隨著現代企業和云環境的擴展,網絡流量的復雜性和數量也在急劇增加。NetFlow 用于記錄有關通過路由器、交換機或主機等網絡設備的流量的元數據。NetFlow 數據對于理解網絡流量至關重要,可以有效建模為圖形,其中邊緣捕獲連接持續時間和數據量等屬性。表示主機的節點缺乏特定屬性。
研究 表明,NetFlow 數據量高達每秒數千萬個事件,這使得傳統的異常檢測方法效率低下。在孤立分析單個聯系時,識別攻擊尤其具有挑戰性,因為在沒有更廣泛的背景下,這些攻擊通常看起來很正常。通過利用圖形結構,可以添加拓撲上下文,從而更容易識別異常模式。
在本文中,我們討論了一種應用基于自動編碼器的圖形神經網絡 (GNN) 來檢測大量 NetFlow 數據中異常的新方法。
傳統的異常檢測解決方案可能依賴于靜態值或簡單的特征工程,無法適應惡意行為不斷演變的性質。目前的解決方案還可能無法達到每秒實時處理數千萬個網絡流所需的推理速度和可擴展性。
現有的基于 GNN 的異常檢測解決方案包括基本的圖嵌入技術、基于 GNN 的傳統檢測器,以及應用于網絡數據的自動編碼器架構。但是,這些方法通常存在以下問題:
- 缺乏 hierarchical graph 結構 來捕獲多級模式。
- 由于僅使用標準 Netflow 5 元組 (源 IP、目標 IP、持續時間、源字節和目標字節) ,因此 覆蓋性能不可靠 。他們通常需要更多元數據,例如 IP reputations 或 external threat intelligence。在生產規模場景中,此類元數據即使不是不可能,也很難獲取。
- 未充分利用 IP 地址空間或鄰域嵌入的 簡單節點特征 。
- 無法實現大規模實時分析所需的高檢測精度和超高吞吐量 。
- 靈活性和擴展潛力有限 ,無法在高流量下保持低誤報率。
GNN:圖形自動編碼器
我們展示了一種基于 GNN 的新型自動編碼器工作流,其中加入了專為檢測大量動態 NetFlow 圖形中的異常而定制的圖形自動編碼器 (GAE) 。

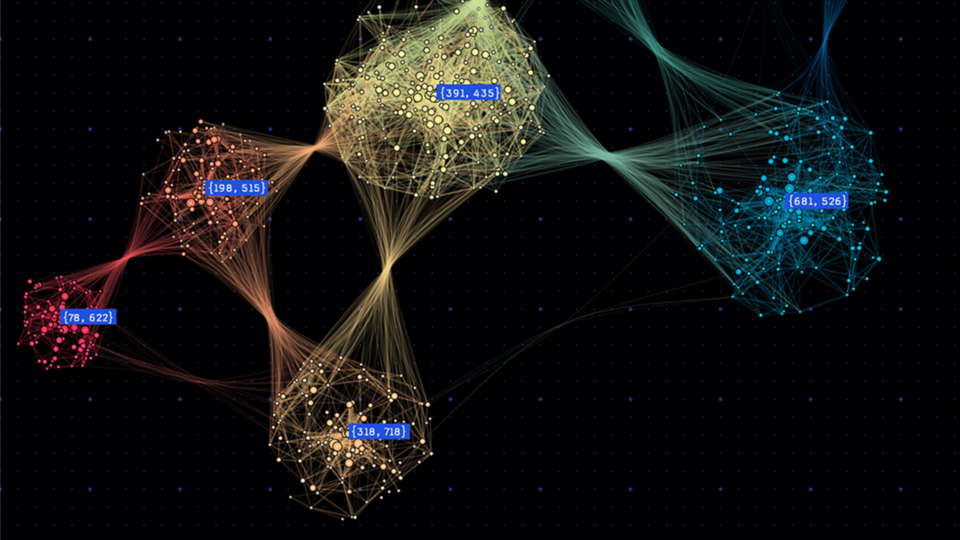
圖 1 顯示流被分塊為多個序列,然后創建圖形結構。每個節點都根據 IP 地址分配一個特征向量,而邊緣由流屬性定義。
構建圖形
構建圖形的第一步是將數據整理成可管理的序列。流根據指定的圖形大小劃分為多個序列,為此,將每個序列的流設置為 200K 流。每個流序列都會經過后續介紹的進一步處理,以形成一個作為模型輸入的圖形。
在推理時,后續批量流之間沒有重疊,因此每個圖形的創建都獨立于上一個圖形。
對數據流進行分塊后,便可形成圖形的基本結構。流中的每個唯一 IP 地址都被視為一個節點,而 IP 地址之間的每個流都構成一個邊緣。此結構會創建圖形骨架,然后將其封裝在 PyTorch 幾何圖形數據對象中。
鑒于流的邊緣中心性質,下一個重點是節點。
每個節點 (代表一個 IP 地址) 最初都會被分配一個向量嵌入,該嵌入衍生自 IP 地址的字節。這些初始嵌入通過迭代過程進行優化,其中每個節點的向量嵌入與其相鄰節點的嵌入求平均值。此平均值會一直持續到嵌入收斂,這表示迭代之間的變化極小。最終嵌入作為圖中每個節點的特征。
