我們的 NVIDIA AI 紅隊 專注于在數據、科學和 AI 生態系統中擴展安全開發實踐。我們參與 開源安全倡議,發布 工具,并出席了 行業會議,主辦 教育競賽 并提供 創新培訓。
最近發布的 Meta Kaggle for Code 數據集為大規模分析機器學習 (ML) 研究和實驗競賽代碼安全性提供了絕佳的機會。我們的目標是利用這些數據來解答以下問題:
- ML 研究代碼的安全狀況如何?
- 安全組織如何改進 ML 研究人員的安全編碼實踐?
我們的分析表明,盡管有關于安全風險的公開文檔以及相對順暢的高級安全工具,ML 研究人員仍繼續使用不安全的編碼實踐。我們的理論認為,研究人員優先考慮快速實驗,并且不會將自己或其項目視為目標,因為他們通常不運行生產服務。
此外,Kaggle 環境可能會因為與研究人員的“真實基礎架構”隔離而導致安全漏洞更加嚴重。但是,研究人員必須承認自己在軟件供應鏈中的地位,并應意識到不安全的編碼操作對其研究和系統帶來的風險。
雖然解釋和利用對抗性示例最初在 2015 年的研究論文中提出,但我們發現在 ML 研究流程中很少有證據表明采用了對抗性訓練或評估。這部分原因可能是由于 Kaggle 比賽的結構和評分指標,但這與我們的其他研究和觀察結果一致。然而,隨著多模態模型的最新進展和基于圖像的提示注入攻擊得到證實,研究人員應優先考慮在對抗性條件和干擾下測試其模型。
觀察
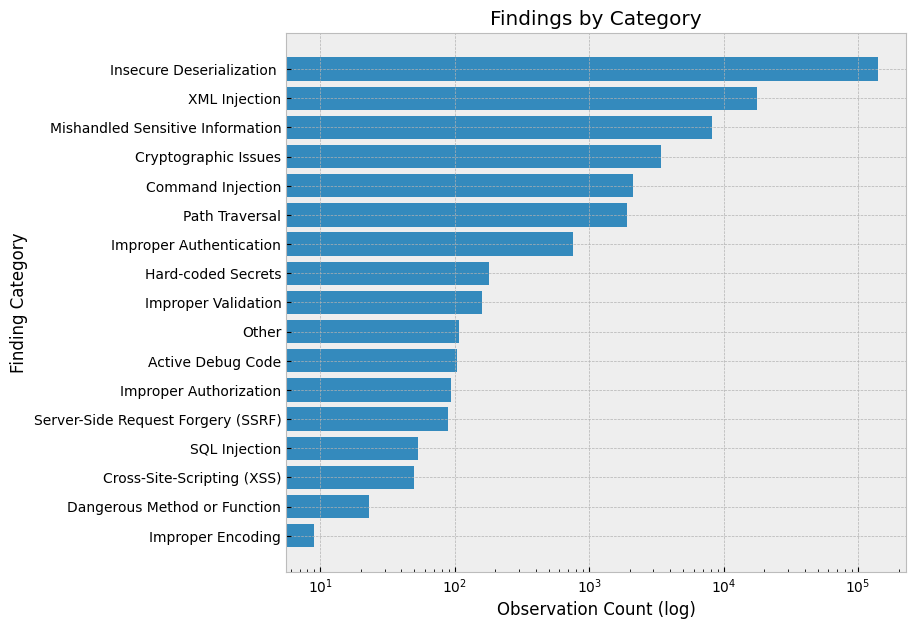
最重要的觀察結果是明文憑據的使用、不安全的反序列化(主要是 pickle)、缺乏對抗性魯棒性和評估技術以及拼寫錯誤。重點關注這些主題的防御控制和教育。
明文憑據
研究人員仍然使用有效期較長的明文憑據,并將其提交給源控制。我們發現,第三方服務(如 OpenAI、AWS、GitHub 等)擁有 140 多個獨特的活動明文憑據。對于某些憑據類型,這些憑據可能會與其他用戶數據(如電子郵件)關聯,從而使用戶面臨網絡釣魚和其他攻擊。
為遵循協調漏洞披露相關的標準行業實踐,我們于 2023 年 8 月 24 日向 Kaggle 報告了此憑據披露情況。他們已采取措施降低此風險。
不安全的反序列化
最常見的風險是不安全的反序列化。此外,許多 Notebook 都包含路徑遍歷迭代,這增加了惡意負載被執行的可能性。
例如,用戶迭代特征目錄和文件名重復執行以下命令:feature=np.load (feature_dir+fileName=`.npy`,allow_pickle=True)。
大多數 XML Injection 發現結果來自 pandas讀取 html容易受到 XML 外部實體攻擊的調用,并且大多數處理不當的敏感信息發現都與http而不是https:。
Pickle 仍然是標準
對于研究人員來說,pickle 模塊實際上仍然是最常用的序列化格式。它是導入量最大的前 50 個模塊之一,導入量接近 5000 個。ONNX 是一種更安全的 ML 模型序列化格式,但僅被直接導入了 9 次。pickle 模塊也可能已經通過其他庫中的內置序列化格式被間接使用。
例如,許多 NumPy 或 PyTorch 的序列化調用依賴于仍然基于 pickle 的內置保存方法。例如,我們確定了 45000 多個示例,其中 pickle 文件作為 pandas,joblib 和 NumPy 的反序列化。
缺乏對抗性再訓練或測試
