
NVIDIA CUDA-X 數學庫助力開發者為 AI、科學計算、數據處理等領域構建加速應用。
CUDA-X 庫的兩個最重要的應用是訓練和推理 LLM,無論是用于日常消費者應用,還是用于藥物研發等高度專業化的科學領域。要在 NVIDIA Blackwell 架構上高效訓練 LLM 和執行 具有突破性性能的推理任務 ,多個 CUDA-X 庫不可或缺。
cuBLAS 是一個 CUDA-X 庫,可提供高度優化的內核,用于執行最基本的線性代數任務,例如矩陣乘法 (matmuls) ,這些任務對于 LLM 訓練和推理至關重要。
NVIDIA CUDA 工具包 12.9 中新推出的 cuBLAS 支持進一步優化 cuBLAS matmul 性能的新功能。它還通過調整浮點精度和利用模擬的基礎模組,實現了更大的靈活性,以平衡準確性和能效等需求。
本文將介紹 cuBLAS 12.9 的具體方法:
- 為 NVIDIA Hopper GPU 推出新的 FP8 擴展方案,提供靈活性和性能。
- 利用適用于 FP4 和 FP8 matmuls 的 NVIDIA Blackwell 第五代 Tensor Cores 提供的塊擴展功能。
- 與 Blackwell 和 Hopper GPU 上的 FP8 matmuls 相比,可在各種精度(包括 FP4)下實現高達 2.3 倍和 4.6 倍的加速。
- Blackwell BF16 Tensor Core 支持 FP32 仿真,其運行 matmuls 的速度比 Blackwell 和 Hopper 原生 FP32 matmuls 快 3 到 4 倍,同時提高了能效。
基于 NVIDIA Hopper 的 Channel-and-block-scaled FP8 matmuls
在使用窄數據類型 (例如 FP8) 執行 matmuls 時,擴展是保持訓練和推理準確性的基礎。之前的 cuBLAS 版本在 NVIDIA Hopper 和 NVIDIA Ada GPU 上支持 FP8 張量范圍擴展 (單擴展因子) 。現在,cuBLAS 12.9 為 Hopper GPU 上的幾種新擴展方案提供了更大的靈活性。
第一種是通道范圍或 外向量縮放 ,支持將單個縮放系數應用于 A[MxK] 的單個矩陣行或 B[KxN] 的列。這可以通過塊縮放進一步擴展,塊縮放會對 K 維中的每個 128 元素 1D 塊或矩陣 A 和 B 的 128 × 128 2D 塊應用縮放系數。