對于圖形中對應的每個流,定義了三個關鍵屬性:
- 前向字節數 :從源服務器發送到目標服務器的字節數。
- 向后字節 :從目的地發送回源的字節。
- 流持續時間 :捕獲流的持續時間。
這些屬性為每個邊緣提供了基本的上下文,豐富了圖形,并使 GNN 能夠更好地理解節點之間的交互。如果兩個 IP 地址之間存在多個連接,則每個連接都會在圖形上創建不同的有向邊緣。
圖結構
通常規模龐大的 NetFlow 數據因標記數據集的可用性有限以及標記過程耗費大量時間而帶來重大挑戰。
在現實場景中,網絡分析師經常遇到未標記的數據,尤其是在努力進行實時異常檢測時。這使得監督式學習方法變得不切實際,因為它們嚴重依賴已標記的示例進行訓練。
相比之下,無監督式學習模型對于 NetFlow 異常檢測至關重要,因為它們不需要標記數據,并且可以根據數據的固有結構識別模式、偏差或異常。研究表明,此類模型非常適合發現網絡流量中的異常模式或行為,這些模式或行為通常會引發安全威脅或性能問題。
通過使用聚類和密度估計等技術,無監督式模型可以高效處理 NetFlow 數據的動態和不斷演變的性質,從而在已知和新場景中有效檢測異常,而無需大量人工干預。
圖 2 總結了通用 pipeline 架構。

流圖首先使用圖形編碼器層進行編碼,這些層根據圖形上的每個節點的拓撲和特征為其生成節點嵌入向量。然后,使用節點嵌入和邊緣屬性為圖形上的每個邊緣生成存在概率,從而重建圖形的原始連接結構 (adjacency matrix) 。最后,我們將異常分數計算為存在概率的補分。
我們方法中的主要創新
- 圖形 U-Net 集成 :我們在編碼器中加入 Graph U-Net,以學習網絡流量模式的分層和多分辨率嵌入,從而提高模型檢測細微異常的能力。
- 解碼中的全局邊緣嵌入:我們通過引入與全局邊緣上下文相結合的邊緣級嵌入來增強自動編碼器的重建步驟。這有助于對邊緣進行更準確的異常評分,這與網絡流量相對應。
- 基于 IP-octet 的節點特征工程 :我們不將 IP 地址視為任意 ID,而是將其分解為 octet,對其進行標準化,并將這些特征與基于近鄰的嵌入相結合。這種方法從現實世界的網絡尋址中捕獲有意義的結構和語義,提高模型對可疑活動的敏感度。
- 輸出異常得分作為概率 :重建相鄰矩陣后,我們計算邊緣存在的概率。異常分數隨后被定義為該概率的補分,反映邊緣不存在的可能性。該模型的架構使圖形上的每個不同邊緣都有不同的異常分數,該分數由圖形上的拓撲結構以及節點和邊緣屬性提供信息。
性能指標和比較
GAE 的表現優于當前表現最佳的基準。我們的測試數據集上當前最先進的 GNN 模型稱為 Anomal-E 。與我們的方法類似,Anomal-E 以自監督的方式使用邊緣特征和圖形拓撲結構。
我們使用相同的數據集評估了 GAE 模型和 Anomal-E。我們的 GAE 模型在真陽性率 (TPR) 和假陽性率 (FPR) 方面的表現優于 Anomal-E (表 1) 。