沒有證據表明存在對抗性重新訓練或測試。常見的對抗性重新訓練和測試庫,例如 Adversarial Robustness Toolbox (ART),Counterfit,TextAttack 以及 CleverHans 不會出現在任何導入中。對于常見的可解釋性工具,Alibi,但是 Fairlearn 已被導入了 34 次。
其他的隱私保護訓練技術,如聯邦學習和差分隱私,也幾乎完全不存在(除了聯邦學習和差分隱私訓練)。您可以嘗試一次性導入 PyDP。
拼寫錯誤
我們發現了一些拼寫錯誤,例如 “熊貓” 和 “mathplotlib”,正確的應該是 “pandas” 和 “matplotlib” 等等。在 PyPI 上,惡意軟件通過搶注拼寫錯誤的域名進行傳播,這是一種眾所周知的手段。想要了解更多詳情,請參閱 A PyPI Typosquatting Campaign Post-Mortem。
一些積極的方面
我們沒有發現任何研究人員從易于在傳輸過程中被劫持或修改的來源加載序列化對象或模型的實例。此外,根據 Google 安全瀏覽查找 API。
推薦
尤其是在研究中,安全控制必須分層和校準,以盡可能減少對速度的影響。了解保護研究人員、研究和網絡所需的控制,以及將成功的研究過渡到生產可能需要的其他控制。我們在下方列出的建議基于之前的觀察結果。
開發替代方案,以取代在源代碼中輸入長期憑據
替代方案包括使用 secrets manager、環境變量、輸入提示和提供短期令牌的憑據銷售服務。多因素身份驗證 (MFA) 還可減少源代碼中泄露的憑據的影響。
經驗反復表明,如果開發者在源代碼中使用憑據,泄露的可能性會顯著增加。這些數據可能會在數據集中泄露,意外提交到版本控制中,或者通過歷史記錄和日志記錄進行披露,如我們在 2023 年 JupyterCon 的演示 中所示。
使用自動化在將錯誤提交到遠程資源之前發現錯誤
版本控制系統如 GitHub 和持續部署系統如 Jenkins 通常是攻擊者的“王冠”。使用 precommit hooks 運行安全自動化,并防止向這些目標廣播本地錯誤。
制定指南、標準和工具,限制反序列化利用風險
我們的 pickle 的安全風險 文件有據可查,但仍然需要惡意攻擊者擁有足夠的訪問權限和權限來執行攻擊。我們的團隊建議組織采用更可靠的序列化格式,例如 ONNX 和協議緩沖區。如果您的工具或組織必須支持 pickle,請執行可以驗證的完整性驗證步驟,而無需反序列化。
識別和減輕潛在的對抗性 ML 攻擊
研發期間的漏洞會影響最終服務的安全性和有效性。了解針對 ML 系統的各種攻擊,以構建適當的威脅模型和防御控件。如需了解詳情,請參閱 NVIDIA AI 紅隊:簡介。
例如,訓練期間加入對抗性重新訓練可以提高您的分類器在抵抗對抗性規避攻擊方面的穩健性。在比較模型性能時,考慮將 對抗性穩健性指標 添加到您的評估框架中。如果您贊助 Kaggle 比賽,建議在評估數據集中添加對抗性示例,以獎勵最可靠的解決方案。
考慮開發環境的生命周期和隔離情況
所有用戶的分析代碼都在 Kaggle 平臺的臨時環境中運行,與開發者的主機計算機隔離。然而,您的組織可能沒有相同級別的租戶隔離。在不不必要地阻礙研究人員的速度的同時,重要的是要考慮簡單錯誤(例如拼寫錯誤的導入語句)的潛在影響和爆炸半徑,并努力確保域資源隔離和網絡分割。
使用“allow/block lists”(允許/塊列表)和內部構件存儲庫來存儲構件,例如導入和數據集
