如果您從事數據分析工作,您就會知道數據攝取通常是數據預處理工作流的瓶頸。由于數據量大且常用格式復雜,從存儲中獲取數據并對其進行解碼通常是工作流中最耗時的步驟之一。對從事大型數據集研究的數據科學家來說,優化數據攝取可以大大減少這一瓶頸。
RAPIDS cuDF 通過為數據科學中流行的格式實現 CUDA 加速讀取器,大大加快了數據解碼速度。
此外, Magnum IO GPUDirect Storage ( GDS )使 cuDF 能夠通過將數據直接從存儲器加載到設備( GPU )內存來加速輸入/輸出。通過在 GPU 和兼容存儲設備(例如,非易失性存儲器 Express ( NVMe )驅動器)之間通過 PCIe 總線提供直接數據路徑, GDS 可以實現高達 3 – 4 倍的 cuDF 讀取吞吐量,在各種數據配置文件中的平均吞吐量提高 30 – 50% 。
在本文中,我們將概述 GPUDirect 存儲以及它如何集成到 cuDF 中。我們介紹了一套用于評估輸入/輸出性能的基準測試。然后,我們將介紹 cuDF 實現的優化 GDS 讀取的技術。我們以基準結果作為結論,并確定使用 GDS 對 cuDF 最有利的案例。
什么是 GPUDirect 存儲?
GPUDirect Storage 是一種新技術,可實現本地或遠程存儲(作為塊設備或通過文件系統接口)與 GPU 內存之間的直接數據傳輸。
換句話說,直接內存訪問( DMA )引擎現在可以快速將數據從存儲器直接路徑移動到 GPU 內存,而不會增加延遲,也不會通過反彈緩沖區對 CPU 進行額外復制。
圖 1 顯示了沒有 GDS 和有 GDS 的數據流模式。使用系統內存反彈緩沖區時,從系統內存到 GPU 的帶寬會限制吞吐量。在具有多個 GPU 和 NVMe 驅動器的系統上,此瓶頸更加明顯。
然而,由于具有將 GPU 與存儲設備直接連接的能力,中介 CPU 從數據路徑中移除,所有 CPU 資源都可以用于特征工程或其他預處理任務。
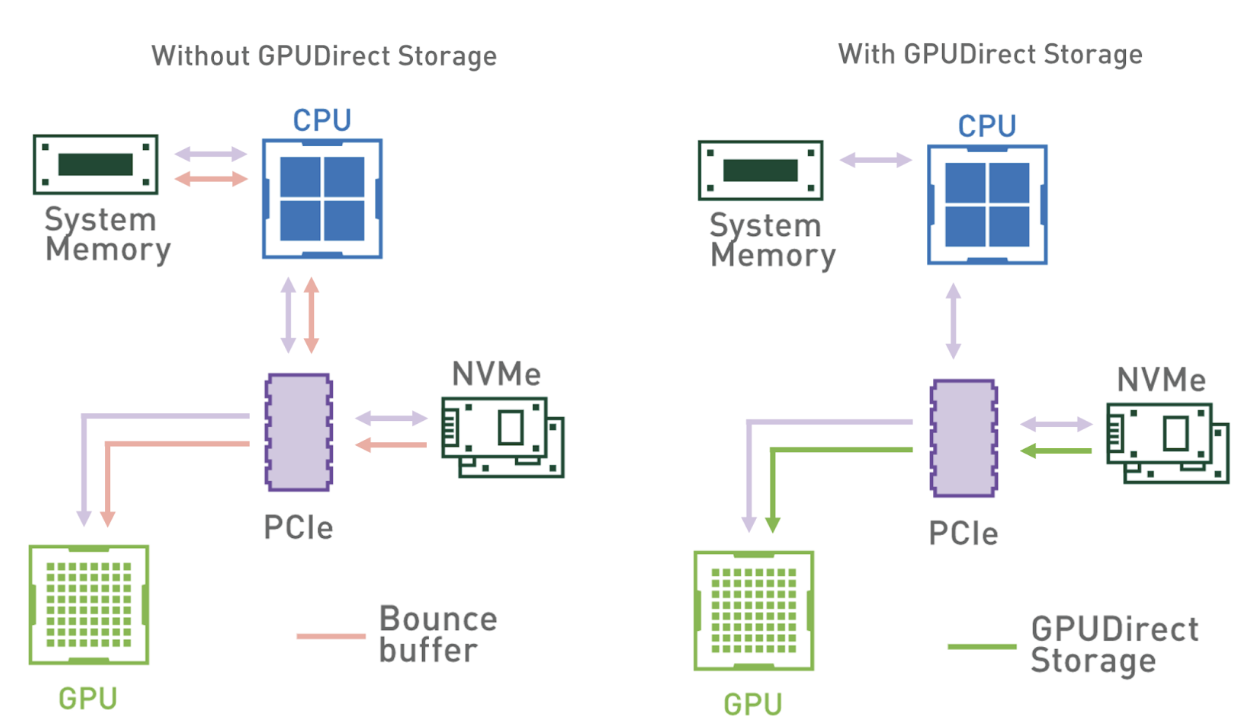
GDS cuFile library 使應用程序和框架能夠利用GDS技術來增加帶寬并降低延遲。自11.4版起,cuFile作為 CUDA 工具包的一部分提供。
RAPIDS cuDF 如何使用 GPUDirect 存儲?
