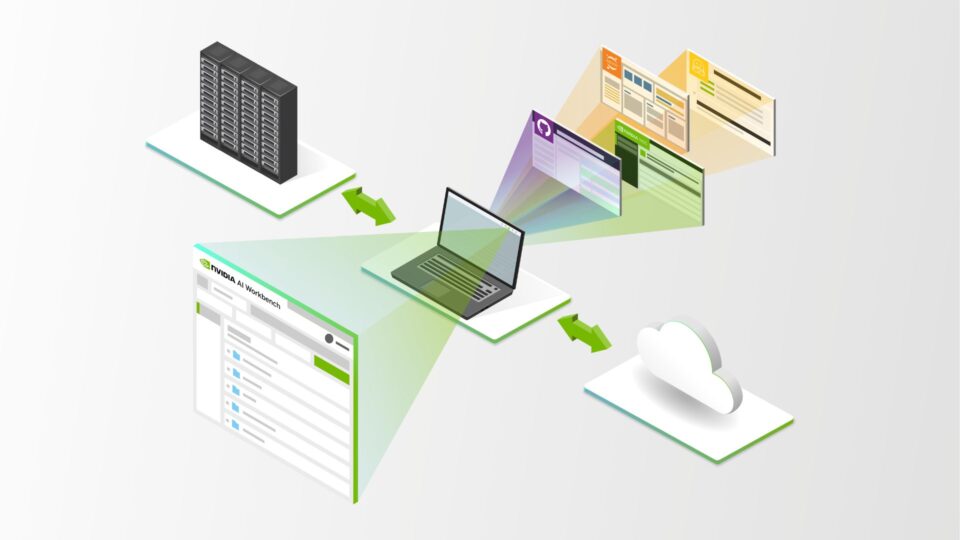
在構建 大型語言模型 (LLM) 智能體應用時,您需要四個關鍵組件:智能體核心、內存模塊、智能體工具和規劃模塊。無論您是設計問答智能體、多模態智能體還是智能體群,您都可以考慮許多實現框架 — 從開源到生產就緒。有關更多信息,請參閱 LLM 代理簡介。
對于首次嘗試開發 LLM 代理的用戶,本文提供了以下內容:
- 開發者生態系統概述,包括可用框架和推薦的讀數,以加快 LLM 代理的速度
- 用于構建首個由 LLM 提供支持的代理的初學者教程
面向代理的開發者生態系統概述
你們大多數人可能已經閱讀過有關 LangChain 或 LLaMa-Index 代理的文章。以下是目前可用的一些實現框架:
那么,我推薦哪一種?答案是,“這取決于”。
單代理框架
社區構建了多個框架來推進 LLM 應用開發生態系統,為您提供了開發代理的簡單路徑。熱門框架的一些示例包括 LangChain、LlamaIndex 和 Haystack.這些框架提供通用代理類、連接器和內存模組功能、第三方工具的訪問權限,以及數據檢索和提取機制。
選擇哪種框架在很大程度上取決于您的工作流的細節和要求。在必須構建具有有向無環圖 (DAG) (如邏輯流)或具有獨特屬性的復雜代理的情況下,這些框架為您自己的自定義實現提供了一個很好的提示參考點和通用架構。
多智能體框架
您可能會問:“多智能體框架有何不同?”簡短回答是“世界”類。要管理多個智能體,您必須構建世界,或者說構建環境中它們彼此交互的環境、用戶和環境中的工具。
這里的挑戰在于,對于每個應用程序,所面對的世界都將是不同的。您需要一個定制的工具包來構建模擬環境,以及一個能夠管理世界狀態并具備代理通用類的工具包。您還需要一個用于管理代理之間流量的通信協議。 OSS 框架的選擇取決于您所構建的應用程序類型以及所需的自定義程度。
為建筑代理推薦的閱讀清單
您可以使用大量資源和材料來激發您對智能體的可能性的思考,但以下資源是涵蓋智能體整體精神的良好起點:
- AutoGPT: 這個 GitHub 項目是首批真正的智能體之一,它旨在展示智能體能夠提供的各種功能。查看項目中所使用的通用架構和提示技術將非常有益。
- Voyager:這個項目由 NVIDIA 研究 所提出,探索了自我提升智能體的概念,即智能體能夠在沒有任何外部干預的情況下學習使用新工具或構建工具。