使用 1D 塊可提高準確性,而 2D 塊可提供更好的性能。cuBLAS 支持 A 和 B 的不同縮放模式 (1D x 1D、1D x 2D 和 2D x 1D)。
圖 1 顯示了各種大小的大型 matmuls 的基準測試。使用各種 FP8 擴展方案可以提供高達 1.75 倍的加速,除一種情況外,在所有其他情況下,FP8 擴展方案提供的加速至少是 BF16 基準的 1.25 倍。

有關使用 示例 ,請參閱 cuBLASLt 庫 API 示例。
基于 NVIDIA Blackwell 的塊級 FP4 和 FP8 matmuls
NVIDIA Blackwell Tensor Core 原生支持細粒度 1D 塊級 FP4 和 FP8 浮點類型 ,可在降低的精度和吞吐量之間實現更高水平的平衡。與使用單一全局縮放系數相比,此方法可更精確地表示每個塊內的值,從而提高整體準確性。
cuBLAS 12.9 可以通過以下 cuBLASLt API 使用這些新精度,其中`E` 是定義數字動態范圍的指數,`M` 用于表示尾數精度:
- `CUDA_R_4F_E2M1`:具有`CUDA_ R_UE4M3` 比例和 16 個單元塊的 matmuls。縮放類型是`CUDA_R_E4M3` 的變體,符號被忽略。查看 API 示例 。
- `CUDA_R_8F` 變體:具有 `CUDA_R_UE8` 比例和 32 個單元塊的 matmuls。此處,縮放類型為 8 位無符號指數型浮點數據類型,可視為不帶符號和尾數位的 FP32。請參閱 API 示例 。

此外,得益于小塊大小和新的縮放模式,cuBLAS matmul 內核可以在輸出為 FP4 或 FP8 時計算 D 張量 (圖 2 中的 scaleD) 的縮放系數。這消除了在執行轉換之前估計縮放系數或額外傳遞數據的需求,而這對于張量范圍的縮放是必不可少的。
請注意,如果 D 是 FP4 張量,則在對所有值進行量化之前,會對其應用二級縮放系數。 有關更多詳情,請參閱 cuBLAS 文檔中的量化說明 。
NVIDIA Blackwell GPU 上的 cuBLAS 12.9 matmul 性能
借助 cuBLAS 12.9 中提供的新數據類型、運行時啟發式算法和內核優化,用戶可以充分利用 Blackwell GPU 的出色性能。