為了提高端到端的讀取吞吐量, cuDF 在其數據攝取接口中使用cuFile API ,如read_parquet和read_orc。由于 cuDF 幾乎在 GPU 上執行所有解析,因此系統內存中不需要大部分數據,可以直接傳輸到 GPU 內存。
因此, CPU 只訪問輸入文件的元數據部分,元數據只占總文件大小的一小部分。這允許 cuDF 數據攝取 API 有效利用 GDS 技術。
自 cuDF 22.02 以來,我們默認啟用了 GDS 的使用。如果安裝了cuFile并請求從受支持的存儲位置讀取數據, cuDF 會通過cuFile API 自動執行直接讀取。如果 GDS 不適用于輸入文件,或者如果用戶禁用 GDS ,則數據將遵循跳出緩沖區路徑,并通過分頁系統內存緩沖區進行復制。
cuDF 中的基準數據攝取
為了應對數據科學數據集的多樣性,我們組裝了一個針對關鍵數據和文件屬性的基準套件。先前的輸入/輸出基準測試示例使用了數據樣本,如 紐約出租車出行記錄 、 Yelp 評論數據集 或 Zillow 住房數據 ,以表示一般用例。然而,我們發現,對數據和文件屬性的特定組合進行基準測試對于性能分析和故障排除至關重要。
涵蓋數據和文件屬性的組合
表 1 顯示了我們在二進制格式基準測試中改變的參數。我們生成了一系列受支持數據類型的偽隨機數據,并為每組相關類型收集了基準測試。我們還獨立地改變了數據的運行長度和基數,以對目標格式進行運行長度編碼和字典編碼。
最后,我們改變了生成的文件中的壓縮類型,用于前面屬性的所有值。我們目前支持兩種選擇:使用 Snappy 或保持數據未壓縮。
| Data Property | Description |
| File format | Parquet, ORC |