- 智能體概念框架如OlaGPT提供了一個很好的起點,用于激發關于如何超越簡單智能體的思考。這是因為簡單智能體通常包含四個基本模塊。
- 本文首先提出了使用結合大型語言模型、外部知識來源和離散推理的模塊化神經符號架構(MRKL 系統)來執行復雜任務的核心機制。詳情請參閱MRKL 系統:結合大型語言模型、外部知識來源和離散推理的模塊化神經符號架構。
- 生成智能體:人類行為的交互式 Simulacra: 這是首批構建真正智能體群體的項目之一,它提供了一個多個智能體以去中心化的方式進行相互交互的解決方案。
如果您正在尋找更多閱讀材料,由 LLM 提供支持的優秀智能體 列出了許多有用信息。如果您有特定的查詢,請在此帖子下發表評論。
教程:構建問答代理
在本教程中,您構建了一個問答 (QA) 代理,可幫助您處理數據。
為了證明即使是一個簡單的坐席也能應對復雜的挑戰,您可以構建一個能夠從財報電話會議中提取信息的坐席。您可以參考通話記錄。圖 1 展示了財報電話會議的一般結構,這將幫助您理解本教程中使用的文件。

在本文結束時,您構建的智能體將回答如下復雜的分層問題:
- 從 2024 年第一季度到 2024 年第二季度,收入增長了多少?
- 24 財年第 2 季度的關鍵要點是什么?
正如本系列的第 1 部分所介紹的,智能體包含四個組件:
- 工具
- 規劃模塊
- 顯存
- 智能體核心
工具
要構建 LLM 代理,您需要以下工具:
- RAG 管道:沒有 RAG,您將無法解決涉及數據對話的問題。因此,您需要的工具之一就是 RAG 工作流。為了本次討論,我們假設 RAG 工作流對基本問題或原子問題的準確性為 100%。
- 數學工具:您還需要一個數學工具來執行各種分析。為了簡化本文,我使用了 LLM 來回答數學問題,但對于生產應用程序,我推薦使用類似于 WolframAlpha 的工具。
規劃模塊
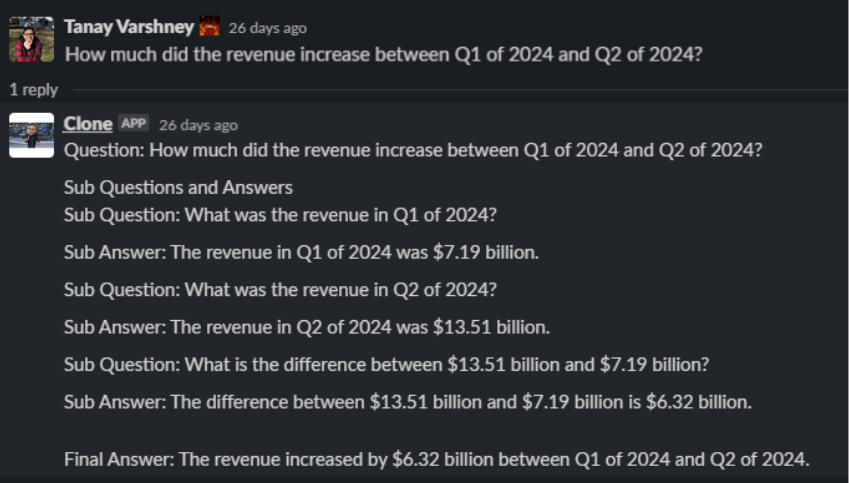
通過此 LLM 代理,您將能夠回答以下問題:“在 2024 年第一季度到 2024 年第二季度期間,收入增長了多少?”基本上,我們將以下三個問題合二為一:
- 第一季度的收入是多少?
- 第二季度的收入是多少?
- 這兩者之間有何區別?