圖 3 展示了 cuBLAS 中適用于各種精度的最新 matmul 性能,并將 NVIDIA B200 和 GB200 與 Hopper H200 進行了比較。合成基準測試由受計算限制的大型矩陣大小 (左) 和 1000 個隨機矩陣大小 (右) 組成,這些矩陣的范圍涵蓋受延遲限制、受內存限制和計算限制的大小。
隨機矩陣數據集由更小的矩陣組成,這些矩陣使 matmul 性能由帶寬比主導,導致速度提升低于受計算限制的情況。在計算受限的情況下,塊級 FP4 在 GB200 上的速度比 H200 FP8 基準快 4.6 倍,可實現高達 6787 TFLOPS/s 的絕對性能。
![This chart shows the geomean speedups of matmuls (A[MxK]B[KxN]) in various precisions on Blackwell compared to Hopper, confirming that cuBLAS achieves close to the throughput ratios on large, compute-bound sizes. The chart also shows that for a dataset of one thousand random sizes (small to large) and shapes, the speedup is dominated by the bandwidth ratios between Blackwell and Hopper GPUs.](https://developer-blogs.nvidia.com/wp-content/uploads/2025/04/Geomean-speedup.png)
“Blackwell 架構在由矩陣形狀和大小組成的現實數據集上也表現出色,這些數據集主要用于重要的 LLM 訓練和推理工作負載 (圖 4) ,與使用 BF16 和 FP8 數據類型 (B200 和 GB200) 獲取的 H200 基準相比,Blackwell 架構至少實現了 1.7 倍的加速和 2.2 倍的加速。圖 4 中的這些幾何平均加速僅適用于 matmuls 及其在數據集中每個模型中的相關重復計數。最終的端到端加速也取決于工作負載中非 matmul 部分的性能。”
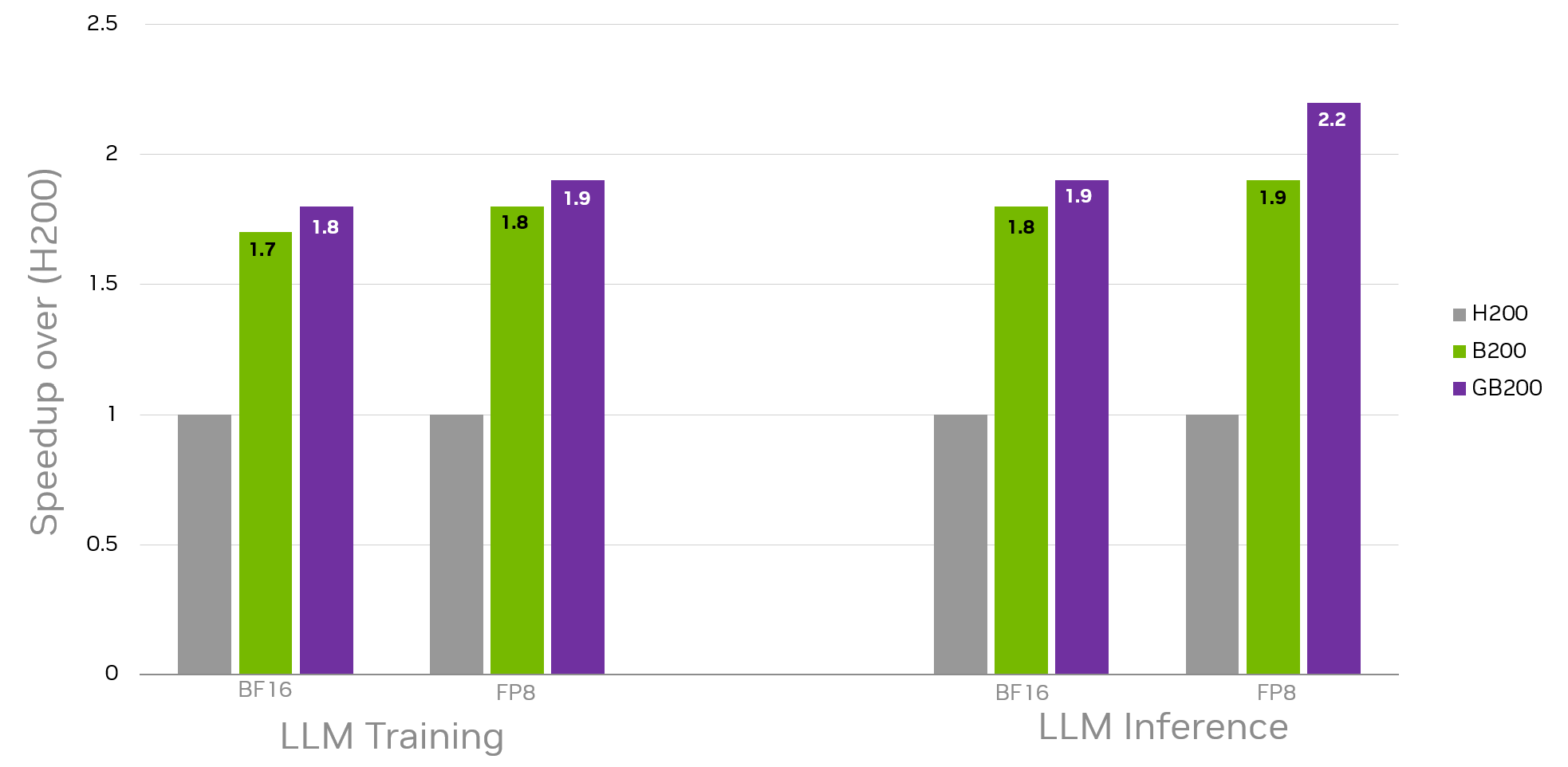
通過 cuBLASLt 啟發式 API 和 自動調整 [6,7]提供的機會性優化,Blackwell 架構實現的性能可以得到進一步提升。
