
這是大語言模型延遲-吞吐量基準測試系列的第三篇博文,旨在指導開發者如何通過估算總體擁有成本 (TCO) 來確定 LLM 推理的成本。
有關基準測試和參數的常用指標的背景知識,請參閱 LLM Inference Benchmarking:基本概念。請參閱 LLM Inference Benchmarking 指南:NVIDIA GenAI-Perf 和 NIM,了解如何在您的應用中使用 GenAI-Perf 和 NVIDIA NIM。
簡介
大語言模型 (LLMs) 已成為現代軟件產業不可或缺的一部分,其功能類似于構建許多應用的“操作系統”基礎層。這些應用包括 AI 助手、客戶支持代理、編碼助手和“深度研究”助手。
正如 DeepSeek R1 模型系列所示,算法和模型效率方面的最新進展降低了訓練和推理成本。隨著效率的提高,LLM 應用有望變得更加經濟實惠和普及,消耗更多的計算資源 (也稱為 Jevons paradox) 。
在準備大規模部署生成式 AI 系統和應用時,企業必須解決的一個問題是,如何估算這些推理應用所需的基礎設施以及總體擁有成本。在本文中,我們將通過詳細指導和分步分析來解決此問題。
在本博文的其余部分,我們列出了要遵循的步驟:
- 完成性能基準測試。這將生成調整基礎設施規模所需的數據。
- 分析基準數據。根據有關延遲和吞吐量的性能數據,我們可以估算模型實例的數量以及以可接受的服務質量為預期用戶群提供服務所需的服務器數量。
- 構建 TCO 計算器。這有助于更輕松地探索不同的部署場景、權衡取舍及其成本影響。
性能基準測試
確定規模并估算 TCO 的前提條件是對每個部署單元 (例如 inference server) 的性能進行基準測試。此步驟的目標是測量系統在負載下可以產生的吞吐量和延遲。這些吞吐量和延遲指標,以及服務質量要求 (例如最大延遲) 和預期峰值需求 (例如最大并發用戶數或每秒請求數) ,將有助于估算所需的硬件,例如調整部署規模。反過來,配置信息是估算給定解決方案的總體擁有成本 (TCO) 的先決條件。
NVIDIA GenAI-Perf 是一款以客戶端 LLM 為中心的基準測試工具,可提供關鍵指標,例如首次令牌時間 (Time to First Token, TTFT) 、令牌間延遲 (Intertoken Latency, ITL) 、每秒令牌數 (Token Per Second, TPS) 、每秒請求數 (Requests Per Second, RPS) 等。有關這些指標及其衡量方式的基礎說明,請參閱我們之前關于 LLM 性能基準測試的博文。
對于使用 NVIDIA NIM 微服務部署的 LLM,我們提供分步指南,以輕松衡量實例的性能。然而,GenAI-perf 是一款多功能工具,可以支持任何其他兼容 OpenAI 的 API,例如 vLLM 或 SGLang。GenAI-perf 還支持通過 NVIDIA Dynamo、NVIDIA Triton 推理服務器和 NVIDIA TensorRT-LLM 后端部署的 LLM。
分析基準數據
收集原始基準數據后,系統會對這些數據進行分析,以深入了解系統的各種性能特征。閱讀我們的 LLM 推理基準測試指南,其中我們使用 GenAI-perf 收集 NIM 性能數據,并使用簡單的 Python 腳本分析數據。
例如,GenAI-perf 提供的性能數據可用于建立 latency-throughput 權衡曲線,如圖 1 所示。