| Data type | Integer (signed and unsigned) Float (32-, 64-bit) String (90% ASCII, 10% Unicode) Timestamp (day, s, ms, us, ns) Decimal (32-, 64-, 128-bit) List (nesting depth 2, int32 elements) |
| Run-length | Average data value repetition (1x or 32x) |
| Cardinality | Unique data values (unlimited or 1000) |
| Compression | Lossless compression type (Snappy or none) |
對于所有獨立更改的屬性,我們有大量不同的情況:每個文件格式( ORC 和 Parquet )有 48 個情況。為了確保案例之間的公平比較,我們針對內存中固定的數據幀大小和列計數,默認大小為 512 MiB 。在這篇文章中,我們引入了一個額外的參數來控制目標內存數據幀大小從 64 到 4096 MiB 。
完整的 cuDF 基準測試套件可在 開源 cuDF 存儲庫 . 為了關注 I / O 的影響,本文只包括 cuDF 中的輸入基準,而不是讀卡器選項或行/列選擇基準。
優化 cuDF + GDS 文件讀取吞吐量
ORC 和 Parquet 等格式的數據存儲在獨立的塊中,我們在單獨的操作中讀取這些數據。我們發現,當在單個線程中執行這些操作時,讀取帶寬不會飽和,無論 GDS 的使用情況如何,都會導致次優性能。