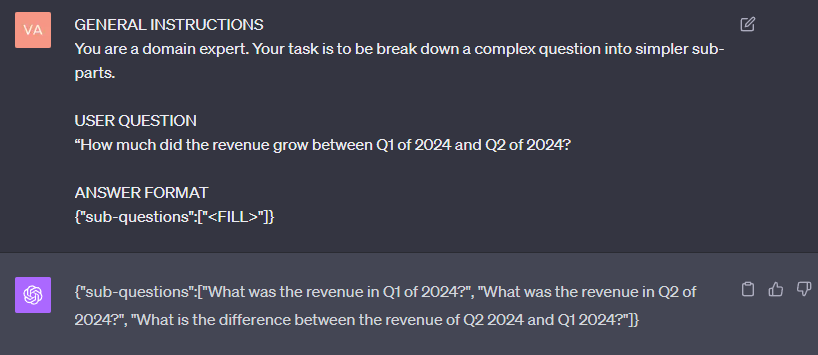
答案是,您必須構建一個問題分解模塊:
decomp_template = """GENERAL INSTRUCTIONSYou are a domain expert. Your task is to break down a complex question into simpler sub-parts.USER QUESTION{{user_question}}ANSWER FORMAT{"sub-questions":["<FILL>"]}"" |
如您所見,分解模塊促使 LLM 將問題分解為不太復雜的部分。圖 3 展示了答案。
顯存
接下來,您必須構建一個內存模塊,以跟蹤被問到的所有問題,或者僅保留所有子問題和上述問題答案的列表。
class Ledger: def __init__(self): self.question_trace = [] self.answer_trace = [] |
您可以使用由兩個列表組成的簡單分類帳來執行此操作:一個用于跟蹤所有問題,另一個用于跟蹤所有答案。這有助于代理記住其已回答但尚未回答的問題。
評估心理模型
在構建智能體核心之前,請評估您目前擁有的核心:
- 用于搜索和執行數學計算的工具
- 一個計劃者來分解這個問題
- 用于跟蹤提問的內存模塊。
此時,您可以將它們連接在一起,看看它是否可以用作心理模型(圖 4)。
template = """GENERAL INSTRUCTIONSYour task is to answer questions. If you cannot answer the question, request a helper or use a tool. Fill with Nil where no tool or helper is required.AVAILABLE TOOLS- Search Tool- Math ToolAVAILABLE HELPERS- Decomposition: Breaks Complex Questions down into simpler subpartsCONTEXTUAL INFORMATION<No previous questions asked>QUESTIONHow much did the revenue grow between Q1 of 2024 and Q2 of 2024?ANSWER FORMAT{"Tool_Request": "<Fill>", "Helper_Request "<Fill>"}""" |
圖 4 顯示了收到的 LLM 答案。
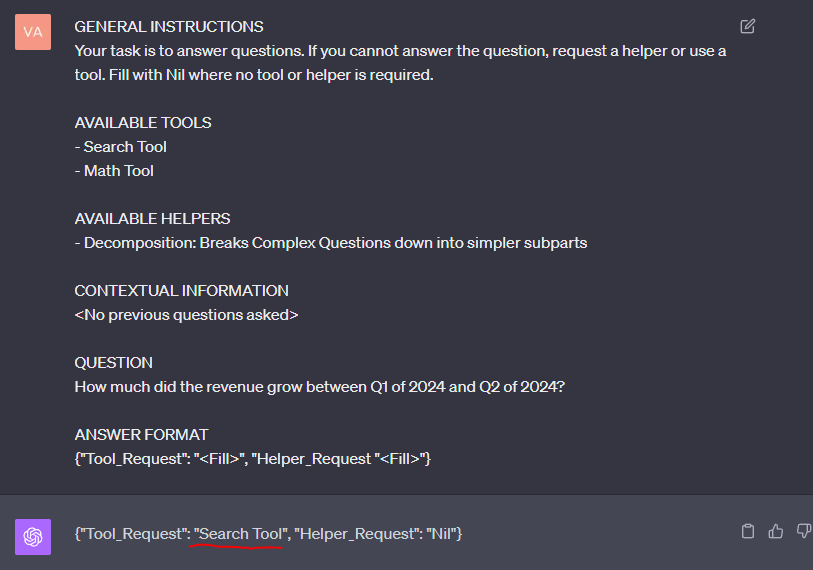
您可以看到,LLM 請求使用搜索工具,這是一個合乎邏輯的步驟,因為答案很可能在語料庫中。也就是說,您知道所有轉錄都不包含答案。在下一步(圖 5)中,您提供來自 RAG 管道的輸入,以確定答案不可用,因此代理隨后決定將問題分解為更簡單的子部分。