此圖中的每個點都對應一個“并發”級別,例如,在整個基準測試過程中,系統在任何給定時間內收到的并發請求數量。x 軸表示以毫秒 (ms) 為單位的 TTFT 延遲,而 y 軸表示每秒請求 (req/s) 的吞吐量。可以使用 GenAI-perf 數據構建類似的圖形,使用 TTFT、ITL 或端到端請求延遲的延遲指標,而吞吐量指標可以是 RPS 或每秒 token 數 (TPS) 。
在大多數情況下,需做出以下tradeoff:
- 在低并發情況下,系統僅服務少量并發請求。延遲較低,但吞吐量也較低 (請參見圖 2 中圖的左上角) 。
- 在高并發下,系統可以使用批處理效果高效地服務更多請求,從而提高吞吐量。但是,這會以延遲增加為代價 (請參見圖的右上角) 。
在評估 FP4、FP8 和 BF16 等部署格式時,推理速度、內存使用量和準確性之間的權衡可以在 Pareto 前端可視化。此曲線突出顯示了在不影響其他指標的情況下無法改進的最佳配置,幫助開發者為其工作負載選擇最高效的精度。
Pareto 前端由在給定延遲級別 (例如第一個 token 的時間) 實現最高吞吐量 (例如每秒請求數) 的部署配置組成。如果沒有其他選項能夠以相同或更低的延遲提供嚴格意義上的更高吞吐量,則部署選項為 Pareto-optimal。在視覺上,Pareto 前端由最接近圖表左上角的一組點表示,其中吞吐量得到最大化,同時保持最小的延遲。