| 數據集 | TPR | FPR | Num 總流量/ 異常流量 | Num 類 | 上一個基準 TPR/ FPR |
| NF-CICIDS-2018 | 87% | 15% | 8.4 M/ 1.0 M | 6 | 88%/ 29% |
| NF-UNSW-NB15 | 98% | 2% | 1.6 米/ 7.2 萬 | 9 | 79%/ 0.2% |
| NF – toN-IOT | 78% | 4% | 1.4 M/ 1.1 M | 9 | 74%/ 57% |
| 物聯網 | 40% | 2% | 60 萬/ 58.6 萬 | 4 | 46%/ 60% |
這一改進對現實世界的異常檢測任務具有重大影響,尤其是在網絡安全應用中。
TPR 越高,表示我們的模型可以正確識別更大比例的實際異常,這對于檢測未經授權的訪問、內部威脅或網絡入侵等惡意活動至關重要。
同樣重要的是,GAE 模型的 FPR 較低,可減少被錯誤標記為異常的正常交互次數。這在實際應用中特別有價值,因為對于安全團隊而言,調查誤報不僅成本高昂,而且十分耗時。通過更大限度地減少誤報,我們的模型使分析師能夠專注于真正的威脅,提高運營效率,并確保將資源分配給高度優先的問題。
在異常檢測中,TPR 和 FPR 之間的平衡至關重要,因為優化一個指標通常以犧牲另一個指標為代價。TPR 高但 FPR 高的模型可能會因誤報率過高而使分析師不堪重負,而 FPR 低但 TPR 低的模型則有可能漏掉關鍵威脅。
我們的 GAE 模型在這兩個指標上的性能都優于 Anomal-E,這證明了其在實現更好的整體平衡方面的有效性,使其在現實世界的部署中更加可靠和實用。
由 NVIDIA Morpheus 加速的 GAE
關于高吞吐量網絡的一個一般問題是其計算效率。通過完全集成 Morpheus,GAE 可以提供近乎實時的推理吞吐量 (圖 3) 。

在圖 3 中,結果表明 Morpheus 顯著提升了模型性能,與僅使用 CPU 的執行相比,實現了更高的吞吐量,并且在各種批量大小下都優于 GPU 順序處理。
在 NVIDIA A100 GPU 上進行測試時,批量大小為 2.5M,批量為 32 個,Morpheus 流程在近乎實時的吞吐量下達到每秒 2.5M 行。與 GPU 加速的基準相比,Morpheus 流程還將攻擊者的停留時間縮短了 78%。
了解詳情
這種方法表明,基于 GNN 的 autoencoder,尤其是通過 U-Net 集成、全局 edge embeddings 和高級 node feature 工程與分層和多分辨率 embeddings 相結合時,可以對大量 NetFlow 數據集進行高度準確和可擴展的異常檢測。通過在真陽性和假陽性率之間實現良好平衡,并通過 NVIDIA Morpheus 利用加速 inference 流程,該解決方案解決了實時、大規模網絡安全分析的核心挑戰。
有關更多信息,請參閱 GitHub 上使用 NVIDIA Morpheus 檢測 Netflow 異常的基于 GNN 的詳細 Autoencoder 示例 。
?