ChatGPT 給人留下了深刻印象。用戶很樂意使用人工智能聊天機器人提問、寫詩、塑造互動角色、充當個人助理等等。大語言模型( LLM )為 ChatGPT 供電,這些模型就是本文的主題
在更仔細地考慮 LLM 之前,我們首先想確定語言模型的作用。語言模型給出了一個單詞在單詞序列中有效的概率分布。從本質上講,語言模型的工作是預測哪個詞最適合一個句子。圖 1 提供了一個示例。
![Screenshot of the words, "Hey I need to chop this onion, can you pass me the [?] -- Model's prediction[?]: Knife."](https://lh4.googleusercontent.com/YMDSzp4md5FuOGakw_5ukMk8By37UAsReaqoGrzhbohrsyioVFx0bUIZkRdyxH0OyXVBQFL42mQU8OBaggzPgGvMhOVlxupKNq6DclAXzg8ij7wCXkrXnclKWb1fOxKmHNvSYJHOqFPsTK-REZo8XWA)
雖然像 BERT 這樣的語言模型已經被有效地用于處理文本分類等許多下游任務,但已經觀察到,隨著這些模型規模的增加,某些額外的能力也會出現
這種規模的增加通常伴隨著以下三個維度的相應增加:參數的數量、訓練數據和訓練模型所需的計算資源。有關詳細信息,請參閱Emergent Abilities of Large Language Models.
LLM 是一種深度學習模型,可以使用大型數據集識別、總結、翻譯、預測和生成內容。 LLM 沒有一個集合的界限,但為了本討論的目的,我們使用這個術語來指代任何 GPT 規模的模型或具有 1B 或更多參數的模
這篇文章解釋了在使用較小語言模型構建的一組模型管道上使用 LLM 的好處。它還涵蓋了以下基本內容:
- LLM 提示
- 快速工程
- P- 調諧
為什么要使用大型語言模型?
聊天機器人通常是由一組 BERT 模型和一個對話框管理器構建的。這種方法具有一些優點,例如更小的模型,這可以降低延遲和計算需求。這反過來又更具成本效益。那么,為什么不使用合奏而不是 LLM 呢?
- 就其設計而言,合奏團不如 LLM 靈活。這種靈活性來自生成能力,以及所述模型是在需要各種任務的大型數據語料庫上訓練的。
- 在許多情況下,獲得足夠的數據來應對挑戰是不可行的。
- 每個集合都有自己的 MLOps 管道。維護和更新大量復雜的合奏是困難的,因為每個合奏中的每個模型都必須定期進行微調。

LLM 在多個系綜中的價值
可以說,一組模型可以比 LLM 便宜。然而,僅考慮推理成本,這一假設忽略了以下考慮因素:
- 節省工程時間和成本:構建、維護和擴展集成是一項復雜的挑戰。每個組件模型都必須進行微調。用于模型推理和縮放以適應流量的人工智能基礎設施需要相當多的時間來構建。這是針對一項技能。為了模仿 LLM ,必須建立多種技能。
- 更短的功能發布時間:為一項新技能建立一個新管道所需的時間通常比對 LLM 進行 p 調諧所需要的時間更長(稍后將對此進行詳細介紹)。這意味著 TTM 要長得多。
- 數據采集和質量維護:任何專門構建的集合都需要大量的特定病例數據,而這些數據并不總是可用的。必須在每個模型的基礎上收集這些數據。換句話說,除了來自集成的 I / O 之外,還需要用于集成中使用的每個單獨模型的數據集。此外,所有模型都會隨著時間的推移而漂移,在使用多個模型時,用于微調的維護成本會迅速增加。
這些考慮因素顯示了在多個系綜上使用 LLM 的價值。
提示 LLM
提示被用作與 LLM 交互以完成任務的一種手段。提示是用戶提供的輸入,模型要對其做出響應。提示可以包括說明、問題或任何其他類型的輸入,具體取決于模型的預期用途。例如,在穩定擴散模型的情況下,提示是要生成的圖像的描述