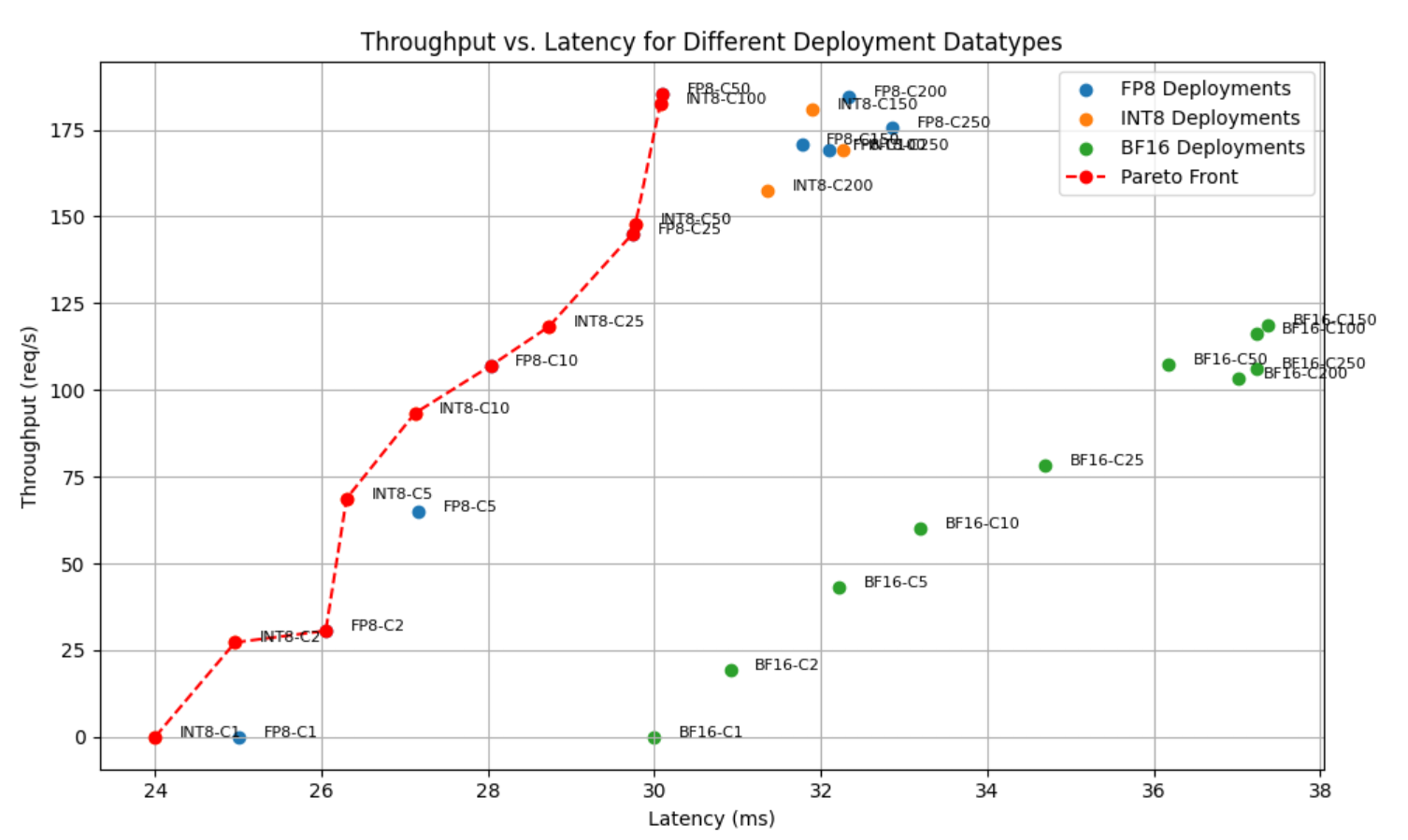
基礎架構配置
為計算給定 LLM 應用所需的基礎架構,我們需要確定以下限制條件:
- 延遲類型和最大值。這通常取決于應用程序的性質。例如,對于具有實時交互式響應的聊天應用程序,將第一個 token 的平均時間保持在 250 毫秒或以下,以確保響應速度。
- 計劃峰值請求/秒。考慮系統預計要服務的并發請求數量。請注意,這與并發用戶數量不同,因為并非所有用戶都會同時收到活動請求。
根據此信息,排除性能圖表中不合格的部分 (在本示例中,為 250 ms 行右側的任何數據點) 。在滿足延遲限制的其余數據點中,我們希望選擇吞吐量最高的數據點,這是最經濟的選項,如圖 3 所示。
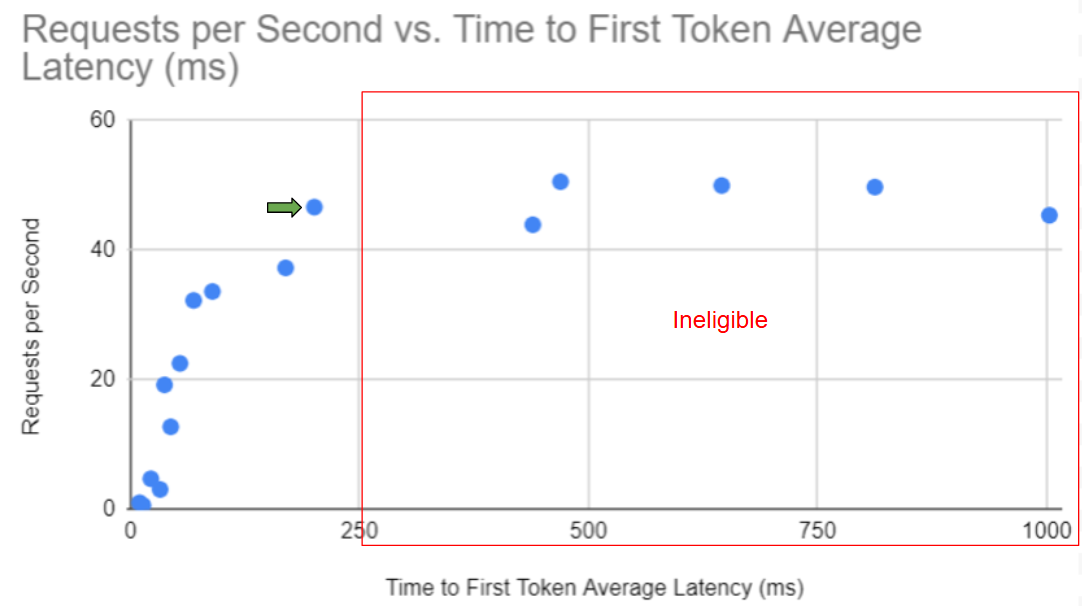
注意:此圖表假設所有部署選項均采用相同數量的 GPU。若非如此,則應將每秒請求數指標歸一化為每個 GPU 每秒請求數,以獲得共同的比較依據。
閱讀圖表中的每秒可優化請求數。這是每個實例實現的吞吐量。還應記錄每個實例使用的 GPU 數量。
接下來,我們計算所需的模型實例數量,如下所示:
- 模型實例的最小數量:計算方法是:將計劃的峰值請求除以每個實例每秒可實現的最優請求。