并行發出多個 GDS 讀取調用可以使多個存儲重疊到 – GPU 拷貝,從而提高吞吐量并可能使讀取帶寬飽和。從版本 1.2.1.4 開始,cuFile調用是同步的,因此并行性需要下游用戶的多線程處理。
控制并行級別
由于我們沒有控制文件布局和數據塊的數量,因此為每個讀取操作創建單獨的線程可能會產生過多的線程,從而導致性能開銷。另一方面,如果我們只有幾個大型讀取調用,我們可能沒有足夠的線程來有效地飽和存儲硬件的讀取帶寬。
為了控制并行級別,我們使用了一個線程池,并將較大的讀取調用分割為可以并行執行的較小讀取。
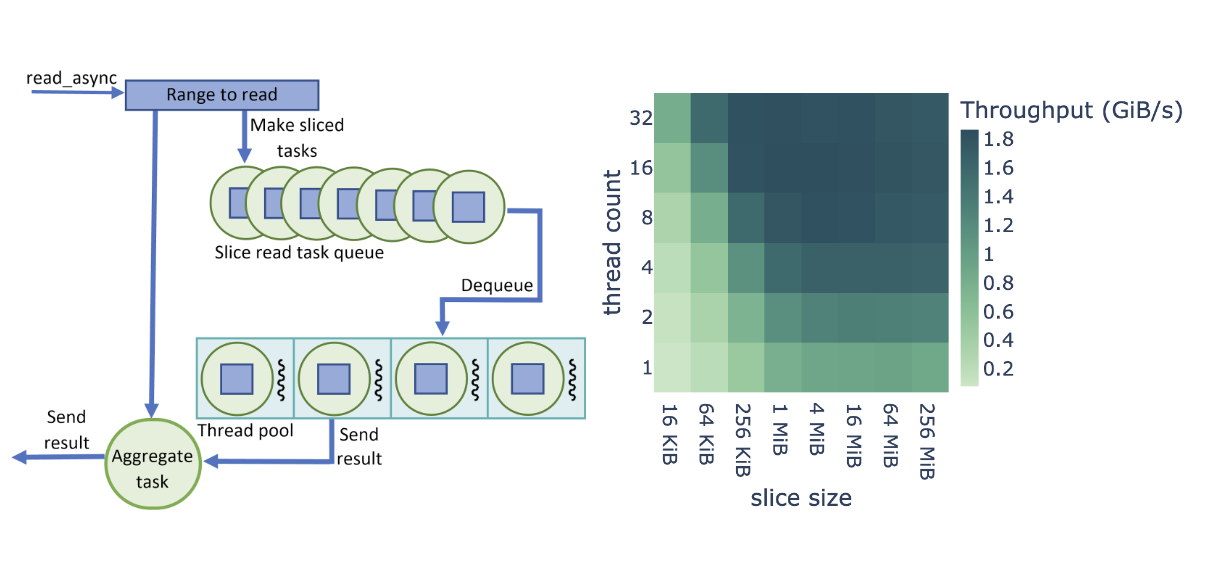
當我們開始使用 GDS 讀取文件時,我們基于 Brock 大學 Barak Shoshany 的 thread-pool 工作創建了一個數據攝取管道。如圖 2 所示,我們將 cuDF 讀取器中的每個文件讀取操作(read_async調用)拆分為固定大小的cuFile調用,但在大多數情況下,最后一個片段除外。
不是直接調用cuFile來讀取數據,而是為每個片創建一個任務并將其放置在隊列中。read_async調用返回一個任務,該任務等待所有切片任務完成。在需要繼續請求數據之后,調用方可以執行其他工作并等待聚合任務。如果可用,池中的線程將任務出列,并進行同步cuFile調用。
完成后,線程將任務設置為已完成,并可用于執行隊列中的下一個任務。由于大多數任務讀取相同數量的數據, cuFile 讀取在線程之間實現了有效的負載平衡。給定的read_async調用的所有任務完成后,聚合任務完成,調用方代碼可以繼續,因為請求的數據范圍已上載到 GPU 內存。
最佳并行級別