在 Blackwell 上使用 BF16 Tensor Core 加速 FP32 matmuls
除了 cuBLAS 已經在 Blackwell 上提供的令人印象深刻的性能之外,它還引入了一項功能, 使用戶能夠選擇使用模擬來實現可能更快的 FP32 矩陣乘法 和更高的能效。
圖 5 展示了 B200 GPU 與原生 FP32 性能和 H200 GPU (適用于各種方形矩陣大小) 相比的 FP32 仿真性能。在最大的情況下 (M=N=K=32,768),在 B200 或 H200 上,模擬可實現比原生 FP32 高 3 到 4 倍的 TFLOPS。
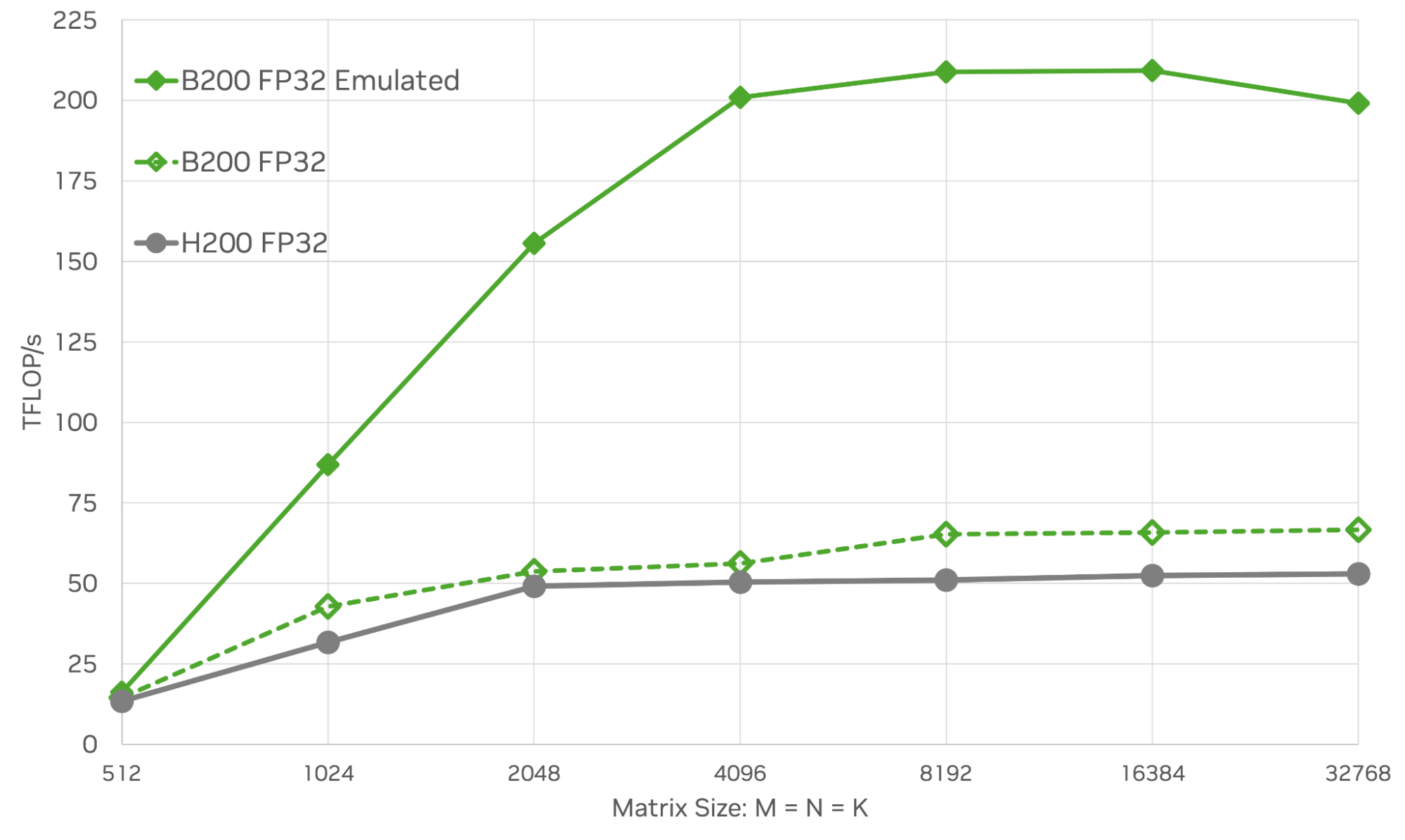
用于科學計算應用的 matmuls 仿真現已得到充分理解,并且提供了幾種利用仿真來提高性能和能效的算法和實現。
例如,NVIDIA GTC 2025 演講“ How Math Libraries Can Help Accelerate Your Applications on Blackwell GPUs ”展示了天氣預報應用程序的一個關鍵組件,在該組件中,模擬可提供 1.4x 性能和 1.3x 能效提升。
cuBLAS 庫中 FP32 仿真的當前實現利用了 BF16 Tensor Core。有關使用示例,請參閱 cuBLASLt 庫 API 示例 。 目前正在開發 FP64 中的 matmuls 仿真。
開始使用 cuBLAS 12.9
下載 cuBLAS 12.9 ,開始使用本博客中討論的技術加速您的應用程序,并參考 cuBLAS 文檔 ,獲取與 Hopper 的新擴展方案 、 Blackwell 上的新塊擴展數據類型 以及 Blackwell FP32 仿真 相關的更多信息。
如需了解詳情:
- 觀看如何 Math Libraries 可以幫助加速您的應用程序在 Blackwell GPUs 上 。
- 觀看通過 Tensor Core 加速的混合精度計算和 Floating-Point 仿真實現的節能超級計算。
- 閱讀 Introducing Grouped GEMM APIs in cuBLAS 和更多性能更新。
- 閱讀從 Tensor Core 恢復單精度精度,同時超越 FP32 理論峰值性能,并 利用 bfloat16 人工智能數據類型進行更高精度的計算 ,以獲取有關模擬 FP32 matmuls 的更多背景信息。
?