構建 TCO 計算器
要估算所需的硬件和軟件許可證數量以及相關成本,請按照以下步驟和假設示例進行操作
首先,收集并識別硬件和軟件對應的成本信息。
| 硬件成本 | 示例值 |
| 1x 服務器成本 (initialServerCost) | 320000 美元 |
| 每臺服務器的 GPU 數量 (GPUsPerServer) | 8 |
| 服務器折舊周期 (以年為單位) (depreciationPeriod) | 4 |
| 每年每臺服務器的托管成本 (yearlyHostingCost) | 3000 美元 |
| 軟件成本 | 示例值 |
| 每年的軟件許可成本 (yearlySoftwareCost) | 4500 美元 |
接下來,按照以下步驟計算總成本:
- 服務器數量的計算方法是:每個實例的實例數乘以 GPU 數,然后除以每臺服務器的 GPU 數。

- 服務器年度成本的計算方法是:初始服務器成本除以折舊期 (以年為單位) ,再加上每臺服務器的年度軟件許可和托管成本。

- 總成本的計算方式為所需服務器數量乘以每臺服務器的年度成本。

總成本可以進一步細分為每服務卷的成本,例如每 1000 個提示的成本,或每百萬個 token 的成本,這些都是行業中流行的成本指標。
- 假設正常運行時間為 100%,則每 1000 個提示所產生的成本是指每年的服務器成本除以服務器一年內可以處理的請求總數。這可以根據實際正常運行時間分數進行調整。
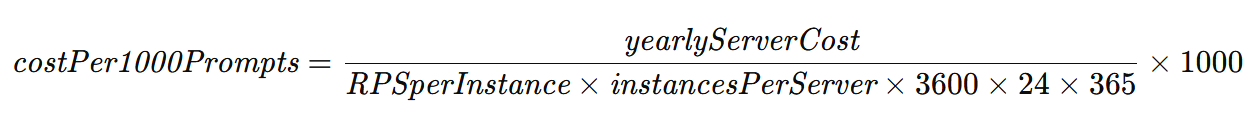
- 每 100 萬個 token 的成本將輸入和輸出相結合。我們已經有了每 1000 個提示詞 (或請求) 的成本。請注意,我們還有與這些提示相關的用例,即其輸入和輸出序列長度 (ISL 和 OSL) 。因此,我們可以計算每 100 萬個組合 token 的成本,如下所示:

- 每 100 萬個輸入/輸出 token 的成本使用輸入和輸出 token 之間的成本比率計算得出。由于輸出 token 通常需要更多時間才能生成,因此大多數商用 LLM-as-a-service 提供商都有單獨的輸入和輸出 token 成本。
| Token 類型 | 參考成本 |
| 100 萬個輸入令牌 (1M inputPrice) | 1 美元 |
| 100 萬個輸出令牌 (1M outputPrice) | 3 美元 |
每 1,000 個提示的參考成本:

最后:

總結
在本系列博客中,我們介紹了為 LLM 應用構建 TCO 計算器的完整流程。我們介紹了設置推理服務器、測量性能特征、估算所需的硬件基礎設施,然后確定相關成本要素,以納入總擁有成本(Total Cost of Ownership)方程。這種方法將幫助用戶為構建和大規模部署 LLM 應用做好準備。
查看以下資源:
- 要詳細了解 TCO 計算方法并實踐實踐,您可以按照自定進度學習“Sizing LLM Inference Systems”在線課程。
- 如需詳細了解 FLOPS 平臺架構對 TCO 的影響,請閱讀博文 NVIDIA DGX 云推出即用型模板來對 AI 平臺性能進行基準測試,以及一系列即用型模板和性能基準測試方法。
- 閱讀《The IT Leader’s Guide to AI Inference and Performance》,了解如何降低每個token的成本并更大限度地利用AI模型。
?