考慮到這對研究速度的潛在影響,您可能需要考慮維護 內部倉庫 的“已知良好”庫和數據集,或者采用 import hooking 方案來降低惡意軟件包安裝和導入的風險。類似的數據集衛生狀況可以提高安全性、再現性和可審計性。
方法
該數據集包含 Kaggle 上公開托管的大約 140GB 的 R、Python 和 Jupyter Notebook 源代碼。Kaggle 允許用戶保存版本,因此其中許多構件只是對其他文件的更新和更改。我們的分析僅限于 Python 文件和 Jupyter Notebook,2020 年 4 月至 2023 年 8 月期間,Kaggle 上執行的文件約有 350 萬個。
雖然一些分析是手動進行的,但我們也嚴重依賴兩個現有的開源安全工具,TruffleHog 用于識別憑據,而 Semgrep 用于執行靜態分析。我們建議使用這些工具來復制我們的分析,并考慮將其納入您的安全工具包。
為了識別和驗證憑據,可以在 Docker 容器中針對源代碼存儲庫或本地文件運行 TruffleHog.在此分析中,我們使用本地下載程序運行 TruffleHogdocker 運行 –rm -it -v “kaggle:/pwd” trufflesecurity/trufflehog:latest filesystem/pwd –json –only-verified > trufflehog_findings.json。
TruffleHog 還支持預提交鉤子,以幫助確保憑據未提交到遠程存儲庫和 CI/CD 集成,以持續監控泄漏。TruffleHog 能夠針對 Kaggle 數據集運行,無需修改,我們根據唯一的機密值刪除了重復數據。
Semgrep 是一種靜態代碼分析器,它使用規則來識別目標源代碼中的潛在漏洞。由于 Semgrep 本身并不支持 Jupyter Notebook,因此我們使用了 nbconvert 在 Semgrep 處理之前將其轉換為 Python 文件。我們使用了默認規則中的 162 條 Python rules 和 Trail of Bits 維護的規則,更專注于 ML 應用。
安裝 Semgrep 后,在本地 Kaggle 下載環境中運行這兩個規則集,semgrep –config=” p/trailofbits ” — config=” p/python ” –json kaggle/-o semgrep_founds.json。在分析期間,我們過濾掉了“Trail of Bits”(追蹤位)的自動內存固定規則,因為我們找不到先前開發的直接路徑或證據。
NVIDIA AI 紅隊將這些工具封裝在一個名為 lintML 的項目中。要重現我們的結果,請使用 lintML – semgrep-options ” –config`p/python`- config`p/trailofbits`” <directory>。
限制
雖然我們對本次分析的數量感到自豪,但它仍然是“單一來源”,因為所有樣本都是通過 Kaggle 收集的。雖然許多結果可能相同,但來自其他數據源的安全觀察的基礎分布可能會有所不同。
例如,對 GitHub 構件執行的類似分析可能會傾向于“更安全”,因為這些存儲庫更有可能包含生產代碼。
此外,Kaggle 競賽 獎勵快速迭代和準確性,這可能會導致不同的庫導入、技術和安全考慮因素,從而實現生產研究。例如,Kaggle 競賽通常會提供必要的數據。在現實中,數據的來源、清理和標記通常是重要的設計決策,潛在的漏洞來源。
