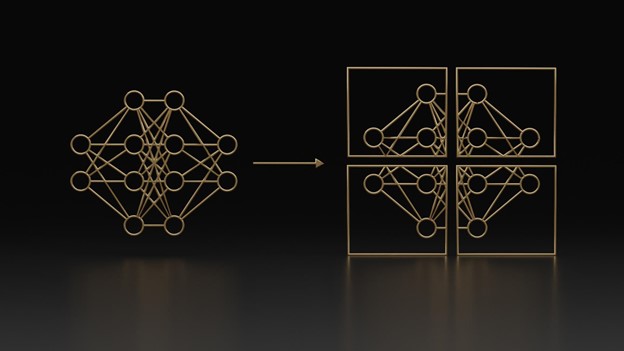
自定義 大語言模型(LLM) 時,組織面臨的一個挑戰是需要運行多個實驗,而這些實驗只能產生一個有用的模型。雖然實驗成本通常較低,并且結果非常值得付出努力,但這個實驗過程確實涉及“浪費”資源,例如在未使用其產品的情況下花費的計算資產、專用的開發者時間等。
模型合并結合了多個自定義語言模型(LLM)的權重,提高了資源利用率,并為成功的模型增加了價值。這種方法提供了兩種關鍵解決方案。
- 通過重新利用“失敗的實驗”來減少實驗浪費
- 提供經濟高效的替代方案來參加培
本文將探討如何自定義模型、模型合并的工作原理、不同類型的模型合并,以及模型合并的迭代和發展方式。
重新定義模型定制?
本節簡要概述了模型如何進行自定義,以及如何利用此過程幫助直觀地了解模型合并。
請注意,為了直觀地理解模型合并,我們過度簡化了所討論的一些概念。建議您先熟悉自定義技術、Transformer 架構和單獨訓練,然后再深入了解模型合并。例如,請參閱 Mastering LLM Techniques:Customization 。
權重矩陣在模型中的作用?
權重矩陣是許多熱門模型架構中的必不可少組件,作為大型數字網格(權重或參數),存儲模型進行預測所需的信息。
當數據流經模型時,數據會流經多個層,每個層都包含自己的權重矩陣。這些矩陣通過數學運算轉換輸入數據,使模型能夠從數據中學習并適應數據。
要修改模型的行為,必須更新這些矩陣中的權重。雖然權重修改的細節并非必需,但務必要了解基礎模型的每次自定義都會產生一組獨特的更新權重。
任務自定義?
針對特定任務 (例如總結或數學運算) 微調大型語言模型(LLM)時,對權重矩陣所做的更新旨在提高該特定任務的性能。這意味著對權重矩陣的修改會定位到特定區域,而不是均勻分布。
為了說明這一概念,可以考慮一個簡單的類比,其中權重矩陣表示為長度為 100 碼的體育場。當定制用于匯總的模型時,權重矩陣的更新可能會集中在特定區域,例如 10 到 30 碼線。相比之下,定制用于數學的模型可能會將更新集中在不同區域,例如 70 到 80 碼線。
有趣的是,在為相關任務 (例如法語摘要) 定制模型時,更新可能會與原始摘要任務重疊,從而影響權重矩陣的相同區域 (例如 25 到 35 碼線)。這種重疊提供了一個重要的見解:不同的任務定制會顯著影響權重矩陣的相同區域。
雖然前面的示例有意過度簡化,但直覺是準確的。不同的任務自定義將導致更新權重矩陣的不同部分,而針對類似任務的自定義可能會導致更改各自權重矩陣的相同部分。
這種理解可以為定制大型語言模型和跨任務利用知識的策略提供指導。
模型合并?
模型合并是一種策略的松散分組,涉及將兩個或多個模型或模型更新合并到單個模型中,以節省資源或提高特定任務的性能。
本次討論主要側重于通過 Arcee AI 開發的開源庫 (稱為 mergekit ) 實現這些技術。該庫簡化了各種合并策略的實現。
許多方法用于合并不同復雜程度的模型。在這里,我們將重點介紹四種主要的合并方法:
- 模型池
- 球形線性插值 (SLERP)
- 任務算法 (使用任務向量)
- TIES 利用 DARE
模型池?
Model Soup 方法 涉及對超參數優化實驗所生成的模型權重求取平均值,如 Model Soups: Averaging Weights of Multiple Fine-Tuned Models Improves Accuracy Without Increasing Inference Time 所述,該方法可在不增加推理時間的情況下提高準確性。
此方法最初通過計算機視覺模型進行測試和驗證,但在大語言模型方面也取得了前景良好的結果。除了從實驗中產生一些額外價值外,此過程簡單且不需要計算密集型計算。
創建模型湯的方法有兩種:樸素和貪婪。樸素的方法是依次合并所有模型,而不管它們各自的性能如何。相比之下,貪婪的實現遵循一個簡單的算法:
- 按所需任務的性能對模型進行排序
- 將性能最佳的模型與第二個性能最佳的模型合并。
- 評估合并模型在所需任務上的性能。
- 如果合并的模型表現更好,請繼續下一個模型;否則,跳過當前模型,使用下一個最佳模型重試。
這種貪婪的方法確保生成的 Model Soup 至少與最佳單個模型一樣出色。

創建模型的每個步驟都通過兩個或多個模型權重的簡單加權和歸一化線性平均值來實現。盡管推薦使用,但加權和歸一化都是可選的。mergekit 庫的實現如下所示:
res = (weights * tensors).sum(dim=0)if self.normalize: res = res / weights.sum(dim=0) |
雖然這種方法在計算機視覺和語言領域已經取得了可喜的成果,但它面臨著一些嚴重的局限性。具體來說,無法保證模型的性能會更高,線性平均值可能會導致性能降低或一般性下降。
下一種方法,SLERP,解決了一些特定的問題。
SLERP?