提示也可以采用圖像的形式。通過這種方法,生成的文本輸出描述了圖像提示。這通常用于圖像字幕等任務。

對于 GPT-3 等模型,文本提示可以是一個簡單的問題,比如“彩虹中有多少種顏色?”或者,提示可以采取復雜問題、數據或指令的形式,比如“寫一首勵志詩,讓我快樂。”
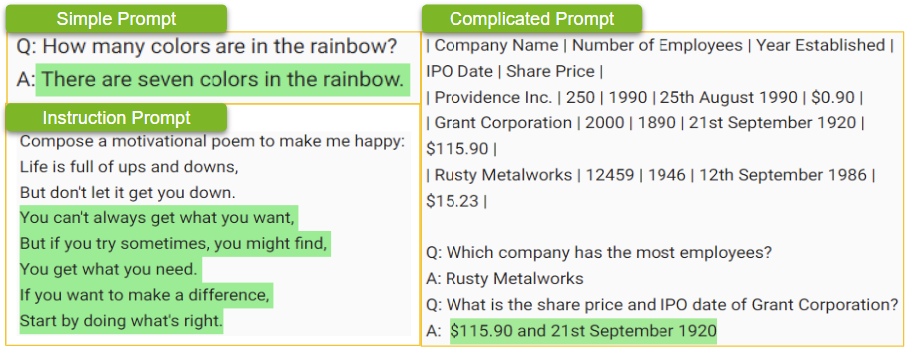
提示還可以包括特定的約束或要求,如語氣、風格,甚至所需的響應長度。例如,給朋友寫信的提示可以指定語氣、字數限制和要包含的特定主題
LLM 生成的響應的質量和相關性在很大程度上取決于提示的質量。因此,提示在自定義 LLM 以確保模型的響應滿足自定義用例的要求方面發揮著關鍵作用
提示工程以獲得更好的提示
術語快速工程是指仔細設計提示以生成特定輸出的過程。提示在從模型中獲得最佳結果方面發揮著關鍵作用,而如何編寫提示可以對生成的輸出產生很大影響。以下示例討論了三種不同的策略:
- 零樣本提示
- 很少提示射擊
- 思維鏈提示
零樣本意味著提示模型,而不顯示任何來自模型的預期行為示例。例如,一個零樣本提示會提出一個問題。

在圖 7 中,答案是錯誤的,因為巴黎是首都。從答案來看,模型可能不理解“資本”一詞在這種情況下的使用
克服這個問題的一個簡單方法是在提示中給出一些例子。這種類型的提示被稱為少鏡頭提示。在提出實際問題之前,您提供了幾個例子

幾次射擊提示使模型能夠在沒有訓練的情況下進行學習。這是設計提示的一種方法
你如何讓模型合乎邏輯地回答一個問題?要了解這一點,請從更復雜的零樣本提示開始。

在圖 9 中,答案再次出現錯誤。(正確答案是四個藍色高爾夫球。)為了幫助發展推理,請使用一種名為 思維鏈提示。通過提供一些鏡頭示例來做到這一點,其中解釋了推理過程。當 LLM 回答提示時,它也會顯示其推理過程。

雖然圖 10 中所示的示例是一個“思考鏈”提示,但您也可以給出一個“零樣本鏈”提示。這種類型的提示包括諸如“讓我們從邏輯上思考這個問題”之類的短語

通過這種方法, LLM 生成了一個能夠準確回答問題的思想鏈。嘗試一系列不同的提示是很有用的
P- 調整以自定義 LLM
如前所述,即時工程是定制模型響應的一種方法。然而,這種方法有缺點:
- 可以使用少量示例,從而限制控制級別。
- 示例必須預先附加,這會影響代幣預算
如何繞過這些限制?
遷移學習是一個明顯的候選者:從一個基本模型開始,使用特定于用例的數據來微調模型。這種方法在處理常規模型時效果很好,但微調具有 530B 參數的模型(比 BERT 模型大約 5300 倍)會消耗相當大的時間和資源
P- 調諧,或迅速調諧, 是一種參數有效的調整技術,可以解決這一挑戰.P- 調諧包括在使用 LLM 之前使用一個小的可訓練模型。小模型用于對文本提示進行編碼,并生成特定于任務的虛擬令牌
這些虛擬令牌被預先附加到提示并傳遞給 LLM 。當調優過程完成時,這些虛擬令牌被存儲在查找表中,并在推理過程中使用,取代較小的模型。
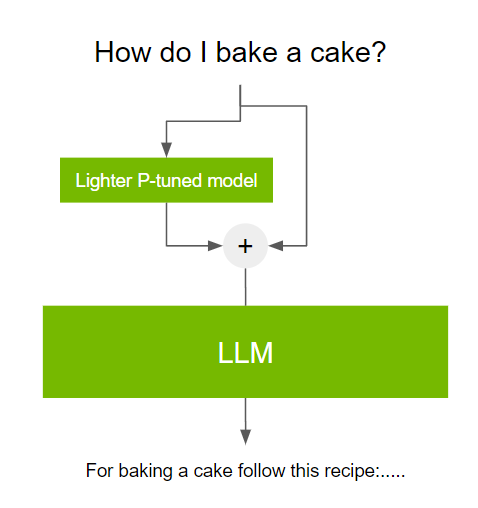
這一過程是有益的,原因如下:
- 與微調 LLM 相比,定制模型管道以獲得所需結果所需的資源要少得多。
- 調整較小型號所需的時間要少得多(最快可達約 20 分鐘)。
- 在不需要大量內存的情況下,可以保存對不同任務進行 p 調整的模型。
這個NVIDIA NeMo 云服務簡化了這個過程。有關詳細信息,請參閱p-tuning the models in the NeMo service(您必須是早期訪問計劃的成員)。
結論
這篇文章討論了 LLM ,并概述了它們的使用案例。它還涵蓋了定制 LLM 行為所涉及的基本概念,包括各種類型的提示、提示工程和 p 調整。
有關詳細信息,請參閱more posts about LLMs.
?