線程池和讀取片的大小極大地影響了同時執行的 GDS 讀取調用的數量。為了最大化吞吐量,我們對這些參數的一系列不同值進行了實驗,并確定了提供最高吞吐量的配置。
圖 2 顯示了對 cuDF + GDS 數據攝取的性能優化研究,其中包含線程數和切片大小的可調參數。在本研究中,我們將端到端讀取吞吐量定義為二進制格式文件大小除以總攝取時間( I / O 加上解析和解碼)。
圖 2 所示的吞吐量是整個基準測試套件的平均吞吐量,基于 512 MiB 的數據幀大小。我們發現, Parquet 和 ORC 二進制格式在參數范圍內共享相同的優化行為,如圖 2 所示。由于讀取任務的數量較多,較小的片大小會導致較高的開銷,而較大的片大小會導致線程池的利用率較低。
此外,較低的線程數不能提供足夠的并行性來飽和 NVMe 讀取帶寬,而較高的線程數會導致線程開銷。我們發現,最高的端到端讀取吞吐量是針對 8-32 個線程和 1-16 個 MiB 片大小。
根據用例的不同,您可能會發現具有不同值的最佳性能。這就是為什么從 22.04 開始,默認線程池大小為 16 ,切片大小為 4 MiB 可以通過環境變量進行配置,如 GPUDirect 存儲集成 中所述。
GDS 對 cuDF 數據攝取的影響
我們使用前面描述的基準套件評估了 GDS 的使用對一些 cuDF 數據攝取 API 性能的影響。為了隔離 GDS 的影響,我們使用默認配置(使用 GDS )運行同一組基準測試,并通過環境變量手動禁用 GDS 。
為了使用 cuDF 基準進行準確的 I / O 基準測試,必須在每次新的讀取操作之前清除文件系統緩存。基準測試測量執行read_orc或read_parquet調用的總時間(讀取時間),這些是我們用于比較的值。計算每個基準案例文件的 GDS 加速比,即通過反彈緩沖區的讀取時間除以通過直接數據路徑的總攝取時間。