球形線性插值(Spherical Linear Interpolation,SLERP)是 1985 年發表的論文 《Animating Rotation with Quaternion Curves》 中引入的一種方法。這是一種計算兩個向量之間平均值的“更智能”的方法。從技術意義上說,它有助于計算曲面上兩個點之間的最短路徑。
此方法擅長組合兩個模型。經典示例是想象地球上兩點之間的最短路徑。從技術上講,最短路徑是一條穿過地球的直線,但實際上它是地球表面上的一條曲線。SLERP 計算此平滑路徑,用于為兩個模型求平均值,同時保持其獨特的模型權重“曲面”。
以下代碼片段是 SLERP 算法的核心,能夠在兩個模型之間提供如此出色的插值:
# Calculate initial angle between v0 and v1theta_0 = np.arccos(dot)sin_theta_0 = np.sin(theta_0)# Angle at timestep ttheta_t = theta_0 * tsin_theta_t = np.sin(theta_t)# Finish the slerp algorithms0 = np.sin(theta_0 - theta_t) / sin_theta_0s1 = sin_theta_t / sin_theta_0res = s0 * v0_copy + s1 * v1_copyreturn maybe_torch(res, is_torch) |
任務算法 (使用任務向量)
這組模型合并方法利用任務向量以各種方式組合模型,增加復雜性。
任務向量:捕獲自定義更新
回顧一下自定義模型的方式,更新模型的權重,并在基礎模型矩陣中捕獲這些更新。我們不將最終矩陣視為全新模型,而是將其視為基礎權重和自定義權重之間的差值(或增量)。這引入了任務向量的概念,即包含基礎權重和自定義權重之間增量的結構。
這與低秩適應(Low Rank Adaptation)背后的直覺相同,但沒有進一步分解表示權重更新的矩陣。
通過減去基礎模型權重,可以輕松地從自定義權重中獲取任務向量。
任務干擾:更新沖突
回顧一下運動領域的示例,不同的自定義設置之間的更新權重可能會重疊。有一些直觀的理解是,與為兩個或多個單獨的任務定制相比,為同一任務定制會導致更新權重沖突率更高。
這種“沖突更新”概念更正式地定義為任務干擾,它涉及兩個或多個任務向量之間重要更新的潛在碰撞。
任務算法
如論文《 Editing Models with Task Arithmetic》所述 ,任務算法是任務向量方法的最簡單實現,具體流程如下:
- 獲取兩個或多個任務向量,并將其線性合并,如 Model Soup 中所示。
- 獲得生成的合并任務向量后,系統會將其添加到基模型中。
這個過程簡單而有效,但有一個關鍵的缺點:沒有注意到要合并的任務向量之間的潛在干擾。
TIES 合并
如論文《TIES-Merging:在合并模型時解決干擾》所述 ,TIES(TrIm Elect Sign and Merge)是一種方法,它采用了任務算法的核心思路,并將其與啟發式算法相結合,以解決任務向量之間的潛在干擾。
一般程序是,對于合并的任務向量中的每個權重,考慮每個傳入權重的大小,然后是每個傳入權重的符號,然后取剩余權重的平均值。

此方法旨在通過在合并過程中優先考慮對任何給定權重更新具有最顯著權重更新的模型來解決干擾問題。其本質是,在合并過程中,優先考慮“關心”該權重的模型,而不是那些對該權重不那么“關心”的模型。
DARE
在論文“ 語言模型是超級馬力歐:從同源模型中吸收能力作為免費午餐 ”中,DARE 并不是一種直接的模型合并技術。相反,它是一種可與其他方法一起考慮的增強。DARE 源自以下內容:
使用 p 比率丟棄增量參數,并將剩余參數重新縮放為 1/(1 – p),以近似原始嵌入。
DARE 并沒有試圖通過啟發式方法解決干擾問題,而是從另一個角度出發。本質上,它通過將特定任務向量中發現的更新設置為 0 來隨機丟棄大量更新,然后根據所丟棄的權重比例重新調整剩余權重。
事實證明,即使任務向量權重下降 90%甚至 99%,DARE 也有效。
通過模型合并提高模型效用?
模型合并的概念為更大限度地提高多個 LLM 的效用提供了一種實用的方法,包括由更大的社區完成的特定于任務的微調。通過 Model Soup、SLERP、Task Arithmetic、TIES-Merging 和 DARE 等技術,組織可以有效地合并同一系列中的多個模型,以便重復使用實驗和跨組織工作。
隨著模型合并背后的技術得到更好的理解和進一步的開發,它們將成為高性能大型語言模型的基石。雖然本文只是簡單介紹,但更多的技術仍在不斷開發之中,包括 一些基于進化的方法 。模型合并是生成式人工智能領域的新領域,因為越來越多的應用正在接受測試和驗證。
?