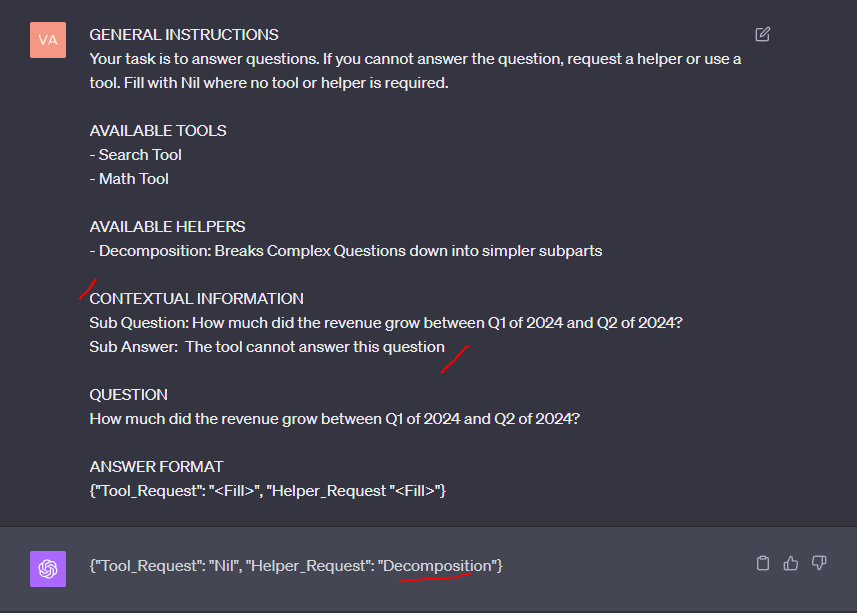
通過本練習,您確認邏輯的核心機制是可靠的。LLM 會根據需要選擇工具和輔助工具。
現在,只需將其整齊地包裝在 Python 函數中,該函數看起來類似于以下代碼示例:
def agent_core(question): answer_dict = prompt_core_llm(question, memory) update_memory() if answer_dict[tools]: execute_tool() update_memory() if answer_dict[planner]: questions = execute_planner() update_memory() if no_new_questions and no tool request: return generate_final_answer(memory) |
智能體核心
您剛剛看到了智能體核心的示例,還剩下什么?智能體核心不僅僅是將所有組件拼接在一起。您必須定義智能體執行流的機制。本質上有三個主要選擇:
- 線性求解器
- 單線程遞歸求解器
- 多線程遞歸求解器
線性求解器
這就是我之前討論過的執行類型。有一個線性解決方案鏈,代理可以在其中使用工具并進行一級規劃。雖然這是一個簡單的設置,但真正的復雜和微妙的問題通常需要分層思考。
單線程遞歸求解器
您還可以構建一個遞歸求解器,該求解器構建一個問題和答案樹,直到原始問題得到解答。此樹在深度優先遍歷中求解。以下代碼示例展示了邏輯:
def Agent_Core(Question, Context): Action = LLM(Context + Question) if Action == "Decomposition": Sub Questions = LLM(Question) Agent_Core(Sub Question, Context) if Action == "Search Tool": Answer = RAG_Pipeline(Question) Context = Context + Answer Agent_Core(Question, Context) if Action == "Gen Final Answer”: return LLM(Context) if Action == "<Another Tool>": <Execute Another Tool> |
多線程遞歸求解器
您可以為樹上的每個節點分離并行執行線程,而不是以迭代方式求解樹。此方法增加了執行復雜性,但由于可以并行處理 LLM 調用,因此會產生巨大的延遲優勢。
接下來該怎么做?
恭喜!您現在已經掌握了構建相當復雜的智能體的知識!下一步是根據您的問題調整前面討論的原則。
要為 LLM 代理開發更多工具,請參閱 NVIDIA 深度學習培訓中心 (DLI)。如需為您的用例構建、自定義和部署 LLM,請參閱 NVIDIA NeMo 框架。
?