為了比較 GDS 性能,我們使用了 NVIDIA DGX-2 , V100 GPU 和 NVMe SSD 連接在 RAID 0 配置中。所有基準測試都使用單個 GPU 并從兩個 3.84 TB NVMe SSD 的單個 RAID 0 讀取。
文件越大,速度越快
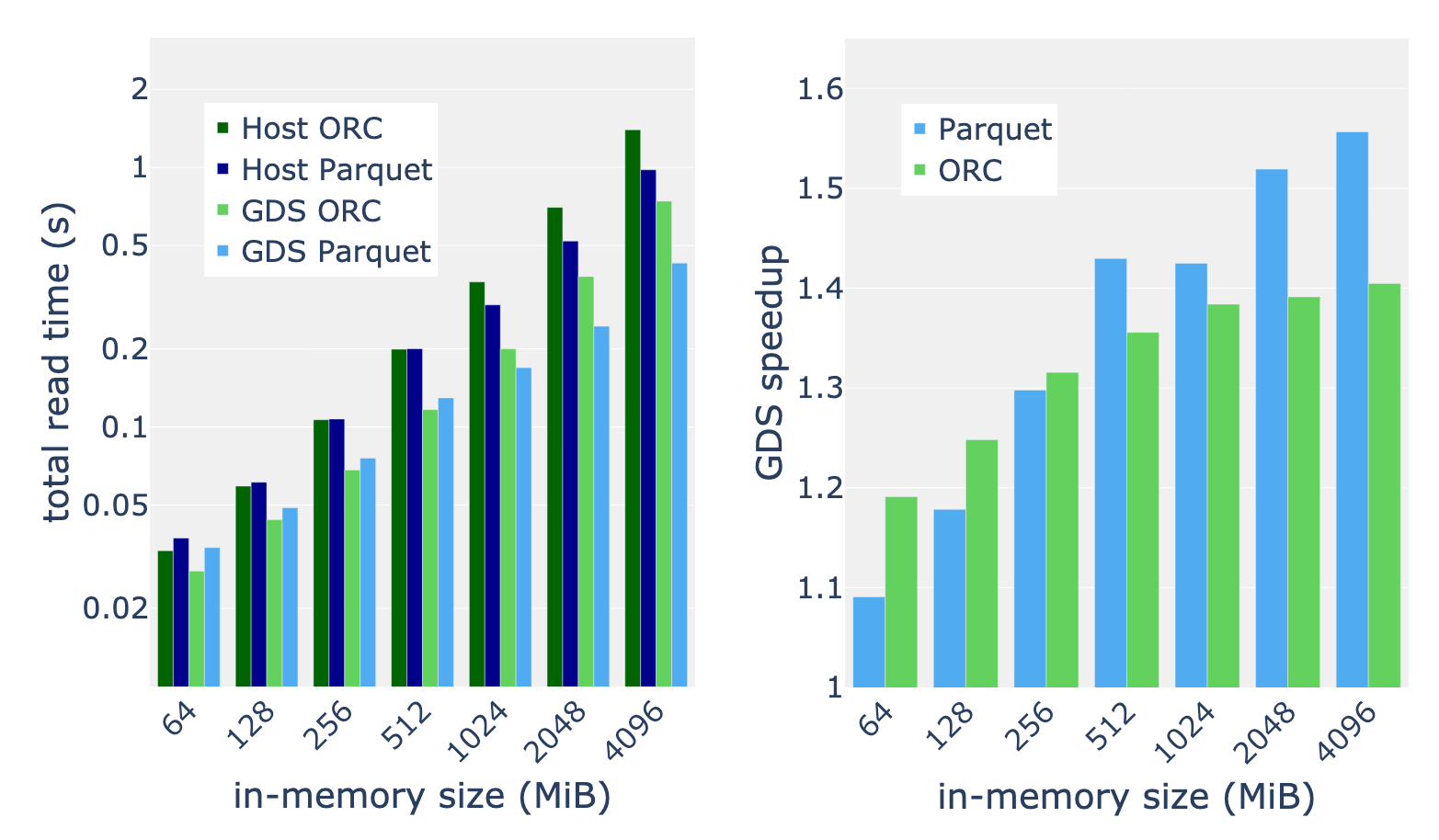
圖 3 顯示了內存數據幀大小為 4096 MiB 的各種文件的 GDS 加速。我們觀察到,性能改進的幅度很大,在主機路徑上的增幅介于 10% 到 270% 之間。
一些差異是由于數據解碼的差異造成的。例如,由于解析復雜度較高,列表類型顯示的加速比較小,而 ORC 中的十進制類型顯示的加速比較小,因為與拼花地板相比,定點解碼的開銷較小。
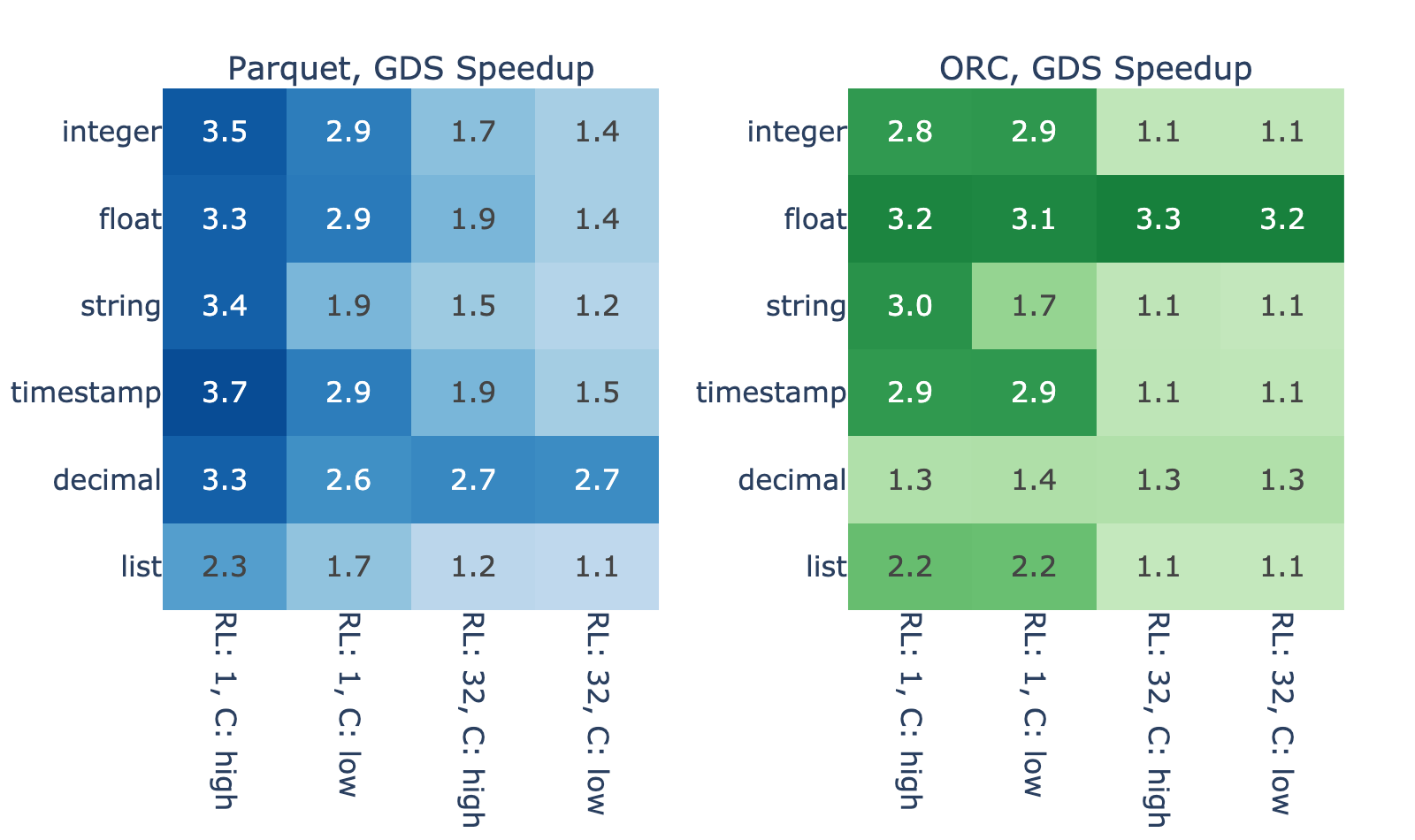
然而,解碼過程不能解釋結果中的大部分方差。由于 ORC 和拼花地板的結果之間的高度相關性,您可以合理地懷疑運行長度和基數等屬性起著主要作用。這兩個屬性都會影響數據的壓縮/編碼程度,因此下面介紹了文件大小與這些屬性的關系,以及通過代理與 GDS 加速的關系。
圖 4 顯示了數據的內在屬性對存儲固定內存數據大小所需的二進制文件大小的影響程度。對于 4096 個 MiB 內存中的數據,在沒有 Snappy 壓縮的基準情況下,文件大小從 0.1 GB 到 5.8 GB 不等。正如預期的那樣,最大的文件大小通常對應較短的運行長度和較高的基數,因為使用此配置文件的數據很難有效編碼。
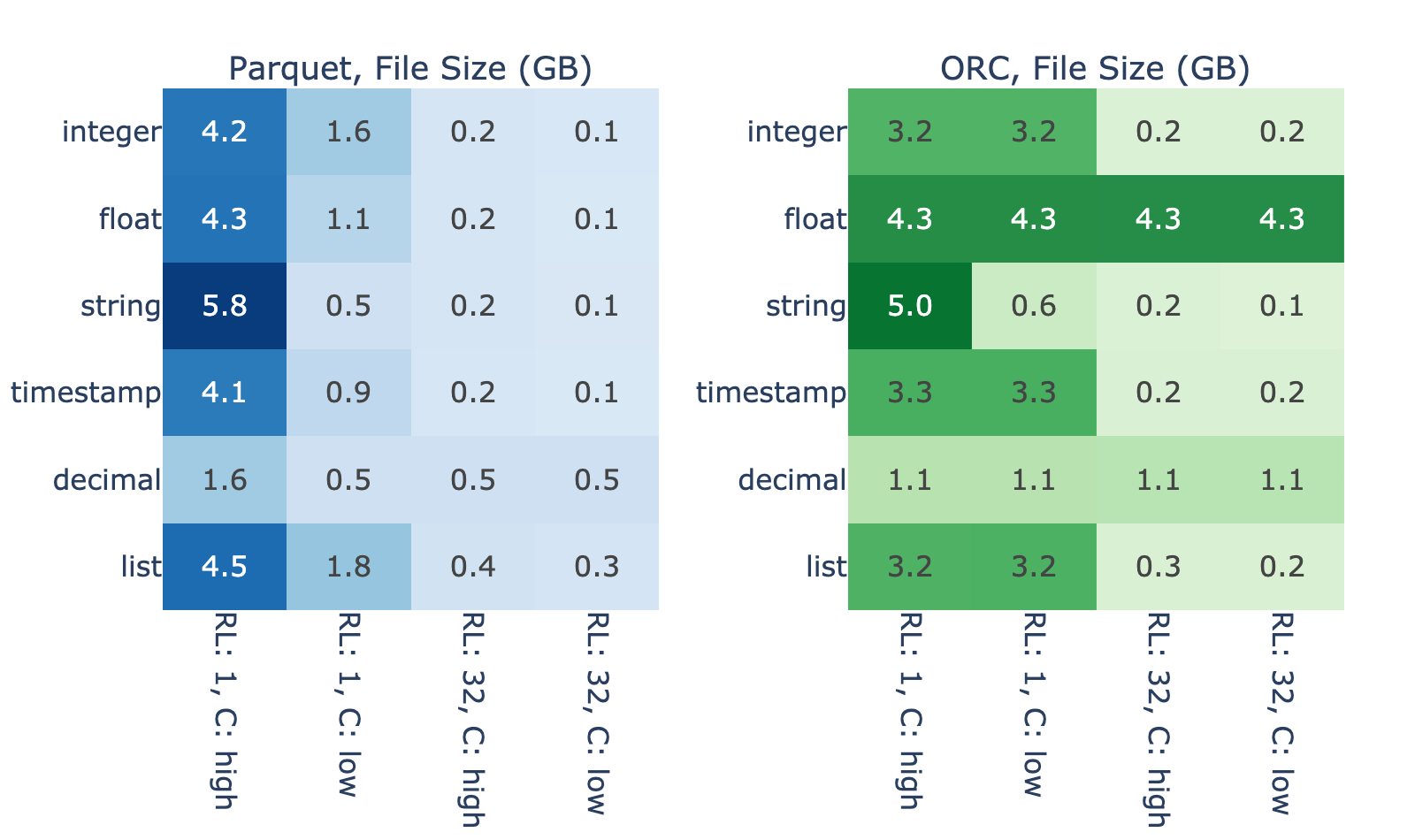