此分析同時受到我們使用的工具的啟用和限制。如果 TruffleHog 中不存在憑據或驗證器,則此處不會有相關發現。同樣,Semgrep 分析受到我們選擇的規則集的限制。這些發現中只有一部分可能是可利用的,但數量可能與總體項目風險相關。
此外,發現的數量分析可能會因規則的分布(更多的反序列化規則會產生更多的結果)而存在偏差。安全研究人員應繼續使用現有的工具,如 TruffleHog 和 Semgrep,來進行與機器學習安全性相關的發現,正如 NVIDIA AI Red Team 所做的那樣。NVIDIA AI Red Team 對于數據流和缺陷分析在機器學習應用程序中的應用特別感興趣。
結束語
Kaggle 是一個實驗、研究和競爭的場所。它獎勵快速的實驗迭代和性能,因此這些代碼構件并不代表生產服務。
事實是如此嗎?代碼經常被重復使用,在研究期間會形成習慣,而默認設置是棘手的。在對 GitHub 上 300 多個排名靠前的機器學習存儲庫進行的類似分析中,我們仍然發現了第三方服務的硬編碼憑據以及此處展示的所有結果。在研究期間提高安全意識以及信息和預防性控制有助于確保產品的安全,并提高企業的專業水平和安全狀態。
安全專業人員應將此分析用作分析其組織中研發實踐的基礎。這些發現大多數代表基準安全控制。如果您開始在組織的研究代碼中找到它們,它們就會發出與研發團隊進行更徹底接觸的信號。
使用類似的技術來評估機器學習開發周期中的偽影,以確保輕松的研究實踐不會將風險傳播到生產產品中。發現早期提供低摩擦工具的機會,而不僅僅是在生產交付流程中。利用前瞻性對抗評估和練習來增強教育、意識和合理的安全控制。
作為科學完整性的一部分,研究人員應專注于建立和維護良好的安全衛生。安全風險應被視為不需要的變量,應加以緩解,以確保實驗的真實性。思考您向組織提取的數據和代碼的來源。與安全團隊聯系,獲取有關最佳實踐和環境強化的指導。
正如您在嚴格測試假設時所做的那樣,在測試您的項目時至關重要,并找出準確性可能不是您想要優化的唯一指標的機會,并考慮包括可靠性、可解釋性和公平性測試。即使您不是在編寫生產服務,您仍然可能會使自己、您的研究和您的組織面臨潛在風險。
您可以使用我們的 安全實踐筆記本 來開始分析這些數據,或者下載 Meta Kaggle Code 使用 TruffleHog 和 Semgrep 進行評估。 lintML 可以識別 ML 訓練代碼中的風險。
如需詳細了解 ML 安全性,請查看 Black Hat Machine Learning 的 “黑帽歐洲 2023 (Black Hat Europe 2023)”。
致謝
我們要感謝 Kaggle 提供此數據集。這類數據有助于提高安全意識并為行業制定基準。NVIDIA AI Red Team 一直在努力與所在地區的 ML 從業者會面,而 Kaggle 一直是實現這一使命的出色合作伙伴和推動者。想要了解更多詳情,請參閱 Improving Machine Learning Security Skills at a DEF CON Competition。我們還要感謝所有參與 Kaggle 競賽的選手們對數據集的貢獻。
此外,我們還要感謝 TruffleHog、Semgrep 和 Trail of Bits 提供的開源安全工具,這些工具為這項研究提供了支持,并感謝 Jupyter、pandas、NumPy 和 Matplotlib 提供的高質量數據分析和可視化工具。
?