圖 3 和圖 4 顯示了文件大小與 GDS 性能優勢之間的密切關系。我們假設這是因為,當讀取一個高效編碼的文件時,與解碼相比, I / O 花費的時間更少,因此 GDS 的改進空間很小。另一方面,結果表明,讀取編碼不好的文件在 I / O 上會遇到瓶頸。
數據越大,速度越快
我們將表 1 中描述的完整基準測試套件應用于內存大小在 64 到 4096 MiB 之間的輸入。以基準測試套件的平均加速比為例,我們發現 GDS 的加速比通常會隨著數據大小的增加而增加。我們測量 512 MiB 和更大內存數據大小的一致加速比為 30-50% 。對于最大的數據集,我們發現拼花地板閱讀器比 ORC 閱讀器從 GDS 中受益更多。
總結
GPUDirect 存儲提供了到 GPU 的直接數據路徑,減少了延遲并提高了 I / O 操作的吞吐量。 RAPIDS cuDF 在其數據攝取 API 中利用 GDS 來解鎖存儲硬件的完整讀取帶寬。
GDS 使您能夠將 cuDF 數據攝取工作負載的速度提高到 3 倍,從而顯著提高工作流的端到端性能。
應用您的知識
如果您還沒有為數據處理工作負載試用過 cuDF ,我們鼓勵您測試我們最新的 22.04 版本。我們為我們的發行版和夜間構建提供了 Docker containers 。 Conda 軟件包也可用于簡化測試和部署。如果你想的話 RAPIDS cuDF 入門 ,您可以這樣做。
如果您已經在使用 cuDF ,我們建議您嘗試一下 GPUDirect 存儲。利用高容量和高性能 NVMe 驅動器比以往任何時候都更容易。如果您已經有了硬件,那么距離解鎖數據攝取的峰值性能還有幾步之遙。請繼續關注即將發布的 cuDF 。
有關存儲 I / O 加速的更多信息,請參閱以下參考資料:
?